20.1
Um die Sprachqualität zu vergleichen und zu den Parametern zu gelangen, die zur Sprachqualität beitragen, ist es erforderlich zu wissen, wie die Sprachqualität gemessen wird und was die Qualitätsziele sind. Der grundlegende Testaufbau für VoIP-Sprachmessungen ist in Thema 13 beschrieben. In diesem Thema werden Sprachqualität als Mean Opinion Scores (MOS), verschiedene Klassifikationen, Einflussparameter auf die Sprachqualität und Verbesserungen diskutiert. Sprachqualitätsmessungen für MOS werden als subjektiv und objektiv klassifiziert.
Eine funktionale Darstellung einiger gängiger Sprachqualitätsmesstechniken ist in Fig. 20.1 . In der Abbildung wird gezeigt, dass die Stimme von
Tabelle 20.1 stammt. PSTN und VoIP Qualitätsvergleiche
| Attribute | PSTN | VoIP |
| Verzerrungen auf | Verzerrungen durch mehrere | Keine analoge Übertragung |
| analoge Leitung | 1000-Fuß-Leitungen von | Verzerrungen bei VoIP-Anrufen. |
| DLC oder CO Standort | ||
| Echounterdrückung | Erreicht durch Verlust | Carrier Grade Echounterdrücker |
| bei nationalen Anrufen | werden Planung und geringe Verzögerungen | verwendet. |
| Automatische Verstärkung | Nicht eingebaut | Einbau für |
| kontrolle | bessere Wahrnehmung von Sprache | |
| pegel oder Hörqualität | ||
| erfahrung. | ||
| Sprachqualität | Überwachung wie GR- | RTCP-XR und GR – 909 sind |
| überwachung | 909 sind integriert | in vielen VoIP |
| in die PSTN | Bereitstellungen. | |
| Bandbreite oder Bit | 64 kbit / s fest auf digital | Variable Bandbreite, normalerweise |
| bewerten | TDM. DCME-Kanäle | erfordert mehr physische |
| verwenden Sie 16, 24, 32 und | Schnittstellen als das PSTN. Faxnummer | |
| 40 kbps, die Fax verschlechtert | Dienste können mehr bekommen | |
| Qualität | Bandbreite oder Redundanz in | |
| übertragung. | ||
| Faxanrufe | Leistung begrenzt durch die | Verwendet kurze Endleitungen. Daher Fax |
| ende übertragung linie | lieferung kann besser mit | |
| eigenschaften | VoIP. Es könnte jedoch | |
| Interoperabilitätsprobleme für | ||
| fax senden. | ||
| Stimme und daten | Vor Allem für stimme anrufe, | Internet service und VoIP können |
| einige Dienste können | zusammen mit Daten und | |
| sprachkanäle für Daten | Mediendienstanforderungen. | |
| Sprachanruffunktionen | Eingeschränkte Funktionen und | Mehrere Funktionen werden als angeboten |
| teuer für mehrere | kostenlos. | |
| leistungsmerkmale | ||
| Sprachschnittstellen | Begrenzte Schnittstellen | Mehrere Schnittstellen und Dienste. |
| Fern | Fern ist teuer | In der Regel frei oder viel niedriger |
| preise. | ||
| Transcoding | Mehrere ebenen von | Ende-zu-ende direkte codierung kann |
| transcodierung für inter- | basierend auf der | |
| regionale Anrufe | verfügbare Unterstützung. | |
| Breitband unterstützung | Stimme anrufe sind von | Breitband ende-zu-ende stimme ist |
| schmalbandig | möglich, die | |
| PSTN Qualität. |
das sendende Gateway zum empfangenden Gateway. Das empfangende Gateway wird mit einigen weiteren erweiterten Blöcken angezeigt, um ein Gesamtbild des E-Modells zu erstellen, das für die Schätzung des R-Faktors, zusätzliche Qualitätsmetriken und den RTCP-XR-Betrieb (Real-Time Transport Control Protocol-Extended Reports) verwendet wird. Im E-Modell werden RTP-, RTCP-, Jitter-Puffer- und Gesamtsystemsignalparameter verwendet. Bei der Berechnung des R-Faktors und anderer abgeleiteter Parameter,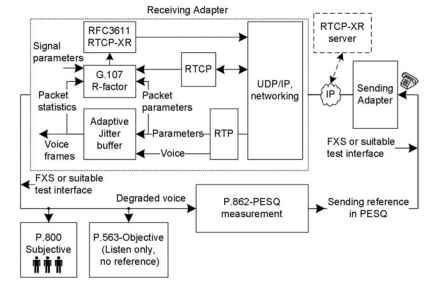
Abbildung 20.1. Überblick über gängige Sprachqualitätsmessungen.
RTCP-XR kann Pakete an die internen Anwendungen, das Ziel-Gateway und den RTCP-XR-Server senden. Zusammenfassend ist der nicht aufdringliche R-Faktor eine objektive Schätzung, die sich als Teil der VoIP-Implementierung befindet, und zusätzliche Software ist im Gateway für die R-Faktor-Schätzung erforderlich. Bei der perzeptuellen Bewertung der Sprachqualität (PESQ) senden Instrumente wie MultiDSLA die Referenzsprache durch das zu testende VoIP-System und bewerten die mit der Referenzsprache verschlechterte Sprache. Diese Messung ist aktiv und VoIP-Gateways müssen nichts über die Messung wissen. Beim subjektiven Hören bewerten mehrere Hörer die Sprachqualität. In P.563 wird die Stimme vollständig anhand des empfangenen verschlechterten Signals analysiert, und die ursprüngliche Referenz ist nicht erforderlich. P.563 ähnelt dem subjektiven Hören, wird jedoch von den Instrumenten oder Prozessoren bewertet. Jede dieser Techniken erreicht eine andere Skala der Sprachqualität. Bei einem VoIP-Sprachanruf zwischen A und B werden Sprachmessungen als Halbduplex durchgeführt, dh Messungen werden einzeln als A nach B oder B nach A durchgeführt. Aufgrund des Halbduplex-Abhörtests werden diese Messungen als LQ-Tests (Listening Quality) bezeichnet. Das Suffix LQ wird angehängt, während die Ergebnisse von Halbduplextests dargestellt werden, und objektive Tests werden zusätzlich mit „O“ als LQO versehen.
20.1.1
Subjektive Messtechnik
Bei der subjektiven Stimmqualitätsbewertung wird die Stimmqualität MOS von der Gruppe der tatsächlichen männlichen und weiblichen Zuhörer bewertet. Es ist der eigentliche Hörtest zur Bewertung des MOS. Die Empfehlungen P.800 und P.830 werden zur Beurteilung der subjektiven Leistung von Sprachcodecs
verwendet. Die gleichen Tests werden auf die VoIP-Sprachqualität ausgedehnt. Eine Gruppe von Personen nimmt teil, um subjektive Ergebnisse aufzuzeichnen. Mehrere Testphrasen werden aufgezeichnet und dann Testpersonen (Gruppe von Menschen) hören sie unter verschiedenen Bedingungen. Diese Tests werden in speziellen Räumen mit Hintergrundgeräuschen durchgeführt und andere Umgebungsfaktoren werden für die Testdurchführung unter Kontrolle gehalten. Die Testbedingungen sind in angegeben. Die subjektiven Messverfahren werden in absolute Category Rating (ACR), Degradation Category Rating (DCR) und Comparison Category Rating (CCR) unterteilt.
I n ACR hören die Teilnehmer aufgezeichnete Sprachbeispiele, die über mehrere Testverbindungen verarbeitet wurden. An der Bewertung sollten mindestens 16 Testpersonen (Hörer) teilnehmen. Beim Hören bewerten Benutzer den Anruf auf einer 1- bis 5-MOS-Skala. Die Durchschnittswerte der Nutzerbewertungen werden zur Generierung der Gesamtanrufqualität herangezogen.
In einem DCR-Test sind zwei Sprachproben vorhanden. Das erste Sprachmuster ist ein Referenzmuster mit vordefinierter Qualität. Das Beispiel bezieht sich hier auf Sprache, die mehrere Sekunden dauert. Das andere Sprachbeispiel ist eine degradierte Version. Listener müssen die degradierte Version mit einer Referenz auf einer Degradationsskala von 1 bis 5 vergleichen. Hier ist 5 eine unhörbare Degradation und 1 stellt die schlechteste Degradation dar. Die Ergebnisse werden als degradiertes MOS zusammengefasst.
In CCR-Tests werden Benutzer gebeten, zwei Sätze von Samples anzuhören, von denen einer der Referenz und der andere der Degradierung entspricht. Dieser Test ähnelt DCR, außer dass die Reihenfolge der den Listenern präsentierten Samples in verschiedenen Iterationen geändert wird. Die Reihenfolge der Referenz und degradiert wird dem Listener nicht deklariert. Die Zuhörer werden gebeten, eine vergleichende Bewertung einer zweiten Stichprobe in Bezug auf die erste auf einer Skala von -3 bis 3 gemäß P.800 Anhang-D abzugeben. Bei der Darstellung der Ergebnisse steht „3“ für eine viel bessere Qualität und „-3“ für die schlechteste Qualität auf einer relativen Skala. Der Qualitätsfaktor wird MOS zugeordnet. Die zulässige MOS-Bewertung beträgt 1 bis 5, eine Benutzerbewertung über 4,5 ist jedoch auf 4,5 beschränkt.
Subjektive Tests sind in Verfahren involviert, und es ist ein kostspieliger Aufwand. Es ist auf weniger Iterationen beschränkt, um neue Algorithmen oder Sprachcodecs zu bewerten. Es ist schwierig, Konsistenz wie instrumentenbasierte objektive Tests aufrechtzuerhalten.
20.1.2
Objektive Messtechniken
Objektive Methoden sind die Messungen und Berechnungen. Es wird erwartet, dass die Ergebnisse über mehrere Messungen hinweg konsistent sind. Es gibt mehrere objektive Methoden, die als aktive und passive Methoden klassifiziert werden.
* Aktive Überwachungstechniken von PESQ
• Passive Überwachungstechniken von P.563 und dem E-Modell
Aktive Überwachungstechniken. Die aktive Messung wird aufgrund der Einbeziehung externer Signale als intrusive Überwachung oder Offline-Überwachung bezeichnet.
Um die subjektive Hörqualität zu ergänzen, werden Tests mit kostengünstigeren objektiven Methoden entwickelt. KPN entwickelte das P.861 Perceptual Speech Quality Measure (PSQM) für die Bewertung der Codec-Leistung. British Telecom entwickelte das Perceptual Analysis Measurement System (PAMS) für Netzwerkmessungen. Der P.862 PESQ ist das Ergebnis eines ITU-Wettbewerbs. Die Leistung von PAMS und einer neuen Version von PSQM, PSQM99, waren ähnlich, so dass die Mitwirkenden aufgefordert wurden, die Algorithmen zu kombinieren. Dies führte zu PESQ, das etwas besser ist als seine Bestandteile.
Diese Verfahren messen Verzerrungen, die durch ein Übertragungssystem und einen Codec eingeführt werden, indem eine ursprüngliche Referenzdatei, die über eine Telefonschnittstelle in das System gesendet wird, mit dem empfangenen beeinträchtigten Signal, das über eine andere Telefonschnittstelle empfangen wird, verglichen wird. PSQM wurde für Labortests von Sprachcodecs entwickelt. PAMS und PESQ sind für Netzwerktests konzipiert. Die Verwendung von Instrumenten für die Sprachqualität ist im Vergleich zu subjektiven oder passiven Messungen viel einfacher. Instrumentenlieferanten stellen auch die extra abgeleiteten Parameter zur Verfügung, um die Quellen von Degradationen durch Messungen zu identifizieren. Weitere Informationen zu verschiedenen Funktionen finden Sie in einigen Instrumenten in Thema 13.
Während des Schreibens dieses Themas wurde PESQ im Volksmund in den Instrumenten unterstützt. PESQ wurde von der ITU im März 2001 als P.862-Empfehlung genehmigt und ersetzte P.861 QM. Die PESQ kombiniert mehrere beste Verdienste von PAMS und PSQM. Es ist präzise bei der Vorhersage subjektiver Testergebnisse und robust unter schwierigen Netzwerkbedingungen wie variablen Verzögerungen, Filterung an analogen Schnittstellen und Unterstützung von Breitband- und Schmalband. PESQ erzeugt eine Punktzahl, die auf einer Skala von -0,5 bis 4,5 liegt. Eine Mapping-Funktion von einem P.862 PESQ-Score zu einem durchschnittlichen subjektiven P.800-LQ MOS-Score wurde bereitgestellt, so dass es
PESQ – LQO für Schmalband-Stimme. LQO steht für listening quality objective. PESQ-LQ liegt zwischen 1 und 4,5. Ein MOS von 4.5 ist die maximale Qualität, die für einen klaren unverzerrten Zustand erreicht wird. Einen Überblick über den PESQ-Algorithmus gibt es hier. Es wird empfohlen, die ITU P.862 Familie von Empfehlungen, Software und einige kommerzielle Instrument Broschüren für weitere Details zu verweisen.
20.1.3
PESQ-Messung
Die menschliche Hörwahrnehmung ist das Kernkonzept von PESQ und seinen Vorgängern PAMS und PSQM. Ein Wahrnehmungsmodell wird verwendet, um korrekt zwischen hörbaren und unhörbaren Verzerrungen zu unterscheiden, und dies hat sich als der beste Weg erwiesen, um die Hörbarkeit und Belästigung komplexer Verzerrungen genau vorherzusagen. Zusätzlich zur Menge der Verzerrung könnte die Verteilung der hörbaren Verzerrung Qualitätsvorhersagen viel genauer machen.
PESQ misst die Einweg-Sprachqualität, dh den Halbduplexbetrieb der Messung. Es bewertet die Qualität eines verzerrten Sprachsignals, das codiert und über das Netzwerk übertragen wurde, indem es mit dem ursprünglichen unverzerrten Signal verglichen wird. Die ursprüngliche und verzerrte Sprache wird auf psychophysische Darstellungen abgebildet, die der Art und Weise entsprechen, wie Menschen Sprache erleben.
Die Qualität der verzerrten Sprache wird anhand von Unterschieden in psychophysischen Repräsentationen beurteilt. Die PESQ-Operation nutzt zwei Hauptklassen logarithmischer Operationen – nämlich die Umwandlung von Signalen in den psychoakustischen Bereich und die kognitive Modellierung. Eine funktionale Darstellung des PESQ-Algorithmus ist in Fig. 20.2. Die Gerätehersteller für die PESQ-Messung bieten zusätzlich zu den PESQ-Messungen mehrere zusätzliche Operationen zum Extrahieren von Signalanalyseparametern und Beeinträchtigungen.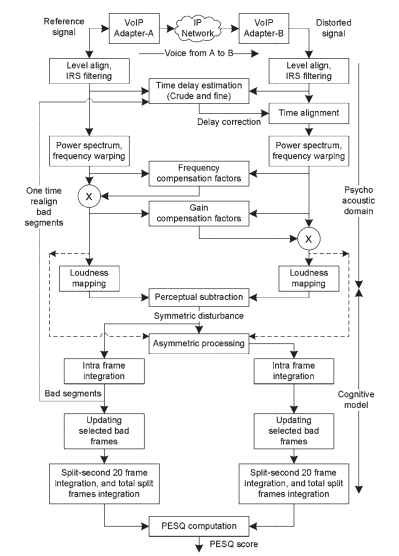
Abbildung 20.2. PESQ Algorithmus funktionale Darstellungen.
Die vom PESQ-Algorithmus durchgeführte Verarbeitung umfasst die unten aufgeführten Stufen. Zusammenfassende Schritte sind hier gegeben; Einige Details zum PESQ sind in angegeben .
Im ersten Verarbeitungsschritt werden sowohl das Referenzsignal als auch das degradierte Signal auf den gleichen konstanten Leistungspegel skaliert. Diese Skalierung ist notwendig, da das Referenzsignal nicht auf einem definierten Pegel liegen muss und die Verstärkung des zu testenden Systems vor dem Test unbekannt ist. PESQ geht davon aus, dass der subjektive Hörpegel am Ohrbezugspunkt konstant 79 dBSPL beträgt . Zur Leistungsnormalisierung werden die elektrischen Signalpegel auf -26dBov (d. H. -20dBm wie in der Referenz angegeben) normalisiert. Eine Signalpegelnormalisierung wird sowohl auf das Referenzsignal als auch auf das degradierte Signal angewendet, um sie auf diesen Pegel zu bringen.
Wahrnehmungsmodelle wie PESQ sollten die Eigenschaften der Telefonhörer berücksichtigen, da subjektives Hören Telefonhörer verwenden kann. In PESQ wird der Empfangspfad der Mobilteile unter Verwendung eines IRS-Bandpasses (Intermediate Reference System) im Frequenzbereich modelliert. Dieser Prozess berücksichtigt die Auswirkungen der elektrischen und akustischen Komponenten des Mobilteils. Sowohl das Referenzsignal als auch das degradierte Signal werden IRS-gefiltert.
Das zu testende System kann eine variable Verzögerung enthalten. Zum Vergleich der Referenz- und degradierten Signale werden beide Signale zeitlich aufeinander abgestimmt. PESQ richtet überlappende Abschnitte der Sprachrahmen aus. In der ersten Stufe wird die Verzögerungsschätzung über die Länge von Dateien durchgeführt, indem die Korrelation zwischen den Dateien berechnet wird. Die in dieser Stufe erhaltene Verzögerung wird als Rohverzögerung bezeichnet. In der nächsten Stufe wendet PESQ die Sprachaktivitätserkennung auf die Signale an, um erforderliche Sprachsegmente zu identifizieren, die normalerweise als Äußerungen bezeichnet werden. Die Verzögerungsschätzung zwischen Äußerungen ist die feine Verzögerung. Dieser Prozess erkennt eine Verzögerung, die über die Länge einer Äußerung variabel ist, da dies in paketbasierten Netzwerken signifikant sein kann.
Die zeitausgerichteten Referenz- und degradierten Signale werden in den Frequenzbereich transformiert, indem eine kurzfristige schnelle Fourier-Transformation (FFT) mit einem Hanning-Fenster über 32-ms-Frames mit 50% Überlappung verwendet wird. Die Leistungen von Original- und degradierten Signalen werden separat berechnet und gespeichert. In der nächsten Stufe der Operationen werden die Frequenzbänder durch Binning von FFT-Bändern in einen Maßstab transformiert. Dieser Prozess verzerrt die Frequenzskala in Hz zur Tonhöhenskala, und die resultierenden Signale werden Tonhöhenleistungsdichten genannt. Bei diesem Verfahren wird eine höhere Bandbreite für ein durch Frequenzanalyse abgeleitetes Hochfrequenzsignal verwendet.
Die Filtereffekte im zu prüfenden System werden durch Berechnung eines Teilkompensationsfaktors pro Rindenbehälter und durch Multiplikation jedes Rahmens des Referenzsignals mit diesem Faktor ausgeglichen. Dieser Vorgang gleicht die Referenz an das verschlechterte Signal aus. Der Kompensationsfaktor wird als Verhältnis von degradiertem Signalspektrum zu Referenzsignalspektrum berechnet. Dieser Faktor berücksichtigt die Filterung an analogen Komponenten des Netzes wie Telefonhörer. In der zweiten Stufe der Entzerrung wird die Verstärkung der Frame-by-Frame-Amplitude
des Systems geschätzt und verwendet, um das verschlechterte Signal mit dem Referenzsignal zu entzerren. In beiden Fällen ist die Entzerrung teilweise und große Mengen an Filterung oder Verstärkungsvariation werden nicht aufgehoben; Daher führt dies zu Messfehlern. Die Frequenz- und verstärkungsausgeglichenen Tonhöhenleistungsdichten werden unter Verwendung des Zwickerschen Gesetzes in die Lautstärkeskala transformiert. Die resultierenden Zeit-Frequenz-Komponenten werden als Lautheitsdichten bezeichnet.
Die vorzeichenbehaftete Differenz zwischen den Lautheitsdichten für die Referenz- und degradierten Signale wird als rohe Störungsdichte bezeichnet, die alle hörbaren Unterschiede zeigt, die durch das zu testende System eingeführt werden. Eine Maskierungsoperation wendet einen Maskierungsfaktor auf die rohen Störungsdichten an, der die kleinen unhörbaren Verzerrungen in Gegenwart lauter Signale maskiert. Die durch dieses Verfahren erhaltene Störungsdichte wird als absolute oder symmetrische Störungsdichte bezeichnet. Die symmetrischen Störungen sind über die Länge des Rahmens integriert (Intraframe). Die aufeinanderfolgenden Frames mit einer Frame-Störung über einem Schwellenwert werden als schlechte Frames kategorisiert. Die fehlerhaften Frames können aufgrund einer falschen Schätzung der Zeitverzögerung oder von Paketverlusten auftreten. In einem lokalisierten Fenster um fehlerhafte Frames wird eine neue Verzögerungsschätzung vorgenommen, die zur Neuberechnung der Störungsdichten verwendet wird. Das Minimum der vorherigen und aktuellen Störungen wird als letzte Störung in diesem fehlerhaften Rahmenfenster betrachtet.
Um die Verzerrung zu modellieren, die durch den im Netzwerk verwendeten Codec eingeführt wird, wird eine asymmetrische Störungsdichte berechnet, indem die symmetrische Störungsdichte mit einem Asymmetriefaktor multipliziert wird. Der Asymmetriefaktor ist das Verhältnis der verzerrten und der ursprünglichen Tonhöhenleistungsdichten, die auf die Potenz von 1,2 angehoben werden. Diese Störungsdichte wird als additive oder asymmetrische Störung bezeichnet.
Schließlich werden die Fehlerparameter in einen Qualitätsfaktor umgewandelt, der eine lineare Kombination aus dem durchschnittlichen symmetrischen Störwert und dem durchschnittlichen asymmetrischen Störwert ist. Aus Fig. 20.2 werden die Stufen von der Pegelausrichtung bis zur Intensitätsverzerrung auf der Lautheitsskala als Umwandlung in den psychoakustischen Bereich bezeichnet, und die algorithmischen Stufen von der Wahrnehmungssubtraktion bis zur PESQ-Score-Berechnung werden als kognitive Modellierung bezeichnet.
PESQ ergibt eine Punktzahl, die als PESQ-Punktzahl gemäß S.862 bekannt ist. Der PESQ-Score liegt im Bereich von -0,5 bis 4,5. PESQ korreliert mit dem subjektiven MOS als 0.94 basierend auf Experimenten an Datenbanken von . Im Vergleich zu subjektiven (tatsächlichen Hörern) Ergebnissen liefert PESQ bessere Ergebnisse für Sprache von schlechter Qualität und pessimistische Ergebnisse für Stimme von guter Qualität. PESQ-LQ bietet eine bessere Korrelation mit subjektiven Werten als PESQ auf einer Hörqualitätsskala. Die PESQ-LQ-Werte liegen im Bereich von 1 bis 4,5. P862.1 bietet eine Qualitätsabbildung zwischen schmalbandigen Qualitätsmessungen PESQ-Score und Hörqualität Objective Mean Opinion Score (MOS-LQO). Empfehlung P.862.2 bietet eine Qualitätsabbildung zwischen Breitbandqualitätsmessungen PESQ-Score und Hörqualität objektiver Mittelwert Meinungswert. Weitere Informationen zu diesen Partituren finden Sie in den Empfehlungen der ITU-T-P.862-Serie und in Referenz .
PESQ ist ein Halbduplex-Betrieb, der die End-to-End-Verzögerung, das Echo, den Lautheitsverlust, den Seitenton und die Hörpegel nicht genau erfasst. Aus der Sprachqualitätsmessung des VoIP-Gateways mit analogen Schnittstellen werden die folgenden PESQ-LQO-Beobachtungen mit DSLA gemacht. Unter der Bedingung ohne Paketverlust beträgt der PESQ-LQO-Wert für den G.711-Codec 4,32, G.729A 3,85 und G.723.1 3,75. Eine weitere Interpretation dieser Ergebnisse für Paketabfallsituationen und ein Vergleich mit dem E-Modell sind im Rahmen der R-Faktor-Berechnungen gegeben und in Tabelle 20.4 dargestellt. Bei PESQ-Berechnungen können mehrere andere Parameter berechnet werden. Gerätelieferanten stellen diese Parameter als zusätzliche Funktionen für PESQ-Messungen zur Verfügung.
20.1.4
Passive Überwachungstechnik
Bei passiven Überwachungstechniken ist das Referenzsignal nicht vorhanden. Es gibt zwei gängige Methoden zur passiven Überwachung der Sprachqualität. Die ITU hat eine signalbasierte, nicht aufdringliche Überwachungsmethode, P.563, standardisiert, die auf dem Ergebnis der Zusammenarbeit zwischen drei Unternehmen, Psytechnics Ltd., basiert., Swissqual und Opticom, die die besten Parameter von drei verschiedenen Modellen kombinierten. P.563 ist eine einseitige objektive Messung, die einen Sprachproduktionsmechanismus verwendet, und die anderen Sprachmodelle verwenden die Hörwahrnehmung. Dieser Algorithmus arbeitet nur mit empfangener degradierter Sprache. Es wird keine Referenzsprache benötigen, und es arbeitet vollständig mit degradierter Sprache. Die Messungen durch P.563 leiten mehrere Parameter aus empfangener Sprache ab, die als Rauschen, künstliche Sprache und tatsächliche Sprache klassifiziert sind. Eine Übersicht über die Single-Ended-Sprachqualitätsbewertungsoperation P.563 finden Sie hier.
In Abwesenheit eines Referenzsignals haben die Modelle keine Kenntnis des ursprünglichen Signals und es müssen Annahmen über das empfangene Signal getroffen werden. Das P.563-Modell kombiniert drei Grundprinzipien zur Bewertung von Verzerrungen. Das erste Prinzip konzentriert sich auf das menschliche Stimmproduktionssystem und modelliert den Stimmtrakt als eine Reihe von Röhren, wobei abnormale Variationen der Röhrenabschnitte als Verschlechterung angesehen werden. Das zweite Prinzip besteht darin, aus dem degradierten Signal ein sauberes Referenzsignal zu rekonstruieren, um danach ein Vollreferenzwahrnehmungsmodell anzuwenden und während der Rekonstruktion unmaskierte Verzerrungen zu bewerten. Das dritte Prinzip besteht darin, spezifische Verzerrungen in Sprachkanälen wie zeitliches Clipping, Robotisierung und Rauschen zu identifizieren und abzuschätzen. Die Hörsprachqualität wird aus den berechneten Parametern aus den drei Prinzipien abgeleitet, wobei eine verzerrungsabhängige Gewichtung angewendet wird.
Während des Schreibens dieses Themas wurde die auf P.563 basierende Technik für Messungen nicht allgemein akzeptiert. P.862 PESQ-basierte Messungen und E-Modell-basierte Schätzungen werden allgemein akzeptiert. Der Hauptvorteil dieser P.563-Technik ist ihre Fähigkeit, am verschlechterten Ende zu überwachen, ohne eine Referenz zu benötigen. Somit können Ferngespräche außerhalb des Labors und in Bereitstellungen besser überwacht werden, was viel einfacher durchzuführen ist als viele andere Messungen. Das P.563-basierte Verfahren kann auch als Teil
des empfangenden Gateways ähnlich wie E-model und RTCP-XR eingebettet werden. P.563-Operationen können für Samples verwendet werden, die über die PCM-Sprachschnittstellen (Pulse Code Modulation) geliefert werden.
Weitere Informationen zur P. 563-Technik finden Sie unter P.563 und . Der MOS-Score von P.563 und andere Techniken ist weit verbreitet und ist notwendig, um die Ergebnisse mehrerer Tests zu mitteln, um eine stabile Qualitätsmetrik über mehrere Ergebnisse zu erreichen. P.563 korreliert mit subjektivem MOS als 0,85 bis 0,9 basierend auf den Experimenten, die in einer Datenbank von durchgeführt wurden , und PESQ wird als 0,94 angegeben.