20.1
Per confrontare la qualità della voce e per arrivare ai parametri che contribuiscono alla qualità della voce, è necessario sapere come viene misurata la qualità della voce e quali sono gli obiettivi di qualità. La configurazione di base del test per le misurazioni vocali VoIP è riportata nell’argomento 13. In questo argomento, la qualità della voce come media opinione punteggi (MOS), varie classificazioni, qualità della voce che influenzano i parametri, e miglioramenti sono discussi. Le misurazioni della qualità della voce per MOS sono classificate come soggettive e oggettive.
Una rappresentazione funzionale di alcune tecniche di misurazione della qualità vocale popolari è illustrata in Fig. 20.1 . Nella figura, la voce viene mostrata da
Tabella 20.1. PSTN e VoIP di Qualità Confronti
| gli Attributi di | PSTN | VoIP |
| Distorsioni sui | Distorsioni dovute a diversi | No trasmissione analogica |
| linea analogica | 1000-metri di linee da | distorsioni con le chiamate VoIP. |
| DLC o posizione CO | ||
| cancellazione dell’Eco | Raggiunto attraverso la perdita di | Carrier grade eco cancellers |
| sulle chiamate nazionali | pianificazione e bassi ritardi | sono utilizzati. |
| Automatico del guadagno | Non incorporated | Possibile incorporare per |
| controllo | migliore percezione del parlato | |
| i livelli di ascolto o di qualità | ||
| esperienza. | ||
| la qualità della Voce | Monitoraggio, come GR- | RTCP – XR e GR – 909 sono |
| monitoraggio | 909 sono incorporati | incorporato in molti VoIP |
| in PSTN | distribuzioni. | |
| Larghezza di banda o bit | 64 kbps fisso su digitale | Larghezza di banda variabile, di solito |
| tasso | TDM. Canali DCME | richiede più sul fisico |
| utilizzare le interfacce 16, 24, 32 e | rispetto al PSTN. Fax | |
| 40 kbps, che degrada fax | servizi può ottenere di più | |
| Qualità | larghezza di banda o di ridondanza | |
| la trasmissione. | ||
| Chiamate fax | Prestazioni limitate da | Utilizza linee di estremità corte. Quindi, fax |
| fine linea di trasmissione | consegna può essere meglio utilizzando | |
| caratteristiche | VoIP. Tuttavia, ci potrebbe | |
| essere problemi di interoperabilità per | ||
| invio fax. | ||
| Voce e dati | Principalmente per le chiamate vocali, | servizi Internet e VoIP può |
| alcuni servizi potrebbero riutilizzare | scala con dati e | |
| voce di canali di dati | media le esigenze di servizio. | |
| Funzioni di chiamata vocale | Funzioni limitate e | Diverse funzionalità sono offerte come |
| costoso per diversi | gratis. | |
| caratteristiche del servizio | ||
| Interfacce vocali | Interfacce limitate | Interfacce e servizi multipli. |
| Lunga distanza | Lunga distanza è costoso | Di solito libero o molto più basso |
| tariffe. | ||
| Transcodifica | Più livelli di | End – to – end per la codifica diretta può essere |
| la transcodifica per inter- | impiegato basato sul | |
| regionale chiamate | supporto disponibili. | |
| banda larga supporto | chiamate Vocali sono di | banda larga end – to – end voce è |
| a banda stretta ( | possibile che può superare | |
| PSTN qualità. |
il gateway di invio al gateway di ricezione. Il gateway ricevente viene mostrato con alcuni blocchi più espansi per creare un quadro generale del modello E, che viene utilizzato per la stima del fattore R, metriche di qualità aggiuntive e l’operazione RTCP-XR (Transport Control Protocol-Extended Reports) in tempo reale. Nel modello E vengono utilizzati i parametri RTP, RTCP, jitter buffer e total system signal. Quando si calcola il fattore R e altri parametri derivati,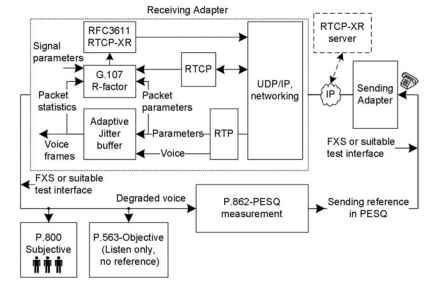
Figura 20.1. Panoramica sulle misure di qualità della voce popolari.
RTCP-XR può inviare pacchetti alle applicazioni interne, al gateway di destinazione e al server RTCP-XR. In sintesi, il fattore R non intrusivo è una stima oggettiva che risiede come parte dell’implementazione VoIP e nel gateway è necessario un software aggiuntivo per la stima del fattore R. Nella valutazione percettiva della qualità del discorso (PESQ), strumenti come MultiDSLA inviare il discorso di riferimento attraverso il sistema VoIP in prova e valutare il degradato con il discorso di riferimento. Questa misurazione è attiva e i gateway VoIP non devono sapere nulla della misurazione. Nell’ascolto soggettivo, più ascoltatori valuteranno la qualità della voce. In P. 563, la voce viene analizzata interamente sul segnale degradato ricevuto e il riferimento originale non è richiesto. P. 563 è simile all’ascolto soggettivo, ma viene valutato dagli strumenti o dai processori. Ognuna di queste tecniche arriva a una diversa scala di qualità della voce. In una chiamata vocale VoIP tra A e B, le misurazioni vocali vengono effettuate come half-duplex, il che significa che le misurazioni vengono effettuate come A a B o B a A, uno alla volta. A causa del tipo di test di ascolto half-duplex, queste misurazioni sono indicate come test di qualità di ascolto (LQ). Il suffisso LQ viene aggiunto durante la presentazione dei risultati sui test half-duplex e i test oggettivi sono inoltre suffissi con ” O ” come LQO.
20.1.1
Tecnica di misurazione soggettiva
Nella valutazione della qualità della voce soggettiva, la qualità della voce MOS è valutata dal gruppo di ascoltatori maschi e femmine effettivi. È il test di ascolto effettivo per valutare il MOS. Le raccomandazioni P. 800 e P. 830 vengono utilizzate per valutare le prestazioni soggettive dei codec vocali
. Gli stessi test sono estesi alla qualità della voce VoIP. Un gruppo di persone partecipa per la registrazione di punteggi soggettivi. Vengono registrate più frasi di prova e quindi i soggetti di prova (gruppo di persone) li ascoltano in condizioni diverse. Questi test vengono eseguiti in stanze speciali con rumori di fondo e altri fattori ambientali sono tenuti sotto controllo per l’esecuzione del test. Le condizioni di prova sono riportate in . Le tecniche di misurazione soggettiva sono classificate come Absolute Category rating (ACR), Degradation Category rating (DCR) e comparison Category rating (CCR).
I n ACR, i partecipanti ascoltano campioni vocali registrati che sono stati elaborati attraverso diverse connessioni di test. Un minimo di 16 soggetti di prova (ascoltatori) dovrebbero partecipare alla valutazione. Durante l’ascolto, gli utenti valutano la chiamata su una scala da 1 a 5 MOS. I valori medi delle valutazioni degli utenti sono considerati per generare la qualità complessiva della chiamata.
In un test DCR sono presenti due campioni vocali. Il primo esempio di discorso è un campione di riferimento con qualità predefinita. L’esempio qui si riferisce al discorso che dura per diversi secondi di durata. L’altro esempio di discorso è una versione degradata. Gli ascoltatori devono confrontare la versione degradata con un riferimento su una scala di degradazione da 1 a 5. Qui, 5 è un degrado impercettibile e 1 rappresenta il peggior degrado. I risultati sono riassunti come MOS degradati.
Nei test CCR, agli utenti viene chiesto di ascoltare due serie di campioni, uno corrispondente al riferimento e l’altro al degradato. Questo test è simile a DCR, tranne che l’ordine dei campioni presentati agli ascoltatori viene modificato in diverse iterazioni. L’ordine di riferimento e degradato non è dichiarato all’ascoltatore. Gli ascoltatori sono invitati a dare una valutazione comparativa di un secondo campione rispetto al primo su una scala da -3 a 3 come da P. 800 Allegato-D. Nel presentare i risultati, ” 3 ” rappresenta una qualità molto migliore e “-3” rappresenta la qualità peggiore su una scala relativa. Il punteggio di qualità è mappato su MOS. La valutazione MOS consentita è da 1 a 5, ma una valutazione utente superiore a 4.5 è limitata a 4.5.
I test soggettivi sono coinvolti nelle procedure ed è uno sforzo costoso. È limitato a meno iterazioni per valutare qualsiasi nuovo algoritmo o codec vocali. È difficile mantenere la coerenza come test oggettivi basati su strumenti.
20.1.2
Tecniche di misurazione oggettiva
Metodi oggettivi sono le misurazioni e calcoli. Si prevede che i risultati saranno coerenti in diverse misurazioni. Esistono diversi metodi oggettivi e sono classificati come metodi attivi e passivi.
• Tecniche di monitoraggio attivo di PESQ Tecniche di monitoraggio attivo. La misurazione attiva è chiamata monitoraggio intrusivo o monitoraggio offline a causa del coinvolgimento di segnali esterni.
Nel tentativo di integrare la qualità dell’ascolto soggettivo, vengono sviluppati test con metodi oggettivi a basso costo. KPN ha sviluppato il P. 861 (questo è obsoleto ora) perceptual speech Quality measure (PSQM) per la valutazione delle prestazioni del codec. British Telecom ha sviluppato il perceptual analysis measurement system (PAMS) per le misurazioni di rete. Il P. 862 PESQ è il risultato di una competizione ITU. Le prestazioni di PAMS e una nuova versione di PSQM, PSQM99, erano simili, quindi i contributori sono stati invitati a combinare gli algoritmi. Ciò ha portato a PESQ, che è leggermente migliore dei suoi costituenti.
Questi metodi misurano la distorsione introdotta da un sistema di trasmissione e codec confrontando un file di riferimento originale inviato nel sistema su un’interfaccia telefonica con il segnale alterato ricevuto ricevuto su un’altra interfaccia telefonica. PSQM è stato sviluppato per test di laboratorio di codec vocali. PAM e PESQ sono progettati per i test di rete. L’uso di strumenti per la qualità della voce è molto più semplice rispetto alle misurazioni soggettive o passive. I fornitori di strumenti forniscono anche i parametri extra-derivati per aiutare a identificare le fonti di degradazione attraverso le misurazioni. Fare riferimento ad alcuni strumenti indicati nell’argomento 13 per maggiori dettagli sulle varie caratteristiche.
Durante la scrittura di questo argomento, PESQ è stato popolarmente supportato negli strumenti. PESQ è stato approvato dall’ITU nel marzo 2001 come raccomandazione P. 862, sostituendo P.861 MQ. Il PESQ combinato diversi migliori meriti di PAMS e PSQM. E ‘ preciso nel predire i punteggi dei test soggettivi, ed è robusto in condizioni di rete gravi come un ritardo variabile, filtraggio alle interfacce analogiche, e il supporto sia a banda larga e banda stretta. PESQ produce un punteggio che si trova su una scala da -0.5 a 4.5. È stata fornita una funzione di mappatura da un punteggio PESQ P. 862 a un punteggio MOS soggettivo medio P. 800-LQ, rendendolo
PESQ – LQO per la voce a banda stretta. LQO denota un obiettivo di qualità di ascolto. PESQ-LQ si trova da 1 a 4.5. Un MOS di 4.5 è la qualità massima raggiunta per una condizione chiara e non distorta. Una panoramica sull’algoritmo PESQ è data qui. Si consiglia di fare riferimento alla famiglia ITU P. 862 di raccomandazioni, software e alcuni opuscoli di strumenti commerciali per maggiori dettagli .
20.1.3
PESQ Misura
Percezione uditiva umana è il concetto di base dietro PESQ e dei suoi predecessori PAMS e PSQM. Un modello percettivo viene utilizzato per distinguere correttamente tra distorsioni udibili e non udibili, e questo ha dimostrato di essere il modo migliore per prevedere con precisione l’udibilità e il fastidio di distorsioni complesse. Oltre alla quantità di distorsione, la distribuzione della distorsione udibile potrebbe rendere le previsioni di qualità molto più accurate.
PESQ misura la qualità della voce unidirezionale, il che significa che il funzionamento half-duplex di misura. Valuta la qualità di un segnale vocale distorto che è stato codificato e trasmesso sulla rete confrontandolo con il segnale originale non distorto. Il discorso originale e distorto è mappato su rappresentazioni psicofisiche che corrispondono al modo in cui gli esseri umani sperimentano il discorso.
La qualità del discorso distorto è giudicata in base alle differenze nelle rappresentazioni psicofisiche. L’operazione PESQ fa uso di due principali classi di operazioni logaritmiche – vale a dire la conversione dei segnali nel dominio psico-acustico e la modellazione cognitiva. Una rappresentazione funzionale dell’algoritmo PESQ è data in Fig. 20.2. I produttori di strumenti per la misurazione PESQ includono diverse operazioni aggiuntive per estrarre i parametri di analisi del segnale e le menomazioni oltre alle misurazioni PESQ.
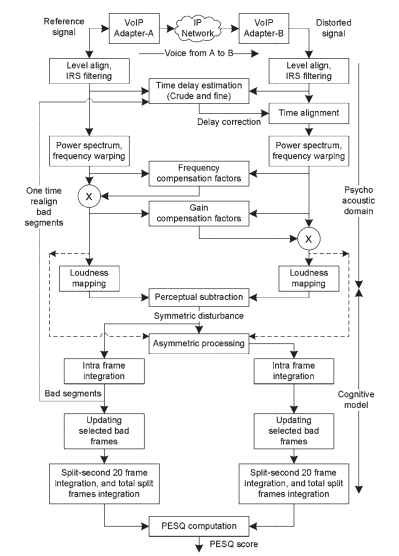
Figura 20.2. Rappresentazioni funzionali dell’algoritmo PESQ.
L’elaborazione effettuata dall’algoritmo PESQ include le fasi elencate di seguito. I passaggi di riepilogo sono riportati qui; diversi dettagli sul PESQ sono forniti in .
Nella prima fase di elaborazione, sia il segnale di riferimento che quello degradato vengono scalati allo stesso livello di potenza costante. Questo ridimensionamento è necessario perché il segnale di riferimento non deve essere a un livello definito e il guadagno del sistema in prova è sconosciuto prima del test. PESQ presuppone che il livello di ascolto soggettivo sia una costante di 79 dBSPL nel punto di riferimento dell’orecchio . Per la normalizzazione della potenza, i livelli di segnale elettrico sono normalizzati a-26dBov (cioè-20dBm come indicato nel riferimento ). Una normalizzazione del livello del segnale viene applicata sia al riferimento che al segnale degradato per portarli a questo livello.
I modelli percettivi come PESQ dovrebbero tenere conto delle caratteristiche dei telefoni cellulari in quanto l’ascolto soggettivo può utilizzare telefoni cellulari. In PESQ, il percorso di ricezione dei telefoni è modellato utilizzando un filtro passa-banda intermedio del sistema di riferimento (IRS) nel dominio della frequenza. Questo processo tiene conto degli effetti dei componenti elettrici e acustici del portatile. Sia il riferimento che il segnale degradato sono filtrati IRS.
Il sistema in prova può includere un ritardo variabile. Per confrontare i segnali di riferimento e quelli degradati, entrambi i segnali sono allineati nel tempo l’uno con l’altro. PESQ allinea le sezioni sovrapposte dei fotogrammi vocali. Nella prima fase, la stima del ritardo viene effettuata sulla lunghezza dei file calcolando la correlazione tra i file. Il ritardo ottenuto in questa fase è chiamato ritardo grezzo. Nella fase successiva, PESQ applica il rilevamento dell’attività vocale ai segnali per identificare i segmenti vocali richiesti solitamente indicati come enunciati. La stima del ritardo tra le espressioni è il ritardo fine. Questo processo rileva il ritardo che è variabile sulla lunghezza di un enunciato, in quanto questo può essere significativo nelle reti basate su pacchetti.
I segnali di riferimento allineati nel tempo e degradati vengono trasformati nel dominio della frequenza utilizzando una trasformata di Fourier veloce a breve termine (FFT) con una finestra di Hanning su fotogrammi di 32 ms con sovrapposizione del 50%. Le potenze dei segnali originali e degradati sono calcolate e memorizzate separatamente. Nella fase successiva delle operazioni, le bande di frequenza vengono trasformate in scala di corteccia binning bande FFT. Questo processo deforma la scala di frequenza in Hz alla scala del passo e i segnali risultanti sono chiamati densità di potenza del passo. In questo processo, una maggiore larghezza di banda viene utilizzata per un segnale ad alta frequenza derivato attraverso l’analisi della frequenza.
Gli effetti di filtraggio nel sistema in esame sono equalizzati calcolando un fattore di compensazione parziale per ogni contenitore di corteccia e moltiplicando ogni frame del segnale di riferimento con questo fattore. Questo processo equalizza il riferimento al segnale degradato. Il fattore di compensazione è calcolato come il rapporto tra lo spettro del segnale degradato e lo spettro del segnale di riferimento. Questo fattore tiene conto del filtraggio a componenti analogici della rete come telefoni cellulari. Nella seconda fase di equalizzazione, il guadagno di ampiezza fotogramma per fotogramma
del sistema viene stimato e utilizzato per equalizzare il segnale degradato al segnale di riferimento. In entrambi i casi, l’equalizzazione è parziale e grandi quantità di filtraggio o variazione di guadagno non vengono annullate; pertanto, si traduce in errori da misurare. La frequenza e le densità di potenza del passo equalizzate dal guadagno vengono trasformate in scala del volume usando la legge di Zwicker . I componenti tempo-frequenza risultanti sono chiamati densità di volume.
La differenza tra le densità di volume per i segnali di riferimento e degradati è nota come densità di disturbo grezzo, che mostra eventuali differenze udibili introdotte dal sistema in prova. Un’operazione di mascheramento applica un fattore maschera sulle densità di disturbo grezze che maschera le piccole distorsioni non udibili in presenza di segnali forti. La densità di disturbo ottenuta da questo processo è chiamata densità di disturbo assoluta o simmetrica. I disturbi simmetrici sono integrati sulla lunghezza del telaio (intraframe). I fotogrammi consecutivi con un disturbo del fotogramma al di sopra di una soglia sono classificati come fotogrammi non validi. I fotogrammi difettosi possono verificarsi a causa di una stima errata del ritardo o di cadute di pacchetti. In una finestra localizzata attorno a fotogrammi danneggiati, viene effettuata una nuova stima del ritardo che viene utilizzata per ricalcolare le densità di disturbo. Il minimo dei disturbi precedenti e attuali è considerato come il disturbo finale in quella finestra di frame male.
Per modellare la distorsione introdotta dal codec utilizzato nella rete, si calcola una densità di disturbo asimmetrico moltiplicando la densità di disturbo simmetrico con un fattore di asimmetria. Il fattore di asimmetria è il rapporto tra le densità di potenza del passo distorte e quelle originali elevate alla potenza di 1.2. Questa densità di disturbo è chiamata disturbo additivo o asimmetrico.
Infine, i parametri di errore vengono convertiti in un punteggio di qualità, che è una combinazione lineare del valore di disturbo simmetrico medio e del valore di disturbo asimmetrico medio. Da Fig. 20.2, gli stadi coinvolti dall’allineamento del livello alla deformazione dell’intensità sulla scala del volume sono noti come la conversione al dominio psico – acustico e gli stadi algoritmici dalla sottrazione percettiva al calcolo del punteggio PESQ sono noti come modellazione cognitiva.
PESQ dà un punteggio noto come il punteggio PESQ in conformità a P. 862. Il punteggio PESQ è compreso tra -0,5 e 4,5. PESQ è correlato al MOS soggettivo come 0.94 sulla base di esperimenti condotti su database da . Rispetto ai punteggi soggettivi (ascoltatori effettivi), PESQ dà risultati migliori per un discorso di scarsa qualità e risultati pessimistici per una voce di buona qualità. PESQ-LQ fornisce una migliore correlazione con i punteggi soggettivi di PESQ su una scala di qualità di ascolto. I punteggi PESQ-LQ sono compresi tra 1 e 4,5. P862.1 fornisce una mappatura di qualità tra le misure di qualità a banda stretta PESQ score e qualità di ascolto obiettivo media opinione score (MOS-LQO). Raccomandazione P. 862.2 fornisce una mappatura della qualità tra le misure di qualità a banda larga punteggio PESQ e qualità di ascolto punteggio medio obiettivo opinione. Maggiori informazioni su questi punteggi possono essere trovate nelle raccomandazioni della serie ITU – T-P. 862 e in riferimento .
PESQ è un’operazione half-duplex che non cattura con precisione il ritardo end-to-end, eco, perdita di volume, sidetone, e livelli di ascolto. Dalla misurazione della qualità vocale del gateway VoIP con interfacce analogiche, le seguenti osservazioni PESQ-LQO vengono effettuate utilizzando DSLA . In assenza di perdita di pacchetti, il punteggio PESQ-LQO per il codec G. 711 è 4.32, G. 729A è 3.85 e G. 723.1 è 3.75. Un’altra interpretazione di questi risultati per le situazioni di caduta dei pacchetti e il confronto con il modello E sono forniti come parte dei calcoli del fattore R e presentati nella tabella 20.4. Nel processo di calcoli PESQ, è possibile calcolare diversi altri parametri. I fornitori di strumenti forniscono questi parametri come funzionalità aggiuntive per le misurazioni PESQ .
20.1.4
Tecnica di monitoraggio passivo
I n tecniche di monitoraggio passivo, il segnale di riferimento non è presente. Esistono due metodi popolari per il monitoraggio passivo della qualità vocale. L’ITU ha standardizzato un metodo di monitoraggio non intrusivo basato sul segnale, P. 563, basato sul risultato della collaborazione tra tre società, Psytechnics Ltd., Swissqual e Opticom, che combinavano i migliori parametri di tre diversi modelli. P. 563 è una misurazione oggettiva single-ended che fa uso di un meccanismo di produzione vocale, e gli altri modelli vocali fanno uso della percezione dell’ascolto. Questo algoritmo funziona solo sul discorso degradato ricevuto. Non avrà bisogno di un discorso di riferimento e opera interamente su un discorso degradato. Le misurazioni attraverso P.563 derivano diversi parametri dal discorso ricevuto classificato come rumore, discorso artificiale e discorso reale. Una panoramica sull’operazione di valutazione della qualità vocale single-ended P. 563 è riportata qui.
In assenza di un segnale di riferimento, i modelli non hanno conoscenza del segnale originale e devono essere fatte ipotesi sul segnale ricevuto. Il modello P. 563 combina tre principi di base per la valutazione delle distorsioni. Il primo principio si concentra sul sistema di produzione della voce umana, modellando il tratto vocale come una serie di tubi, con variazioni anomale delle sezioni dei tubi considerate come degradazione. Il secondo principio consiste nel ricostruire un segnale di riferimento pulito dal segnale degradato per applicare successivamente un modello percettivo di riferimento completo e valutare le distorsioni smascherate durante la ricostruzione. Il terzo principio è quello di identificare e stimare le distorsioni specifiche incontrate nei canali vocali, come il ritaglio temporale, la robotizzazione e il rumore. La qualità del discorso di ascolto deriva dai parametri calcolati dai tre principi, applicando una ponderazione dipendente dalla distorsione.
Durante la scrittura di questo argomento, la tecnica basata su P. 563 non è stata ampiamente accettata per le misurazioni. P. 862 Le misurazioni basate su PESQ e le stime basate su E-model sono più comunemente accettate. Il vantaggio principale di questa tecnica P. 563 è la sua capacità di monitorare all’estremità degradata senza chiamare per riferimento. Pertanto, può monitorare meglio le chiamate a lunga distanza al di fuori del laboratorio e nelle distribuzioni, che saranno molto più semplici da condurre rispetto a molte altre misurazioni. Il metodo basato su P. 563 può anche essere incorporato come parte
del gateway di ricezione simile a E-model e RTCP-XR. Le operazioni P. 563 possono essere utilizzate su campioni che vengono consegnati sulle interfacce vocali pulse Code modulation (PCM).
Maggiori informazioni sulla tecnica P. 563 possono essere trovate da P. 563 e . Il punteggio MOS prodotto da P.563 e altre tecniche è ampiamente diffuso ed è necessario per la media dei risultati di più test per ottenere una metrica di qualità stabile su più risultati. P. 563 è correlato con MOS soggettivo come 0.85 a 0.9 sulla base degli esperimenti condotti su un database da, e PESQ è riportato come 0.94.