Bei der Durchführung von Forschung ist es wichtig, dass Sie in der Lage sind, Ihre Daten zu verstehen. Auf diese Weise können Sie andere Forscher auf Ihrem Gebiet und andere darüber informieren, was Sie gefunden haben. Es kann auch verwendet werden, um Beweise für eine Theorie zu erstellen. Daher ist ein Verständnis dafür erforderlich, welcher Test wann verwendet werden soll. Es gibt einige bewährte Methoden, wenn Sie mit der Durchführung statistischer Analysen nicht vertraut sind. Die erste besteht darin, Ihre Variablen zu bestimmen.
Überblick über grundlegende Statistiken:
Abhängige Variable (DV) – Dies ist diejenige, die Sie messen. Aus dem Beispiel der Partitur des Schülers.
Unabhängige Variable (IV) – Dies ist die Variable, die Sie mit den verschiedenen Bedingungen manipulieren. Aus dem Beispiel entweder Powerpoint oder Overhead-Projektor-Präsentation.
Messstufen:
Sobald dies erledigt ist, möchten Sie den Messgrad beider Variablen bestimmen. Auf diese Weise können Sie später bestimmen, welcher Test in Ihrer Analyse verwendet werden soll. Es gibt vier Messebenen:
Intervall – Diese haben gleiche Zahlen (d. h. Anzahl der Haustiere).
Verhältnis – Es gibt keine echte Null und es gibt Intervalle zwischen ganzen Zahlen (d. H. Geburtsgewicht)
Nominal – Einfach Kategorien benennen (d. H. Männlich / Weiblich).
Ordinal – Einfach bestellen (dh 1 = Stimme nicht zu; 2 = Stimme nicht zu; 3 = Neutral; 4 = Stimme zu; 5 = Stimme stark zu).
Schließlich haben Sie die Informationen, die Sie benötigen, um zu bestimmen, welchen Test Sie verwenden müssen. Bis Sie sich mit statistischen Analysen vertraut gemacht haben, sollten Sie diese Informationen im Auge behalten (siehe Tabelle 3).

Tabelle 3. Variable, Messniveau und Anzahl der IVS
Mit diesen Informationen können Sie der folgenden Tabelle entnehmen, um zu bestimmen, welcher statistische Test verwendet werden soll. Bestimmen Sie zuerst, ob die Studie innerhalb oder zwischen den Probanden durchgeführt wird, dann die Anzahl der Gruppen und dann das Messniveau (siehe Abbildung 1).
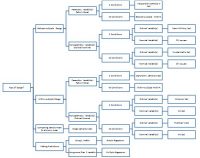
Abbildung 1. Diagramm der Tests nach Design, Anzahl der Bedingungen und Messniveau
Entscheidungsbaum
Statistische Tests können in zwei Gruppen unterteilt werden, parametrisch und nichtparametrisch, und werden durch das Messniveau bestimmt. Parametrische Tests werden verwendet, um Intervall- und Verhältnisdaten zu analysieren, und nichtparametrische Tests analysieren ordinale und nominale Daten. Es gibt verschiedene Tests in jeder Gruppe zu verwenden. Wir werden zuerst mit den parametrischen Tests beginnen.
Parametrische Tests: (Intervall- / Verhältnisdaten)
Diese Tests gehen davon aus, dass die Daten normalverteilt sind (Glockenkurve) und im Vergleich zu nichtparametrischen Tests sehr stark sind.
Innerhalb des Subjektdesigns 1. Abhängige Proben t-Test: Vergleicht Mittelwerte von zwei Gruppen. Ein Beispiel ist die Bestimmung, ob PowerPoint oder eine Overhead-Projektion Noten beeinflussen. 2. Innerhalb der Probanden ANOVA: Vergleicht Mittelwerte von mehr als zwei Gruppen. Ein Beispiel ist die Bestimmung, ob PowerPoint, Overhead-Projektion und Podcast die Noten beeinflusst haben und wenn ja, welche.
Zwischen Thema Design
1. Unabhängige Proben t-Test: Vergleicht Mittel zweier Gruppen. Ein Beispiel ist die Bestimmung, ob eine PowerPoint-Präsentation die Noten im Vergleich zu einer Kontrollgruppe beeinflusst. 2. Zwischen Probanden ANOVA: Vergleicht Mittelwerte von mehr als zwei Gruppen. Ein Beispiel ist die Bestimmung, ob PowerPoint oder ein Overheadprojektor die Noten beeinflusst haben und wenn ja, welche. 3. Pearson-Korrelation: Bestimmt, ob eine Beziehung zwischen zwei Variablen besteht. Es bestimmt auch die Stärke der Beziehung, falls vorhanden.
Der Korrelationskoeffizient reicht von -1,0 bis 1,0. Je näher an -1,0 oder 1,0, desto stärker ist die Beziehung. Wenn r negativ ist, bedeutet dies, dass es eine negative Beziehung gibt (eine Variable geht auf / ab, die andere macht das Gegenteil). Wenn r positiv ist, bedeutet dies, dass es eine positive Beziehung gibt (eine Variable steigt oder fällt, die andere auch). Im folgenden Beispiel wird die Korrelation zwischen den pro Woche gesendeten Texten und den Noten untersucht. Eine andere Möglichkeit, die Beziehung und Stärke zu bestimmen, besteht darin, die Grafik zu betrachten. Je näher die Datenpunkte an der Linie liegen, desto stärker ist die Beziehung (siehe Abbildung 2). Vorsicht: Eine starke Korrelation bedeutet nicht, dass eine Bedingung das Ergebnis verursacht hat. Es bedeutet nur, dass die beiden Variablen in irgendeiner Weise zusammenhängen.
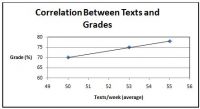
Abbildung 2. Graph von Texten vs. Gradkorrelation
Nichtparametrische Tests: (Ordinale / nominale Daten)
Diese Tests gehen nicht von der Form der Daten aus. Diese Tests sind nicht so stark wie die parametrischen.
Innerhalb des Subjektdesigns
1. Wilcoxon: Dies ist die nichtparametrische Version des T-Tests für abhängige Stichproben, da er die Differenz der Ränge für Zweiergruppen nur mit Ordinaldaten vergleicht. Ein Beispiel ist die Bestimmung des Rankings der Teilnehmer für die visuelle Präferenz zwischen zwei iPad-Spiele-Apps. 2. Friedman: Dies ist die nichtparametrische Version der within subjects ANOVA, da sie Ränge für Gruppen von mehr als zwei mit nur Ordinaldaten vergleicht. Ein Beispiel ist die Bestimmung des Ranges von drei verschiedenen Websites basierend auf der Benutzerfreundlichkeit.
Zwischen Thema Design
1. Chi-Quadrat: Vergleicht Ränge für zwei Gruppen- und mehr als zwei Gruppen-Designs mit NUR nominalen Daten. A. Chi-Quadrat (Güte der Anpassung) – Vergleicht den Anteil der Stichprobe mit einem bereits vorhandenen Wert. Ein Beispiel wäre der Vergleich der Alphabetisierungsraten in Zentral-Missouri mit denen des gesamten Staates. B. Chi-Quadrat (Unabhängigkeitstest) – Vergleicht die Proportionen zweier Variablen, um festzustellen, ob sie verwandt sind oder nicht. Ein Beispiel wäre, gibt es eine ähnliche Anzahl von Baseball- und Softball-Athleten in diesem Semester allgemeine Psychologie Kurs eingeschrieben. 2. Kruskall-Wallis: Dies ist die nichtparametrische Version der ANOVA zwischen den Probanden, da sie erkennt, ob mehrere Stichproben aus derselben Population stammen. Ein Beispiel ist die Bestimmung, wie die Teilnehmer einen Arzt bewerten, basierend darauf, ob er / sie einen Computer, ein Buch oder keine Hilfe bei der Diagnose verwendet hat. 3. Mann-Whitney: Dies ist die nichtparametrische Version des unabhängigen Stichproben-T-Tests, da er Ränge für Gruppen von mehr als zwei mit nur Ordinaldaten vergleicht. Ein Beispiel wäre die Bestimmung, ob das Essen von Snickers-Schokoriegeln die Noten der Schüler in Mathematikkursen beeinflusst. 4. Korrelationen: A. Spearmans Rho: Wie die Pearson-Korrelation bestimmt auch dieser Test die Stärke der Beziehung zwischen zwei Variablen basierend auf ihren Rängen. Ein Beispiel wäre, die Beziehung zwischen Physik- und Englischkursnoten zu bestimmen.
Abschnitt Statistische Analyse-Handbuch