Lors de la recherche, il est essentiel que vous puissiez donner un sens à vos données. Cela vous permet d’informer les autres chercheurs de votre domaine et les autres de ce que vous avez trouvé. Il peut également être utilisé pour aider à construire des preuves pour une théorie. Par conséquent, une compréhension de quel test utiliser et quand est nécessaire. Il y a quelques bonnes pratiques à faire si vous n’êtes pas familier avec l’analyse statistique. La première consiste à déterminer vos variables.
Aperçu des statistiques de base:
Variable dépendante (DV) – C’est celle que vous mesurez. De l’exemple du score de l’élève.
Variable indépendante (IV) – C’est celle que vous manipulez avec les différentes conditions. À partir de l’exemple de présentation PowerPoint ou rétroprojecteur.
Niveaux de mesure:
Une fois cela fait, vous voudrez déterminer le niveau de mesure des deux variables. Cela vous aidera à déterminer plus tard quel test utiliser dans votre analyse. Il existe quatre niveaux de mesure : Intervalle
– Ceux-ci ont des nombres égaux (i.e. Nombre d’animaux).
Rapport – Il n’y a pas de zéro réel et il y a des intervalles entre les nombres entiers (c’est-à-dire le poids à la naissance)
Nominal – Nommant simplement les catégories (c’est-à-dire Mâle / Femelle).
Ordinal – Ordonnancement simple (c’est-à-dire 1 = Tout à fait en désaccord; 2 = En désaccord; 3 = Neutre; 4 = d’accord; 5 = Tout à fait d’accord).
Enfin, vous aurez les informations nécessaires pour déterminer quel test vous devez utiliser. Jusqu’à ce que vous vous familiarisiez avec l’analyse statistique, il est recommandé de garder une trace de ces informations (voir tableau 3).

Tableau 3. Variable, niveau de mesure et nombre d’IV
Avec ces informations, vous pouvez vous référer au tableau suivant pour déterminer quel test statistique utiliser. Déterminez d’abord si l’étude se situe à l’intérieur ou entre les sujets, puis le nombre de groupes, puis le niveau de mesure (voir Figure 1).
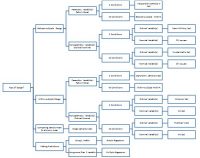
Figure 1. Tableau des tests par conception, nombre de conditions et niveau de mesure
Arbre de décision
Les tests statistiques peuvent être divisés en deux groupes, paramétriques et non paramétriques et sont déterminés par le niveau de mesure. Les tests paramétriques sont utilisés pour analyser les données d’intervalle et de rapport et les tests non paramétriques analysent les données ordinales et nominales. Il existe différents tests à utiliser dans chaque groupe. Nous commencerons d’abord par les tests paramétriques.
Essais paramétriques: (Données Intervalle/ rapport)
Ces tests supposent que les données sont normalement distribuées (courbe en cloche) et sont très fortes par rapport aux tests non paramétriques.
Dans la conception du sujet 1. Échantillons dépendants t-test: Compare les moyennes de deux groupes. Un exemple est de déterminer si PowerPoint ou une projection aérienne a un impact sur les notes. 2. Au sein des sujets ANOVA: Compare les moyennes de plus de deux groupes. Un exemple consiste à déterminer si PowerPoint, la rétroprojection et le podcast ont eu une incidence sur les notes et, si oui, laquelle.
Entre la Conception du sujet
1. Échantillons indépendants t-test: Compare les moyens de deux groupes. Un exemple consiste à déterminer si une présentation PowerPoint a eu un impact sur les notes par rapport à un groupe témoin. 2. Entre les sujets ANOVA: Compare les moyennes de plus de deux groupes. Un exemple consiste à déterminer si PowerPoint ou un rétroprojecteur a eu un impact sur les notes et, si oui, lequel. 3. Corrélation de Pearson : Détermine s’il existe une relation entre deux variables. Il détermine également la force de la relation, si elle existe.
Le coefficient de corrélation varie de -1,0 à 1,0. Plus la relation est proche de -1,0 ou 1,0, plus la relation est forte. Lorsque r est négatif, cela signifie qu’il y a une relation négative (une variable monte / descend, l’autre fait le contraire). Lorsque r est positif, cela signifie qu’il existe une relation positive (une variable monte ou descend, l’autre aussi). Voir l’exemple ci-dessous examinant la corrélation entre les textes envoyés par semaine et les notes. Une autre façon de déterminer la relation et la force est de regarder le graphique. Plus les points de données sont proches de la ligne, plus la relation est forte (voir Figure 2). Attention: une forte corrélation ne signifie pas qu’une condition a causé le résultat. Cela signifie seulement que les deux variables sont liées d’une manière ou d’une autre.
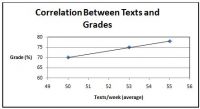
Figure 2. Graphique des textes par rapport à la corrélation de grade
Tests non paramétriques: (Données ordinales / nominales)
Ces tests ne supposent rien sur la forme des données. Ces tests ne sont pas aussi forts que les tests paramétriques.
Dans la Conception du sujet
1. Wilcoxon: Il s’agit de la version non paramétrique du test t des échantillons dépendants car il compare la différence de rangs pour les groupes de deux avec uniquement des données ordinales. Un exemple est la détermination du classement des participants pour la préférence visuelle entre deux applications de jeux iPad. 2. Friedman: Il s’agit de la version non paramétrique de l’ANOVA au sein des sujets car elle compare les rangs pour les groupes de plus de deux avec uniquement des données ordinales. Un exemple est la détermination du rang de trois sites Web différents en fonction de la convivialité.
Entre la Conception du sujet
1. Chi carré : Compare les rangs pour deux groupes et plus de deux groupes avec UNIQUEMENT des données nominales. A. Chi carré (Qualité de l’ajustement) – Compare la proportion de l’échantillon à une valeur déjà existante. Un exemple serait de comparer les taux d’alphabétisation dans le centre du Missouri à ceux de l’ensemble de l’État. B. Chi carré (Test d’indépendance) – Compare les proportions de deux variables pour voir si elles sont liées ou non. Un exemple serait le nombre similaire d’athlètes de baseball et de softball inscrits au cours de psychologie générale de ce semestre. 2. Kruskall-Wallis: Il s’agit de la version non paramétrique de l’ANOVA entre sujets car elle voit si plusieurs échantillons proviennent de la même population. Un exemple consiste à déterminer comment les participants évaluent un médecin selon qu’il a utilisé un ordinateur, un livre ou aucune aide pour le diagnostiquer. 3. Mann-Whitney: Il s’agit de la version non paramétrique du test t des échantillons indépendants car il compare les rangs pour les groupes de plus de deux avec uniquement des données ordinales. Un exemple serait de déterminer si manger des barres chocolatées Snickers affecte les notes des élèves dans les cours de mathématiques. 4. Corrélations: Rho de A. Spearman: Comme la corrélation de Pearson, ce test détermine également la force de la relation entre deux variables en fonction de leurs rangs. Un exemple serait de déterminer la relation entre les notes des cours de physique et d’anglais.
Section Analyse statistique – Manuel