研究を行う際には、データを理解できることが不可欠です。 これにより、あなたの分野の他の研究者や他の研究者にあなたが見つけたことを知らせることができます。 また、理論の証拠の構築を支援するために使用することができます。 したがって、どのようなテストを使用するか、いつ必要なのかを理解することができます。 統計分析の実行に慣れていない場合は、いくつかの良い方法があります。 最初はあなたの変数を決定することです。
基本統計の概要:
従属変数(DV)-これはあなたが測定しているものです。 学生のスコアの例から。
独立変数(IV)-これは、異なる条件で操作している変数です。 この例では、PowerPointまたはオーバーヘッドプロジェクタのプレゼンテーションのいずれかから。
測定レベル:
これが完了したら、両方の変数が測定レベルを決定したいと思うでしょう。 これは、後で分析で使用するテストを決定するのに役立ちます。 測定には4つのレベルがあります:
間隔-これらは等しい数を持っています(つまり ペットの数)。
Ratio-実数ゼロはなく、整数の間に間隔があります(出生体重)
公称-単純にカテゴリを命名します(男性/女性)。
序数-単純な順序付け(すなわち、1=強く同意しない;2=同意しない;3=中立;4=同意する;5=強く同意する)。
最後に、どのテストを使用する必要があるかを判断するために必要な情報が得られます。 統計分析を行うことに慣れるまでは、この情報を追跡することをお勧めします(表3を参照)。

表3. 変数、測定レベル、IVの数
この情報を使用すると、次の表を参照して、使用する統計的検定を決定できます。 まず、研究が被験者の中にあるかどうか、被験者の間にあるかどうかを判断し、次にグループの数、次に測定レベルを決定します(図1を参照)。
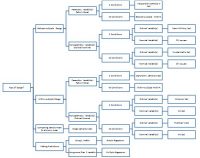
図1. 設計によるテストのチャート、条件の数、および測定レベル
決定木
統計的テストは、パラメトリックとノンパラメトリックの二つのグループに分けることができ、測定レベルによって決定される。 パラメトリック検定は、区間データと比率データの分析に使用され、ノンパラメトリック検定は順序データと公称データの分析に使用されます。 各グループで使用する異なるテストがあります。 最初にパラメトリック検定から始めます。
パラメトリック検定: (Interval/Ratio data)
これらの検定は、データが正規分布(ベル曲線)であり、ノンパラメトリック検定と比較した場合に非常に強いことを前提としています。
対象デザイン内の1. 従属標本t検定:2つのグループの平均を比較します。 例として、PowerPointまたは頭上投影が成績に影響を与えるかどうかを判断することがあります。 2. 被験者ANOVA内:2つ以上のグループの平均を比較します。 たとえば、PowerPoint、overhead projection、podcastが成績に影響を与えたかどうか、そしてそうであればどれが影響を与えるかを判断することです。
対象デザイン間
1. 独立標本t検定: 二つのグループの平均を比較します。 例として、PowerPointプレゼンテーションが対照群と比較して成績に影響を与えるかどうかを判断することがあります。 2. 被験者間ANOVA:2つ以上のグループの平均を比較します。 例えば、PowerPointやオーバーヘッドプロジェクターが成績に影響を与えたかどうか、そうであればどちらかを判断することです。 3. Pearson Correlation:2つの変数の間に関係があるかどうかを判断します。 また、関係が存在する場合は、関係の強さも決定します。
相関係数の範囲は-1.0~1.0です。 -1.0または1.0に近いほど、関係は強くなります。 Rが負の場合、それは負の関係があることを意味します(1つの変数が上/下になり、もう1つの変数が逆になります)。 Rが正の場合、それは正の関係があることを意味します(1つの変数が上下になり、もう1つの変数も上下になります)。 週に送信されるテキストと成績の相関関係を調べるには、以下の例を参照してください。 関係と強さを決定する別の方法は、グラフを見ることです。 データポイントがラインに近いほど、関係は強くなります(図2参照)。 注意:強い相関関係は、条件が結果を引き起こしたことを意味するものではありません。 これは、2つの変数が何らかの形で関連していることを意味するだけです。
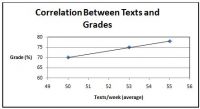
図2。 テキストとグレードの相関のグラフ
ノンパラメトリック検定:(順序/公称データ)
これらの検定は、データの形状について何も仮定しません。 これらの検定はパラメトリック検定ほど強力ではありません。
対象デザイン内
1. Wilcoxon:これは、2つのグループのランクの差と順序データのみを比較するため、従属サンプルt検定のノンパラメトリック版です。 例は、2つのiPadゲームアプリ間の視覚的な好みのための参加者のランキングを決定することです。 2. Friedman:これは、2つ以上のグループのランクと順序データのみを比較するため、被験者内ANOVAのノンパラメトリック版です。 たとえば、使いやすさに基づいて3つの異なるwebサイトのランクを決定することです。
と
の間の1. カイ二乗:2つのグループ計画と2つ以上のグループ計画の両方のランクをノミナルデータのみで比較します。 A.カイ二乗(適合度)-サンプルの比率を既存の値と比較します。 例としては、ミズーリ州中央部の識字率と州全体の識字率を比較することが挙げられます。 B.カイ二乗(独立性の検定)-2つの変数の比率を比較して、それらが関連しているかどうかを確認します。 一例は、この学期の一般心理学コースに登録されている野球とソフトボールの選手の同様の数があるでしょう。 2. Kruskall-Wallis:複数のサンプルが同じ母集団からのものであるかどうかを確認するため、これは被験者間ANOVAのノンパラメトリック版です。 一例は、参加者がコンピュータ、本、またはそれらの診断に援助を使用していないかどうかに基づいて、医師を評価する方法を決定することです。 3. Mann-Whitney:これは、2つ以上のグループのランクと順序データのみを比較するため、独立標本t検定のノンパラメトリック版です。 例はSnickersキャンデー棒を食べることが数学のコースの学生の等級に影響を与えるかどうか定めることである。 4. 相関:A.Spearman’s Rho:Pearson相関と同様に、この検定も2つの変数のランクに基づいて2つの変数間の関係の強さを決定します。 一例は、物理学と英語のコースの成績との関係を決定することです。
統計分析セクション-マニュアル