20.1
for at sammenligne stemmekvaliteten og nå frem til de parametre, der bidrager til stemmekvaliteten, er det nødvendigt at vide, hvordan stemmekvaliteten måles, og hvad er kvalitetsmålene. Den grundlæggende testopsætning til VoIP-stemmemålinger er angivet i emne 13. I dette emne diskuteres stemmekvalitet som gennemsnitlige opinionsresultater (MOS), forskellige klassifikationer, stemmekvalitet, der påvirker parametre og forbedringer. Stemmekvalitetsmålinger for MOS klassificeres som subjektive og objektive.
en funktionel repræsentation af nogle populære stemmekvalitetsmålingsteknikker er illustreret i Fig. 20.1 . I figuren er stemmen vist at være fra
tabel 20.1. PSTN og VoIP kvalitet sammenligninger
| attributter | PSTN | VoIP |
| forvrængninger på | forvrængninger på grund af flere | ingen analog transmission |
| analog linje | 1000-fødder linjer fra | forvrængninger med VoIP-opkald. |
| DLC eller CO placering | ||
| ekko annullering | opnået gennem tab | ekko cancellers |
| på nationale opkald | planlægning og lave forsinkelser | anvendes. |
| automatisk forstærkning | ikke inkorporeret | muligt at inkorporere for |
| kontrol | bedre opfattelse af tale | |
| niveauer eller lyttekvalitet | ||
| erfaring. | ||
| stemmekvalitet | overvågning som GR- | RTCP – RR og GR – 909 er |
| overvågning | 909 er indarbejdet | indarbejdet i mange VoIP |
| i PSTN | implementeringer. | |
| båndbredde eller bit | 64 kbps fast på digital | variabel båndbredde, normalt |
| Sats | TDM. Dcme kanaler | kræver mere på fysisk |
| brug 16, 24, 32 og | grænseflader end PSTN. Helle | |
| 40 | tjenester kan få mere | |
| kvalitet | båndbredde eller redundans i | |
| transmission. | ||
| opkald | ydeevne begrænset af | bruger korte slutlinjer. Derfor |
| end transmissionsledning | levering kan være bedre ved hjælp af | |
| egenskaber | VoIP. Der kunne dog | |
| være interoperabilitetsproblemer for | ||
| sender Faks. | ||
| stemme og data | hovedsagelig til taleopkald, | Internet service og VoIP kan |
| nogle tjenester kan genbruge | skala sammen med data og | |
| talekanaler til data | krav til medietjeneste. | |
| Taleopkaldsfunktioner | begrænsede funktioner og | flere funktioner tilbydes som |
| dyrt for flere | gratis. | |
| service funktioner | ||
| Stemmegrænseflader | begrænsede grænseflader | flere grænseflader og tjenester. |
| lang afstand | lang afstand er dyrt | normalt gratis eller meget lavere |
| priser. | ||
| Transcoding | flere niveauer af | End – to – end direkte kodning kan være |
| transcoding for inter- | anvendt baseret på | |
| regionale opkald | tilgængelig support. | |
| Bredbåndsstøtte | taleopkald er af | bredbånd ende-til-ende stemme er |
| smalbånd | muligt, der kan overstige | |
| PSTN kvalitet. |
den afsendende port til den modtagende Port. Modtagerporten vises med nogle mere udvidede blokke for at skabe et stort billede af E-modellen, som bruges til R-faktor estimering, yderligere kvalitetsmålinger og realtids Transportkontrolprotokol-udvidede rapporter (RTCP-RR) drift. I E-modellen anvendes RTP, RTCP, jitter buffer og total system signal parametre. Når man beregner R-faktoren og andre afledte parametre,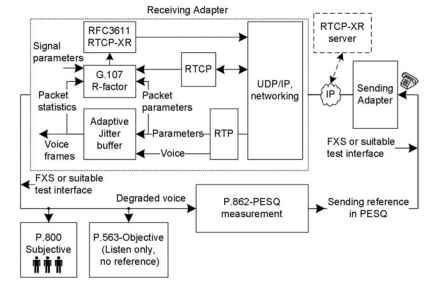
figur 20.1. Oversigt over populære talekvalitetsmålinger.
RTCP-RTCP kan sende pakker til de interne applikationer, destinationsporten og RTCP-RTCP-serveren. Sammenfattende er den ikke-påtrængende R-faktor et objektivt skøn, der findes som en del af VoIP-implementeringen, og der kræves yderligere programmer i porten til R-faktorestimeringen. Ved perceptuel evaluering af talekvalitet sender instrumenter som MultiDSLA referencetalen gennem VoIP-systemet under test og evaluerer det forringede med referencetalen. Denne måling er aktiv, og VoIP-porte behøver ikke at vide noget om målingen. I subjektiv lytning vil flere lyttere evaluere stemmekvaliteten. I P. 563 analyseres stemmen udelukkende på det modtagne forringede signal, og den oprindelige reference er ikke påkrævet. P. 563 ligner subjektiv lytning, men den evalueres af instrumenterne eller processorerne. Hver af disse teknikker ankommer til en anden skala af stemmekvalitet. I et VoIP-taleopkald mellem A og B foretages stemmemålinger som halv dupleks, hvilket betyder, at målinger foretages som A til B eller B til A, en ad gangen. På grund af den halve dupleks lytningstype af test kaldes disse målinger lyttekvalitetstest. Suffikset er tilføjet, mens resultaterne præsenteres på halv-dupleksprøver, og objektive tests er desuden suffikset med “O” som LCO.
20.1.1
subjektiv måleteknik
i subjektiv stemmekvalitetsevaluering vurderes stemmekvalitet MOS af gruppen af faktiske mandlige og kvindelige lyttere. Det er den egentlige lyttetest til evaluering af MOS. P. 800 og P. 830 anbefalingerne bruges til at vurdere den subjektive præstation af tale
codecs. De samme tests udvides til VoIP-stemmekvaliteten. En gruppe mennesker deltager i registrering af subjektive scoringer. Flere testfraser registreres, og derefter lytter testpersoner (gruppe af mennesker) til dem under forskellige forhold. Disse tests udføres i specielle rum med baggrundsstøj, og andre miljøfaktorer holdes under kontrol til testudførelse. Testbetingelserne er angivet i . De subjektive måleteknikker er kategoriseret som absolut kategori rating (ACR), nedbrydning kategori rating (DCR) og sammenligning kategori rating (CCR).
i n ACR, deltagerne lytter til optagede taleprøver, der er blevet behandlet gennem flere testforbindelser. Mindst 16 testpersoner (lyttere) skal deltage i vurderingen. Når du lytter, vurderer brugerne opkaldet på en 1 til 5 MOS skala. Gennemsnitsværdierne for brugerbedømmelserne anses for at generere den samlede opkaldskvalitet.
i en DCR-test er der to taleprøver til stede. Den første taleprøve er en referenceprøve med foruddefineret kvalitet. Prøven her refererer til tale, der varer i flere sekunder i varighed. Den anden taleprøve er en forringet version. Lyttere skal sammenligne den forringede version med en reference på en nedbrydningsskala på 1 til 5. Her er 5 uhørlig nedbrydning, og 1 repræsenterer værste nedbrydning. Resultaterne opsummeres som forringet MOS.
i CCR-test bliver brugerne bedt om at lytte til to sæt prøver, den ene svarer til reference og den anden til nedbrudt. Denne test ligner DCR, bortset fra at rækkefølgen af prøver, der præsenteres for lytterne, ændres i forskellige iterationer. Rækkefølgen af reference og forringet er ikke erklæret for lytteren. Lyttere bliver bedt om at give en sammenlignende vurdering af en anden prøve i forhold til den første på en skala fra -3 til 3 i henhold til P. 800 bilag-D . Ved præsentationen af resultaterne repræsenterer “3 “meget bedre kvalitet, og” -3 ” repræsenterer den værste kvalitet i relativ skala. Kvalitetsresultatet er kortlagt til MOS. Den tilladte MOS-rating er 1 til 5, men en brugerbedømmelse over 4,5 er begrænset til 4,5.
subjektive tests er involveret i procedurer, og det er en kostbar indsats. Det er begrænset til mindre iterationer for at evaluere enhver ny algoritme eller talekodeker. Det er vanskeligt at opretholde konsistens som instrumentbaserede objektive tests.
20.1.2
Målmålingsteknikker
objektive metoder er målinger og beregninger. Det forventes, at resultaterne vil være konsistente på tværs af flere målinger. Der findes flere objektive metoder og klassificeres som aktive og passive metoder.
• aktive overvågningsteknikker
• Passive overvågningsteknikker af P. 563 og E-modellen
aktive overvågningsteknikker. Aktiv måling kaldes påtrængende overvågning eller offline overvågning på grund af involvering af eksterne signaler.
i et forsøg på at supplere subjektiv lyttekvalitet udvikles test med lavere omkostninger objektive metoder. KPN udviklede P. 861 (dette er forældet nu) perceptuel talekvalitetsmåling (PSKVM) til evaluering af codec-ydeevne. British Telecom udviklede perceptual analysis measurement system (PAMS) til netværksmålinger. P. 862 var resultatet af en ITU-konkurrence. Udførelsen af PAMS og en ny version af PSKVM, PSKVM99, var ens, så bidragyderne blev inviteret til at kombinere algoritmerne. Dette resulterede i PESKS, hvilket er lidt bedre end dets bestanddele.
disse metoder måler forvrængning indført af et transmissionssystem og codec ved at sammenligne en original referencefil sendt til systemet på en telefongrænseflade med det modtagne forringede signal modtaget på en anden telefongrænseflade. PSKVM blev udviklet til laboratorietest af talekodeker. PAMS og PESKS er designet til netværkstest. Brugen af instrumenter til stemmekvalitet er meget enklere sammenlignet med subjektive eller passive målinger. Instrumentleverandører leverer også de ekstra afledte parametre, der hjælper med at identificere nedbrydningskilderne gennem målinger. Se nogle instrumenter i emne 13 for flere detaljer om forskellige funktioner.
mens du skriver dette emne, blev PESKS populært understøttet i instrumenterne. ITU godkendte i marts 2001 P. 862-anbefalingen, der erstattede P.861 PSKVM. PESKS kombinerede flere bedste fordele ved PAMS og PSKVM. Det er nøjagtigt til at forudsige subjektive testresultater, og det er robust under svære netværksforhold, såsom variable forsinkelser, filtrering ved analoge grænseflader og understøttelse af både bredbånd og smalbånd. En score, der ligger på en skala fra -0,5 til 4,5. En kortlægning funktion fra en P. 862 PESKV score til en gennemsnitlig subjektiv P. 800-LKK MOS score blev leveret, hvilket gør det
PESKVK for smalbånd stemme. LCO betegner et mål for lyttekvalitet. Fra 1 til 4,5. En MOS af 4.5 er den maksimale kvalitet, der opnås for en klar uforvrænget tilstand. En oversigt over pesks algoritme er givet her. Det foreslås at henvise til ITU P. 862 – familien af anbefalinger, programmer og nogle kommercielle instrumentbrochurer for flere detaljer .
20.1.3
Peskv måling
menneskelig auditiv perception er kernekonceptet bag PESKV og dets forgængere PAMS og PSKVM. En perceptuel model bruges til at skelne korrekt mellem hørbare og uhørlige forvrængninger, og dette har vist sig at være den bedste måde at nøjagtigt forudsige hørbarhed og irritation af komplekse forvrængninger. Ud over mængden af forvrængning kunne fordelingen af hørbar forvrængning gøre kvalitetsforudsigelser meget mere nøjagtige.
PESKV måler envejs stemmekvalitet, hvilket betyder halv-dupleksdrift af måling. Det vurderer kvaliteten af et forvrænget talesignal, der er kodet og transmitteret over netværket ved at sammenligne det med det originale uforvrængede signal. Den originale og forvrængede tale er kortlagt til psykofysiske repræsentationer, der matcher den måde, mennesker oplever tale på.
kvaliteten af den forvrængede tale bedømmes ud fra forskelle i psykofysiske repræsentationer. Der er to hovedklasser af logaritmiske operationer, nemlig konvertering af signaler til det psykoakustiske domæne og kognitiv modellering. En funktionel repræsentation af PESKS algoritme er angivet i Fig. 20.2. Instrumentproducenter til måling af PESKV inkluderer flere ekstra operationer til at udtrække signalanalyseparametre og svækkelser ud over PESKV-målinger.
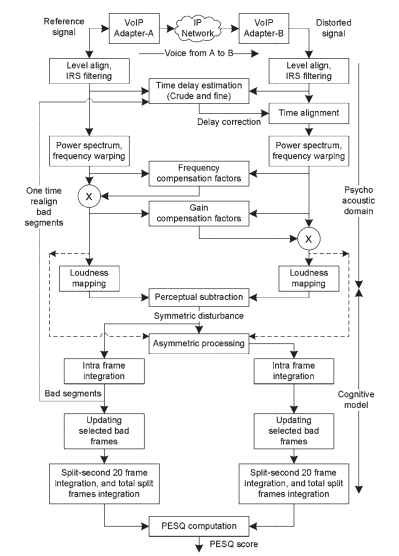
figur 20.2. Algoritme funktionelle repræsentationer.
den behandling, der udføres af PESKS algoritme, omfatter nedenstående trin. Sammendrag trin er givet her; flere detaljer om PESKS er givet i .
i det første trin i behandlingen skaleres både referencen og det nedbrudte signal til det samme konstante effektniveau. Denne skalering er nødvendig, fordi referencesignalet ikke behøver at være på et defineret niveau, og forstærkningen af systemet under test er ukendt før test. Det subjektive lytteniveau er en konstant 79 dBSPL ved øreferencepunktet . Til effekt normalisering normaliseres elektriske signalniveauer til-26dbov (dvs.- 20dBm som angivet i referencen). En normalisering af signalniveau anvendes på både referencen og det forringede signal for at bringe dem til dette niveau.
perceptuelle modeller som f.eks. Håndsættets modtagebane modelleres ved hjælp af et intermediate reference system (IRS) båndpasfilter i frekvensdomænet. Denne proces tager højde for virkningerne af håndsættets elektriske og akustiske komponenter. Både referencen og det nedbrudte signal er IRS filtreret.
det testede system kan omfatte variabel forsinkelse. For at sammenligne reference-og nedbrudte signaler er begge signaler tidsjusteret med hinanden. Peskv justerer overlappende dele af talerammerne. I første fase udføres forsinkelsesestimeringen over længden af filer ved at beregne sammenhængen mellem filerne. Forsinkelsen opnået i dette trin kaldes rå forsinkelse. I det næste trin anvender PESKV stemmeaktivitetsdetektering på signalerne for at identificere krævede talesegmenter, der normalt kaldes udtryk. Forsinkelsesestimatet mellem udtryk er den fine forsinkelse. Denne proces registrerer forsinkelse, der er variabel over længden af et udtryk, da dette kan være signifikant i pakkebaserede netværk.
den tidsjusterede reference og nedbrudte signaler omdannes til frekvensdomænet ved hjælp af en kortvarig fast Fourier-transformation (FFT) med et Hanning-vindue over 32 ms-Rammer med 50% overlappende. Kræfterne for originale og nedbrudte signaler beregnes og lagres separat. I den næste fase af operationer omdannes frekvensbåndene til barkskala ved at binde FFT-bånd. Denne proces vrider frekvensskalaen i HS til tonehøjdeskalaen, og de resulterende signaler kaldes tonehøjdekrafttætheder. I denne proces anvendes højere båndbredde til et højfrekvent signal afledt gennem frekvensanalyse.
filtreringseffekterne i det testede system udlignes ved at beregne en delvis kompensationsfaktor pr. Denne proces udligner henvisningen til det forringede signal. Kompensationsfaktoren beregnes som forholdet mellem nedbrudt signalspektrum og referencesignalspektrum. Denne faktor tager højde for filtreringen ved analoge komponenter i netværket, såsom telefonhåndsæt. I det andet trin af udligning estimeres frame-by-frame amplitude
forstærkning af systemet og bruges til at udligne det nedbrudte signal til referencesignalet. I begge tilfælde er udligningen delvis, og store mængder filtrering eller forstærkningsvariation annulleres ikke; derfor resulterer det i, at fejl måles. Frekvensen og forstærkningsudlignet tonehøjdekrafttætheder omdannes til lydstyrkeskala ved hjælp af GVM ‘ s lov . De resulterende tidsfrekvenskomponenter kaldes loudness densities.
den underskrevne forskel mellem loudness densities for reference og nedbrudte signaler er kendt som rå forstyrrelse tæthed, som viser eventuelle hørbare forskelle indført af systemet under test. En maskeringsoperation anvender en maskefaktor på de rå forstyrrelsesdensiteter, der maskerer de små uhørlige forvrængninger i nærvær af høje signaler. Forstyrrelsestætheden opnået ved denne proces kaldes absolut eller symmetrisk forstyrrelsestæthed. De symmetriske forstyrrelser er integreret over rammens længde (intraframe). De på hinanden følgende rammer med en rammeforstyrrelse over en tærskel er kategoriseret som dårlige rammer. De dårlige rammer kan opstå på grund af forkert estimering af tidsforsinkelse eller pakkedråber. På et lokaliseret vindue omkring dårlige rammer foretages et nyt forsinkelsesestimat, der bruges til at beregne forstyrrelsestæthederne igen. Minimumet af tidligere og nuværende forstyrrelser betragtes som den endelige forstyrrelse i det dårlige rammevindue.
for at modellere den forvrængning, der indføres af codec, der anvendes i netværket, beregnes en asymmetrisk forstyrrelsesdensitet ved at multiplicere den symmetriske forstyrrelsesdensitet med en asymmetrifaktor. Asymmetrifaktoren er forholdet mellem forvrænget og de oprindelige tonehøjdekrafttætheder hævet til kraften på 1,2. Denne forstyrrelsesdensitet kaldes en additiv eller asymmetrisk forstyrrelse.
endelig konverteres fejlparametrene til et kvalitetsresultat, som er en lineær kombination af den gennemsnitlige symmetriske forstyrrelsesværdi og den gennemsnitlige asymmetriske forstyrrelsesværdi. Fra Fig. 20.2, er de involverede faser fra niveaujustering til intensitetsvridning på lydstyrkeskalaen kendt som konvertering til det psykoakustiske domæne, og de algoritmiske stadier fra perceptuel subtraktion til beregning af PESKSCORE er kendt som kognitiv modellering.
PESKV giver en score kendt som PESKVU score i overensstemmelse med P. 862. PESKS score ligger i intervallet -0,5 til 4,5. 0,94 baseret på eksperimenter udført på databaser af . Sammenlignet med subjektive (faktiske lyttere) scoringer giver PESKS bedre resultater for tale af dårlig kvalitet og pessimistiske resultater for stemme af god kvalitet. Det giver bedre korrelation med subjektive scoringer end på en lyttekvalitetsskala. Der er mellem 1 og 4,5 point. P862. 1 giver en kvalitetskortlægning mellem smalbåndskvalitetsmålinger PESKSCORE og lyttekvalitetsmål mean opinion score (MOS-LCO). Anbefaling P. 862.2 giver en kvalitetskortlægning mellem bredbåndskvalitetsmålinger PESKSCORE og lyttekvalitetsmål gennemsnitlig meningsscore. Flere oplysninger om disse scoringer findes i ITU-T-P. 862-seriens anbefalinger og i reference .
PESKV er en halv dupleks operation, der ikke vil fange nøjagtigt på end-to-end forsinkelse, ekko, loudness tab, sidetone og lytte niveauer. Fra Stemmekvalitetsmåling af VoIP-porten med analoge grænseflader foretages følgende PESKOOBSERVATIONER ved hjælp af dsla . Under ingen pakketab betingelse er pesko-score for G. 711 codec 4.32, G. 729A er 3.85, og G. 723.1 er 3.75. En anden fortolkning af disse resultater for pakkefaldssituationer og sammenligning med E-modellen er givet som en del af R-faktorberegningerne og præsenteret i tabel 20.4. I forbindelse med PESKS beregninger kan flere andre parametre beregnes. Instrumentleverandører leverer disse parametre som ekstra funktioner til PESKMÅLINGER .
20.1.4
passiv Overvågningsteknik
I n passive overvågningsteknikker, referencesignalet er ikke til stede. Der findes to populære metoder til passiv overvågning af talekvalitet. ITU har standardiseret en signalbaseret ikke-påtrængende overvågningsmetode, P. 563, baseret på resultatet af samarbejde mellem tre virksomheder, Psytechnics Ltd. Opticom, som kombinerede de bedste parametre for tre forskellige modeller. P. 563 er en målmåling med en enkelt ende, der gør brug af en taleproduktionsmekanisme, og de andre talemodeller gør brug af lytteopfattelse. Denne algoritme fungerer kun på modtaget forringet tale. Det behøver ikke reference tale, og det fungerer helt på forringet tale. Målingerne gennem P.563 udlede flere parametre fra modtaget tale klassificeret som støj, kunstig tale og faktisk tale. En oversigt over P. 563 single-ended tale-kvalitetsvurderingsoperationen er givet her.
i mangel af et Referencesignal har modellerne ikke kendskab til det oprindelige signal, og der skal antages antagelser om det modtagne signal. P. 563-modellen kombinerer tre grundlæggende principper for evaluering af forvrængninger. Det første princip fokuserer på det menneskelige stemmeproduktionssystem og modellerer vokalkanalen som en række rør med unormale variationer af rørets sektioner betragtes som nedbrydning. Det andet princip er at rekonstruere et rent Referencesignal fra det forringede signal for derefter at anvende en fuld reference perceptuel model og vurdere forvrængninger, der ikke er maskeret under genopbygningen. Det tredje princip er at identificere og estimere specifikke forvrængninger, der opstår i stemmekanaler, såsom tidsmæssig klipning, robotisering og støj. Lytte talekvalitet er afledt af de beregnede parametre fra de tre principper, der anvender en forvrængningsafhængig vægtning.
mens du skriver dette emne, blev den P. 563-baserede teknik ikke bredt accepteret til målinger. P. 862 PESKV-baserede målinger og e-model-baserede estimater accepteres mere populært. Den største fordel ved denne P. 563-teknik er dens evne til at overvåge ved den forringede ende uden at kræve reference. Det kan således bedre overvåge langdistanceopkald uden for laboratoriet og i implementeringer, hvilket vil være meget enklere at udføre end mange andre målinger. Den P. 563-baserede metode kan også indlejres som en del
af modtagerporten svarende til E-model og RTCP-RTCP. P. 563-operationer kan bruges på prøver, der leveres på pulse code modulation (PCM) stemmegrænseflader.
flere oplysninger om P. 563 teknik kan findes fra P. 563 og . MOS score produceret af P.563 og andre teknikker er bredt spredt og er nødvendige for at gennemsnitlige resultaterne af flere tests for at opnå en stabil kvalitetsmåling over flere resultater. P. 563 er korreleret med subjektiv MOS som 0,85 til 0,9 baseret på eksperimenterne udført på en database af , og PESKS rapporteres som 0,94.