20.1
för att jämföra röstkvaliteten och för att komma fram till de parametrar som bidrar till röstkvaliteten krävs det att veta hur röstkvaliteten mäts och vilka kvalitetsmål. Den grundläggande testinställningen för VoIP-röstmätningar ges i ämne 13. I detta ämne diskuteras röstkvalitet som mean opinion scores (MOS), olika klassificeringar, röstkvalitetspåverkande parametrar och förbättringar. Röstkvalitetsmätningar för MOS klassificeras som subjektiva och objektiva.
en funktionell representation av några populära röstkvalitetsmätningstekniker illustreras i Fig. 20.1 . I figuren visas röst från
tabell 20.1. PSTN och VoIP kvalitet jämförelser
| attribut | PSTN | VoIP |
| snedvridningar på | snedvridningar på grund av flera | ingen analog överföring |
| analog linje | 1000-fot linjer från | snedvridningar med VoIP-samtal. |
| DLC eller CO plats | ||
| Echo cancellers | uppnås genom förlust | Carrier grade echo cancellers |
| på nationella samtal | planering och låga förseningar | används. |
| automatisk förstärkning | inte införlivad | möjligt att införliva för |
| kontroll | bättre uppfattning om tal | |
| nivåer eller lyssningskvalitet | ||
| erfarenhet. | ||
| röstkvalitet | övervakning som GR – | RTCP – XR och GR – 909 är |
| övervakning | 909 införlivas | införlivas i många VoIP |
| i PSTN | distributioner. | |
| bandbredd eller bit | 64 kbps fast på digital | variabel bandbredd, vanligtvis |
| betygsätt | TDM. Dcme-kanaler | kräver mer på fysisk |
| använd 16, 24, 32 och | gränssnitt än PSTN. Fax | |
| 40 kbps som försämrar fax | tjänster kan få mer | |
| kvalitet | bandbredd eller redundans i | |
| sändning. | ||
| faxsamtal | prestanda begränsad av | använder korta slutlinjer. Därför fax |
| leverans kan vara bättre med | ||
| egenskaper | VoIP. Det kan dock | |
| vara interoperabilitetsproblem för | ||
| skicka fax. | ||
| röst och data | främst för röstsamtal, | internettjänst och VoIP kan |
| vissa tjänster kan återanvända | skala tillsammans med data och | |
| röstkanaler för data | krav på medietjänster. | |
| röstsamtal funktioner | begränsade funktioner och | flera funktioner erbjuds som |
| dyrt för flera | gratis. | |
| service funktioner | ||
| röstgränssnitt | begränsade gränssnitt | flera gränssnitt och tjänster. |
| långdistans | långdistans är dyrt | vanligtvis gratis eller mycket lägre |
| priser. | ||
| transkodning | flera nivåer av | End – to – end direktkodning kan vara |
| transkodning för Inter – | anställd baserat på | |
| regionala samtal | tillgänglig support. | |
| bredbandsstöd | röstsamtal är av | bredband end-to-end röst är |
| smalband | möjligt som kan överstiga | |
| PSTN kvalitet. |
den sändande gatewayen till den mottagande gatewayen. Den mottagande gatewayen visas med några mer expanderade block för att skapa en stor bild av E-modellen, som används för R-faktoruppskattning, ytterligare kvalitetsmätningar och RTCP-XR-drift i realtid Transport Control Protocol-Extended Reports (RTCP-XR). I e-modellen används RTP, RTCP, jitterbuffert och totala systemsignalparametrar. Vid beräkning av R-faktorn och andra härledda parametrar,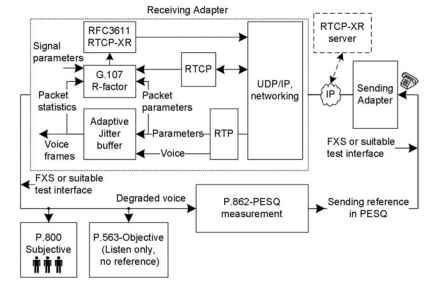
figur 20.1. Översikt över populära röstkvalitetsmätningar.
RTCP-XR kan skicka paket till de interna applikationerna, destinationsgatewayen och RTCP-XR-servern. Sammanfattningsvis är den icke-intrusiva R-faktorn en objektiv uppskattning som finns som en del av VoIP-implementeringen, och ytterligare programvara krävs i porten för R-faktoruppskattningen. I perceptuell utvärdering av talkvalitet (PESQ) skickar instrument som MultiDSLA referenstalet genom VoIP-systemet som testas och utvärderar det försämrade med referenstalet. Denna mätning är aktiv och VoIP-gateways behöver inte veta något om mätningen. I subjektivt lyssnande kommer flera lyssnare att utvärdera röstkvaliteten. I P. 563 analyseras röst helt på den mottagna nedbrutna signalen och den ursprungliga referensen krävs inte. P. 563 liknar subjektivt lyssnande, men det utvärderas av instrumenten eller processorerna. Var och en av dessa tekniker kommer i en annan skala av röstkvalitet. I ett VoIP-röstsamtal mellan A och B görs röstmätningar som halvduplex, vilket innebär att mätningar görs som A till B eller B till A, en i taget. På grund av den halvduplexa lyssningstypen av testning kallas dessa mätningar för lyssningskvalitet (LQ)-test. Suffixet LQ läggs till medan resultaten presenteras på halvduplextester, och objektiva tester suffixas dessutom med ”O” som LQO.
20.1.1
subjektiv mätteknik
i subjektiv röstkvalitetsutvärdering betygsätts röstkvalitet MOS av gruppen faktiska manliga och kvinnliga lyssnare. Det är det faktiska lyssningstestet för utvärdering av MOS. Rekommendationerna P. 800 och P. 830 används för att bedöma den subjektiva prestationen av tal
codecs. Samma tester utvidgas till VoIP-röstkvaliteten. En grupp människor deltar för att spela in subjektiva poäng. Flera testfraser spelas in och sedan lyssnar försökspersoner (grupp människor) på dem under olika förhållanden. Dessa tester utförs i speciella rum med bakgrundsljud och andra miljöfaktorer hålls under kontroll för testkörning. Testförhållandena anges i . De subjektiva mätteknikerna kategoriseras som absolute category rating (ACR), degradering category rating (DCR) och comparison category rating (CCR).
i ACR lyssnar deltagarna på inspelade talprover som har bearbetats genom flera testanslutningar. Minst 16 testpersoner (lyssnare) bör delta i bedömningen. När du lyssnar betygsätter användarna samtalet på en skala från 1 till 5 MOS. Medelvärdena för användarbetyg anses generera den totala samtalskvaliteten.
i ett DCR-test finns två talprover närvarande. Det första talprovet är ett referensprov med fördefinierad kvalitet. Provet här hänvisar till tal som varar i flera sekunder i varaktighet. Det andra talprovet är en nedbruten version. Lyssnare måste jämföra den nedbrutna versionen med en referens på en nedbrytningsskala på 1 till 5. Här är 5 ohörbar nedbrytning och 1 representerar värsta nedbrytning. Resultaten sammanfattas som nedbrutna MOS.
i CCR-tester uppmanas användarna att lyssna på två uppsättningar prover, en som motsvarar referens och den andra att försämras. Detta test liknar DCR, förutom att ordningen på prover som presenteras för lyssnarna ändras i olika iterationer. Referensordningen och degraderad förklaras inte för lyssnaren. Lyssnare uppmanas att ge en jämförande bedömning av ett andra prov med avseende på den första på en skala från -3 till 3 enligt P. 800 Bilaga-D . Vid presentationen av resultaten representerar ”3 ”mycket bättre kvalitet och” -3 ” representerar den värsta kvaliteten i relativ skala. Kvalitetsresultatet är mappat till MOS. MOS-värdet är 1 till 5, men ett användarbetyg över 4,5 är begränsat till 4,5.
subjektiva tester är inblandade i förfaranden, och det är en kostsam ansträngning. Det är begränsat till mindre iterationer för att utvärdera alla nya algoritmer eller talkodeker. Det är svårt att upprätthålla konsistens som instrumentbaserade objektiva tester.
20.1.2
objektiva mättekniker
objektiva metoder är mätningar och beräkningar. Det förväntas att resultaten kommer att vara konsekventa över flera mätningar. Flera objektiva metoder finns och klassificeras som aktiva och passiva metoder.• passiva övervakningstekniker för P. 563 och E-modellen
aktiva övervakningstekniker. Aktiv mätning kallas påträngande övervakning eller offline monitorings på grund av inblandning av externa signaler.
i ett försök att komplettera subjektiv lyssningskvalitet utvecklas testning med objektiva metoder med lägre kostnad. KPN utvecklade P. 861 (detta är föråldrat nu) perceptual speech quality measure (PSQM) för utvärdering av codec-prestanda. British Telecom utvecklade perceptual analysis measurement system (PAMS) för nätverksmätningar. P. 862 PESQ resulterade från en ITU-tävling. Prestandan för PAMS och en ny version av PSQM, PSQM99, var liknande så bidragsgivarna blev inbjudna att kombinera algoritmerna. Detta resulterade i PESQ, vilket är något bättre än dess beståndsdelar.
dessa metoder mäter distorsion som introduceras av ett överföringssystem och codec genom att jämföra en originalreferensfil som skickas in i systemet på ett telefongränssnitt med den mottagna försämrade signalen som mottas på ett annat telefongränssnitt. PSQM utvecklades för laboratorietestning av talkodek. PAMS och PESQ är utformade för nätverkstestning. Användningen av instrument för röstkvalitet är mycket enklare jämfört med subjektiva eller passiva mätningar. Instrumentleverantörer tillhandahåller också de extra härledda parametrarna för att hjälpa till att identifiera källorna till nedbrytningar genom mätningar. Se några instrument som ges i ämne 13 för mer information om olika funktioner.
under skrivandet av detta ämne stöddes PESQ populärt i instrumenten. PESQ godkändes av ITU i mars 2001 som P. 862-rekommendationen och ersatte P.861 PSQM. PESQ kombinerade flera Bästa fördelar med PAMS och PSQM. Det är korrekt att förutsäga subjektiva testresultat, och det är robust under svåra nätverksförhållanden såsom en variabel förseningar, filtrering vid Analoga gränssnitt, och stöd för både bredband och smalband. PESQ producerar en poäng som ligger på en skala från -0,5 till 4,5. En kartläggningsfunktion från en P. 862 PESQ-poäng till en genomsnittlig subjektiv P. 800 – LQ MOS-poäng tillhandahölls, vilket gjorde det
PESQ-LQO för smalbandsröst. LQO betecknar ett lyssningskvalitetsmål. PESQ-LQ ligger från 1 till 4,5. En MOS av 4.5 är den högsta kvalitet som uppnås för ett tydligt, oförvrängt tillstånd. En översikt över pesq-algoritmen ges här. Det föreslås att hänvisa till ITU P. 862-familjen med rekommendationer, programvara och några kommersiella instrumentbroschyrer för mer information .
20.1.3
PESQ mätning
mänsklig hörseluppfattning är kärnkonceptet bakom PESQ och dess föregångare PAMS och PSQM. En perceptuell modell används för att skilja korrekt mellan hörbara och ohörbara snedvridningar, och detta har visat sig vara det bästa sättet att exakt förutsäga hörbarheten och irritationen av komplexa snedvridningar. Förutom mängden distorsion kan fördelningen av hörbar distorsion göra kvalitetsprognoser mycket mer exakta.
PESQ mäter enkelriktad röstkvalitet, vilket betyder halvduplexoperation av mätning. Den bedömer kvaliteten på en förvrängd talsignal som har kodats och överförts över nätverket genom att jämföra den med den ursprungliga oförvrängda signalen. Det ursprungliga och förvrängda talet kartläggs till psykofysiska representationer som matchar hur människor upplever tal.
kvaliteten på det förvrängda talet bedöms utifrån skillnader i psykofysiska representationer. PESQ-operationen använder sig av två huvudklasser av logaritmiska operationer—nämligen omvandling av signaler till den psyko-akustiska domänen och kognitiv modellering. En funktionell representation av pesq-algoritmen ges i Fig. 20.2. Instrumenttillverkare för PESQ-mätningen inkluderar flera extra operationer för att extrahera signalanalysparametrar och försämringar utöver PESQ-mätningar.
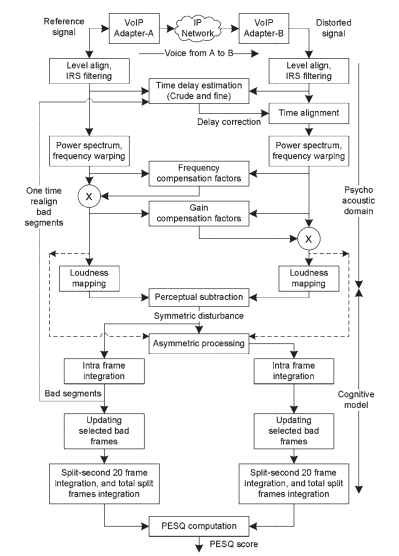
figur 20.2. PESQ algoritm funktionella representationer.
behandlingen som utförs av PESQ-algoritmen inkluderar stegen nedan. Sammanfattande steg ges här; flera detaljer om PESQ ges i .
i det första bearbetningssteget skalas både referensen och den nedbrutna signalen till samma konstanta effektnivå. Denna skalning är nödvändig eftersom referenssignalen inte behöver vara på en definierad nivå och förstärkningen av systemet som testas är okänt före testning. PESQ antar att den subjektiva lyssningsnivån är en konstant 79 dBSPL vid öronreferenspunkten . För effektnormalisering normaliseras elektriska signalnivåer till – 26dbov (dvs-20dBm som anges i referensen ). En signalnivånormalisering tillämpas på både referensen och den nedbrutna signalen för att föra dem till denna nivå.
perceptuella modeller som PESQ bör ta hänsyn till telefonens egenskaper eftersom subjektivt lyssnande kan använda telefontelefoner. I PESQ modelleras mottagningsvägen för handenheterna med hjälp av ett intermediate reference system (IRS) bandpassfilter i frekvensdomänen. Denna process tar hänsyn till effekterna av handenhetens elektriska och akustiska komponenter. Både referensen och den nedbrutna signalen filtreras IRS.
systemet som testas kan innehålla variabel fördröjning. För att jämföra referens-och nedbrutna signaler är båda signalerna tidsjusterade med varandra. PESQ justerar överlappande delar av talramarna. I det första steget utförs fördröjningsuppskattningen över filernas längd genom att beräkna korrelationen mellan filerna. Fördröjningen som erhålls i detta steg kallas rå fördröjning. I nästa steg tillämpar PESQ röstaktivitetsdetektering på signalerna för att identifiera nödvändiga talsegment som vanligtvis kallas uttalanden. Fördröjningsuppskattningen mellan yttranden är bötesfördröjningen. Denna process upptäcker fördröjning som är variabel över längden på ett yttrande, eftersom detta kan vara betydande i paketbaserade nätverk.
den tidsjusterade referensen och degraderade signalerna omvandlas till frekvensdomänen genom att använda en kortvarig snabb Fourier-Transformation (FFT) med ett Hanning-fönster över 32-ms-ramar med 50% överlappande. Krafterna för original-och nedbrutna signaler beräknas och lagras separat. I nästa steg av verksamheten, frekvensbanden omvandlas till bark skala genom binning FFT band. Denna process vrider frekvensskalan i Hz till tonhöjdsskalan, och de resulterande signalerna kallas tonhöjdsdensiteter. I denna process används högre bandbredd för en högfrekvent signal härledd genom frekvensanalys.
filtreringseffekterna i det system som testas utjämnas genom att beräkna en partiell kompensationsfaktor per varje barkfack och genom att multiplicera varje ram av referenssignalen med denna faktor. Denna process utjämnar hänvisningen till den nedbrutna signalen. Kompensationsfaktorn beräknas som förhållandet mellan försämrat signalspektrum och referenssignalspektrum. Denna faktor tar hänsyn till filtreringen vid analoga komponenter i nätverket, såsom telefontelefoner. I det andra utjämningssteget uppskattas ram-för-RAM-amplituden
förstärkningen av systemet och används för att utjämna den nedbrutna signalen till referenssignalen. I båda fallen är utjämningen partiell och stora mängder filtrering eller förstärkningsvariation avbryts inte; därför resulterar det i att fel mäts. Frekvensen och förstärkningsutjämnade tonhöjdstätheter omvandlas till volymskala med hjälp av Zwickers lag . De resulterande tidsfrekvenskomponenterna kallas ljudtäthet.
den signerade skillnaden mellan ljudtätheten för referenssignalerna och degraderade signalerna är känd som råstörningstäthet, vilket visar eventuella hörbara skillnader som införs av systemet som testas. En maskeringsoperation tillämpar en maskfaktor på de råa störningstätheterna som maskerar de små ohörbara snedvridningarna i närvaro av höga signaler. Störningstätheten erhållen genom denna process kallas absolut eller symmetrisk störningstäthet. De symmetriska störningarna är integrerade över ramens längd (intraframe). De på varandra följande ramarna med en ramstörning över en tröskel kategoriseras som dåliga ramar. De dåliga ramar kan uppstå på grund av felaktig tidsfördröjning uppskattning eller paketdroppar. I ett lokaliserat fönster runt dåliga ramar görs en ny fördröjningsuppskattning som används för att beräkna störningstätheten igen. Minsta av tidigare och nuvarande störningar betraktas som den slutliga störningen i det dåliga ramfönstret.
för att modellera distorsionen som introduceras av codec som används i nätverket beräknas en asymmetrisk störningstäthet genom att multiplicera den symmetriska störningstätheten med en asymmetrifaktor. Asymmetrifaktorn är förhållandet mellan förvrängda och de ursprungliga tonhöjdstätheterna höjda till kraften 1.2. Denna störningstäthet kallas additiv eller asymmetrisk störning.
slutligen konverteras felparametrarna till ett kvalitetsresultat, vilket är en linjär kombination av det genomsnittliga symmetriska störningsvärdet och det genomsnittliga asymmetriska störningsvärdet. Från Fig. 20.2, de involverade stadierna från nivåinriktning till intensitetsvridningen på ljudskalan är kända som omvandlingen till den psyko – akustiska domänen, och de algoritmiska stadierna från perceptuell subtraktion till PESQ-poängberäkning är kända som kognitiv modellering.
PESQ ger en poäng som kallas PESQ-poängen i enlighet med P. 862. PESQ-poängen ligger i intervallet -0,5 till 4,5. PESQ är korrelerad till den subjektiva MOS som 0.94 baserat på experiment utförda på databaser av . Jämfört med subjektiva (faktiska lyssnare) poäng, pesq ger bättre resultat för dålig kvalitet tal och pessimistiska resultat för god kvalitet röst. PESQ-LQ ger bättre korrelation med subjektiva poäng än PESQ på en lyssningskvalitetsskala. PESQ-LQ-poängen ligger inom intervallet 1 till 4,5. P862.1 ger en kvalitetsmappning mellan smalbandskvalitetsmätningar PESQ-poäng och lyssningskvalitet objective mean opinion score (MOS-LQO). Rekommendation P. 862.2 ger en kvalitetskartläggning mellan bredbandskvalitetsmätningar PESQ-poäng och lyssningskvalitet mål mean opinion score. Mer information om dessa poäng finns i ITU-T-P. 862-seriens rekommendationer och i referens .
PESQ är en halv duplex operation som inte kommer att fånga exakt på end-to-end fördröjning, eko, loudness förlust, sideton, och lyssningsnivåer. Från Röstkvalitetsmätningen av VoIP-gatewayen med Analoga gränssnitt görs följande pesq-LQO-observationer med DSLA . Under inget paketförlustvillkor är PESQ-LQO-poängen för G. 711-codec 4.32, G. 729A är 3.85 och G. 723.1 är 3.75. En annan tolkning av dessa resultat för paketfallssituationer och jämförelse med E-modellen ges som en del av R-faktorberäkningarna och presenteras i tabell 20.4. I processen med PESQ-beräkningar kan flera andra parametrar beräknas. Instrumentleverantörer tillhandahåller dessa parametrar som ytterligare funktioner för PESQ-mätningar .
20.1.4
passiv övervakningsteknik
i passiva övervakningstekniker är referenssignalen inte närvarande. Två populära metoder för passiv talkvalitetsövervakning finns. ITU har standardiserat en signalbaserad icke-intrusiv övervakningsmetod, P. 563, baserat på resultatet av samarbete mellan tre företag, Psytechnics Ltd., Swissqual och Opticom, som kombinerade de bästa parametrarna för tre olika modeller. P. 563 är en enstaka objektiv mätning som använder sig av en talproduktionsmekanism, och de andra talmodellerna använder sig av lyssningsuppfattning. Denna algoritm fungerar endast på mottaget försämrat tal. Det behöver inte referenstal, och det fungerar helt på försämrat tal. Mätningarna genom P.563 härleda flera parametrar från mottaget tal klassificerat som buller, artificiellt tal och faktiskt tal. En översikt över P. 563 single-ended talkvalitetsbedömningsoperationen ges här.
i avsaknad av en Referenssignal har modellerna inte kunskap om den ursprungliga signalen och antaganden måste göras om den mottagna signalen. P. 563-modellen kombinerar tre grundläggande principer för utvärdering av snedvridningar. Den första principen fokuserar på det mänskliga röstproduktionssystemet och modellerar vokalkanalen som en serie rör, med onormala variationer av rörens sektioner betraktade som nedbrytning. Den andra principen är att rekonstruera en ren Referenssignal från den nedbrutna signalen för att därefter tillämpa en fullreferensperceptuell modell och för att bedöma snedvridningar som maskeras under rekonstruktionen. Den tredje principen är att identifiera och uppskatta specifika snedvridningar som uppstår i röstkanaler, såsom tidsmässig klippning, robotisering och buller. Lyssna tal kvalitet härrör från de beräknade parametrarna från de tre principerna, tillämpa en distorsionsberoende viktning.
medan du skriver detta ämne, var P. 563-baserad teknik inte allmänt accepterad för mätningar. P. 862 PESQ – baserade mätningar och e-modellbaserade uppskattningar accepteras mer populärt. Den största fördelen med denna P. 563-teknik är dess förmåga att övervaka vid den nedbrutna änden utan att kräva referens. Således kan det bättre övervaka fjärrsamtal utanför laboratoriet och i distributioner, vilket blir mycket enklare att genomföra än många andra mätningar. Den P. 563-baserade metoden kan också inbäddas som en del
i den mottagande gatewayen som liknar E-model och RTCP-XR. P. 563 operationer kan användas på prover som får levereras på pulse code modulation (PCM) röstgränssnitt.
mer information om P. 563-tekniken finns från P. 563 och . MOS-poängen producerad av P.563 och andra tekniker är brett spridda och är nödvändiga för att genomsnittliga resultaten av flera tester för att uppnå en stabil kvalitetsmätning över flera resultat. P. 563 är korrelerad med subjektiva MOS som 0.85 till 0.9 baserat på de experiment som utförs på en databas av , och PESQ rapporteras som 0.94.