20.1
aby porównać jakość głosu i uzyskać parametry przyczyniające się do jakości głosu, należy wiedzieć, w jaki sposób mierzy się jakość głosu i jakie są cele jakości. Podstawowe ustawienia testowe dla pomiarów głosu VoIP podano w temacie 13. W tym temacie omówiono jakość głosu jako średnią ocenę opinii (MOS), różne klasyfikacje, parametry wpływające na jakość głosu i ulepszenia. Pomiary jakości głosu dla MOS są klasyfikowane jako subiektywne i obiektywne.
funkcjonalna reprezentacja niektórych popularnych technik pomiaru jakości głosu jest zilustrowana na Fig. 20.1 . Na rysunku pokazano, że głos pochodzi z
tabeli 20.1. Porównanie jakości PSTN i VoIP
| atrybuty | PSTN | VoIP |
| zniekształcenia na | zniekształcenia spowodowane kilkoma | brak transmisji analogowej |
| linia analogowa | 1000-metrowe linie z | zniekształcenia z połączeniami VoIP. |
| lokalizacja DLC lub CO | ||
| anulowanie ECHA | osiągnięte poprzez utratę | cancellery ECHA klasy nośnej |
| w przypadku połączeń krajowych | stosuje się planowanie i małe opóźnienia | . |
| automatyczne wzmocnienie | nie włączone | możliwe włączenie dla |
| Kontrola | lepsze postrzeganie mowy | |
| poziomy lub jakość odsłuchu | ||
| doświadczenie. | ||
| jakość głosu | monitorowanie, takie jak GR- | RTCP-XR i GR – 909 są |
| monitoring | 909 są włączone | włączone do wielu VoIP |
| do PSTN | ||
| przepustowość lub bit | 64 kbps stałe na cyfrowym | zmienna przepustowość, Zwykle |
| Oceń | TDM. Kanały DCME | wymagają więcej na fizycznym |
| użyj interfejsów 16, 24, 32 i | niż PSTN. Faks | |
| 40 kbps, który degraduje fax | usługi mogą uzyskać więcej | |
| jakość | przepustowość lub redundancja w | |
| transmisja. | ||
| połączenia faksowe | ograniczone przez | wykorzystują krótkie linie końcowe. Stąd fax |
| koniec linii przesyłowej | dostawa może być lepsza przy użyciu | |
| charakterystyka | VoIP. Jednak nie może | |
| być kwestie interoperacyjności dla | ||
| wysyłam faks. | ||
| głos i dane | głównie dla połączeń głosowych, | Usługi internetowe i VoIP mogą |
| niektóre usługi mogą ponownie wykorzystywać | skalowanie wraz z danymi i | |
| kanały głosowe dla danych | wymagania dotyczące usług medialnych. | |
| funkcje połączeń głosowych | funkcje ograniczone i | kilka funkcji jest oferowanych jako |
| drogie dla kilku | za darmo. | |
| funkcje serwisu | ||
| interfejsy głosowe | ograniczone interfejsy | wiele interfejsów i usług. |
| długi dystans | długi dystans jest kosztowny | Zwykle wolny lub znacznie niższy |
| stawki. | ||
| transkodowanie | wiele poziomów | End – to – end bezpośrednie kodowanie może być |
| transkodowanie dla inter – | ||
| połączenia regionalne | dostępne wsparcie. | |
| Wideband wsparcie | połączenia głosowe są z | Wideband end-to-end głos jest |
| wąskie pasmo | możliwe, że może przekraczać | |
| jakość PSTN. |
bramka wysyłająca do bramki odbiorczej. Brama odbiorcza jest pokazana z kilkoma bardziej rozbudowanymi blokami do tworzenia pełnego obrazu modelu E, który jest używany do estymacji czynnika R, dodatkowych wskaźników jakości i operacji Real-Time Transport Control Protocol-Extended Reports (RTCP-XR). W modelu E wykorzystywane są RTP, RTCP, bufor jitter i całkowite parametry sygnału systemu. Przy obliczaniu współczynnika R i innych pochodnych parametrów,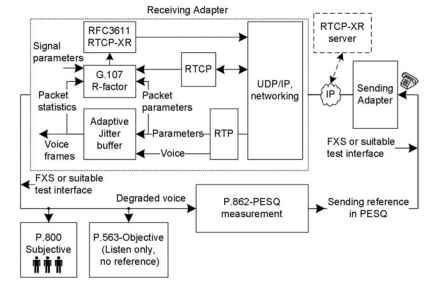
rysunek 20.1. Przegląd popularnych pomiarów jakości głosu.
RTCP-XR może wysyłać pakiety do aplikacji wewnętrznych, bramy docelowej i serwera RTCP-XR. Podsumowując, nieintrusive r-factor jest obiektywną estymacją, która znajduje się w ramach implementacji VoIP, a dodatkowe oprogramowanie jest wymagane w bramce do estymacji r-factor. W perceptual evaluation of speech quality (PESQ) instrumenty takie jak MultiDSLA przesyłają mowę referencyjną przez testowany system VoIP i oceniają zdegradowaną mowę referencyjną. Ten pomiar jest aktywny, a bramki VoIP nie muszą nic wiedzieć o pomiarze. W subiektywnym słuchaniu wielu słuchaczy oceni jakość głosu. W P. 563 głos jest analizowany całkowicie na odebranym sygnale zdegradowanym, a oryginalne odniesienie nie jest wymagane. P. 563 jest podobny do subiektywnego odsłuchu, ale jest oceniany przez instrumenty lub procesory. Każda z tych technik ma inną skalę jakości głosu. W połączeniach głosowych VoIP między A i B pomiary głosu są wykonywane jako half-duplex, co oznacza, że pomiary są wykonywane jako a do B lub B Do a, pojedynczo. Ze względu na typ odsłuchu półdupleksu, pomiary te są określane jako testy jakości odsłuchu (LQ). Przyrostek LQ jest dołączany podczas prezentowania wyników testów półdupleksowych, a testy obiektywne są dodatkowo przyrostkiem ” O ” jako LQO.
20.1.1
subiektywna technika pomiaru
w subiektywnej ocenie jakości głosu, jakość głosu MOS jest oceniana przez grupę rzeczywistych słuchaczy płci męskiej i żeńskiej. Jest to rzeczywisty test odsłuchowy do oceny MOS. Zalecenia P. 800 i P. 830 służą do oceny subiektywnej wydajności kodeków mowy
. Te same testy są rozszerzone na jakość głosu VoIP. Grupa osób uczestniczy w nagrywaniu subiektywnych partytur. Wiele fraz testowych jest rejestrowanych, a następnie testerzy (grupa osób) słuchają ich w różnych warunkach. Testy te są wykonywane w specjalnych pomieszczeniach z hałasem w tle, a inne czynniki środowiskowe są kontrolowane w celu wykonania testu. Warunki badania podane są w. Subiektywne techniki pomiarowe są klasyfikowane jako absolute category rating (ACR), degradation category rating (DCR) i comparison category rating (CCR).
I N ACR, uczestnicy słuchają nagranych próbek mowy, które zostały przetworzone przez kilka połączeń testowych. W ocenie powinno uczestniczyć co najmniej 16 osób testujących (słuchaczy). Podczas słuchania użytkownicy oceniają połączenie w skali od 1 do 5 MOS. Średnie wartości ocen użytkowników są uważane za generowanie ogólnej jakości połączenia.
W teście DCR obecne są dwie próbki mowy. Pierwsza próbka mowy jest próbką referencyjną o predefiniowanej jakości. Próbka odnosi się do mowy trwającej kilka sekund. Druga próbka mowy jest wersją zdegradowaną. Słuchacze muszą porównać wersję zdegradowaną z referencją w skali degradacji od 1 do 5. Tutaj 5 jest niesłyszalną degradacją, a 1 oznacza najgorszą degradację. Wyniki podsumowano jako zdegradowany MOS.
w testach CCR użytkownicy proszeni są o odsłuchanie dwóch zestawów próbek, z których jeden odpowiada referencji, a drugi degradacji. Test ten jest podobny do DCR, z tą różnicą, że kolejność próbek prezentowanych słuchaczom zmienia się w różnych iteracjach. Kolejność odniesienia i degradacji nie jest deklarowana słuchaczowi. Słuchacze proszeni są o ocenę porównawczą drugiej próbki w stosunku do pierwszej w skali od -3 do 3 zgodnie z P. 800 Załącznik-D. Prezentując wyniki, „3 „reprezentuje znacznie lepszą jakość, a” -3 ” reprezentuje najgorszą jakość w względnej skali. Wynik jakości jest odwzorowany na MOS. Ocena MOS jest dozwolona od 1 do 5, ale ocena użytkownika powyżej 4.5 jest ograniczona do 4.5.
testy subiektywne są zaangażowane w procedury i jest to kosztowny wysiłek. Jest on ograniczony do mniejszej liczby iteracji, aby ocenić każdy nowy algorytm lub kodeki mowy. Trudno jest utrzymać spójność, tak jak obiektywne testy oparte na instrumentach.
20.1.2
obiektywne Techniki Pomiarowe
obiektywne metody to pomiary i obliczenia. Oczekuje się, że wyniki będą spójne w kilku pomiarach. Istnieje kilka metod obiektywnych i są klasyfikowane jako metody aktywne i pasywne.aktywne techniki monitorowania. Pomiar aktywny nazywany jest monitoringiem natrętnym lub monitoringiem offline ze względu na zaangażowanie sygnałów zewnętrznych.
w celu uzupełnienia subiektywnej jakości odsłuchu opracowywane są testy przy użyciu obiektywnych metod o niższych kosztach. KPN opracował P. 861 (obecnie jest to przestarzałe) perceptual speech quality measure (PSQM) do oceny wydajności kodeków. British Telecom opracował system perceptual analysis measurement system (PAMS) do pomiarów sieciowych. P. 862 PESQ wynikało z konkursu ITU. Wydajność PAMS i nowej wersji PSQM, PSQM99, były podobne, więc współpracownicy zostali zaproszeni do łączenia algorytmów. Zaowocowało to PESQ, które jest nieco lepsze od jego składników.
metody te mierzą zniekształcenia wprowadzone przez system przesyłowy i kodek poprzez porównanie oryginalnego pliku referencyjnego wysłanego do systemu na interfejsie telefonicznym z odebranym sygnałem odebranym na innym interfejsie telefonicznym. PSQM został opracowany do testowania laboratoryjnego kodeków mowy. PAMS i PESQ są przeznaczone do testowania sieci. Zastosowanie instrumentów do jakości głosu jest znacznie prostsze w porównaniu z pomiarami subiektywnymi lub pasywnymi. Dostawcy instrumentów zapewniają również dodatkowe parametry, aby pomóc w identyfikacji źródeł degradacji poprzez pomiary. Aby uzyskać więcej informacji na temat różnych funkcji, zapoznaj się z niektórymi instrumentami podanymi w temacie 13.
pisząc ten temat, PESQ był powszechnie wspierany w instrumentach. PESQ zostało zatwierdzone przez ITU w marcu 2001 r. jako zalecenie P. 862, zastępując P.861 PSQM. PESQ połączyło kilka najlepszych zalet PAMS i PSQM. Jest dokładny w przewidywaniu subiektywnych wyników testów i jest niezawodny w trudnych warunkach sieciowych, takich jak zmienne opóźnienia, filtrowanie na interfejsach analogowych i obsługa zarówno szerokopasmowego, jak i wąskopasmowego. PESQ daje wynik w skali od -0,5 do 4,5. Funkcja mapowania z wyniku P. 862 PESQ do średniego subiektywnego wyniku P. 800-LQ MOS, co czyni go
PESQ-LQO dla głosu wąskopasmowego. LQO oznacza cel jakości odsłuchu. PESQ-LQ leży od 1 do 4,5. MOS 4.5 to maksymalna jakość osiągnięta dla wyraźnego, niezakłóconego stanu. Przegląd algorytmu PESQ znajduje się tutaj. Zaleca się, aby zapoznać się z itu P. 862 rodziny zaleceń, oprogramowania i niektórych komercyjnych broszur instrumentów więcej szczegółów .
20.1.3
pomiar PESQ
ludzka percepcja słuchowa jest podstawową koncepcją pesq i jej poprzedników PAMS i PSQM. Model percepcyjny jest używany do prawidłowego rozróżniania zniekształceń słyszalnych i niesłyszalnych, a to okazało się najlepszym sposobem dokładnego przewidywania słyszalności i irytacji złożonych zniekształceń. Oprócz ilości zniekształceń, rozkład słyszalnych zniekształceń może znacznie zwiększyć dokładność prognoz jakości.
PESQ mierzy jednokierunkową jakość głosu, co oznacza operację half-duplex pomiaru. Ocenia jakość zniekształconego sygnału mowy, który został zakodowany i przesłany przez sieć, porównując go z oryginalnym niezakłóconym sygnałem. Oryginalna i zniekształcona mowa jest odwzorowana na psychofizyczne reprezentacje, które pasują do sposobu, w jaki ludzie doświadczają mowy.
jakość zniekształconej mowy oceniana jest na podstawie różnic w przedstawieniach psychofizycznych. Operacja PESQ wykorzystuje dwie główne klasy operacji logarytmicznych-mianowicie konwersję sygnałów do dziedziny psycho-akustycznej i modelowanie kognitywne. Funkcjonalna reprezentacja algorytmu PESQ jest przedstawiona na Rys. 20.2. Producenci przyrządów do pomiaru PESQ oprócz pomiarów PESQ obejmują kilka dodatkowych operacji w celu wyodrębnienia parametrów analizy sygnału i zakłóceń.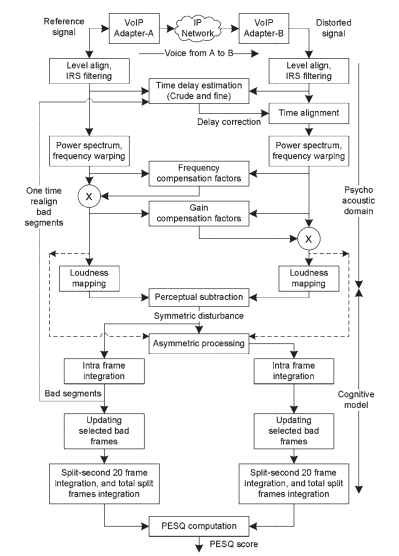
rysunek 20.2. Reprezentacje funkcjonalne algorytmu PESQ.
przetwarzanie przeprowadzane przez algorytm PESQ obejmuje etapy wymienione poniżej. Kroki podsumowania podano tutaj; kilka szczegółów na temat PESQ podano w .
w pierwszym etapie przetwarzania zarówno sygnał referencyjny, jak i sygnał zdegradowany są skalowane do tego samego stałego poziomu mocy. Skalowanie to jest konieczne, ponieważ Sygnał odniesienia nie musi znajdować się na określonym poziomie, a wzmocnienie testowanego systemu jest nieznane przed testowaniem. PESQ zakłada, że subiektywny poziom słuchania jest stałym 79 dBSPL w punkcie odniesienia ucha . W przypadku normalizacji mocy poziomy sygnału elektrycznego są znormalizowane do-26dbov (tj. Normalizacja poziomu sygnału jest stosowana zarówno do sygnału referencyjnego, jak i zdegradowanego, aby doprowadzić je do tego poziomu.
modele percepcyjne, takie jak PESQ, powinny uwzględniać charakterystykę słuchawek telefonicznych, ponieważ subiektywne słuchanie może wykorzystywać słuchawki telefoniczne. W PESQ ścieżka odbioru słuchawek jest modelowana za pomocą pośredniego filtra pasmowo-pasmowego systemu odniesienia (IRS) w dziedzinie częstotliwości. Proces ten uwzględnia wpływ elementów elektrycznych i akustycznych słuchawki. Zarówno sygnał referencyjny, jak i zdegradowany są filtrowane przez IRS.
testowany system może zawierać zmienne opóźnienie. Aby porównać sygnały referencyjne i zdegradowane, oba sygnały są wyrównane w czasie. PESQ wyrównuje nakładające się części ramek mowy. W pierwszym etapie estymacja opóźnienia jest przeprowadzana na długości plików poprzez obliczenie korelacji między plikami. Opóźnienie uzyskane w tym etapie nazywa się opóźnieniem surowym. W kolejnym etapie PESQ stosuje wykrywanie aktywności głosowej do sygnałów w celu identyfikacji wymaganych segmentów mowy Zwykle nazywanych wypowiedziami. Opóźnienie między wypowiedziami to opóźnienie grzywny. Proces ten wykrywa opóźnienie, które jest zmienne w długości wypowiedzi, ponieważ może to być istotne w sieciach opartych na pakietach.
wyrównane czasowo sygnały odniesienia i zdegradowane są przekształcane w dziedzinę częstotliwości za pomocą krótkotrwałej szybkiej transformacji Fouriera (FFT) z oknem Hanninga na klatkach 32-ms z 50% nakładaniem się na siebie. Potęgi sygnałów oryginalnych i zdegradowanych są obliczane i przechowywane oddzielnie. W kolejnym etapie operacji pasma częstotliwości są przekształcane do skali kory przez binowanie pasm FFT. Proces ten wypacza skalę częstotliwości w Hz do skali skoku, a uzyskane sygnały nazywane są gęstościami mocy skoku. W tym procesie wyższa przepustowość jest wykorzystywana do sygnału wysokiej częstotliwości uzyskanego poprzez analizę częstotliwości.
efekty filtrowania w badanym układzie są wyrównywane przez obliczenie współczynnika kompensacji częściowej na każdy pojemnik kory i mnożenie każdej klatki sygnału odniesienia przez ten współczynnik. Proces ten wyrównuje odniesienie do sygnału zdegradowanego. Współczynnik kompensacji oblicza się jako stosunek widma sygnału zdegradowanego do widma sygnału odniesienia. Czynnik ten bierze pod uwagę filtrowanie w analogowych elementach sieci, takich jak telefony komórkowe. W drugim etapie wyrównania ocenia się amplitudę
wzmocnienia układu klatka po klatce i wykorzystuje się ją do wyrównania sygnału zdegradowanego do sygnału odniesienia. W obu przypadkach wyrównanie jest częściowe i duże ilości zmienności filtrowania lub wzmocnienia nie są anulowane; w związku z tym powoduje to mierzenie błędów. Gęstość mocy wyrównanej częstotliwością i wzmocnieniem jest przekształcana w skalę głośności za pomocą prawa Zwickera . Powstałe składowe czasowo-częstotliwościowe nazywane są gęstościami głośności.
sygnowana różnica między gęstością głośności dla sygnałów odniesienia i sygnału zdegradowanego jest znana jako gęstość zakłóceń surowych, która pokazuje wszelkie słyszalne różnice wprowadzone przez testowany system. Operacja maskowania stosuje współczynnik maski na gęstościach zakłóceń surowych, który maskuje małe niesłyszalne zniekształcenia w obecności głośnych sygnałów. Gęstość zakłóceń uzyskana w tym procesie nazywana jest absolutną lub symetryczną gęstością zakłóceń. Zakłócenia symetryczne są zintegrowane na całej długości ramki (intraframe). Kolejne klatki z zakłóceniem ramki powyżej progu są klasyfikowane jako złe klatki. Złe klatki mogą wystąpić z powodu nieprawidłowego oszacowania opóźnienia czasowego lub spadku pakietów. W zlokalizowanym oknie wokół złych ramek dokonuje się nowego oszacowania opóźnienia, które służy do przeliczenia gęstości zakłóceń. Minimum wcześniejszych i obecnych zakłóceń jest uważane za ostateczne zakłócenie w tym złym oknie ramy.
aby modelować zniekształcenia wprowadzone przez kodek używany w sieci, asymetryczna gęstość zakłóceń jest obliczana przez pomnożenie symetrycznej gęstości zakłóceń przez współczynnik asymetrii. Współczynnik asymetrii to stosunek zniekształconych i oryginalnych gęstości mocy pitch podniesionych do mocy 1,2. To zaburzenie nazywa się zaburzeniem addytywnym lub asymetrycznym.
wreszcie, parametry błędu są konwertowane na wynik jakości, który jest liniową kombinacją średniej symetrycznej wartości zakłócenia i średniej asymetrycznej wartości zakłócenia. Z Fot. 20.2, etapy zaangażowane od wyrównania poziomu do wypaczenia intensywności na skali głośności są znane jako konwersja do domeny psycho – akustycznej, a etapy algorytmiczne od odejmowania percepcyjnego do obliczania wyniku PESQ są znane jako modelowanie kognitywne.
PESQ daje wynik znany jako wynik PESQ zgodnie z P. 862. Wynik PESQ mieści się w zakresie od -0,5 do 4,5. PESQ jest skorelowane z subiektywnym MOS jako 0,94 na podstawie eksperymentów przeprowadzonych na bazach danych przez . W porównaniu z subiektywnymi (rzeczywistymi wynikami słuchaczy), PESQ daje lepsze wyniki dla słabej jakości mowy i pesymistyczne wyniki dla dobrej jakości głosu. PESQ-LQ zapewnia lepszą korelację z subiektywnymi wynikami niż PESQ w skali jakości odsłuchu. Wyniki PESQ-LQ mieszczą się w zakresie od 1 do 4,5. P862. 1 zapewnia mapowanie jakości pomiędzy wąskopasmowymi pomiarami jakości PESQ a obiektywną średnią ocen słuchu (Mos-LQO). Zalecenie P. 862.2 zapewnia mapowanie jakości pomiędzy szerokopasmowymi pomiarami jakości PESQ a obiektywną średnią ocen jakości słuchu. Więcej informacji na temat tych wyników można znaleźć w zaleceniach serii ITU-T-P. 862 oraz w referencji .
PESQ to operacja half-duplex, która nie rejestruje dokładnie na opóźnieniu end-to-end, echu, utracie głośności, poziomie sidetone i odsłuchu. Z pomiaru jakości głosu bramki VoIP z interfejsami analogowymi wynika, że następujące obserwacje PESQ-LQO są dokonywane za pomocą DSLA . W warunkach braku utraty pakietów, wynik PESQ-LQO dla kodeka G. 711 wynosi 4,32, G. 729A 3,85, a G. 723.1 3,75. Inna interpretacja tych wyników dla sytuacji upuszczania pakietów i porównanie z Modelem E podano jako część obliczeń współczynnika R i przedstawiono w tabeli 20.4. W procesie obliczeń PESQ można obliczyć kilka innych parametrów. Dostawcy przyrządów dostarczają te parametry jako dodatkowe funkcje do pomiarów PESQ .
20.1.4
pasywna Technika monitorowania
I N pasywne techniki monitorowania, Sygnał odniesienia nie jest obecny. Istnieją dwie popularne metody monitorowania jakości mowy pasywnej. ITU ustandaryzowało nieintruzyjną metodę monitorowania opartą na sygnale, P. 563, opartą na wyniku współpracy trzech firm, Psytechnics Ltd., Swissqual i Opticom, które połączyły najlepsze parametry trzech różnych modeli. P. 563 jest jednostronnym obiektywnym pomiarem wykorzystującym mechanizm produkcji mowy, a inne modele mowy wykorzystują percepcję słuchu. Algorytm ten działa tylko na odebranej zdegradowanej mowie. Nie będzie potrzebował mowy referencyjnej i całkowicie operuje na zdegradowanej mowie. Pomiary przez P.563 wyprowadza kilka parametrów z odebranej mowy sklasyfikowanej jako szum, sztuczna mowa i rzeczywista mowa. Przegląd operacji P. 563 single-ended speech-quality assessment znajduje się tutaj.
W przypadku braku sygnału odniesienia modele nie mają wiedzy o oryginalnym sygnale i należy przyjąć założenia dotyczące odebranego sygnału. Model P. 563 łączy trzy podstawowe zasady oceny zniekształceń. Pierwsza zasada koncentruje się na systemie produkcji głosu ludzkiego, modelując układ głosowy jako serię rur, z nieprawidłowymi zmianami sekcji rur uznawanych za degradację. Drugą zasadą jest odtworzenie czystego sygnału odniesienia z sygnału zdegradowanego w celu zastosowania pełnego modelu percepcyjnego i oceny zniekształceń zdemaskowanych podczas rekonstrukcji. Trzecią zasadą jest identyfikacja i oszacowanie specyficznych zniekształceń występujących w kanałach głosowych, takich jak obcinanie temporalne, robotyzacja i szum. Jakość słuchania mowy opiera się na obliczonych parametrach z trzech zasad, stosując wagę zależną od zniekształceń.
pisząc ten temat, technika oparta na P. 563 nie była powszechnie akceptowana do pomiarów. P. 862 pomiary oparte na PESQ i estymacje oparte na modelu E są bardziej powszechnie akceptowane. Główną zaletą tej techniki P. 563 jest jej zdolność do monitorowania na zdegradowanym końcu bez powoływania się na odniesienie. Dzięki temu może lepiej monitorować połączenia międzymiastowe poza laboratorium i we wdrożeniach, co będzie znacznie prostsze w prowadzeniu niż wiele innych pomiarów. Metoda oparta na P. 563 może być również osadzona jako część
bramki odbiorczej podobnej do modelu E i RTCP-XR. Operacje P. 563 mogą być używane na próbkach, które są dostarczane na interfejsach głosowych pulse code modulation (PCM).
więcej informacji na temat techniki P. 563 można znaleźć w P. 563 i . Wynik MOS wyprodukowany przez P.563 i inne techniki są szeroko rozpowszechnione i są niezbędne do uśredniania wyników wielu testów w celu osiągnięcia stabilnej jakości metryki w stosunku do wielu wyników. P. 563 jest skorelowany z subiektywnym MOS jako 0,85 do 0,9 w oparciu o eksperymenty przeprowadzone na bazie danych przez, a PESQ jest zgłaszane jako 0,94.