podczas wykonywania badań ważne jest, abyś był w stanie zrozumieć swoje dane. Dzięki temu możesz poinformować innych badaczy w swojej dziedzinie i innych o tym, co znalazłeś. Może również służyć do budowania dowodów na teorię. Dlatego zrozumienie, jakiego testu użyć i kiedy jest to konieczne. Istnieje kilka dobrych praktyk do zrobienia, jeśli nie są zaznajomieni z wykonywania analizy statystycznej. Pierwszym z nich jest określenie zmiennych.
przegląd podstawowych statystyk:
zmienna zależna (DV) – to jest ta, którą mierzysz . Na przykładzie wyniku ucznia.
zmienna niezależna (IV)-to jest ta, którą manipulujesz różnymi warunkami. Na przykładzie prezentacji PowerPoint lub rzutnika.
poziomy pomiaru:
po wykonaniu tej czynności będziesz chciał określić poziom pomiaru, którym są obie zmienne. Pomoże Ci to później określić, jakiego testu użyć w analizie. Istnieją cztery poziomy pomiaru:
interwał-mają one jednakowe liczby (tj. Liczba zwierząt).
stosunek-nie ma rzeczywistego zera i istnieją odstępy między liczbami całkowitymi (tj. masa urodzeniowa)
Nominalny-po prostu nazywając kategorie (tj. Mężczyzna/Kobieta).
porządkowanie-po prostu porządkowanie (tj. 1=zdecydowanie się nie zgadzam; 2 = nie Zgadzam się; 3 = Neutralnie; 4=Zgadzam się; 5 = zdecydowanie się Zgadzam).
wreszcie, będziesz miał informacje potrzebne do określenia, jakiego testu potrzebujesz użyć. Do czasu zapoznania się z wykonywaniem analizy statystycznej, dobrą praktyką jest śledzenie tych informacji (patrz Tabela 3).

Tabela 3. Zmienna, poziom pomiaru i liczba IV
dzięki tym informacjom można odnieść się do poniższego wykresu, aby określić, jakiego testu statystycznego użyć. Najpierw określ, czy badanie jest wewnątrz lub między podmiotami, następnie liczbę grup, a następnie poziom pomiaru (patrz rysunek 1).
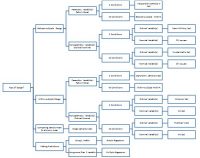
Rysunek 1. Wykres badań według projektu, liczba warunków i poziom pomiaru
drzewo decyzyjne
testy statystyczne można podzielić na dwie grupy, parametryczne i nieparametryczne i są określone przez poziom pomiaru. Testy parametryczne są używane do analizy danych interwałowych i stosunek i nieparametryczne testy analizują dane porządkowe i nominalne. Istnieją różne testy do wykorzystania w każdej grupie. Najpierw zaczniemy od testów parametrycznych.
Testy Parametryczne: (Interval/Ratio data)
te testy zakładają, że dane są normalnie rozłożone (krzywa Dzwonowa) i są bardzo silne w porównaniu z testami nieparametrycznymi.
W Ramach Projektu Tematu 1. Zależne próbki t-test: porównuje środki z dwóch grup. Przykładem jest określenie, czy PowerPoint lub klasy wpływu rzutu napowietrznego. 2. W ramach badanych ANOVA: porównuje środki z więcej niż dwóch grup. Przykładem jest określenie, czy PowerPoint, rzutowanie narzutu i podcast wpłynęły na stopnie, a jeśli tak, to który.
Między Projektem Przedmiotu
1. Niezależne próbki t-test: Porównuje środki z dwóch grup. Przykładem może być określenie, czy prezentacja programu PowerPoint wpłynęła na oceny w porównaniu z grupą kontrolną. 2. Między podmiotami ANOVA: porównuje środki z więcej niż dwóch grup. Przykładem jest określenie, czy PowerPoint lub projektor wpłynął na stopnie, a jeśli tak, to który. 3. Korelacja Pearsona: określa, czy istnieje zależność między dwiema zmiennymi. Określa również siłę związku, jeśli taki istnieje.
współczynnik korelacji waha się od -1,0 do 1,0. Im bliżej -1.0 lub 1.0, tym silniejsza relacja. Gdy R jest ujemne, oznacza to, że istnieje ujemna zależność (jedna zmienna idzie w górę/w dół, druga robi odwrotnie). Kiedy r jest dodatnie, oznacza to, że istnieje dodatnia zależność (jedna zmienna idzie w górę lub w dół, podobnie jak druga). Zobacz poniższy przykład badający korelację między tekstami wysyłanymi w tygodniu a ocenami. Innym sposobem określenia zależności i siły jest spojrzenie na wykres. Im bliżej linii znajdują się punkty danych, tym silniejsza relacja (patrz rysunek 2). Uwaga: silna korelacja nie oznacza, że stan spowodował wynik. Oznacza to tylko, że dwie zmienne są ze sobą w jakiś sposób powiązane.
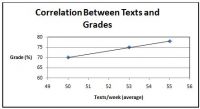
Rysunek 2. Wykres tekstów a korelacja klas
testy nieparametryczne: (dane porządkowe/nominalne)
testy te nie zakładają niczego o kształcie danych. Testy te nie są tak silne jak testy parametryczne.
W Ramach Projektu Przedmiotu
1. Wilcoxon: jest to nieparametryczna wersja testu zależnych próbek T, ponieważ porównuje różnicę rang dla grup dwóch z danymi tylko porządkowymi. Przykładem może być określenie rankingu uczestników pod względem preferencji wizualnych między dwiema aplikacjami do gier na iPada. 2. Friedman: jest to nieparametryczna wersja obiektu ANOVA, ponieważ porównuje szeregi dla grup więcej niż dwóch z tylko danymi porządkowymi. Przykładem jest określenie rangi trzech różnych stron internetowych w oparciu o łatwość obsługi.
Między Projektem Przedmiotu
1. Chi kwadrat: porównuje szeregi dla dwóch grup i więcej niż dwóch projektów grupowych z tylko nominalnymi danymi. A. chi kwadrat (dobroć dopasowania) – porównuje proporcję próbki do już istniejącej wartości. Przykładem może być porównanie wskaźników umiejętności czytania i pisania w centrum Missouri z tymi w całym stanie. B. chi kwadrat (Test niezależności) – porównuje proporcje dwóch zmiennych, aby sprawdzić, czy są ze sobą powiązane, czy nie. Przykładem może być podobna liczba zawodników baseballu i softballu zapisanych na kurs psychologii ogólnej w tym semestrze. 2. Kruskall-Wallis: Jest to nieparametryczna wersja między testerami ANOVA, ponieważ widzi, czy wiele próbek pochodzi z tej samej populacji. Przykładem jest określenie, w jaki sposób uczestnicy oceniają lekarza na podstawie tego, czy korzystał z komputera, książki, czy też nie miał pomocy w ich diagnozowaniu. 3. Mann-Whitney: jest to nieparametryczna wersja testu niezależnych próbek T, ponieważ porównuje szeregi dla grup więcej niż dwóch z tylko danymi porządkowymi. Przykładem może być ustalenie, czy jedzenie batoników Snickers wpływa na oceny uczniów na kursach matematycznych. 4. Korelacje: A. Spearman ’ s Rho: podobnie jak korelacja Pearsona, ten test również określa siłę zależności między dwiema zmiennymi na podstawie ich Rang. Przykładem może być określenie zależności między klasami fizyki i języka angielskiego.
Sekcja Analizy Statystycznej-Podręcznik