při provádění výzkumu je nezbytné, abyste byli schopni pochopit vaše data. To vám umožní informovat ostatní výzkumné pracovníky ve vašem oboru a další, co jste našli. Může být také použit k vytvoření důkazů pro teorii. Proto je nutné pochopit, jaký test použít a kdy je nutné. Pokud nejste obeznámeni s prováděním statistické analýzy, je třeba udělat několik osvědčených postupů. První je určit vaše proměnné.
přehled základních statistik:
závislá proměnná (DV) – to je ta, kterou měříte. Z příkladu skóre studenta.
nezávislá proměnná (IV)-to je ta, kterou manipulujete s různými podmínkami. Z příkladu buď PowerPoint nebo zpětný projektor prezentace.
úrovně měření:
jakmile to bude provedeno, budete chtít určit úroveň měření, kterou jsou obě proměnné. To vám pomůže později určit, jaký test použít ve své analýze. Existují čtyři úrovně měření:
Interval-tyto mají stejná čísla (tj. Počet domácích zvířat).
poměr-neexistuje žádná skutečná nula a existují intervaly mezi celými čísly (tj. porodní hmotností)
nominální-jednoduše pojmenujte kategorie (tj. Muž/Žena).
Ordinal-jednoduše objednávat (tj. 1=silně nesouhlasit; 2=nesouhlasit; 3=neutrální; 4=souhlasit; 5=silně souhlasit).
nakonec budete mít informace potřebné k určení, jaký test musíte použít. Dokud se seznámíte se statistickou analýzou, je dobré tyto informace sledovat (viz tabulka 3).

Tabulka 3. Proměnná, úroveň měření a počet IV
pomocí těchto informací můžete určit, jaký statistický test použít, v následujícím grafu. Nejprve určete, zda je studie uvnitř nebo mezi subjekty, pak počet skupin, pak úroveň měření (viz Obrázek 1).
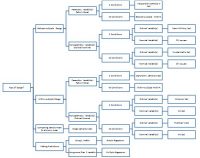
Obrázek 1. Graf testů podle návrhu, počtu podmínek a úrovně měření
rozhodovací strom
statistické testy lze rozdělit do dvou skupin, parametrické a neparametrické a jsou určeny úrovní měření. Parametrické testy se používají k analýze intervalových a poměrových dat a neparametrické testy analyzují pořadová a nominální data. V každé skupině se používají různé testy. Nejprve začneme parametrickými testy.
Parametrické Testy: (Údaje o intervalu/poměru)
tyto testy předpokládají, že data jsou normálně distribuována (bell curve) a jsou velmi silná ve srovnání s neparametrickými testy.
V Rámci Návrhu Předmětu 1. Závislé vzorky t-test: porovnává prostředky dvou skupin. Příkladem je určení, zda PowerPoint nebo režijní projekce dopadové stupně. 2. V rámci subjektů ANOVA: porovnává prostředky více než dvou skupin. Příkladem je určení, zda PowerPoint, režijní projekce, a podcast ovlivnil stupně a pokud ano, který z nich.
Mezi Návrhem Předmětu
1. Nezávislé vzorky t-test: Porovnává prostředky dvou skupin. Příkladem je určení, zda prezentace PowerPoint ovlivnila stupně ve srovnání s kontrolní skupinou. 2. Mezi subjekty ANOVA: porovnává prostředky více než dvou skupin. Příkladem je určení, zda PowerPoint nebo zpětný projektor ovlivnily stupně a pokud ano, který z nich. 3. Pearsonova korelace: určuje, zda existuje vztah mezi dvěma proměnnými. Určuje také sílu vztahu, pokud existuje.
korelační koeficient se pohybuje od -1,0 do 1,0. Čím blíže je -1,0 nebo 1,0, tím silnější je vztah. Když je r záporné, znamená to, že existuje negativní vztah (jedna proměnná jde nahoru / dolů a druhá dělá opak). Když je r pozitivní, znamená to, že existuje pozitivní vztah (jedna proměnná jde nahoru nebo dolů, stejně jako druhá). Viz níže uvedený příklad zkoumající korelaci mezi texty zasílanými týdně a známkami. Dalším způsobem, jak určit vztah a sílu, je podívat se na graf. Čím blíže jsou datové body k linii, tím silnější je vztah (viz Obrázek 2). Pozor: silná korelace neznamená, že výsledek způsobil stav. Znamená to pouze, že tyto dvě proměnné jsou nějakým způsobem spojeny.
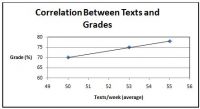
Obrázek 2. Graf textů vs. korelace stupně
neparametrické testy: (pořadová/nominální data)
tyto testy nepředpokládají nic o tvaru dat. Tyto testy nejsou tak silné jako parametrické.
V Rámci Předmětu
1. Wilcoxon: Toto je neparametrická verze závislých vzorků t-test, protože porovnává rozdíl řad pro skupiny dvou pouze s pořadovými údaji. Příkladem je určení pořadí účastníků pro vizuální preference mezi dvěma herními aplikacemi iPad. 2. Friedman: Toto je neparametrická verze anovy uvnitř subjektů, protože porovnává pozice pro skupiny více než dvou s pouze pořadovými údaji. Příkladem je určení pořadí tří různých webových stránek na základě uživatelské přívětivosti.
Mezi Návrhem Předmětu
1. Chi square: porovnává pozice pro dvě skupiny a více než dva skupinové návrhy pouze s nominálními údaji. A. Chi square (Goodness of Fit) – porovnává podíl vzorku s již existující hodnotou. Příkladem by bylo srovnání míry gramotnosti ve střední Missouri s mírou gramotnosti celého státu. B. Chi square (Test nezávislosti) – porovnává proporce dvou proměnných, aby zjistil, zda jsou příbuzné nebo ne. Příkladem může být, že existují podobné počty baseballových a softbalových sportovců zapsaných do kurzu obecné psychologie v tomto semestru. 2. Kruskall-Wallis: Toto je neparametrická verze mezi subjekty ANOVA, protože vidí, zda je více vzorků ze stejné populace. Příkladem je určení toho, jak účastníci hodnotí lékaře na základě toho, zda použil počítač, knihu nebo žádnou pomoc při jejich diagnostice. 3. Mann-Whitney: Toto je neparametrická verze t-testu nezávislých vzorků, protože porovnává pozice pro skupiny více než dvou s pouze pořadovými údaji. Příkladem by bylo určení, zda konzumace bonbónů Snickers ovlivňuje známky studentů v matematických kurzech. 4. Korelace: a. Spearmanova Rho: jako Pearsonova korelace, tento test také určuje sílu vztahu mezi dvěma proměnnými na základě jejich řad. Příkladem by bylo určení vztahu mezi fyzikou a známkami kurzu angličtiny.
Sekce Statistické Analýzy-Manuál