20.1
para comparar a qualidade da voz e chegar aos parâmetros que contribuem para a qualidade da voz, é necessário saber como a qualidade da voz é medida e quais são os objetivos de qualidade. A configuração básica do teste para medições de voz VoIP é fornecida no tópico 13. Neste tópico, a qualidade da voz como escores médios de opinião (MOS), várias classificações, parâmetros de influência da qualidade da voz e melhorias são discutidas. As medidas de qualidade de voz para MOS são classificadas como subjetivas e objetivas.
uma representação funcional de algumas técnicas populares de medição da qualidade da voz é ilustrada na Fig. 20.1 . Na figura, a voz é mostrada a partir de
- tabela 20.1. PSTN e VoIP de Qualidade Comparações
- técnica de medição subjetiva
- técnicas de medição objetiva
- a percepção auditiva humana é o conceito central por trás do PESQ e de seus antecessores PAMS e PSQM. Um modelo perceptivo é usado para distinguir corretamente entre distorções audíveis e inaudíveis, e esta provou ser a melhor maneira de prever com precisão a audibilidade e o aborrecimento de distorções complexas. Além da quantidade de distorção, a distribuição da distorção audível poderia tornar as previsões de qualidade muito mais precisas.PESQ mede a qualidade de voz unidirecional, o que significa a operação half-duplex de medição. Ele avalia a qualidade de um sinal de fala distorcido que foi codificado e transmitido pela rede, comparando-o com o sinal original não distorcido. A fala original e distorcida é mapeada para representações psicofísicas que correspondem à maneira como os humanos experimentam a fala.A qualidade da fala distorcida é julgada com base nas diferenças nas representações psicofísicas. A operação PESQ faz uso de duas classes principais de operações logarítmicas – a saber, conversão de sinais no domínio psicoacústico e modelagem cognitiva. Uma representação funcional do algoritmo PESQ é dada na Fig. 20.2. Os fabricantes de instrumentos para a medição PESQ incluem várias operações extras para extrair parâmetros de análise de sinal e deficiências, além das medições PESQ. figura 20.2. Representações funcionais do algoritmo PESQ.o processamento realizado pelo algoritmo PESQ inclui as etapas listadas abaixo. As etapas de resumo são fornecidas aqui; vários detalhes sobre o PESQ são fornecidos . na primeira etapa do processamento, tanto a referência quanto o sinal degradado são dimensionados para o mesmo nível de potência constante. Essa escala é necessária porque o sinal de referência não precisa estar em um nível definido e o ganho do sistema em teste é Desconhecido antes do teste. PESQ assume que o nível subjetivo de escuta é uma constante de 79 dBSPL no ponto de referência do ouvido . Para normalização de potência, os níveis de sinal elétrico são normalizados para-26dBov (ou seja,- 20dBm conforme dado na referência ). Uma normalização do nível do sinal é aplicada tanto à referência quanto ao sinal degradado para trazê-los para esse nível.modelos perceptivos como o PESQ devem levar em consideração as características dos aparelhos telefônicos, pois a escuta subjetiva pode usar aparelhos telefônicos. No PESQ, o caminho de recepção dos aparelhos é modelado usando um sistema de referência intermediário (IRS) filtro de passagem de banda no domínio de frequência. Este processo leva em conta os efeitos dos componentes elétricos e acústicos do aparelho. Tanto a referência quanto o sinal degradado são filtrados pelo IRS. o sistema em teste pode incluir atraso variável. Para comparar os sinais de referência e degradados, ambos os sinais são alinhados com o tempo um com o outro. PESQ alinha seções sobrepostas dos quadros de fala. Na primeira etapa, a estimativa de atraso é realizada ao longo do comprimento dos arquivos, computando a correlação entre os arquivos. O atraso obtido nesta fase é chamado de atraso bruto. No próximo estágio, o PESQ aplica a detecção de atividade de voz aos sinais para identificar os segmentos de fala necessários, geralmente chamados de enunciados. A estimativa de atraso entre enunciados é o atraso fino. Esse processo detecta um atraso que é variável ao longo do comprimento de um enunciado, pois isso pode ser significativo em redes baseadas em pacotes.a referência alinhada pelo tempo e os sinais degradados são transformados no domínio da frequência usando uma transformação rápida de Fourier de curto prazo (FFT) com uma janela de abertura sobre quadros de 32 ms com sobreposição de 50%. Os poderes dos sinais originais e degradados são calculados e armazenados separadamente. No próximo estágio de operações, as bandas de frequência são transformadas em escala de casca binning FFT bandas. Este processo distorce a escala de frequência em Hz para a escala de pitch, e os sinais resultantes são chamados de densidades de potência de pitch. Nesse processo, maior largura de banda é usada para um sinal de alta frequência derivado por meio da análise de frequência.os efeitos de filtragem no sistema em teste são equalizados computando um fator de compensação parcial por cada escaninho de casca e multiplicando cada quadro do sinal de referência com este fator. Este processo equaliza a referência ao sinal degradado. O Fator de compensação é calculado como a razão entre o espectro de sinal degradado e o espectro de sinal de referência. Esse fator leva em consideração a filtragem em componentes analógicos da rede, como aparelhos telefônicos. No segundo estágio de equalização, O ganho de amplitude quadro a quadrodo sistema é estimado e usado para equalizar o sinal degradado ao sinal de referência. Em ambos os casos, a equalização é parcial e grandes quantidades de filtragem ou variação de ganho não são canceladas; portanto, resulta em erros sendo medidos. As densidades de potência de passo equalizadas por frequência e ganho são transformadas em escala de volume usando a lei de Zwicker . Os componentes de frequência de tempo resultantes são chamados de densidades de volume. a diferença assinada entre as densidades de volume para os sinais de referência e degradados é conhecida como densidade de perturbação bruta, que mostra quaisquer diferenças audíveis introduzidas pelo sistema em teste. Uma operação de mascaramento aplica um fator de máscara nas densidades de perturbação bruta que mascara as pequenas distorções inaudíveis na presença de sinais altos. A densidade de perturbação obtida por este processo é chamada densidade de perturbação absoluta ou simétrica. Os distúrbios simétricos são integrados ao longo do comprimento do quadro (intraframe). Os quadros consecutivos com um distúrbio de quadro acima de um limite são categorizados como quadros ruins. Os quadros ruins podem ocorrer devido à estimativa incorreta de atraso de tempo ou quedas de pacotes. Em uma janela localizada em torno de quadros ruins, é feita uma nova estimativa de atraso usada para recomputar as densidades de perturbação. O mínimo dos distúrbios anteriores e atuais é considerado como o distúrbio final nessa janela de quadro ruim. para modelar a distorção introduzida pelo codec usado na rede, uma densidade de perturbação assimétrica é calculada multiplicando a densidade de perturbação simétrica por um fator de assimetria. O Fator de assimetria é a proporção de densidades de potência de passo distorcidas e originais elevadas à potência de 1,2. Essa densidade de perturbação é chamada de perturbação aditiva ou assimétrica.por fim, os parâmetros de erro são convertidos em um escore de qualidade, que é uma combinação linear do valor médio de perturbação simétrica e do valor médio de perturbação assimétrica. Da Fig. 20.2, os estágios envolvidos desde o alinhamento de nível até a deformação de intensidade na escala de volume são conhecidos como a conversão para o domínio psico – acústico, e os estágios algorítmicos da subtração perceptiva à computação de pontuação PESQ são conhecidos como modelagem cognitiva. PESQ dá uma pontuação conhecida como pontuação PESQ de acordo com P. 862. A pontuação do PESQ está na faixa de -0,5 a 4,5. PESQ está correlacionado com o MOS subjetivo como 0,94 com base em experimentos realizados em bancos de dados por . Comparado com as pontuações subjetivas (ouvintes reais), O PESQ fornece melhores resultados para fala de baixa qualidade e resultados pessimistas para voz de boa qualidade. PESQ-LQ fornece melhor correlação com pontuações subjetivas do que PESQ em uma escala de qualidade de audição. As pontuações PESQ-LQ estão na faixa de 1 a 4,5. P862. 1 fornece um mapeamento de qualidade entre medições de qualidade de banda estreita pontuação PESQ e qualidade de audição pontuação média de opinião objetiva (mos-LQO). Recomendação P. 862. 2 fornece um mapeamento de qualidade entre medições de qualidade de banda larga pontuação PESQ e pontuação de opinião média objetiva de qualidade auditiva. Mais informações sobre esses escores podem ser encontradas nas recomendações da série ITU-T-P. 862 e em referência . PESQ é uma operação half-duplex que não irá capturar com precisão em end-to-end delay, echo, loudness loss, sidetone, e níveis de escuta. A partir da medição da qualidade da voz do gateway VoIP com interfaces analógicas, as seguintes observações PESQ-LQO são feitas usando DSLA . Sob a condição sem perda de pacotes, a pontuação PESQ-LQO para o codec G. 711 é 4,32, G. 729A é 3,85 e G. 723.1 é 3,75. Outra interpretação desses resultados para Situações de queda de pacotes e comparação com o modelo E é dada como parte dos cálculos do fator R e apresentada na tabela 20.4. No processo de cálculos PESQ, vários outros parâmetros podem ser calculados. Os fornecedores de instrumentos fornecem esses parâmetros como recursos adicionais às medições PESQ .20.1.4 técnica de monitoramento passivo
tabela 20.1. PSTN e VoIP de Qualidade Comparações
| Atributos de | PSTN | VoIP |
| Distorções em | Distorções, devido a vários | Nenhuma transmissão analógico |
| linha analógica | 1000 metros de linhas de | distorções com as chamadas de VoIP. |
| DLC ou CO localização | ||
| cancelamento de Eco | Alcançado através da perda | o nível de Portadora de eco cancellers |
| em chamadas nacionais | planejamento e baixos atrasos | são usados. |
| Automático de ganho | Não incorporou | Possível incorporar para |
| controle | melhor percepção da fala | |
| níveis de qualidade de audição ou | ||
| experiência. | ||
| qualidade de Voz | Monitoramento, tais como GR- | RTCP XR e GR – 909 são |
| monitorização | 909 são incorporados | incorporado em muitos VoIP |
| para a PSTN | implantações. | |
| largura de Banda ou bit | 64 kbps fixa digital | largura de banda Variável, geralmente |
| taxa de | TDM. Canais DCME | requer mais em física |
| use 16, 24, 32 e | interfaces do que o PSTN. Fax | |
| 40 kbps que degrada fax | serviços pode obter a mais | |
| Qualidade | largura de banda ou redundância | |
| transmissão. | ||
| chamadas de Fax | Desempenho limitado pelo | curta Usa linhas finais. Assim, fax |
| fim de linha de transmissão | a entrega pode ser melhor usar | |
| características | VoIP. No entanto, não poderia | |
| ser problemas de interoperabilidade para | ||
| o envio de fax. | ||
| de Voz e de dados | Principalmente por chamadas de voz, | serviço de Internet e VoIP pode |
| alguns serviços podem reutilizar | escala, juntamente com os dados e | |
| canais de voz para dados | multimédia requisitos do serviço. | |
| chamada de Voz de recursos | recursos Limitados e | Vários recursos são oferecidos como |
| caro para vários | livre. | |
| características do serviço | ||
| Voz interfaces | Limitado de interfaces | Várias interfaces e serviços. |
| de Longa distância | de Longa distância é caro | Geralmente livre ou muito menor |
| as taxas. | ||
| Transcodificação | Vários níveis de | End – to – end de codificação directa pode ser |
| de transcodificação para o inter- | empregadas com base no | |
| regional chamadas de | suporte disponíveis. | |
| de banda Larga de suporte | chamadas de Voz são de | banda Larga fim – a – fim é a voz de |
| banda estreita | possível que pode exceder | |
| PSTN qualidade. |
o gateway de envio para o gateway de recebimento. O gateway de recebimento é mostrado com alguns blocos mais expandidos para criar uma imagem geral do modelo E, que é usado para estimativa de fator R, métricas de qualidade adicionais e operação RTCP-XR (real-Time Transport Control Protocol-Extended Reports). No modelo E, são utilizados parâmetros de sinal do sistema RTP, RTCP, jitter buffer e total. Ao calcular o fator R e outros parâmetros derivados,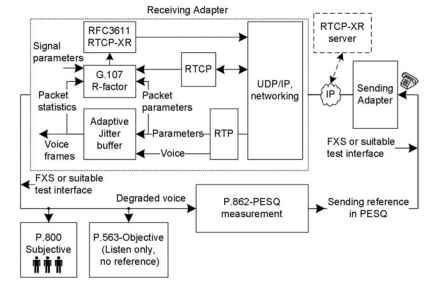
figura 20.1. Visão geral sobre medições populares de qualidade de voz.
RTCP-XR pode enviar pacotes para os aplicativos internos, gateway de destino e servidor RTCP-XR. Em resumo, o fator R não intrusivo é uma estimativa objetiva que reside como parte da implementação VoIP, e software adicional é necessário no gateway para a estimativa do fator R. Na avaliação perceptiva da qualidade da fala (PESQ), instrumentos como o MultiDSLA enviam a fala de referência através do sistema VoIP em teste e avaliam o degradado com a fala de referência. Essa medição está ativa e os gateways VoIP não precisam saber nada sobre a medição. Na escuta subjetiva, vários ouvintes avaliarão a qualidade da voz. No P. 563, a voz é analisada inteiramente no sinal degradado recebido e a referência original não é necessária. P. 563 é semelhante à escuta subjetiva, mas é avaliada pelos instrumentos ou processadores. Cada uma dessas técnicas chega a uma escala diferente de qualidade de voz. Em uma chamada de voz VoIP entre A e B, as medições de Voz são feitas como half-duplex, o que significa que as medições são feitas como A A B ou B A a, uma de cada vez. Devido ao tipo de teste de audição half-duplex, essas medições são chamadas de testes de qualidade de audição (LQ). O sufixo LQ é anexado ao apresentar os resultados em testes half-duplex, e os testes objetivos são adicionalmente sufixados com “O” como LQO.
20.1.1
técnica de medição subjetiva
na avaliação subjetiva da qualidade da voz, a qualidade da voz MOS é avaliada pelo grupo de ouvintes reais do sexo masculino e feminino. É o teste de audição real para avaliar o MOS. As recomendações P. 800 e P. 830 são usadas para avaliar o desempenho subjetivo dos codecs de fala
. Os mesmos testes são estendidos à qualidade de voz VoIP. Um grupo de pessoas participa para registrar pontuações subjetivas. Várias frases de teste são gravadas e, em seguida, os sujeitos de teste (grupo de pessoas) as ouvem em diferentes condições. Esses testes são realizados em salas especiais com ruídos de fundo e outros fatores ambientais são mantidos sob controle para a execução do teste. As condições de teste são dadas em . As técnicas de medição subjetiva são categorizadas como classificação de categoria absoluta (ACR), classificação de categoria de degradação (DCR) e classificação de categoria de comparação (CCR).
I N ACR, os participantes ouvem amostras de fala gravadas que foram processadas por meio de várias conexões de teste. Um mínimo de 16 sujeitos de teste (ouvintes) deve participar da avaliação. Ao ouvir, os usuários classificam a chamada em uma escala de 1 a 5 MOS. Os valores médios das classificações do usuário são considerados para gerar a qualidade geral da chamada.
em um teste DCR, duas amostras de fala estão presentes. A primeira amostra de fala é uma amostra de referência com qualidade predefinida. A amostra aqui se refere à fala com duração de vários segundos. A outra amostra de fala é uma versão degradada. Os ouvintes devem comparar a versão degradada com uma referência em uma escala de degradação de 1 a 5. Aqui, 5 é degradação inaudível e 1 representa a pior degradação. Os resultados são resumidos como mos degradados.
nos testes CCR, os usuários são solicitados a ouvir dois conjuntos de amostras, Um correspondente à referência e o outro a degradado. Este teste é semelhante ao DCR, exceto que a ordem das amostras apresentadas aos ouvintes é alterada em diferentes iterações. A ordem de referência e degradada não é declarada ao ouvinte. Os ouvintes são convidados a dar uma classificação comparativa de uma segunda amostra em relação à primeira em uma escala de -3 a 3 de acordo com P. 800 anexo-D. Ao apresentar os resultados,” 3 “representa uma qualidade muito melhor e” -3 ” representa a pior qualidade em uma escala relativa. A pontuação de qualidade é mapeada para MOS. A classificação mos permitida é de 1 a 5, mas uma classificação do Usuário acima de 4,5 é limitada a 4,5.
testes subjetivos estão envolvidos em procedimentos, e é um esforço caro. É limitado a menos iterações para avaliar qualquer novo algoritmo ou codecs de fala. É difícil manter a consistência como testes objetivos baseados em instrumentos.
20.1.2
técnicas de medição objetiva
métodos objetivos são as medições e cálculos. Espera-se que os resultados sejam consistentes em várias medições. Existem vários métodos objetivos e são classificados como métodos ativos e passivos.
• técnicas de monitoramento ativo do PESQ
• técnicas de monitoramento passivo do P. 563 e do modelo e
técnicas de monitoramento ativo. A medição ativa é chamada de monitoramento intrusivo ou monitoramento offline devido ao envolvimento de sinais externos.
em um esforço para complementar a qualidade subjetiva da audição, são desenvolvidos testes com métodos objetivos de menor custo. A KPN desenvolveu a medida de qualidade de fala perceptiva (PSQM) P. 861 (agora obsoleta) para a avaliação do desempenho do codec. A British Telecom desenvolveu o sistema de medição de análise perceptiva (Pams) para medições de rede. O P. 862 PESQ resultou de uma competição da ITU. O desempenho do PAMS e uma nova versão do PSQM, PSQM99, foram semelhantes, então os colaboradores foram convidados a combinar os algoritmos. Isso resultou em PESQ, que é um pouco melhor que seus constituintes.Esses métodos medem a distorção introduzida por um sistema de transmissão e codec comparando um arquivo de referência original enviado ao sistema em uma interface telefônica com o sinal prejudicado recebido recebido em outra interface telefônica. O PSQM foi desenvolvido para testes laboratoriais de codecs de fala. PAMS e PESQ são projetados para testes de rede. O uso de instrumentos para a qualidade da voz é muito mais simples em comparação com medições subjetivas ou passivas. Os fornecedores de instrumentos também estão fornecendo os parâmetros extra-derivados para ajudar a identificar as fontes de degradações por meio de medições. Consulte alguns instrumentos fornecidos no tópico 13 para obter mais detalhes sobre vários recursos.
ao escrever este tópico, o PESQ foi popularmente apoiado nos instrumentos. O PESQ foi aprovado pela UIT em Março de 2001 como a recomendação P. 862, substituindo P.861 PSQM. O PESQ combinou vários melhores méritos de PAMS e PSQM. É preciso prever pontuações de teste subjetivas e é robusto sob condições de rede severas, como atrasos variáveis, filtragem em interfaces analógicas e suporte de banda larga e Banda Estreita. PESQ produz uma pontuação que está em uma escala de -0,5 a 4,5. Uma função de mapeamento de uma pontuação P. 862 PESQ para uma pontuação média subjetiva P. 800-LQ mos foi fornecida, tornando-a
PESQ-LQO para voz de banda estreita. LQO denota um objetivo de qualidade auditiva. PESQ-LQ fica de 1 a 4,5. Um MOS de 4.5 é a qualidade máxima alcançada para uma condição clara e não distorcida. Uma visão geral do algoritmo PESQ é fornecida aqui. Sugere-se consultar a família de recomendações, software e alguns folhetos de instrumentos comerciais da ITU P. 862 para obter mais detalhes .
20.1.3
a percepção auditiva humana é o conceito central por trás do PESQ e de seus antecessores PAMS e PSQM. Um modelo perceptivo é usado para distinguir corretamente entre distorções audíveis e inaudíveis, e esta provou ser a melhor maneira de prever com precisão a audibilidade e o aborrecimento de distorções complexas. Além da quantidade de distorção, a distribuição da distorção audível poderia tornar as previsões de qualidade muito mais precisas.PESQ mede a qualidade de voz unidirecional, o que significa a operação half-duplex de medição. Ele avalia a qualidade de um sinal de fala distorcido que foi codificado e transmitido pela rede, comparando-o com o sinal original não distorcido. A fala original e distorcida é mapeada para representações psicofísicas que correspondem à maneira como os humanos experimentam a fala.A qualidade da fala distorcida é julgada com base nas diferenças nas representações psicofísicas. A operação PESQ faz uso de duas classes principais de operações logarítmicas – a saber, conversão de sinais no domínio psicoacústico e modelagem cognitiva. Uma representação funcional do algoritmo PESQ é dada na Fig. 20.2. Os fabricantes de instrumentos para a medição PESQ incluem várias operações extras para extrair parâmetros de análise de sinal e deficiências, além das medições PESQ.
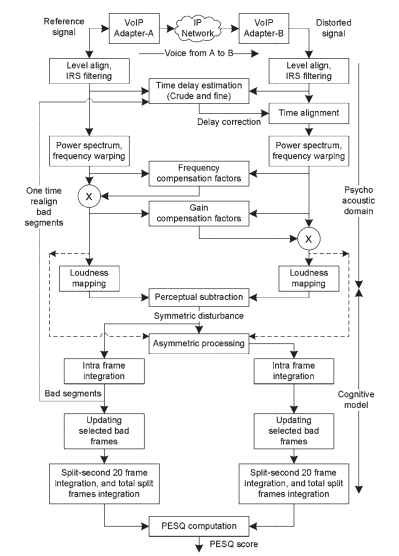
figura 20.2. Representações funcionais do algoritmo PESQ.
o processamento realizado pelo algoritmo PESQ inclui as etapas listadas abaixo. As etapas de resumo são fornecidas aqui; vários detalhes sobre o PESQ são fornecidos .
na primeira etapa do processamento, tanto a referência quanto o sinal degradado são dimensionados para o mesmo nível de potência constante. Essa escala é necessária porque o sinal de referência não precisa estar em um nível definido e o ganho do sistema em teste é Desconhecido antes do teste. PESQ assume que o nível subjetivo de escuta é uma constante de 79 dBSPL no ponto de referência do ouvido . Para normalização de potência, os níveis de sinal elétrico são normalizados para-26dBov (ou seja,- 20dBm conforme dado na referência ). Uma normalização do nível do sinal é aplicada tanto à referência quanto ao sinal degradado para trazê-los para esse nível.
modelos perceptivos como o PESQ devem levar em consideração as características dos aparelhos telefônicos, pois a escuta subjetiva pode usar aparelhos telefônicos. No PESQ, o caminho de recepção dos aparelhos é modelado usando um sistema de referência intermediário (IRS) filtro de passagem de banda no domínio de frequência. Este processo leva em conta os efeitos dos componentes elétricos e acústicos do aparelho. Tanto a referência quanto o sinal degradado são filtrados pelo IRS.
o sistema em teste pode incluir atraso variável. Para comparar os sinais de referência e degradados, ambos os sinais são alinhados com o tempo um com o outro. PESQ alinha seções sobrepostas dos quadros de fala. Na primeira etapa, a estimativa de atraso é realizada ao longo do comprimento dos arquivos, computando a correlação entre os arquivos. O atraso obtido nesta fase é chamado de atraso bruto. No próximo estágio, o PESQ aplica a detecção de atividade de voz aos sinais para identificar os segmentos de fala necessários, geralmente chamados de enunciados. A estimativa de atraso entre enunciados é o atraso fino. Esse processo detecta um atraso que é variável ao longo do comprimento de um enunciado, pois isso pode ser significativo em redes baseadas em pacotes.
a referência alinhada pelo tempo e os sinais degradados são transformados no domínio da frequência usando uma transformação rápida de Fourier de curto prazo (FFT) com uma janela de abertura sobre quadros de 32 ms com sobreposição de 50%. Os poderes dos sinais originais e degradados são calculados e armazenados separadamente. No próximo estágio de operações, as bandas de frequência são transformadas em escala de casca binning FFT bandas. Este processo distorce a escala de frequência em Hz para a escala de pitch, e os sinais resultantes são chamados de densidades de potência de pitch. Nesse processo, maior largura de banda é usada para um sinal de alta frequência derivado por meio da análise de frequência.
os efeitos de filtragem no sistema em teste são equalizados computando um fator de compensação parcial por cada escaninho de casca e multiplicando cada quadro do sinal de referência com este fator. Este processo equaliza a referência ao sinal degradado. O Fator de compensação é calculado como a razão entre o espectro de sinal degradado e o espectro de sinal de referência. Esse fator leva em consideração a filtragem em componentes analógicos da rede, como aparelhos telefônicos. No segundo estágio de equalização, O ganho de amplitude quadro a quadro
do sistema é estimado e usado para equalizar o sinal degradado ao sinal de referência. Em ambos os casos, a equalização é parcial e grandes quantidades de filtragem ou variação de ganho não são canceladas; portanto, resulta em erros sendo medidos. As densidades de potência de passo equalizadas por frequência e ganho são transformadas em escala de volume usando a lei de Zwicker . Os componentes de frequência de tempo resultantes são chamados de densidades de volume.
a diferença assinada entre as densidades de volume para os sinais de referência e degradados é conhecida como densidade de perturbação bruta, que mostra quaisquer diferenças audíveis introduzidas pelo sistema em teste. Uma operação de mascaramento aplica um fator de máscara nas densidades de perturbação bruta que mascara as pequenas distorções inaudíveis na presença de sinais altos. A densidade de perturbação obtida por este processo é chamada densidade de perturbação absoluta ou simétrica. Os distúrbios simétricos são integrados ao longo do comprimento do quadro (intraframe). Os quadros consecutivos com um distúrbio de quadro acima de um limite são categorizados como quadros ruins. Os quadros ruins podem ocorrer devido à estimativa incorreta de atraso de tempo ou quedas de pacotes. Em uma janela localizada em torno de quadros ruins, é feita uma nova estimativa de atraso usada para recomputar as densidades de perturbação. O mínimo dos distúrbios anteriores e atuais é considerado como o distúrbio final nessa janela de quadro ruim.
para modelar a distorção introduzida pelo codec usado na rede, uma densidade de perturbação assimétrica é calculada multiplicando a densidade de perturbação simétrica por um fator de assimetria. O Fator de assimetria é a proporção de densidades de potência de passo distorcidas e originais elevadas à potência de 1,2. Essa densidade de perturbação é chamada de perturbação aditiva ou assimétrica.
por fim, os parâmetros de erro são convertidos em um escore de qualidade, que é uma combinação linear do valor médio de perturbação simétrica e do valor médio de perturbação assimétrica. Da Fig. 20.2, os estágios envolvidos desde o alinhamento de nível até a deformação de intensidade na escala de volume são conhecidos como a conversão para o domínio psico – acústico, e os estágios algorítmicos da subtração perceptiva à computação de pontuação PESQ são conhecidos como modelagem cognitiva.
PESQ dá uma pontuação conhecida como pontuação PESQ de acordo com P. 862. A pontuação do PESQ está na faixa de -0,5 a 4,5. PESQ está correlacionado com o MOS subjetivo como 0,94 com base em experimentos realizados em bancos de dados por . Comparado com as pontuações subjetivas (ouvintes reais), O PESQ fornece melhores resultados para fala de baixa qualidade e resultados pessimistas para voz de boa qualidade. PESQ-LQ fornece melhor correlação com pontuações subjetivas do que PESQ em uma escala de qualidade de audição. As pontuações PESQ-LQ estão na faixa de 1 a 4,5. P862. 1 fornece um mapeamento de qualidade entre medições de qualidade de banda estreita pontuação PESQ e qualidade de audição pontuação média de opinião objetiva (mos-LQO). Recomendação P. 862. 2 fornece um mapeamento de qualidade entre medições de qualidade de banda larga pontuação PESQ e pontuação de opinião média objetiva de qualidade auditiva. Mais informações sobre esses escores podem ser encontradas nas recomendações da série ITU-T-P. 862 e em referência .
PESQ é uma operação half-duplex que não irá capturar com precisão em end-to-end delay, echo, loudness loss, sidetone, e níveis de escuta. A partir da medição da qualidade da voz do gateway VoIP com interfaces analógicas, as seguintes observações PESQ-LQO são feitas usando DSLA . Sob a condição sem perda de pacotes, a pontuação PESQ-LQO para o codec G. 711 é 4,32, G. 729A é 3,85 e G. 723.1 é 3,75. Outra interpretação desses resultados para Situações de queda de pacotes e comparação com o modelo E é dada como parte dos cálculos do fator R e apresentada na tabela 20.4. No processo de cálculos PESQ, vários outros parâmetros podem ser calculados. Os fornecedores de instrumentos fornecem esses parâmetros como recursos adicionais às medições PESQ .
20.1.4
técnica de monitoramento passivo
i n técnicas de monitoramento passivo, o sinal de referência não está presente. Existem dois métodos populares para monitoramento passivo da qualidade da fala. A UIT padronizou um método de monitoramento não intrusivo baseado em sinal, P. 563, com base no resultado da colaboração entre três empresas, a Psytechnics Ltd., Swissqual e Opticom, que combinaram os melhores parâmetros de três modelos diferentes. P. 563 é uma medida objetiva de extremidade única que faz uso de um mecanismo de produção de fala, e os outros modelos de fala fazem uso da percepção auditiva. Este algoritmo opera apenas na fala degradada recebida. Não precisará de fala de referência e opera inteiramente na fala degradada. As medições através de P.563 derivam vários parâmetros da fala recebida classificados como ruído, fala artificial e fala real. Uma visão geral sobre a operação de avaliação de qualidade de fala de extremidade única P. 563 é fornecida aqui.
na ausência de um sinal de referência, os modelos não têm conhecimento do sinal original e as suposições devem ser feitas sobre o sinal recebido. O modelo P. 563 combina três princípios básicos para avaliar distorções. O primeiro princípio se concentra no sistema de produção de voz humana, modelando o trato vocal como uma série de tubos, com variações anormais das seções dos tubos consideradas como degradação. O segundo princípio é reconstruir um sinal de referência limpo a partir do sinal degradado, a fim de aplicar um modelo perceptivo de referência completa posteriormente e avaliar as distorções desmascaradas durante a reconstrução. O terceiro princípio é identificar e estimar distorções específicas encontradas nos canais de voz, como recorte temporal, robotização e ruído. A qualidade da fala auditiva é derivada dos parâmetros calculados a partir dos três princípios, aplicando uma ponderação dependente de distorção.
ao escrever este tópico, a técnica baseada em P. 563 não foi amplamente aceita para medições. P. 862 medições baseadas em PESQ e estimativas baseadas em modelos eletrônicos são mais popularmente aceitas. A principal vantagem desta técnica P. 563 é sua capacidade de monitorar na extremidade degradada sem pedir referência. Assim, ele pode monitorar melhor as chamadas de longa distância fora do Laboratório e em implantações, o que será muito mais simples de conduzir do que muitas outras medições. O método baseado em P. 563 também pode ser incorporado como parte
do gateway de recebimento semelhante ao E-model E RTCP-XR. As operações P. 563 podem ser usadas em amostras que são entregues nas interfaces de voz de modulação de código de pulso (PCM).
mais informações sobre a técnica P. 563 podem ser encontradas em P. 563 E. A pontuação mos produzida por P.563 e outras técnicas são amplamente difundidas e são necessárias para calcular a média dos resultados de vários testes para obter uma métrica de qualidade estável em vários resultados. P. 563 está correlacionado com mos subjetivos como 0,85 a 0,9 com base nos experimentos realizados em um banco de dados por , e PESQ é relatado como 0,94.