20.1
Para comparar la calidad de la voz, y para llegar a los parámetros que contribuyen a la calidad de la voz, es necesario saber cómo se mide la calidad de la voz y cuáles son los objetivos de calidad. La configuración de prueba básica para mediciones de voz VoIP se muestra en el tema 13. En este tema, se discuten la calidad de voz como puntuaciones de opinión medias (MOS), varias clasificaciones, parámetros de influencia de la calidad de voz y mejoras. Las mediciones de calidad de voz para MOS se clasifican como subjetivas y objetivas.
En la Fig. 20.1 . En la figura, se muestra la voz de
Tabla 20.1. Comparaciones de Calidad PSTN y VoIP
| Atributos | PSTN | VoIP |
| Distorsiones en | Distorsiones debidas a varias | Sin transmisión analógica |
| líneas analógicas | líneas de 1000 pies desde | distorsiones con llamadas VoIP. |
| DLC o CO ubicación | ||
| cancelación de Eco | Logra a través de la pérdida de | Carrier echo cancellers |
| en llamadas nacionales | planificación y baja retrasos | se utilizan. |
| Automático de ganancia | No se incorporan | Posible incorporar para |
| control | mejor percepción del habla | |
| los niveles o la calidad de escucha | ||
| experiencia. | ||
| la calidad de la Voz | Monitoreo tales como GR- | RTCP – XR y el GR – 909 son |
| seguimiento | 909 se incorporan | incorporados en muchas de VoIP |
| en la RTC | implementaciones. | |
| Ancho de banda o bit | 64 kbps fijo en digital | Ancho de banda variable, generalmente |
| tasa | TDM. Los canales DCME | requieren más información física |
| utilice interfaces 16, 24, 32 y | que la PSTN. Fax | |
| 40 kbps que se degrada de fax | servicios puede obtener más | |
| Calidad | ancho de banda o la redundancia en | |
| de la transmisión. | ||
| Llamadas de fax | El rendimiento limitado por | Utiliza líneas de extremo corto. Por lo tanto, el fax |
| línea de transmisión final | la entrega puede ser mejor usando | |
| características | VoIP. Sin embargo, no podría | |
| ser problemas de interoperabilidad para | ||
| envío de fax. | ||
| Voz y datos | Principalmente para llamadas de voz, | El servicio de Internet y VoIP pueden |
| algunos servicios pueden reutilizar la escala | junto con los datos y | |
| canales de voz para datos | requisitos del servicio multimedia. | |
| de Voz funciones de llamada | características Limitadas y | Varias características que se ofrecen como |
| caro para varios | libre. | |
| características del servicio | ||
| Voz interfaces | Limitado de interfaces | Múltiples interfaces y servicios. |
| de Larga distancia | de Larga distancia es costoso | Suele ser gratuito o mucho menor |
| las tasas. | ||
| Transcodificación | Múltiples niveles de | La codificación directa de extremo a extremo puede ser |
| transcodificación para inter – | empleada en base al | |
| llamadas regionales | soporte disponible. | |
| Soporte de banda ancha | Las llamadas de voz son de | La voz de extremo a extremo de banda ancha es |
| banda estrecha | posible que puede exceder | |
| Calidad PSTN. |
la puerta de enlace de envío a la puerta de enlace de recepción. La puerta de enlace receptora se muestra con algunos bloques más expandidos para crear una imagen general del modelo E, que se utiliza para la estimación del factor R, métricas de calidad adicionales y operación de Informes Extendidos del Protocolo de Control de Transporte en Tiempo Real (RTCP-XR). En el modelo E, se utilizan los parámetros RTP, RTCP, búfer de fluctuación y señal total del sistema. Al calcular el factor R y otros parámetros derivados,
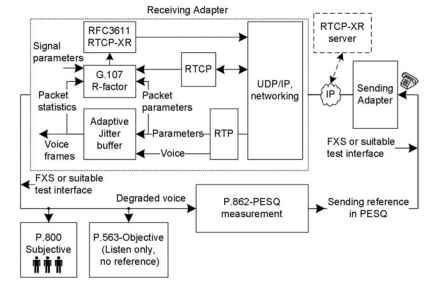
Figura 20.1. Descripción general de las mediciones de calidad de voz más populares.
RTCP – XR puede enviar paquetes a las aplicaciones internas, la puerta de enlace de destino y el servidor RTCP-XR. En resumen, el factor R no intrusivo es una estimación objetiva que reside como parte de la implementación de VoIP, y se requiere software adicional en la puerta de enlace para la estimación del factor R. En la evaluación perceptiva de la calidad del habla (PESQ, por sus siglas en inglés), instrumentos como MultiDSLA envían el habla de referencia a través del sistema VoIP bajo prueba y evalúan la degradada con el habla de referencia. Esta medición está activa y las pasarelas VoIP no necesitan saber nada sobre la medición. En la escucha subjetiva, varios oyentes evaluarán la calidad de la voz. En P. 563, la voz se analiza completamente en la señal degradada recibida y no se requiere la referencia original. P. 563 es similar a la escucha subjetiva, pero es evaluada por los instrumentos o procesadores. Cada una de estas técnicas llega a una escala diferente de calidad de voz. En una llamada de voz VoIP entre A y B, las mediciones de voz se realizan como semidúplex, lo que significa que las mediciones se realizan de A a B o de B a A, una a la vez. Debido al tipo de prueba de escucha semidúplex, estas mediciones se conocen como pruebas de calidad de escucha (LQ). El sufijo LQ se anexa al presentar los resultados en pruebas semidúplex, y las pruebas objetivas se adjuntan adicionalmente con el sufijo «O» como LQO.
20.1.1
Técnica de medición subjetiva
En la evaluación de calidad de voz subjetiva, la calidad de voz MOS es calificada por el grupo de oyentes masculinos y femeninos reales. Es la prueba de escucha real para evaluar el MOS. Las recomendaciones P. 800 y P. 830 se utilizan para evaluar el rendimiento subjetivo de los códecs de habla
. Las mismas pruebas se extienden a la calidad de voz VoIP. Un grupo de personas participa para registrar puntuaciones subjetivas. Se graban varias frases de prueba y luego los sujetos de prueba (grupo de personas) las escuchan en diferentes condiciones. Estas pruebas se realizan en salas especiales con ruidos de fondo y otros factores ambientales se mantienen bajo control para la ejecución de las pruebas. Se indican las condiciones de la prueba . Las técnicas de medición subjetiva se clasifican como clasificación de categoría absoluta (ACR), clasificación de categoría de degradación (DCR) y clasificación de categoría de comparación (CCR).
En ACR, los participantes escuchan muestras de voz grabadas que se han procesado a través de varias conexiones de prueba. Un mínimo de 16 sujetos de prueba (oyentes) deben participar en la evaluación. Al escuchar, los usuarios califican la llamada en una escala de 1 a 5 MOS. Se considera que los valores medios de las calificaciones de los usuarios generan la calidad general de la llamada.
En una prueba de DCR, dos muestras de habla están presentes. La primera muestra de voz es una muestra de referencia con calidad predefinida. La muestra aquí se refiere al habla que dura varios segundos de duración. La otra muestra de voz es una versión degradada. Los oyentes deben comparar la versión degradada con una referencia en una escala de degradación de 1 a 5. Aquí, 5 es degradación inaudible y 1 representa la peor degradación. Los resultados se resumen como MOS degradados.
En las pruebas de CCR, se pide a los usuarios que escuchen dos conjuntos de muestras, una correspondiente a referencia y la otra a degradada. Esta prueba es similar a DCR, excepto que el orden de las muestras presentadas a los oyentes se cambia en diferentes iteraciones. El orden de referencia y degradado no se declara al oyente. Se pide a los oyentes que den una calificación comparativa de una segunda muestra con respecto a la primera en una escala de -3 a 3 según P. 800 Anexo-D. Al presentar los resultados, «3» representa una calidad mucho mejor y» -3 » representa la peor calidad en una escala relativa. La puntuación de calidad se asigna a MOS. La calificación MOS permitida es de 1 a 5, pero una calificación de usuario superior a 4.5 está limitada a 4.5.
Las pruebas subjetivas están involucradas en los procedimientos, y es un esfuerzo costoso. Se limita a menos iteraciones para evaluar cualquier nuevo algoritmo o códecs de voz. Es difícil mantener la consistencia como las pruebas objetivas basadas en instrumentos.
20.1.2
Técnicas de medición objetiva
Los métodos objetivos son las mediciones y los cálculos. Se espera que los resultados sean coherentes en varias mediciones. Existen varios métodos objetivos y se clasifican como métodos activos y pasivos.
* Técnicas de monitoreo activo de PESQ
* Técnicas de monitoreo pasivo de P. 563 y el modelo E
Técnicas de Monitoreo Activo. La medición activa se denomina monitoreo intrusivo o monitoreo fuera de línea debido a la participación de señales externas.
En un esfuerzo por complementar la calidad auditiva subjetiva, se desarrollan pruebas con métodos objetivos de menor costo. KPN desarrolló el P. 861 (ahora obsoleto) perceptual speech quality measure (PSQM) para la evaluación del rendimiento de los códecs. British Telecom desarrolló el sistema de medición de análisis perceptual (PAMS) para mediciones de red. El P. 862 PESQ fue el resultado de un concurso de la UIT. El rendimiento de PAMS y una nueva versión de PSQM, PSQM99, fueron similares, por lo que se invitó a los colaboradores a combinar los algoritmos. Esto dio lugar a PESQ, que es ligeramente mejor que sus componentes.
Estos métodos miden la distorsión introducida por un sistema de transmisión y un códec comparando un archivo de referencia original enviado al sistema en una interfaz telefónica con la señal deteriorada recibida en otra interfaz telefónica. PSQM fue desarrollado para pruebas de laboratorio de códecs de voz. PAMS y PESQ están diseñados para pruebas de red. El uso de instrumentos para la calidad de voz es mucho más sencillo en comparación con las mediciones subjetivas o pasivas. Los proveedores de instrumentos también están proporcionando los parámetros extra-derivados para ayudar a identificar las fuentes de degradaciones a través de mediciones. Para más detalles sobre diversas características, véanse algunos instrumentos que figuran en el tema 13.
Mientras escribía este tema, PESQ fue apoyado popularmente en los instrumentos. PESQ fue aprobada por la UIT en marzo de 2001 como recomendación P. 862, en sustitución de P.861 PSQM. El PESQ combinó varios de los mejores méritos de PAMS y PSQM. Es preciso en la predicción de puntajes de prueba subjetivos, y es robusto en condiciones de red severas, como retrasos variables, filtrado en interfaces analógicas y soporte de banda ancha y banda estrecha. PESQ produce una puntuación que se encuentra en una escala de -0,5 a 4,5. Se proporcionó una función de mapeo de una puntuación P. 862 PESQ a una puntuación media subjetiva P. 800-LQ MOS, lo que la convierte en
PESQ – LQO para voz de banda estrecha. LQO denota un objetivo de calidad auditiva. PESQ-LQ se encuentra de 1 a 4,5. Un MOS de 4.5 es la calidad máxima lograda para una condición clara y sin distorsiones. Aquí se ofrece una visión general del algoritmo PESQ. Se sugiere consultar la familia de recomendaciones, programas informáticos y algunos folletos de instrumentos comerciales de la UIT P. 862 para obtener más detalles .
20.1.3
Medición PESQ
La percepción auditiva humana es el concepto central detrás de PESQ y sus predecesores PAMS y PSQM. Se utiliza un modelo perceptivo para distinguir correctamente entre distorsiones audibles e inaudibles, y esto ha demostrado ser la mejor manera de predecir con precisión la audibilidad y la molestia de las distorsiones complejas. Además de la cantidad de distorsión, la distribución de la distorsión audible podría hacer predicciones de calidad mucho más precisas.
PESQ mide la calidad de voz unidireccional, lo que significa la operación semidúplex de medición. Evalúa la calidad de una señal de voz distorsionada que ha sido codificada y transmitida a través de la red comparándola con la señal original no distorsionada. El habla original y distorsionada se asigna a representaciones psicofísicas que coinciden con la forma en que los humanos experimentan el habla.
La calidad del habla distorsionada se juzga en función de las diferencias en las representaciones psicofísicas. La operación PESQ hace uso de dos clases principales de operaciones logarítmicas, a saber, la conversión de señales en el dominio psicoacústico y el modelado cognitivo. Una representación funcional del algoritmo PESQ se da en la Fig. 20.2. Los fabricantes de instrumentos para la medición de PESQ incluyen varias operaciones adicionales para extraer parámetros de análisis de señales y deficiencias, además de las mediciones de PESQ.
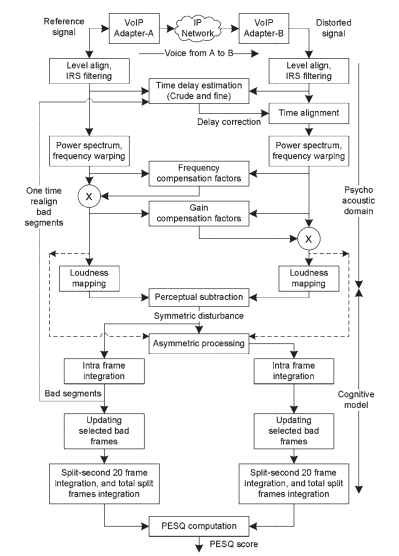
Figura 20.2. Representaciones funcionales del algoritmo PESQ.
El procesamiento llevado a cabo por el algoritmo PESQ incluye las etapas que se enumeran a continuación. Los pasos resumidos se dan aquí; varios detalles sobre el PESQ se dan en .
En el primer paso del procesamiento, tanto la señal de referencia como la señal degradada se escalan al mismo nivel de potencia constante. Esta escala es necesaria porque la señal de referencia no tiene que estar en un nivel definido y la ganancia del sistema bajo prueba es desconocida antes de la prueba. PESQ asume que el nivel de escucha subjetivo es una constante de 79 dBSPL en el punto de referencia del oído . Para la normalización de potencia, los niveles de señal eléctrica se normalizan a-26dBov (es decir,- 20dBm como se indica en la referencia ). Se aplica una normalización de nivel de señal tanto a la señal de referencia como a la señal degradada para llevarlas a este nivel.
Los modelos perceptivos, como el PESQ, deben tener en cuenta las características de los teléfonos móviles, ya que la escucha subjetiva puede utilizar teléfonos móviles. En PESQ, la ruta de recepción de los teléfonos se modela utilizando un filtro de paso de banda del sistema de referencia intermedia (IRS) en el dominio de frecuencia. Este proceso tiene en cuenta los efectos de los componentes eléctricos y acústicos del teléfono. Tanto la señal de referencia como la señal degradada se filtran IRS.
El sistema sometido a ensayo puede incluir retardo variable. Para comparar las señales de referencia y degradadas, ambas señales están alineadas en el tiempo entre sí. PESQ alinea secciones superpuestas de los marcos de voz. En la primera etapa, la estimación del retraso se lleva a cabo sobre la longitud de los archivos mediante el cálculo de la correlación entre los archivos. El retardo obtenido en esta etapa se denomina retardo crudo. En la siguiente etapa, PESQ aplica la detección de actividad de voz a las señales para identificar los segmentos de voz requeridos, generalmente denominados expresiones. La estimación de retardo entre declaraciones es el retardo fino. Este proceso detecta retardo que es variable a lo largo de una expresión, ya que puede ser significativo en redes basadas en paquetes.
Las señales de referencia alineadas en el tiempo y degradadas se transforman en el dominio de frecuencia mediante el uso de una transformada rápida de Fourier (FFT) a corto plazo con una ventana de Hanning sobre fotogramas de 32 ms con un 50% de superposición. Las potencias de las señales originales y degradadas se calculan y almacenan por separado. En la siguiente etapa de operaciones, las bandas de frecuencia se transforman en escala de corteza mediante bandas FFT de binning. Este proceso deforma la escala de frecuencia en Hz a la escala de tono, y las señales resultantes se denominan densidades de potencia de tono. En este proceso, se utiliza un mayor ancho de banda para una señal de alta frecuencia derivada a través del análisis de frecuencia.
Los efectos de filtrado en el sistema sometido a prueba se ecualizan calculando un factor de compensación parcial por cada contenedor de corteza y multiplicando cada marco de la señal de referencia con este factor. Este proceso iguala la referencia a la señal degradada. El factor de compensación se calcula como la relación entre el espectro de señal degradado y el espectro de señal de referencia. Este factor tiene en cuenta el filtrado en los componentes analógicos de la red, como los teléfonos móviles. En la segunda etapa de ecualización, se estima la ganancia de amplitud cuadro a cuadro
del sistema y se usa para ecualizar la señal degradada a la señal de referencia. En ambos casos, la ecualización es parcial y no se cancelan grandes cantidades de filtrado o variación de ganancia; por lo tanto, resulta en errores que se miden. Las densidades de potencia de tono de frecuencia y ecualización de ganancia se transforman en una escala de sonoridad utilizando la ley de Zwicker . Los componentes de frecuencia de tiempo resultantes se denominan densidades de sonoridad.
La diferencia de signos entre las densidades de sonoridad para las señales de referencia y degradadas se conoce como densidad de perturbación cruda, que muestra cualquier diferencia audible introducida por el sistema bajo prueba. Una operación de enmascaramiento aplica un factor de máscara a las densidades de perturbación en bruto que enmascara las pequeñas distorsiones inaudibles en presencia de señales fuertes. La densidad de perturbación obtenida por este proceso se denomina densidad de perturbación absoluta o simétrica. Las perturbaciones simétricas se integran a lo largo del bastidor (intraframe). Los fotogramas consecutivos con una perturbación de fotogramas por encima de un umbral se clasifican como fotogramas defectuosos. Los fotogramas defectuosos pueden ocurrir debido a una estimación de retardo de tiempo incorrecta o caídas de paquetes. En una ventana localizada alrededor de marcos defectuosos, se realiza una nueva estimación de retardo que se utiliza para volver a calcular las densidades de perturbación. El mínimo de las perturbaciones anteriores y actuales se considera la perturbación final en esa ventana de marco defectuoso.
Para modelar la distorsión introducida por el códec utilizado en la red, se calcula una densidad de perturbación asimétrica multiplicando la densidad de perturbación simétrica con un factor de asimetría. El factor de asimetría es la relación de las densidades de potencia de tono distorsionadas y originales elevadas a la potencia de 1,2. Esta densidad de perturbación se denomina perturbación aditiva o asimétrica.
Finalmente, los parámetros de error se convierten en una puntuación de calidad, que es una combinación lineal del valor promedio de perturbación simétrica y el valor promedio de perturbación asimétrica. De Fig. 20.2, las etapas involucradas desde la alineación de niveles hasta la deformación de intensidad en la escala de sonoridad se conocen como la conversión al dominio psicoacústico, y las etapas algorítmicas desde la resta perceptual hasta el cálculo de la puntuación PESQ se conocen como modelado cognitivo.
PESQ da una puntuación conocida como la puntuación PESQ de acuerdo con P. 862. La puntuación de la PESQ está en el rango de -0,5 a 4,5. PESQ se correlaciona con el MOS subjetivo como 0.94 basado en experimentos realizados en bases de datos por . En comparación con las puntuaciones subjetivas (oyentes reales), PESQ da mejores resultados para el habla de mala calidad y resultados pesimistas para una voz de buena calidad. PESQ-LQ proporciona una mejor correlación con las puntuaciones subjetivas que PESQ en una escala de calidad auditiva. Las puntuaciones de PESQ-LQ están en el rango de 1 a 4,5. P862.1 proporciona un mapeo de calidad entre la puntuación PESQ de las mediciones de calidad de banda estrecha y la puntuación de opinión media objetiva de calidad auditiva (MOS-LQO). La recomendación P. 862. 2 proporciona un mapeo de calidad entre la puntuación PESQ de las mediciones de calidad de banda ancha y la puntuación de opinión media objetiva de calidad auditiva. Se puede encontrar más información sobre estas puntuaciones en las recomendaciones de la serie UIT-T-P. 862 y en reference .
PESQ es una operación semidúplex que no captura con precisión el retardo de extremo a extremo, el eco, la pérdida de sonoridad, el tono lateral y los niveles de escucha. A partir de la medición de la Calidad de voz de la puerta de enlace VoIP con interfaces analógicas, se realizan las siguientes observaciones PESQ-LQO utilizando DSLA . Bajo la condición de no pérdida de paquetes, la puntuación PESQ-LQO para el códec G. 711 es 4.32, G. 729A es 3.85 y G. 723.1 es 3.75. Otra interpretación de estos resultados para situaciones de entrega de paquetes y comparación con el modelo E se da como parte de los cálculos del factor R y se presenta en la Tabla 20.4. En el proceso de cálculos de PESQ, se pueden calcular varios otros parámetros. Los proveedores de instrumentos proporcionan estos parámetros como características adicionales a las mediciones de PESQ .
20.1.4
Técnica de monitoreo pasivo
En las técnicas de monitoreo pasivo, la señal de referencia no está presente. Existen dos métodos populares para el monitoreo pasivo de la calidad del habla. La uit ha estandarizado un método de monitoreo no intrusivo basado en señales, P. 563, basado en el resultado de la colaboración entre tres empresas, Psytechnics Ltd. Swissqual y Opticom, que combinaban los mejores parámetros de tres modelos diferentes. P. 563 es una medición objetiva de un solo extremo que hace uso de un mecanismo de producción de voz, y los otros modelos de voz hacen uso de la percepción auditiva. Este algoritmo funciona solo en el habla degradada recibida. No necesitará habla de referencia, y funciona completamente con habla degradada. Las mediciones a través de P.563 derivar varios parámetros del habla recibida clasificados como ruido, habla artificial y habla real. Aquí se ofrece una descripción general de la operación de evaluación de calidad de voz de un solo extremo P. 563.
En ausencia de una señal de referencia, los modelos no tienen conocimiento de la señal original y deben hacerse suposiciones sobre la señal recibida. El modelo P. 563 combina tres principios básicos para evaluar las distorsiones. El primer principio se centra en el sistema de producción de voz humana, modelando el tracto vocal como una serie de tubos, con variaciones anormales de las secciones de los tubos consideradas como degradación. El segundo principio es reconstruir una señal de referencia limpia a partir de la señal degradada para aplicar un modelo perceptivo de referencia completa a partir de entonces y evaluar las distorsiones desenmascaradas durante la reconstrucción. El tercer principio es identificar y estimar las distorsiones específicas encontradas en los canales de voz, como el recorte temporal, la robotización y el ruido. La calidad del habla auditiva se deriva de los parámetros calculados a partir de los tres principios, aplicando una ponderación dependiente de la distorsión.
Al escribir este tema, la técnica basada en P. 563 no fue ampliamente aceptada para las mediciones. Las mediciones basadas en PESQ P. 862 y las estimaciones basadas en modelos electrónicos son más aceptadas popularmente. La principal ventaja de esta técnica P. 563 es su capacidad de monitorear en el extremo degradado sin llamar a referencia. Por lo tanto, puede monitorear mejor las llamadas de larga distancia fuera del laboratorio y en las implementaciones, lo que será mucho más fácil de realizar que muchas otras mediciones. El método basado en P. 563 también se puede incrustar como parte
de la puerta de enlace receptora de forma similar a E-model y RTCP-XR. Las operaciones P. 563 se pueden usar en muestras que se entregan en las interfaces de voz de modulación de código de impulsos (PCM).
Se puede encontrar más información sobre la técnica P. 563 en P. 563 y . La partitura de MOS producida por P.563 y otras técnicas están ampliamente difundidas y son necesarias para promediar los resultados de múltiples pruebas para lograr una métrica de calidad estable sobre múltiples resultados. P. 563 se correlaciona con MOS subjetivos como 0.85 a 0.9 en base a los experimentos realizados en una base de datos por , y PESQ se reporta como 0.94.