20.1
voor het vergelijken van de stemkwaliteit en om te komen tot de parameters die bijdragen aan de stemkwaliteit, is het nodig om te weten hoe de stemkwaliteit wordt gemeten en wat de kwaliteitsdoelstellingen zijn. De basis testopstelling voor VoIP spraakmetingen wordt gegeven in Onderwerp 13. In dit onderwerp worden spraakkwaliteit als gemiddelde opiniescores (MOS), verschillende classificaties, stemkwaliteit beïnvloedende parameters en verbeteringen besproken. Stemkwaliteitsmetingen voor MOS worden geclassificeerd als subjectief en objectief.
een functionele weergave van enkele populaire meettechnieken voor stemkwaliteit wordt geïllustreerd in Fig. 20.1 . In de figuur is de stem weergegeven van
tabel 20.1. PSTN en VoIP kwaliteit vergelijkingen
| attributen | PSTN | VoIP |
| vervormingen op | vervormingen door verscheidene | geen analoge transmissie |
| analoge lijn | 1000 voet lijnen van | vervormingen met VoIP-gesprekken. |
| DLC of CO locatie | ||
| Echo-onderdrukking | bereikt door verlies | echo-onderdrukking van Carrierkwaliteit |
| bij Nationale oproepen worden | planning en geringe vertragingen | gebruikt. |
| Automatic gain | Niet opgenomen | Mogelijk op te nemen voor |
| controle | betere waarneming van spraak | |
| niveaus of luisteren kwaliteit | ||
| ervaring. | ||
| spraakkwaliteit | Monitoring zoals GR – | RTCP-XR en GR-909 zijn |
| monitoring | 909 zijn opgenomen | opgenomen in veel VoIP |
| in de PSTN | implementaties. | |
| bandbreedte of bit | 64 kbps vaste op digitale | variabele bandbreedte, gewoonlijk |
| percentage | TDM. DCME-kanalen | vereist meer fysieke |
| gebruik 16, 24, 32 en | interfaces dan de PSTN. Fax | |
| 40 kbps die fax | – services degradeert, kunnen meer krijgen | |
| kwaliteit | bandbreedte of redundantie in | |
| transmissie. | ||
| faxoproepen | Performance beperkt door de | maakt gebruik van korte eindlijnen. Vandaar, fax |
| eindtransmissielijn | levering kan beter met behulp van | |
| kenmerken | VoIP. Er kan echter | |
| be interoperabiliteitsproblemen voor | ||
| fax versturen. | ||
| spraak en data | voornamelijk voor spraakoproepen, | internetdienst en VoIP can |
| sommige diensten kunnen de schaal | hergebruiken, samen met gegevens en | |
| spraakkanalen voor gegevens | vereisten voor mediadiensten. | |
| functies voor spraakoproepen | beperkte functies en | verschillende functies worden aangeboden als |
| duur voor meerdere | vrij. | |
| service-functies | ||
| Spraakinterfaces | beperkte interfaces | meerdere interfaces en diensten. |
| lange afstand | lange afstand is duur | meestal vrij of veel lager |
| tarieven. | ||
| transcodering | meerdere niveaus van | End-to-end directe codering kunnen worden |
| transcodering voor inter – | gebruikt op basis van de | |
| regionale oproepen | beschikbare steun. | |
| breedband ondersteuning | spraakoproepen zijn van | breedband end-to-end spraak is |
| smalband | mogelijk groter dan | |
| PSTN kwaliteit. |
de verzendgateway naar de ontvangende gateway. De ontvangende gateway wordt weergegeven met een aantal meer uitgebreide blokken voor het maken van een groter beeld van het E-model, die wordt gebruikt voor R-factor schatting, extra kwaliteit metrics, en Real-Time Transport Control Protocol-Extended Reports (RTCP-XR) operatie. In het E-model worden RTP, RTCP, jitter buffer en total system signal parameters gebruikt. Bij het berekenen van de R-factor en andere afgeleide parameters,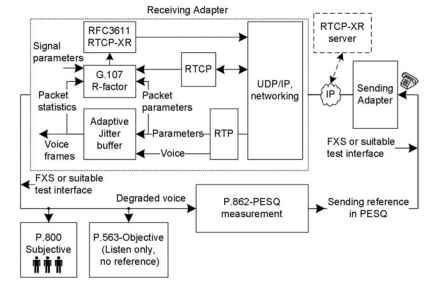
figuur 20.1. Overzicht van populaire spraakkwaliteitsmetingen.
RTCP-XR kan pakketten verzenden naar de interne toepassingen, doelgateway en RTCP-XR-server. Samengevat, de niet-opdringerige R-factor is een objectieve schatting die zich bevindt als onderdeel van VoIP-implementatie, en extra software is vereist in de gateway voor de R-factor schatting. In perceptual evaluation of speech quality (PESQ) sturen instrumenten als MultiDSLA de referentiespeech door het te testen VoIP-systeem en evalueren de gedegradeerde met de referentiespeech. Deze meting is actief en VoIP-gateways hoeven niets over de meting te weten. Bij subjectief luisteren zullen meerdere luisteraars de stemkwaliteit evalueren. In P. 563 wordt de stem volledig geanalyseerd op het ontvangen gedegradeerde signaal en is de originele referentie niet vereist. P. 563 is vergelijkbaar met subjectief luisteren, maar het wordt geëvalueerd door de instrumenten of processors. Elk van deze technieken komt op een andere schaal van stemkwaliteit. In een VoIP-spraakoproep tussen A en B worden spraakmetingen uitgevoerd als half-duplex, wat betekent dat metingen worden uitgevoerd als A naar B of B naar A, één voor één. Vanwege het half-duplex luistertype worden deze metingen aangeduid als luisterkwaliteitstests (LQ). Het achtervoegsel LQ wordt toegevoegd terwijl het presenteren van de resultaten op half-duplex tests, en objectieve tests worden bovendien achtervoegsel met “O” als LQO.
20.1.1
subjectieve meettechniek
bij subjectieve evaluatie van de stemkwaliteit wordt de stemkwaliteit MOS beoordeeld door de groep van werkelijke mannelijke en vrouwelijke luisteraars. Het is de eigenlijke luistertest voor het evalueren van de MOS. De aanbevelingen P. 800 en P. 830 worden gebruikt voor de beoordeling van de subjectieve prestaties van spraak
codecs. Dezelfde tests worden uitgebreid tot de voip voice kwaliteit. Een groep mensen neemt deel aan het opnemen van subjectieve scores. Meerdere testzinnen worden opgenomen en vervolgens proefpersonen (groep mensen) luisteren naar hen in verschillende omstandigheden. Deze tests worden uitgevoerd in speciale ruimten met achtergrondgeluiden en andere omgevingsfactoren worden onder controle gehouden voor de uitvoering van de test. De testomstandigheden zijn aangegeven . De subjectieve meettechnieken worden gecategoriseerd als absolute categorie rating (ACR), afbraak categorie rating (DCR), en vergelijking categorie rating (CCR).
in ACR luisteren deelnemers naar opgenomen spraakvoorbeelden die via verschillende testverbindingen zijn verwerkt. Minimaal 16 proefpersonen (luisteraars) moeten deelnemen aan de beoordeling. Tijdens het luisteren beoordelen gebruikers het gesprek op een schaal van 1 tot 5 MOS. De gemiddelde waarden van de gebruikersbeoordelingen worden beschouwd als de Algemene gesprekskwaliteit te genereren.
bij een DCR-test zijn twee spraakmonsters aanwezig. Het eerste spraakmonster is een referentiemonster met vooraf gedefinieerde kwaliteit. Het voorbeeld verwijst hier naar spraak die enkele seconden duurt. Het andere spraakmonster is een gedegradeerde versie. De luisteraars moeten de afgebroken versie vergelijken met een referentie op een afbraakschaal van 1 tot 5. Hier is 5 onhoorbare degradatie en 1 staat voor ergste degradatie. De resultaten worden samengevat als gedegradeerde MOS.
bij CCR-tests wordt de gebruiker gevraagd naar twee reeksen monsters te luisteren, één die overeenkomt met referentie en de andere met gedegradeerd. Deze test is vergelijkbaar met DCR, behalve dat de volgorde van de monsters die aan de luisteraars worden gepresenteerd in verschillende iteraties worden gewijzigd. De volgorde van verwijzing en afgebroken wordt niet aangegeven aan de luisteraar. De luisteraars wordt verzocht een vergelijkende beoordeling te geven van een tweede steekproef ten opzichte van de eerste op een schaal van -3 tot 3 volgens P. 800 Bijlage-D . Bij de presentatie van de resultaten staat “3 “voor een veel betere kwaliteit en” -3 ” voor de slechtste kwaliteit op relatieve schaal. De kwaliteitsscore is gekoppeld aan MOS. De toegestane MOS-rating is 1 tot 5, maar een gebruikersbeoordeling boven 4.5 is beperkt tot 4.5.
subjectieve tests zijn betrokken bij procedures en het is een kostbare inspanning. Het is beperkt tot minder iteraties om nieuwe algoritmen of spraakcodecs te evalueren. Het is moeilijk om consistentie te handhaven zoals op instrumenten gebaseerde objectieve tests.
20.1.2
objectieve meettechnieken
objectieve methoden zijn de metingen en berekeningen. De verwachting is dat de resultaten bij verschillende metingen consistent zullen zijn. Verschillende objectieve methoden bestaan en worden geclassificeerd als actieve en passieve methoden.
* actieve monitoringtechnieken van PESQ
* passieve monitoringtechnieken van P. 563 en het E-model
actieve Monitoringtechnieken. Actieve meting wordt opdringerige monitoring of offline monitoring genoemd vanwege betrokkenheid van externe signalen.
om de subjectieve luisterkwaliteit aan te vullen, worden proeven met goedkopere objectieve methoden ontwikkeld. KPN ontwikkelde de P. 861 (dit is nu verouderd) perceptual speech quality measure (PSQM) voor de evaluatie van codec prestaties. British Telecom ontwikkelde het perceptual analysis measurement system (PAMS) voor netwerkmetingen. De P. 862 PESQ was het resultaat van een ITU wedstrijd. De prestaties van PAMS en een nieuwe versie van PSQM, PSQM99, waren vergelijkbaar, dus de bijdragers werden uitgenodigd om de algoritmen te combineren. Dit resulteerde in PESQ, wat iets beter is dan de bestanddelen.
deze methoden meten de vervorming die wordt veroorzaakt door een transmissiesysteem en codec door een origineel referentiebestand dat via een telefooninterface naar het systeem wordt gestuurd, te vergelijken met het ontvangen signaal dat via een andere telefooninterface wordt ontvangen. PSQM is ontwikkeld voor laboratoriumtesten van spraakcodecs. PAMS en PESQ zijn ontworpen voor Netwerk testen. Het gebruik van instrumenten voor de stemkwaliteit is veel eenvoudiger in vergelijking met subjectieve of passieve metingen. Instrumentleveranciers leveren ook de extra afgeleide parameters om de bronnen van degradaties door middel van metingen te helpen identificeren. Zie enkele instrumenten in Onderwerp 13 voor meer informatie over de verschillende kenmerken.
tijdens het schrijven van dit onderwerp werd PESQ door de bevolking gesteund in de instrumenten. PESQ werd in maart 2001 door de ITU goedgekeurd als aanbeveling P. 862, ter vervanging van P.861 PSQM. De PESQ combineerde verschillende beste verdiensten van PAMS en PSQM. Het is nauwkeurig in het voorspellen van subjectieve testscores, en het is robuust onder strenge netwerkomstandigheden zoals een variabele vertragingen, filteren op analoge interfaces, en ondersteuning van zowel breedband en smalband. PESQ produceert een score die ligt op een schaal van -0,5 tot 4,5. Een mapping functie van een P. 862 PESQ score naar een gemiddelde subjectieve P. 800-LQ MOS score werd verstrekt, waardoor het
PESQ-LQO voor narrowband voice. LQO is een kwaliteitsdoelstelling voor het luisteren. PESQ-LQ ligt van 1 tot 4,5. Een MOS van 4.5 is de maximale kwaliteit die wordt bereikt voor een duidelijke niet-vervormde toestand. Een overzicht van het PESQ algoritme wordt hier gegeven. Er wordt voorgesteld om te verwijzen naar de ITU P. 862 familie van aanbevelingen, software, en een aantal commerciële instrument brochures voor meer informatie .
20.1.3
PESQ-meting
menselijke auditieve perceptie is het kernconcept achter PESQ en zijn voorgangers PAMS en PSQM. Een perceptueel model wordt gebruikt om correct onderscheid te maken tussen hoorbare en onhoorbare vervormingen, en dit is de beste manier gebleken om nauwkeurig de hoorbaarheid en ergernis van complexe vervormingen te voorspellen. Naast de kwantiteit van vervorming kan de verdeling van hoorbare vervorming kwaliteitsvoorspellingen veel nauwkeuriger maken.
PESQ meet one-way voice quality, wat betekent dat de half-duplex werking van de meting. Het beoordeelt de kwaliteit van een vervormd spraaksignaal dat is gecodeerd en verzonden via het netwerk door het te vergelijken met het oorspronkelijke onvervormde signaal. De originele en vervormde spraak wordt in kaart gebracht op psychofysische representaties die overeenkomen met de manier waarop mensen spraak ervaren.
de kwaliteit van de vervormde spraak wordt beoordeeld op basis van verschillen in psychofysische representaties. De PESQ operatie maakt gebruik van twee grote klassen van logaritmische operaties—namelijk omzetting van signalen in het psycho-akoestische domein en cognitieve modellering. Een functionele representatie van het PESQ-algoritme wordt gegeven in Fig. 20.2. Instrumentfabrikanten voor de PESQ-meting omvatten verschillende extra bewerkingen om signaalanalyseparameters en impairments te extraheren naast PESQ-metingen.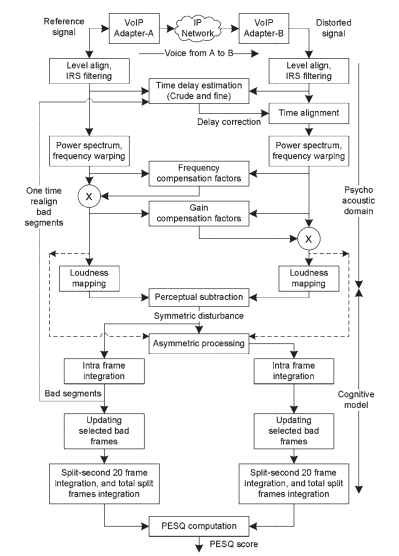
figuur 20.2. PESQ algoritme functionele representaties.
de verwerking door het PESQ-algoritme omvat de onderstaande fasen. Beknopte stappen worden hier gegeven; verschillende details over de PESQ worden gegeven in .
in de eerste stap van de verwerking worden zowel het referentie-als het gedegradeerde signaal op hetzelfde constante vermogensniveau geschaald. Deze schaling is noodzakelijk omdat het referentiesignaal niet op een bepaald niveau hoeft te zijn en de winst van het te testen systeem vóór de test onbekend is. PESQ gaat ervan uit dat het subjectieve luisterniveau een constante 79 dBSPL is op het referentiepunt van het oor . Voor stroomnormalisatie worden elektrische signaalniveaus genormaliseerd tot-26dBov (d.w.z.-20dBm zoals aangegeven in de referentie ). Een signaalniveau normalisatie wordt toegepast op zowel de referentie als het gedegradeerde signaal om ze op dit niveau te brengen.
perceptuele modellen zoals PESQ moeten rekening houden met de kenmerken van de telefoontoestellen, aangezien subjectief luisteren telefoontoestellen kan gebruiken. In PESQ wordt het ontvangstpad van de handsets gemodelleerd met behulp van een intermediate reference system (IRS) band-pass filter in het frequentiedomein. Dit proces houdt rekening met de effecten van de elektrische en akoestische componenten van de handset. Zowel de referentie als het gedegradeerde signaal worden gefilterd.
het te testen systeem kan variabele vertraging bevatten. Om de referentie-en gedegradeerde signalen te vergelijken, zijn beide signalen tijd met elkaar uitgelijnd. PESQ lijnt overlappende secties van de spraakframes uit. In de eerste fase wordt de vertraging schatting uitgevoerd over de lengte van bestanden door het berekenen van de correlatie tussen de bestanden. De vertraging die in dit stadium wordt verkregen, wordt ruwe vertraging genoemd. In de volgende fase past PESQ spraakactiviteitsdetectie toe op de signalen om vereiste spraaksegmenten te identificeren die gewoonlijk worden aangeduid als uitingen. De vertraging schatting tussen uitingen is de boete vertraging. Dit proces detecteert vertraging die variabel is over de lengte van een uiting, omdat dit significant kan zijn in pakketgebaseerde netwerken.
de tijdgebonden referentie-en gedegradeerde signalen worden omgezet in het frequentiedomein door gebruik te maken van een korte termijn fast Fourier transform (FFT) met een Hanning-venster over 32 ms-frames met 50% overlapping. De krachten van originele en gedegradeerde signalen worden afzonderlijk berekend en opgeslagen. In de volgende fase van de operaties worden de frequentiebanden omgezet in schors schaal door binning FFT banden. Dit proces vervormt de frequentieschaal in Hz naar de toonhoogte schaal, en de resulterende signalen worden pitch power densities genoemd. In dit proces, wordt de hogere bandbreedte gebruikt voor een hoogfrequent signaal dat door frequentieanalyse wordt afgeleid.
de filtereffecten in het te testen systeem worden vereffend door een partiële compensatiefactor per bark bin te berekenen en door elk frame van het referentiesignaal met deze factor te vermenigvuldigen. Dit proces egaliseert de verwijzing naar het gedegradeerde signaal. De compensatiefactor wordt berekend als de verhouding tussen het gedegradeerde signaalspectrum en het referentiesignaalspectrum. Deze factor houdt rekening met de filtering op analoge componenten van het netwerk, zoals telefoontoestellen. In de tweede fase van de egalisatie wordt de frame-by-frame amplitude
versterking van het systeem geschat en gebruikt om het gedegradeerde signaal te egaliseren met het referentiesignaal. In beide gevallen is de egalisatie gedeeltelijk en worden grote hoeveelheden filtering of versterkingsvariatie niet geannuleerd; daarom resulteert het in fouten die worden gemeten. De frequentie-en gain-verevelde pitch power dichtheden worden getransformeerd naar luidheid schaal met behulp van de wet van Zwicker . De resulterende tijd-frequentie componenten worden luidheid dichtheden genoemd.
het getekende verschil tussen de geluidsdichtheid voor de referentie-en de gedegradeerde signalen staat bekend als de ruwe storingsdichtheid, die de hoorbare verschillen vertoont die door het te testen systeem worden veroorzaakt. Een maskeeroperatie past een maskerfactor toe op de ruwe verstoringsdichtheid die de kleine onhoorbare vervormingen maskeert in de aanwezigheid van luide signalen. De door dit proces verkregen storingsdichtheid wordt absolute of symmetrische storingsdichtheid genoemd. De symmetrische storingen zijn geïntegreerd over de lengte van het frame (intraframe). De opeenvolgende frames met een frame verstoring boven een drempel worden gecategoriseerd als slechte frames. De slechte frames kunnen optreden als gevolg van onjuiste tijd vertraging schatting of pakket druppels. Op een gelokaliseerd venster rond slechte frames wordt een nieuwe vertragingsschatting gemaakt die wordt gebruikt om de storingsdichtheid te berekenen. Het minimum van de vorige en Huidige storingen wordt beschouwd als de laatste storing in dat slechte frame venster.
om de vervorming te modelleren die wordt veroorzaakt door de codec die in het netwerk wordt gebruikt, wordt een asymmetrische storingsdichtheid berekend door de symmetrische storingsdichtheid te vermenigvuldigen met een asymmetriefactor. De asymmetrie factor is de verhouding van vervormde en de oorspronkelijke pitch macht dichtheden verhoogd tot de macht van 1,2. Deze storingsdichtheid wordt een additieve of asymmetrische verstoring genoemd.
ten slotte worden de foutparameters omgezet in een kwaliteitsscore, die een lineaire combinatie is van de gemiddelde symmetrische storingswaarde en de gemiddelde asymmetrische storingswaarde. Van Fig. 20.2, de betrokken stadia van niveau uitlijning tot de intensiteit kromtrekken op de luidheidsschaal staan bekend als de conversie naar het psycho – akoestische domein, en de algoritmische stadia van perceptuele aftrekking tot PESQ score berekening staan bekend als cognitieve modellering.
PESQ geeft een score die bekend staat als de PESQ-score in overeenstemming met P. 862. De PESQ-score ligt in het bereik van -0,5 tot 4,5. PESQ is gecorreleerd aan de subjectieve MOS als 0,94 gebaseerd op experimenten uitgevoerd op databases door . Vergeleken met subjectieve (werkelijke luisteraars) scores, PESQ geeft betere resultaten voor slechte kwaliteit spraak en pessimistische resultaten voor goede kwaliteit stem. PESQ-LQ biedt een betere correlatie met subjectieve scores dan PESQ op een luisterkwaliteitsschaal. PESQ-LQ scores liggen tussen 1 en 4,5. P862. 1 biedt een kwaliteit mapping tussen smalband kwaliteit metingen PESQ score en luisteren kwaliteit doelstelling mean opinion score (MOS-LQO). Aanbeveling P. 862. 2 biedt een kwaliteit mapping tussen breedband kwaliteit metingen PESQ score en luisteren kwaliteit doelstelling gemiddelde opiniescore. Meer informatie over deze scores is te vinden in de aanbevelingen van de ITU-T-P. 862-reeks en in referentie.
PESQ is een half-duplex bewerking die niet nauwkeurig kan worden vastgelegd op end-to-end delay, echo, loudness loss, sidetone en luisterniveaus. Uit de meting van de stemkwaliteit van de VoIP-gateway met analoge interfaces worden de volgende PESQ-LQO-observaties gemaakt met behulp van DSLA . De PESQ-LQO score voor de G. 711 codec is 4,32, G. 729A is 3,85, en G. 723.1 is 3,75. Een andere interpretatie van deze resultaten voor packet drop situaties en vergelijking met het E-model worden gegeven als onderdeel van de R-factor berekeningen en weergegeven in Tabel 20.4. Tijdens PESQ-berekeningen kunnen verschillende andere parameters worden berekend. Instrument leveranciers bieden deze parameters als extra functies voor PESQ metingen .
20.1.4
passieve Bewakingstechniek
i n passieve bewakingstechnieken is het referentiesignaal niet aanwezig. Er bestaan twee populaire methoden voor het monitoren van de passieve spraakkwaliteit. De ITU heeft een signaalgebaseerde niet-opdringerige monitoringmethode, P. 563, gestandaardiseerd op basis van samenwerking tussen drie bedrijven, Psytechnics Ltd., Swissqual, en Opticom, die de beste parameters van drie verschillende modellen gecombineerd. P. 563 is een enkelvoudige objectieve meting die gebruik maakt van een spraakproductiemechanisme, en de andere spraakmodellen maken gebruik van luisterperceptie. Dit algoritme werkt alleen op ontvangen gedegradeerde spraak. Het zal geen referentie spraak nodig hebben, en het werkt volledig op gedegradeerde spraak. De metingen door P.563 ontlenen verschillende parameters van ontvangen spraak geclassificeerd als ruis, kunstmatige spraak, en werkelijke spraak. Een overzicht van de P. 563 single-ended speech-quality assessment operatie wordt hier gegeven.
bij afwezigheid van een Referentiesignaal hebben de modellen geen kennis van het oorspronkelijke signaal en moeten aannames worden gemaakt over het ontvangen signaal. Het P. 563-model combineert drie basisprincipes voor het evalueren van verstoringen. Het eerste principe richt zich op het menselijke stem productiesysteem, het modelleren van het stemkanaal als een reeks van buizen, met abnormale variaties van de secties van de buizen beschouwd als degradatie. Het tweede principe is het reconstrueren van een schoon Referentiesignaal uit het gedegradeerde signaal om daarna een volledig referentieperceptueel model toe te passen en vervormingen te beoordelen die tijdens de reconstructie zijn ontmaskerd. Het derde principe is het identificeren en schatten van specifieke verstoringen in spraakkanalen, zoals temporele knippen, robotisering en ruis. De kwaliteit van het luisteren wordt afgeleid uit de berekende parameters van de drie principes, waarbij een vervormingsafhankelijke weging wordt toegepast.
tijdens het schrijven van dit onderwerp werd de op P. 563 gebaseerde techniek niet algemeen aanvaard voor metingen. P. 862 PESQ-gebaseerde metingen en E-model-gebaseerde schattingen worden meer algemeen aanvaard. Het belangrijkste voordeel van deze P. 563 techniek is zijn capaciteit om aan het gedegradeerde eind te controleren zonder om verwijzing te roepen. Zo kan het interlokale gesprekken buiten het laboratorium en in implementaties beter monitoren, wat veel eenvoudiger uit te voeren is dan veel andere metingen. De op P. 563 gebaseerde methode kan ook worden ingebed als onderdeel
van de ontvangende gateway, vergelijkbaar met E-model en RTCP-XR. P. 563 operaties kunnen worden gebruikt op samples die worden geleverd op de pulse code modulation (PCM) voice interfaces.
meer informatie over de P. 563 techniek is te vinden bij P. 563 en . De MOS score geproduceerd door P.563 en andere technieken is wijd verspreid en is noodzakelijk om de resultaten van meerdere tests te Gemiddelde om een stabiele kwaliteit metriek over meerdere resultaten te bereiken. P. 563 is gecorreleerd met subjectieve MOS als 0,85 tot 0,9 gebaseerd op de experimenten uitgevoerd op een database door , en PESQ wordt gerapporteerd als 0,94.