20.1
Pour comparer la qualité de la voix, et pour arriver aux paramètres contribuant à la qualité de la voix, il est nécessaire de savoir comment la qualité de la voix est mesurée et quels sont les objectifs de qualité. La configuration de test de base pour les mesures vocales VoIP est donnée au sujet 13. Dans ce sujet, la qualité de la voix en tant que scores d’opinion moyens (MOS), diverses classifications, paramètres influençant la qualité de la voix et améliorations sont discutées. Les mesures de qualité vocale pour MOS sont classées comme subjectives et objectives.
Une représentation fonctionnelle de certaines techniques de mesure de qualité vocale populaires est illustrée à la Fig. 20.1 . Sur la figure, la voix provient de
Tableau 20.1. Comparaisons de qualité RTPC et VoIP
| Attributs | RTPC | VoIP |
| Distorsions sur | Distorsions dues à plusieurs | Pas de transmission analogique |
| ligne analogique | lignes de 1000 pieds à partir de distorsions | avec des appels VoIP. |
| Emplacement DLC ou CO | ||
| Annulation d’écho | Obtenue par perte | Annuleurs d’écho de qualité porteuse |
| sur les appels nationaux | la planification et les faibles retards | sont utilisés. |
| Gain automatique | Non incorporé | Possible d’incorporer pour |
| contrôle | meilleure perception de la parole | |
| niveaux ou qualité d’écoute | ||
| expérience. | ||
| La qualité vocale | La surveillance telle que GR- | RTCP-XR et GR-909 sont |
| surveillance | 909 sont incorporés | incorporés dans de nombreuses VoIP |
| dans les déploiements PSTN | . | |
| Bande passante ou bit | 64 kbps fixe sur bande passante numérique | variable, généralement |
| taux | TDM. Canaux DCME | nécessite plus d’informations physiques |
| utilisez les interfaces 16, 24, 32 et | que le RTPC. Télécopie | |
| 40 les kbps qui dégradent les services de fax | peuvent en obtenir plus | |
| Qualité | bande passante ou redondance dans | |
| transmission. | ||
| Appels de télécopie | Les performances limitées par | Utilisent des lignes d’extrémité courtes. Par conséquent, fax |
| ligne de transmission d’extrémité | la livraison peut être meilleure en utilisant | |
| caractéristiques | VoIP. Cependant, il pourrait y avoir | |
| être des problèmes d’interopérabilité pour | ||
| envoi de fax. | ||
| Voix et données | Principalement pour les appels vocaux, | Service Internet et VoIP peuvent |
| certains services peuvent réutiliser l’échelle | avec les données et | |
| canaux vocaux pour les données | exigences de service multimédia. | |
| Fonctions d’appel vocal | Fonctions limitées et | Plusieurs fonctionnalités sont proposées comme |
| cher pour plusieurs | gratuit. | |
| caractéristiques du service | ||
| Interfaces vocales | Interfaces limitées | Interfaces et services multiples. |
| Longue distance | Longue distance est coûteuse | Généralement gratuite ou beaucoup plus faible |
| tarifs. | ||
| Transcodage | Plusieurs niveaux de | Le codage direct de bout en bout peut être |
| transcodage pour inter- | utilisé sur la base de la | |
| appels régionaux | support disponible. | |
| Prise en charge à large bande | Les appels vocaux sont de | La voix de bout en bout à large bande est |
| bande étroite | possible qui peut dépasser | |
| Qualité RTPC. |
la passerelle d’envoi à la passerelle de réception. La passerelle de réception est affichée avec des blocs plus étendus pour créer une vue d’ensemble du modèle électronique, qui est utilisé pour l’estimation du facteur R, des métriques de qualité supplémentaires et l’opération RTCP-XR (Real-Time Transport Control Protocol – Extended Reports). Dans le modèle électronique, les paramètres RTP, RTCP, tampon de gigue et signal système total sont utilisés. Lors du calcul du facteur R et d’autres paramètres dérivés,
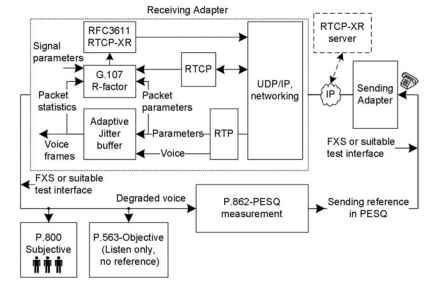
Figure 20.1. Aperçu des mesures de qualité vocale populaires.
RTCP-XR peut envoyer des paquets aux applications internes, à la passerelle de destination et au serveur RTCP-XR. En résumé, le facteur R non intrusif est une estimation objective qui fait partie de la mise en œuvre de la VoIP, et un logiciel supplémentaire est requis dans la passerelle pour l’estimation du facteur R. Dans l’évaluation perceptuelle de la qualité de la parole (PESQ), des instruments tels que MultiDSLA envoient la parole de référence via le système VoIP testé et évaluent la parole dégradée avec la parole de référence. Cette mesure est active et les passerelles VoIP n’ont pas besoin de savoir quoi que ce soit sur la mesure. En écoute subjective, plusieurs auditeurs évalueront la qualité de la voix. En P.563, la voix est entièrement analysée sur le signal dégradé reçu et la référence d’origine n’est pas requise. P.563 est similaire à l’écoute subjective, mais elle est évaluée par les instruments ou les processeurs. Chacune de ces techniques arrive à une échelle différente de la qualité de la voix. Dans un appel vocal VoIP entre A et B, les mesures vocales sont effectuées en semi-duplex, ce qui signifie que les mesures sont effectuées de A à B ou de B à A, une à la fois. En raison du type de test d’écoute semi-duplex, ces mesures sont appelées tests de qualité d’écoute (LQ). Le suffixe LQ est ajouté lors de la présentation des résultats des tests semi-duplex, et les tests objectifs sont en outre suffixés avec « O » comme LQO.
20.1.1
Technique de mesure subjective
Dans l’évaluation subjective de la qualité vocale, la qualité vocale MOS est évaluée par le groupe d’auditeurs masculins et féminins réels. C’est le test d’écoute réel pour évaluer le MOS. Les recommandations P.800 et P.830 sont utilisées pour évaluer les performances subjectives des codecs speech
. Les mêmes tests sont étendus à la qualité de la voix VoIP. Un groupe de personnes participe à l’enregistrement des scores subjectifs. Plusieurs phrases de test sont enregistrées, puis les sujets de test (groupe de personnes) les écoutent dans différentes conditions. Ces tests sont effectués dans des pièces spéciales avec des bruits de fond et d’autres facteurs environnementaux sont contrôlés pour l’exécution des tests. Les conditions d’essai sont données dans. Les techniques de mesure subjectives sont classées en catégorie absolue (ACR), catégorie de dégradation (DCR) et catégorie de comparaison (CCR).
En ACR, les participants écoutent des échantillons de parole enregistrés qui ont été traités via plusieurs connexions de test. Un minimum de 16 sujets de test (auditeurs) devraient participer à l’évaluation. Lors de l’écoute, les utilisateurs évaluent l’appel sur une échelle de 1 à 5 MOS. Les valeurs moyennes des évaluations des utilisateurs sont prises en compte pour générer la qualité globale des appels.
Dans un test DCR, deux échantillons de parole sont présents. Le premier échantillon de parole est un échantillon de référence avec une qualité prédéfinie. L’échantillon ici fait référence à un discours de plusieurs secondes. L’autre exemple de discours est une version dégradée. Les auditeurs doivent comparer la version dégradée avec une référence sur une échelle de dégradation de 1 à 5. Ici, 5 est une dégradation inaudible et 1 représente la dégradation la plus grave. Les résultats sont résumés sous forme de MOS dégradés.
Dans les tests CCR, les utilisateurs sont invités à écouter deux ensembles d’échantillons, l’un correspondant à la référence et l’autre à dégradé. Ce test est similaire à DCR, sauf que l’ordre des échantillons présentés aux auditeurs est modifié dans différentes itérations. L’ordre de référence et dégradé n’est pas déclaré à l’auditeur. Les auditeurs sont invités à donner une note comparative d’un deuxième échantillon par rapport au premier sur une échelle de -3 à 3 selon l’annexe-D P.800. Dans la présentation des résultats, « 3 » représente une bien meilleure qualité et « -3 » représente la moins bonne qualité sur une échelle relative. Le score de qualité est mappé à MOS. La note MOS autorisée est de 1 à 5, mais une note d’utilisateur supérieure à 4,5 est limitée à 4,5.
Des tests subjectifs sont impliqués dans les procédures, et c’est un effort coûteux. Il est limité à moins d’itérations pour évaluer tout nouvel algorithme ou codecs vocaux. Il est difficile de maintenir la cohérence comme les tests objectifs basés sur des instruments.
20.1.2
Techniques de mesure objectives
Les méthodes objectives sont les mesures et les calculs. On s’attend à ce que les résultats soient cohérents entre plusieurs mesures. Plusieurs méthodes objectives existent et sont classées comme méthodes actives et passives.
* Techniques de surveillance active de PESQ Techniques de surveillance Active. La mesure active est appelée surveillance intrusive ou surveillance hors ligne en raison de l’implication de signaux externes.
Dans un effort pour compléter la qualité d’écoute subjective, des tests avec des méthodes objectives à moindre coût sont développés. KPN a développé la mesure de la qualité de la parole perceptuelle (PSQM) P.861 (aujourd’hui obsolète) pour l’évaluation des performances des codecs. British Telecom a développé le système de mesure d’analyse perceptuelle (PAMS) pour les mesures de réseau. Le PESQ P.862 est le résultat d’un concours de l’ IT. Les performances de PAMS et d’une nouvelle version de PSQM, PSQM99, étant similaires, les contributeurs ont été invités à combiner les algorithmes. Cela a abouti à PESQ, qui est légèrement meilleur que ses constituants.
Ces procédés mesurent la distorsion introduite par un système de transmission et un codec en comparant un fichier de référence original envoyé dans le système sur une interface téléphonique avec le signal altéré reçu reçu sur une autre interface téléphonique. PSQM a été développé pour les tests en laboratoire des codecs vocaux. PAMS et PESQ sont conçus pour les tests de réseau. L’utilisation d’instruments pour la qualité de la voix est beaucoup plus simple par rapport aux mesures subjectives ou passives. Les fournisseurs d’instruments fournissent également les paramètres dérivés supplémentaires pour aider à identifier les sources de dégradations par des mesures. Reportez-vous à certains instruments donnés au sujet 13 pour plus de détails sur diverses fonctionnalités.
Lors de la rédaction de ce sujet, PESQ a été populairement soutenu dans les instruments. PESQ a été approuvé par l’U en mars 2001 en tant que recommandation P.862, remplaçant P.861 MQP. Le PESQ a combiné plusieurs des meilleurs mérites du PAMS et du PSQM. Il est précis dans la prédiction des scores de test subjectifs, et il est robuste dans des conditions de réseau sévères telles que des retards variables, un filtrage aux interfaces analogiques et la prise en charge des bandes large et étroite. PESQ produit un score qui se situe sur une échelle de -0,5 à 4,5. Une fonction de mappage d’un score P.862 PESQ à un score MOS subjectif moyen P.800-LQ a été fournie, ce qui en fait
PESQ–LQO pour la voix à bande étroite. LQO désigne un objectif de qualité d’écoute. PESQ-LQ se situe de 1 à 4,5. Un MOS de 4.5 est la qualité maximale obtenue pour une condition claire et non faussée. Un aperçu de l’algorithme PESQ est donné ici. Il est suggéré de se référer à la famille de recommandations P.862 de l’U, aux logiciels et à certaines brochures sur les instruments commerciaux pour plus de détails.
20.1.3
La mesure PESQ
La perception auditive humaine est le concept de base derrière PESQ et ses prédécesseurs PAMS et PSQM. Un modèle perceptuel est utilisé pour distinguer correctement les distorsions audibles et inaudibles, ce qui s’est avéré être le meilleur moyen de prédire avec précision l’audibilité et l’ennui des distorsions complexes. En plus de la quantité de distorsion, la distribution de la distorsion audible pourrait rendre les prédictions de qualité beaucoup plus précises.
PESQ mesure la qualité vocale unidirectionnelle, ce qui signifie l’opération de mesure en semi-duplex. Il évalue la qualité d’un signal de parole déformé qui a été codé et transmis sur le réseau en le comparant au signal non déformé d’origine. Le discours original et déformé est cartographié sur des représentations psychophysiques qui correspondent à la façon dont les humains vivent la parole.
La qualité de la parole déformée est jugée en fonction des différences de représentations psychophysiques. L’opération PESQ utilise deux grandes classes d’opérations logarithmiques – à savoir la conversion des signaux dans le domaine psycho-acoustique et la modélisation cognitive. Une représentation fonctionnelle de l’algorithme PESQ est donnée à la Fig. 20.2. Les fabricants d’instruments pour la mesure PESQ incluent plusieurs opérations supplémentaires pour extraire les paramètres d’analyse du signal et les altérations en plus des mesures PESQ.
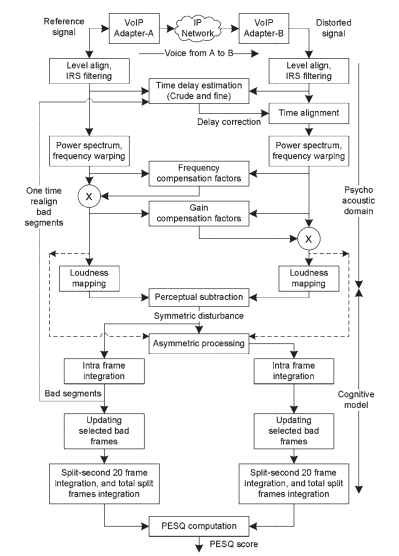
Figure 20.2. Représentations fonctionnelles de l’algorithme PESQ.
Le traitement effectué par l’algorithme PESQ comprend les étapes énumérées ci-dessous. Les étapes sommaires sont données ici; plusieurs détails sur le PESQ sont donnés dans.
Dans la première étape de traitement, la référence et le signal dégradé sont mis à l’échelle au même niveau de puissance constant. Cette mise à l’échelle est nécessaire car le signal de référence n’a pas besoin d’être à un niveau défini et le gain du système testé est inconnu avant le test. PESQ suppose que le niveau d’écoute subjectif est une constante de 79 dBSPL au point de référence de l’oreille. Pour la normalisation de la puissance, les niveaux de signal électrique sont normalisés à -26dBov (c’est-à-dire -20dBm comme indiqué dans la référence). Une normalisation au niveau du signal est appliquée à la fois au signal de référence et au signal dégradé pour les amener à ce niveau.
Les modèles perceptifs tels que PESQ devraient prendre en compte les caractéristiques des combinés téléphoniques, car l’écoute subjective peut utiliser des combinés téléphoniques. En PESQ, le chemin de réception des combinés est modélisé à l’aide d’un filtre passe-bande du système de référence intermédiaire (IRS) dans le domaine fréquentiel. Ce processus prend en compte les effets des composants électriques et acoustiques du combiné. La référence et le signal dégradé sont filtrés IRS.
Le système testé peut comporter un retard variable. Pour comparer les signaux de référence et dégradés, les deux signaux sont alignés dans le temps l’un avec l’autre. PESQ aligne les sections qui se chevauchent des trames vocales. Dans la première étape, l’estimation du retard est réalisée sur la longueur des fichiers en calculant la corrélation entre les fichiers. Le retard obtenu dans cette étape est appelé retard brut. Dans l’étape suivante, PESQ applique une détection d’activité vocale aux signaux pour identifier les segments de parole requis généralement appelés énoncés. L’estimation du délai entre les énoncés est le délai fin. Ce processus détecte un retard variable sur la longueur d’un énoncé, car cela peut être significatif dans les réseaux à base de paquets.
Les signaux de référence et dégradés alignés dans le temps sont transformés dans le domaine fréquentiel en utilisant une transformée de Fourier rapide à court terme (FFT) avec une fenêtre de Hanning sur des trames de 32 ms avec 50% de chevauchement. Les puissances des signaux originaux et dégradés sont calculées et stockées séparément. Dans l’étape suivante des opérations, les bandes de fréquences sont transformées en échelle d’écorce en regroupant des bandes FFT. Ce processus déforme l’échelle de fréquence en Hz à l’échelle de hauteur, et les signaux résultants sont appelés densités de puissance de hauteur. Dans ce processus, une bande passante plus élevée est utilisée pour un signal haute fréquence dérivé par analyse de fréquence.
Les effets de filtrage dans le système testé sont égalisés en calculant un facteur de compensation partielle par chaque bac d’écorce et en multipliant chaque trame du signal de référence par ce facteur. Ce processus égalise la référence au signal dégradé. Le facteur de compensation est calculé comme le rapport entre le spectre du signal dégradé et le spectre du signal de référence. Ce facteur prend en compte le filtrage au niveau des composants analogiques du réseau tels que les combinés téléphoniques. Dans la deuxième étape d’égalisation, le gain d’amplitude trame par trame
du système est estimé et utilisé pour égaliser le signal dégradé au signal de référence. Dans les deux cas, l’égalisation est partielle et de grandes quantités de filtrage ou de variation de gain ne sont pas annulées; par conséquent, il en résulte des erreurs mesurées. Les densités de puissance de hauteur de fréquence et de gain égalisées sont transformées en échelle de volume à l’aide de la loi de Zwicker. Les composantes temps-fréquence résultantes sont appelées densités de volume.
La différence signée entre les densités de sonie pour les signaux de référence et dégradés est appelée densité de perturbation brute, qui montre les différences audibles introduites par le système testé. Une opération de masquage applique un facteur de masque sur les densités de perturbation brutes qui masque les petites distorsions inaudibles en présence de signaux forts. La densité de perturbation obtenue par ce processus est appelée densité de perturbation absolue ou symétrique. Les perturbations symétriques sont intégrées sur la longueur de la trame (intrafame). Les trames consécutives avec une perturbation de trame supérieure à un seuil sont classées comme mauvaises trames. Les mauvaises trames peuvent se produire en raison d’une estimation de délai incorrecte ou de chutes de paquets. Sur une fenêtre localisée autour de mauvaises trames, une nouvelle estimation de retard est effectuée qui est utilisée pour recalculer les densités de perturbation. Le minimum des perturbations précédentes et actuelles est considéré comme la perturbation finale dans cette fenêtre de mauvais cadre.
Pour modéliser la distorsion introduite par le codec utilisé dans le réseau, une densité de perturbation asymétrique est calculée en multipliant la densité de perturbation symétrique par un facteur d’asymétrie. Le facteur d’asymétrie est le rapport entre les densités de puissance de tangage déformées et les densités de puissance de tangage d’origine portées à la puissance de 1,2. Cette densité de perturbation est appelée perturbation additive ou asymétrique.
Enfin, les paramètres d’erreur sont convertis en un score de qualité, qui est une combinaison linéaire de la valeur moyenne de perturbation symétrique et de la valeur moyenne de perturbation asymétrique. De la Fig. 20.2, les étapes impliquées de l’alignement des niveaux à la déformation de l’intensité sur l’échelle de volume sont connues sous le nom de conversion vers le domaine psycho-acoustique, et les étapes algorithmiques de la soustraction perceptive au calcul du score PESQ sont connues sous le nom de modélisation cognitive.
PESQ donne un score connu sous le nom de score PESQ conformément à la P.862. Le score PESQ est compris entre -0,5 et 4,5. PESQ est corrélé au MOS subjectif comme 0,94 sur la base d’expériences menées sur des bases de données par. Comparé aux scores subjectifs (auditeurs réels), PESQ donne de meilleurs résultats pour une parole de mauvaise qualité et des résultats pessimistes pour une voix de bonne qualité. PESQ-LQ fournit une meilleure corrélation avec les scores subjectifs que PESQ sur une échelle de qualité d’écoute. Les scores PESQ-LQ sont compris entre 1 et 4,5. P862.1 fournit une cartographie de la qualité entre le score PESQ des mesures de qualité à bande étroite et le score d’opinion moyenne objective de la qualité d’écoute (MOS-LQO). La recommandation P.862.2 fournit une cartographie de la qualité entre le score PESQ des mesures de qualité à large bande et le score d’opinion moyenne objective de la qualité d’écoute. Vous trouverez plus d’informations sur ces scores dans les recommandations de la série ITU-T-P.862 et en référence.
PESQ est une opération semi-duplex qui ne capturera pas avec précision les niveaux de retard, d’écho, de perte de volume, de tonalité latérale et d’écoute de bout en bout. À partir de la mesure de la qualité vocale de la passerelle VoIP avec interfaces analogiques, les observations PESQ-LQO suivantes sont effectuées en utilisant DSLA. Dans la condition d’absence de perte de paquets, le score PESQ-LQO pour le codec G.711 est de 4,32, G.729A est de 3,85 et G.723.1 est de 3,75. Une autre interprétation de ces résultats pour les situations de largage de paquets et la comparaison avec le modèle E sont données dans le cadre des calculs du facteur R et présentées dans le tableau 20.4. Dans le processus de calculs de PESQ, plusieurs autres paramètres peuvent être calculés. Les fournisseurs d’instruments fournissent ces paramètres en tant que caractéristiques supplémentaires aux mesures PESQ.
20.1.4
Technique de surveillance passive
Dans les techniques de surveillance passive, le signal de référence n’est pas présent. Il existe deux méthodes populaires de surveillance passive de la qualité de la parole. L’ IT a normalisé une méthode de surveillance non intrusive basée sur le signal, P.563, basée sur le résultat de la collaboration entre trois sociétés, Psytechnics Ltd., Swissqual et Opticom, qui ont combiné les meilleurs paramètres de trois modèles différents. P.563 est une mesure objective à une extrémité qui utilise un mécanisme de production de la parole, et les autres modèles de la parole utilisent la perception de l’écoute. Cet algorithme fonctionne uniquement sur la parole dégradée reçue. Il n’aura pas besoin de discours de référence, et il fonctionne entièrement sur la parole dégradée. Les mesures par P.563 dériver plusieurs paramètres de la parole reçue classés comme bruit, parole artificielle et parole réelle. Un aperçu de l’opération d’évaluation de la qualité de la parole à une extrémité P.563 est donné ici.
En l’absence de signal de référence, les modèles n’ont pas connaissance du signal d’origine et des hypothèses doivent être faites sur le signal reçu. Le modèle P.563 combine trois principes de base pour évaluer les distorsions. Le premier principe se concentre sur le système de production de la voix humaine, modélisant le tractus vocal comme une série de tubes, avec des variations anormales des sections des tubes considérées comme une dégradation. Le deuxième principe consiste à reconstruire un signal de référence propre à partir du signal dégradé afin d’appliquer ensuite un modèle perceptif de référence complète et d’évaluer les distorsions démasquées lors de la reconstruction. Le troisième principe est d’identifier et d’estimer les distorsions spécifiques rencontrées dans les canaux vocaux, telles que l’écrêtage temporel, la robotisation et le bruit. La qualité de la parole d’écoute est dérivée des paramètres calculés à partir des trois principes, en appliquant une pondération dépendante de la distorsion.
Lors de la rédaction de ce sujet, la technique basée sur P.563 n’a pas été largement acceptée pour les mesures. P.862 Les mesures basées sur PESQ et les estimations basées sur le modèle électronique sont plus communément acceptées. Le principal avantage de cette technique P.563 est sa capacité à surveiller à l’extrémité dégradée sans appel de référence. Ainsi, il peut mieux surveiller les appels longue distance en dehors du laboratoire et dans les déploiements, ce qui sera beaucoup plus simple à réaliser que de nombreuses autres mesures. La méthode basée sur P.563 peut également être intégrée en tant que partie
de la passerelle de réception similaire à E-model et RTCP-XR. Les opérations P.563 peuvent être utilisées sur des échantillons livrés sur les interfaces vocales de modulation par impulsions codées (PCM).
Plus d’informations sur la technique P.563 peuvent être trouvées à partir de P.563 et. Le score MOS produit par P.563 et d’autres techniques sont largement répandues et sont nécessaires pour faire la moyenne des résultats de plusieurs tests afin d’obtenir une mesure de qualité stable sur plusieurs résultats. P.563 est corrélé avec le MOS subjectif de 0,85 à 0,9 d’après les expériences menées sur une base de données de, et PESQ est rapporté à 0,94.