bij het uitvoeren van onderzoek is het essentieel dat u in staat bent om uw gegevens te begrijpen. Dit stelt u in staat om andere onderzoekers in uw vakgebied en anderen te informeren over wat u hebt gevonden. Het kan ook worden gebruikt om bewijs voor een theorie op te bouwen. Daarom een begrip van welke test te gebruiken en wanneer nodig is. Er zijn een aantal goede praktijken te doen als u niet bekend bent met het uitvoeren van statistische analyse. De eerste is om je variabelen te bepalen.
overzicht van basisstatistieken:
afhankelijke variabele (DV) – Dit is degene die u meet. Uit het voorbeeld van de score van de student.
onafhankelijke variabele (IV) – Dit is degene die u manipuleert met de verschillende condities. Uit het voorbeeld PowerPoint of overheadprojector presentatie.
Meetniveaus:
als dit is gebeurd, wilt u het meetniveau bepalen dat beide variabelen zijn. Dit zal u later helpen bepalen welke test te gebruiken in uw analyse. Er zijn vier meetniveaus:
Interval-deze hebben gelijke aantallen (d.w.z. Aantal huisdieren).
Verhouding-er is geen echte nul en er zijn intervallen tussen hele getallen (d.w.z. geboortegewicht)
Nominaal-gewoon categorieën benoemen (d.w.z. Man/Vrouw).
ordinaal-eenvoudig ordenen (d.w.z. 1=zeer oneens; 2=oneens; 3=Neutraal; 4=mee eens; 5=Zeer mee eens).
ten slotte hebt u de informatie die nodig is om te bepalen welke test u moet gebruiken. Totdat u vertrouwd raakt met het doen van statistische analyses, is het een goede praktijk om deze informatie bij te houden (zie Tabel 3).

Tabel 3. Variabele, meetniveau en aantal IV ‘ s
met deze informatie kunt u naar de volgende grafiek verwijzen om te bepalen welke statistische test moet worden gebruikt. Bepaal eerst of de studie binnen of tussen proefpersonen ligt, dan het aantal groepen, dan het meetniveau (zie Figuur 1).
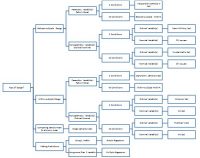
figuur 1. Tabel van de tests naar ontwerp, aantal voorwaarden en meetniveau
beslissingsboom
statistische Tests kunnen worden onderverdeeld in twee groepen, parametrisch en niet-parametrisch en worden bepaald door het meetniveau. De parametrische tests worden gebruikt om interval en ratio gegevens te analyseren en de niet-parametrische tests analyseren ordinal en nominale gegevens. Er zijn verschillende tests te gebruiken in elke groep. We beginnen eerst met de parametrische testen.
Parametrische Tests: (Interval/Ratio data)
deze tests gaan ervan uit dat de gegevens normaal verdeeld zijn (bell curve) en zeer sterk zijn in vergelijking met niet-parametrische tests.
Binnen De Opzet Van Het Onderwerp 1. Afhankelijke monsters t-test: vergelijkt gemiddelden van twee groepen. Een voorbeeld is het bepalen of PowerPoint of een overhead projectie impact kwaliteiten. 2. Binnen onderwerpen Anova: vergelijkt middelen van meer dan twee groepen. Een voorbeeld is het bepalen of PowerPoint, overhead projectie, en podcast grades beà nvloed en zo ja welke.
Tussen Ontwerp Van Het Onderwerp
1. Onafhankelijke monsters t-test: Vergelijkt middelen van twee groepen. Een voorbeeld is het bepalen of een PowerPoint-presentatie grades beïnvloed in vergelijking met een controlegroep. 2. Tussen proefpersonen ANOVA: vergelijkt middelen van meer dan twee groepen. Een voorbeeld is het bepalen of PowerPoint of een overheadprojector grades heeft beïnvloed en zo ja welke. 3. Pearson correlatie: bepaalt of er een relatie is tussen twee variabelen. Het bepaalt ook de sterkte van de relatie, als die bestaat.
de correlatiecoëfficiënt varieert van -1,0 tot 1,0. Hoe dichter bij -1.0 of 1.0, hoe sterker de relatie. Wanneer r negatief is, betekent dat dat er een negatieve relatie is (de ene variabele gaat omhoog/omlaag, de andere doet het tegenovergestelde). Als r positief is, betekent dat dat er een positieve relatie is (de ene variabele gaat omhoog of omlaag, de andere ook). Zie onderstaand voorbeeld over de correlatie tussen per week verzonden teksten en cijfers. Een andere manier om de relatie en kracht te bepalen is om naar de grafiek te kijken. Hoe dichter de datapunten bij de lijn liggen, hoe sterker de relatie is (zie Figuur 2). Let op: een sterke correlatie betekent niet dat een aandoening het resultaat veroorzaakt. Het betekent alleen dat de twee variabelen zijn gerelateerd op een bepaalde manier.
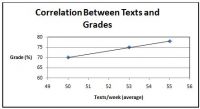
Figuur 2. Grafiek van teksten vs. correlatie van de cijfers
niet-parametrische Tests: (ordinale/Nominale gegevens)
deze tests nemen niets aan over de vorm van de gegevens. Deze tests zijn niet zo sterk als de parametrische.
Binnen De Opzet Van Het Onderwerp
1. Wilcoxon: Dit is de niet-parametrische versie van de afhankelijke steekproeven T-test aangezien het het verschil van rangen voor groepen van twee met slechts ordinal gegevens vergelijkt. Een voorbeeld is het bepalen van de ranking van de deelnemer voor visuele voorkeur tussen twee iPad game apps. 2. Friedman: dit is de niet-parametrische versie van de binnenonderwerpen ANOVA omdat het rangen vergelijkt voor groepen van meer dan twee met alleen ordinale gegevens. Een voorbeeld is het bepalen van de rang van drie verschillende websites op basis van gebruiksvriendelijkheid.
Tussen Ontwerp Van Het Onderwerp
1. Chi square: vergelijkt rangen voor zowel twee groep en meer dan twee Groep ontwerpen met alleen nominale gegevens. A. Chi square(Goodness of Fit) – vergelijkt het aandeel van het monster met een reeds bestaande waarde. Een voorbeeld is het vergelijken van alfabetiseringscijfers in Centraal-Missouri met die van de hele staat. B. Chi square (test of Independence)-vergelijkt de verhoudingen van twee variabelen om te zien of ze gerelateerd zijn of niet. Een voorbeeld zou zijn zijn er vergelijkbare aantallen honkbal en softbal atleten ingeschreven in de Algemene Psychologie cursus van dit semester. 2. Kruskall-Wallis: dit is de niet-parametrische versie van de tussen proefpersonen ANOVA omdat het ziet of meerdere monsters van dezelfde populatie zijn. Een voorbeeld is het bepalen van hoe deelnemers een arts beoordelen op basis van de vraag of hij / zij een computer, boek, of geen hulp bij het diagnosticeren van hen gebruikt. 3. Mann-Whitney: dit is de niet-parametrische versie van de onafhankelijke steekproeven T-test aangezien het rangen voor groepen van meer dan twee met slechts ordinale gegevens vergelijkt. Een voorbeeld zou zijn om te bepalen of het eten van Snickers snoep repen invloed student cijfers in wiskunde cursussen. 4. Correlaties: A. Spearman ‘ s Rho: net als de Pearson correlatie bepaalt ook deze test de sterkte van de relatie tussen twee variabelen op basis van hun rangen. Een voorbeeld zou zijn om de relatie tussen natuurkunde en Engels cursus cijfers te bepalen.
Sectie Statistische Analyse-Handleiding