
Fuente: Potencie sus modelos de visión por computadora con la API de Detección de objetos TensorFlow,
Jonathan Huang, Científico investigador y Vivek Rathod, Ingeniero de Software,
Blog de Inteligencia Artificial de Google
- Detección de objetos como tarea en la Visión por computadora
- YOLO como detector de objetos en tiempo real
- ¿Qué es YOLO?
- YOLO en comparación con otros detectores
- Versiones de YOLO
- Ejemplos de aplicaciones de YOLO
- YOLO como detector de objetos en TensorFlow & Keras
- TensorFlow & marcos Keras en Aprendizaje automático
- Implementación de YOLO en TensorFlow & Keras
- Cómo ejecutar YOLO preentrenado listo para usar y obtener resultados
- Cómo entrenar su modelo de detección de objetos YOLO personalizado
- Instrucción de tareas
- Conjunto de datos & anotaciones
- Dónde obtener datos de
- Cómo anotar datos para YOLO
- Cómo transformar datos de otros formatos a YOLO
- Dividir los datos en subconjuntos
- Creación de generadores de datos
- Instalación & configuración requerida para el entrenamiento de modelos
- Modelo de capacitación
- Requisitos previos
- Inicialización de objetos de modelo
- Definir callbacks
- Ajuste del modelo
- Modelo personalizado entrenado en modo de inferencia
- Conclusiones
- Anton Morgunov
- API de Detección de objetos TensorFlow: Prácticas recomendadas para Capacitación, Evaluación & Implementación
Detección de objetos como tarea en la Visión por computadora
Nos encontramos con objetos todos los días de nuestra vida. Mira a tu alrededor y encontrarás varios objetos a tu alrededor. Como ser humano, puedes detectar e identificar fácilmente cada objeto que ves. Es natural y no requiere mucho esfuerzo.
Para los ordenadores, sin embargo, la detección de objetos es una tarea que necesita una solución compleja. Para una computadora, «detectar objetos» significa procesar una imagen de entrada (o un solo fotograma de un video) y responder con información sobre los objetos en la imagen y su posición. En términos de visión artificial, llamamos a estas dos tareas clasificación y localización. Queremos que la computadora diga qué tipo de objetos se presentan en una imagen dada y dónde se encuentran exactamente.
Se han desarrollado múltiples soluciones para ayudar a los ordenadores a detectar objetos. Hoy, vamos a explorar un algoritmo de última generación llamado YOLO, que logra una alta precisión a velocidad en tiempo real. En particular, aprenderemos a entrenar este algoritmo en un conjunto de datos personalizado en TensorFlow / Keras.
Primero, veamos qué es exactamente YOLO y por qué es famoso.
YOLO como detector de objetos en tiempo real
¿Qué es YOLO?
YOLO es un acrónimo de «You Only Look Once» (No lo confundas con «You Only Live Once from The Simpsons»). Como su nombre indica, una sola» mirada » es suficiente para encontrar todos los objetos en una imagen e identificarlos.
En términos de aprendizaje automático, podemos decir que todos los objetos se detectan a través de una sola ejecución de algoritmo. Se hace dividiendo una imagen en una cuadrícula y prediciendo cajas delimitadoras y probabilidades de clase para cada celda de una cuadrícula. En caso de que nos gustaría emplear YOLO para la detección de automóviles, así es como podrían verse la cuadrícula y las cajas delimitadoras previstas:

La caja delimitadora que YOLO predice para el primer coche está en rojo.
La caja delimitadora que YOLO predice para el segundo coche es amarilla.
Fuente de la imagen.
La imagen de arriba contiene solo el conjunto final de cajas obtenidas después del filtrado. Vale la pena señalar que la salida raw de YOLO contiene muchos cuadros delimitadores para el mismo objeto. Estas cajas difieren en forma y tamaño. Como puede ver en la imagen de abajo, algunas cajas son mejores para capturar el objeto de destino, mientras que otras ofrecidas por un algoritmo funcionan mal.

Todas las cajas amarillas son para el segundo coche.
Las cajas rojas y amarillas en negrita son las mejores para la detección de automóviles.
Fuente de la imagen.
Para seleccionar el mejor cuadro delimitador para un objeto dado, se aplica un algoritmo de supresión no máxima (NMS).

predichas para que los autos conserven solo las que mejor capturan los objetos.
Fuente de la imagen.
Todas las cajas que YOLO predice tienen un nivel de confianza asociado con ellas. NMS utiliza estos valores de confianza para eliminar las casillas que se predijeron con poca certeza. Por lo general, todas estas son cajas que se predicen con confianza por debajo de 0,5.

Puede ver las puntuaciones de confianza en la esquina superior izquierda de cada cuadro, junto al nombre del objeto.
Fuente de la imagen.
Cuando se eliminan todas las cajas delimitadoras inciertas, solo quedan las cajas con el nivel de confianza alto. Para seleccionar la mejor entre los candidatos de mejor rendimiento, NMS selecciona la caja con el nivel de confianza más alto y calcula cómo se cruza con las otras cajas alrededor. Si una intersección es más alta que un nivel de umbral en particular, se elimina el cuadro delimitador con menor confianza. En caso de que NMS compare dos casillas que tienen una intersección por debajo de un umbral seleccionado, ambas casillas se mantendrán en las predicciones finales.
YOLO en comparación con otros detectores
Aunque se utiliza una red neuronal convolucional (CNN) bajo el capó de YOLO, todavía es capaz de detectar objetos con rendimiento en tiempo real. Es posible gracias a la capacidad de YOLO de hacer las predicciones simultáneamente en un enfoque de una sola etapa.
Otros algoritmos más lentos para la detección de objetos (como R-CNN más rápido) suelen utilizar un enfoque de dos etapas:
- en la primera etapa, se seleccionan regiones de imagen interesantes. Estas son las partes de una imagen que pueden contener cualquier objeto;
- en la segunda etapa, cada una de estas regiones se clasifica utilizando una red neuronal convolucional.
Por lo general, hay muchas regiones en una imagen con los objetos. Todas estas regiones se envían a la clasificación. La clasificación es una operación que consume mucho tiempo, por lo que el enfoque de detección de objetos de dos etapas funciona más lento en comparación con la detección de una etapa.
YOLO no selecciona las partes interesantes de una imagen, no hay necesidad de eso. En su lugar, predice cajas delimitadoras y clases para toda la imagen en una sola pasada de red hacia adelante.
A continuación puede ver qué tan rápido se compara YOLO con otros detectores populares.

SSD y YOLO son detectores de objetos de una etapa, mientras que Faster-RCNN
y R-FCN son detectores de objetos de dos etapas.
Fuente de la imagen.
Versiones de YOLO
YOLO fue presentado por primera vez en 2015 por Joseph Redmon en su artículo de investigación titulado «You Only Look Once: Unified, Real-Time Object Detection».
Desde entonces, YOLO ha evolucionado mucho. En 2016, Joseph Redmon describió la segunda versión de YOLO en «YOLO9000: Mejor, Más rápido, Más fuerte».
Unos dos años después de la segunda actualización de YOLO, a Joseph se le ocurrió otra actualización de red. Su artículo, llamado «YOLOv3: Una mejora incremental», llamó la atención de muchos ingenieros informáticos y se hizo popular en la comunidad de aprendizaje automático.
En 2020, Joseph Redmon decidió dejar de investigar la visión por computadora, pero no impidió que YOLO fuera desarrollado por otros. Ese mismo año, un equipo de tres ingenieros (Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao) diseñó la cuarta versión de YOLO, incluso más rápida y precisa que antes. Sus hallazgos se describen en el » YOLOv4: Velocidad y Precisión óptimas de Detección de objetos», artículo publicado el 23 de abril de 2020.
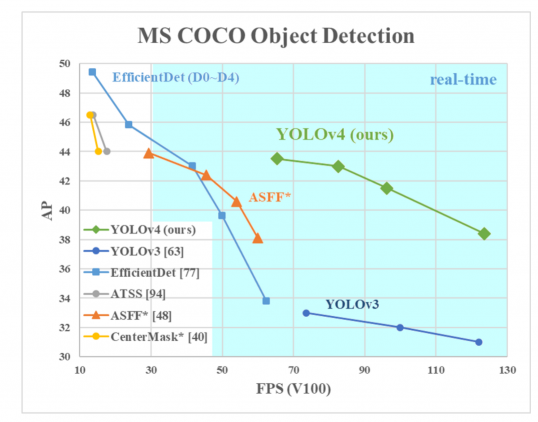
AP en el eje Y es una métrica llamada «precisión promedio». Describe la precisión de la red.
FPS (fotogramas por segundo) en el eje X es una métrica que describe la velocidad.
Fuente de la imagen.
Dos meses después del lanzamiento de la 4ª versión, un desarrollador independiente, Glenn Jocher, anunció la 5ª versión de YOLO. Esta vez, no se publicó ningún artículo de investigación. La red estuvo disponible en la página de GitHub de Jocher como una implementación de PyTorch. La quinta versión tenía la misma precisión que la cuarta, pero era más rápida.
Por último, en julio de 2020 recibimos otra gran actualización de YOLO. En un artículo titulado «PP-YOLO: Una implementación Efectiva y Eficiente del Detector de Objetos», Xiang Long y su equipo idearon una nueva versión de YOLO. Esta iteración de YOLO se basó en la versión del 3er modelo y superó el rendimiento de YOLO v4.

El mapa en el eje Y es una métrica llamada «precisión media media». Describe la precisión de la red.
FPS (fotogramas por segundo) en el eje X es una métrica que describe la velocidad.
Fuente de la imagen.
En este tutorial, vamos a echar un vistazo más de cerca a YOLOv4 y su implementación. ¿Por qué YOLOv4? Tres razones:
- Tiene una amplia aprobación en la comunidad de aprendizaje automático;
- Esta versión ha demostrado su alto rendimiento en una amplia gama de tareas de detección;
- YOLOv4 se ha implementado en múltiples frameworks populares, incluidos TensorFlow y Keras, con los que vamos a trabajar.
Ejemplos de aplicaciones de YOLO
Antes de pasar a la parte práctica de este artículo, implementando nuestro detector de objetos personalizado basado en YOLO, me gustaría mostrarles un par de implementaciones geniales de YOLOv4, y luego haremos nuestra implementación.
¡Presta atención a lo rápidas y precisas que son las predicciones!
Este es el primer ejemplo impresionante de lo que YOLOv4 puede hacer, detectando múltiples objetos de diferentes escenas de juegos y películas.
Alternativamente, puede comprobar esta demostración de detección de objetos desde una vista de cámara real.
YOLO como detector de objetos en TensorFlow & Keras
TensorFlow & marcos Keras en Aprendizaje automático

Fuente de la imagen.
Los marcos son esenciales en todos los ámbitos de la tecnología de la información. El aprendizaje automático no es una excepción. Hay varios jugadores establecidos en el mercado de ML que nos ayudan a simplificar la experiencia de programación general. PyTorch, scikit-learn, TensorFlow, Keras, MXNet y Caffe son solo algunos que vale la pena mencionar.
Hoy, vamos a trabajar en estrecha colaboración con TensorFlow / Keras. No es de extrañar que estos dos marcos se encuentren entre los más populares en el universo del aprendizaje automático. Esto se debe en gran medida al hecho de que tanto TensorFlow como Keras proporcionan capacidades ricas para el desarrollo. Estos dos marcos son bastante similares entre sí. Sin profundizar demasiado en los detalles, la clave es recordar que Keras es solo un envoltorio para el marco TensorFlow.
Implementación de YOLO en TensorFlow & Keras
En el momento de escribir este artículo, había 808 repositorios con implementaciones de YOLO en un backend de TensorFlow / Keras. YOLO versión 4 es lo que vamos a implementar. Limitando la búsqueda a solo YOLO v4, tengo 55 repositorios.
Hojeando cuidadosamente todos ellos, encontré un candidato interesante con el que continuar.
Fuente de la imagen.
Esta implementación fue desarrollada por taipingeric y jimmyaspire. Es bastante simple y muy intuitivo si has trabajado con TensorFlow y Keras antes.
Para comenzar a trabajar con esta implementación, simplemente clone el repositorio en su máquina local. A continuación, le mostraré cómo usar YOLO desde el primer momento y cómo entrenar su propio detector de objetos personalizado.
Cómo ejecutar YOLO preentrenado listo para usar y obtener resultados
Mirando la sección «Inicio rápido» del repositorio, puede ver que para poner en marcha un modelo, solo tenemos que importar YOLO como un objeto de clase y cargar los pesos del modelo:
from models import Yolov4model = Yolov4(weight_path='yolov4.weights', class_name_path='class_names/coco_classes.txt')
Tenga en cuenta que debe descargar manualmente los pesos del modelo con anticipación. El archivo de pesos de modelo que viene con YOLO proviene del conjunto de datos COCO y está disponible en la página oficial del proyecto darknet de AlexeyAB en GitHub. Puede descargar las pesas directamente a través de este enlace.
Justo después, el modelo está completamente listo para trabajar con imágenes en modo de inferencia. Solo usa el método predict () para una imagen de tu elección. El método es estándar para los marcos TensorFlow y Keras.
pred = model.predict('input.jpg')
por ejemplo, Para esta imagen de entrada:

Obtuve el siguiente modelo de salida:

Las predicciones que el modelo realizado se devuelven en una forma conveniente de un marco de datos pandas. Obtenemos el nombre de la clase, el tamaño de la caja y las coordenadas de cada objeto detectado:

Mucha información útil sobre los objetos detectados
Hay varios parámetros dentro del método predict() que nos permiten especificar si queremos trazar la imagen con los cuadros delimitadores previstos, nombres textuales para cada objeto, etc. Echa un vistazo a la cadena de documentos que acompaña al método predict () para familiarizarte con lo que tenemos disponible:

Debe esperar que su modelo solo pueda detectar tipos de objetos que estén estrictamente limitados al conjunto de datos COCO. Para saber qué tipos de objetos es capaz de detectar un modelo de YOLO preentrenado, consulte coco_classes.archivo txt disponible en … / yolo-v4-tf.kers / class_names/. Hay 80 tipos de objetos ahí.
Cómo entrenar su modelo de detección de objetos YOLO personalizado
Instrucción de tareas

Para diseñar un modelo de detección de objetos, debe saber qué tipos de objetos desea detectar. Este debe ser un número limitado de tipos de objetos para los que desea crear su detector. Es bueno tener una lista de tipos de objetos preparados a medida que avanzamos al desarrollo del modelo real.
Idealmente, también debería tener un conjunto de datos anotado que tenga objetos de su interés. Este conjunto de datos se utilizará para entrenar un detector y validarlo. Si aún no tiene un conjunto de datos o una anotación para él, no se preocupe, le mostraré dónde y cómo puede obtenerlo.
Conjunto de datos & anotaciones
Dónde obtener datos de
Si tiene un conjunto de datos anotado con el que trabajar, simplemente omita esta parte y pase al siguiente capítulo. Pero, si necesita un conjunto de datos para su proyecto, ahora vamos a explorar recursos en línea donde puede obtener datos.
Realmente no importa en qué campo esté trabajando, hay una gran posibilidad de que ya haya un conjunto de datos de código abierto que pueda usar para su proyecto.
El primer recurso que recomiendo es el artículo» Más de 50 Conjuntos de datos de detección de objetos de diferentes dominios de la industria » de Abhishek Annamraju, que ha recopilado maravillosos conjuntos de datos anotados para industrias como la Moda, el comercio Minorista, los Deportes, la Medicina y muchas más.

Fuente de la imagen.
Otros dos excelentes lugares para buscar los datos son paperswithcode.com y roboflow.com que proporcionan acceso a conjuntos de datos de alta calidad para la detección de objetos.
Consulte estos recursos anteriores para recopilar los datos que necesita o para enriquecer el conjunto de datos que ya tiene.
Cómo anotar datos para YOLO
Si su conjunto de datos de imágenes viene sin anotaciones, debe hacer el trabajo de anotación usted mismo. Esta operación manual consume bastante tiempo, así que asegúrese de tener suficiente tiempo para hacerlo.
Como herramienta de anotación, puede considerar varias opciones. Personalmente, recomendaría usar LabelImg. Es una herramienta de anotación de imágenes liviana y fácil de usar que puede generar anotaciones directamente para los modelos YOLO.
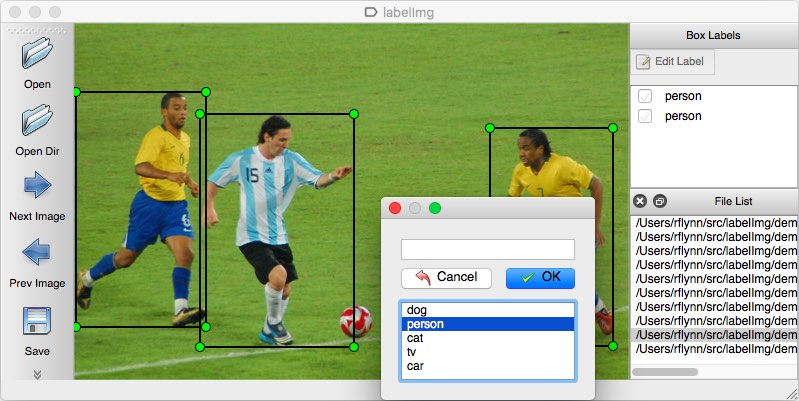
Fuente de la imagen.
Cómo transformar datos de otros formatos a YOLO
Las anotaciones para YOLO se presentan en forma de archivos txt. Cada línea de un archivo txt de YOLO debe tener el siguiente formato:
image1.jpg 10,15,345,284,0image2.jpg 100,94,613,814,0 31,420,220,540,1
Podemos separar cada línea del archivo txt y ver en qué consiste:
- La primera parte de una línea especifica los nombres de base de las imágenes: image1.jpg, imagen 2.jpg
- La segunda parte de una línea define las coordenadas del cuadro delimitador y la etiqueta de clase. Por ejemplo, 10,15,345,284,0 estados para xmin, ymin, xmax, ymax, class_id
- Si una imagen dada tiene más de un objeto, habrá varios cuadros y etiquetas de clase junto al nombre base de la imagen, divididos por un espacio.
Las coordenadas del cuadro delimitador son un concepto claro, pero ¿qué pasa con el número class_id que especifica la etiqueta de clase? Cada class_id está vinculado a una clase en particular en otro archivo txt. Por ejemplo, YOLO preentrenado viene con las coco_classes.archivo txt que se parece a este:
personbicyclecarmotorbikeaeroplanebus...
El número de líneas en los archivos de clases debe coincidir con el número de clases que el detector va a detectar. La numeración comienza desde cero, lo que significa que el número class_id para la primera clase en el archivo de clases será 0. La clase que se coloca en la segunda línea del archivo txt de clases tendrá el número 1.
Ahora ya sabe cómo se ve la anotación para YOLO. Para continuar creando un detector de objetos personalizado, le insto a que haga dos cosas ahora:
- cree un archivo txt de clases donde encontrará las clases que desea que detecte su detector. Recuerda que el orden de las clases es importante.
- Crea un archivo txt con anotaciones. En caso de que ya tenga anotación pero en el formato VOC (.XMLs), puede usar este archivo para transformar de XML a YOLO.
Dividir los datos en subconjuntos
Como siempre, queremos dividir el conjunto de datos en 2 subconjuntos: para entrenamiento y para validación. Se puede hacer tan simple como:
from utils import read_annotation_lines train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1)
Creación de generadores de datos
Cuando los datos se dividen, podemos proceder a la inicialización del generador de datos. Tendremos un generador de datos para cada archivo de datos. En nuestro caso, tendremos un generador para el subconjunto de entrenamiento y para el subconjunto de validación.
Así se crean los generadores de datos:
from utils import DataGenerator FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
Para resumir todo, así es como se ve el código completo para la división de datos y la creación de generadores:
from utils import read_annotation_lines, DataGenerator train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1) FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
Instalación & configuración requerida para el entrenamiento de modelos
Hablemos de los requisitos previos que son esenciales para crear su propio detector de objetos:
- Debería tener Python ya instalado en su computadora. En caso de que necesites instalarlo, te recomiendo seguir esta guía oficial de Anaconda;
- Si el equipo tiene una GPU habilitada para CUDA (una GPU creada por NVIDIA), se necesitan algunas bibliotecas relevantes para admitir la capacitación basada en GPU. En caso de que necesite habilitar la compatibilidad con GPU, consulte las directrices del sitio web de NVIDIA. Su objetivo es instalar la última versión de CUDA Toolkit y cuDNN para su sistema operativo;
- Es posible que desee organizar un entorno virtual independiente para trabajar. Este proyecto requiere TensorFlow 2 instalado. Todas las demás bibliotecas se presentarán más adelante;
- En cuanto a mí, estaba construyendo y entrenando mi modelo YOLOv4 en un entorno de desarrollo de cuadernos Jupyter. Aunque Jupyter Notebook parece una opción razonable, considere el desarrollo en un IDE de su elección si lo desea.
Modelo de capacitación

Requisitos previos
A estas alturas ya debería tener:
- Una división para el conjunto de datos;
- Dos generadores de datos inicializados;
- Un archivo txt con las clases.
Inicialización de objetos de modelo
Para prepararse para un trabajo de formación, inicialice el objeto de modelo YOLOv4. Asegúrese de usar None como valor para el parámetro weight_path. También debe proporcionar una ruta a su archivo txt de clases en este paso. Aquí está el código de inicialización que utilicé en mi proyecto:
class_name_path = 'path2project_folder/model_data/scans_file.txt' model = Yolov4(weight_path=None, class_name_path=class_name_path)
La inicialización del modelo anterior conduce a la creación de un objeto de modelo con un conjunto predeterminado de parámetros. Considere cambiar la configuración de su modelo pasando un diccionario como valor al parámetro del modelo de configuración.

Config especifica un conjunto de parámetros para el modelo YOLOv4.
La configuración predeterminada del modelo es un buen punto de partida, pero es posible que desee experimentar con otras configuraciones para mejorar la calidad del modelo.
En particular, recomiendo experimentar con anclas e img_size. Anclas especifique la geometría de las anclas que se utilizarán para capturar objetos. Cuanto mejor se ajusten las formas de los anclajes a las formas de los objetos, mayor será el rendimiento del modelo.
Aumentar img_size también podría ser útil en algunos casos. Tenga en cuenta que cuanto más alta sea la imagen, más tiempo hará la inferencia el modelo.
En caso de que desee usar Neptune como herramienta de seguimiento, también debe inicializar una ejecución de experimento, como esta:
import neptune.new as neptune run = neptune.init(project='projects/my_project', api_token=my_token)
Definir callbacks
TensorFlow & Keras nos permite usar callbacks para monitorear el progreso del entrenamiento, hacer puntos de control y administrar parámetros de entrenamiento (por ejemplo, velocidad de aprendizaje).
Antes de ajustar su modelo, defina devoluciones de llamada que serán útiles para sus propósitos. Asegúrese de especificar rutas para almacenar los puntos de control del modelo y los registros asociados. Así es como lo hice en uno de mis proyectos:
# defining pathes and callbacks dir4saving = 'path2checkpoint/checkpoints'os.makedirs(dir4saving, exist_ok = True) logdir = 'path4logdir/logs'os.makedirs(logdir, exist_ok = True) name4saving = 'epoch_{epoch:02d}-val_loss-{val_loss:.4f}.hdf5' filepath = os.path.join(dir4saving, name4saving) rLrCallBack = keras.callbacks.ReduceLROnPlateau(monitor = 'val_loss', factor = 0.1, patience = 5, verbose = 1) tbCallBack = keras.callbacks.TensorBoard(log_dir = logdir, histogram_freq = 0, write_graph = False, write_images = False) mcCallBack_loss = keras.callbacks.ModelCheckpoint(filepath, monitor = 'val_loss', verbose = 1, save_best_only = True, save_weights_only = False, mode = 'auto', period = 1)esCallBack = keras.callbacks.EarlyStopping(monitor = 'val_loss', mode = 'min', verbose = 1, patience = 10)
Podría haber notado que en el conjunto de devoluciones de llamada anterior, el TensorBoard se usa como herramienta de seguimiento. Considere el uso de Neptune como una herramienta mucho más avanzada para el seguimiento de experimentos. Si es así, no olvide inicializar otra devolución de llamada para habilitar la integración con Neptune:
from neptune.new.integrations.tensorflow_keras import NeptuneCallback neptune_cbk = NeptuneCallback(run=run, base_namespace='metrics')
Ajuste del modelo
Para comenzar el trabajo de entrenamiento, simplemente ajuste el objeto del modelo utilizando el método fit() estándar en TensorFlow / Keras. Así es como empecé a entrenar a mi modelo:
model.fit(data_gen_train, initial_epoch=0, epochs=10000, val_data_gen=data_gen_val, callbacks= )
Cuando comience el entrenamiento, verá una barra de progreso estándar.

El proceso de capacitación se evaluará el modelo al final de cada época. Si utiliza un conjunto de devoluciones de llamada similar a lo que inicialicé y pasé mientras ajustaba, los puntos de control que muestran mejoras en el modelo en términos de menor pérdida se guardarán en un directorio especificado.
Si no se producen errores y el proceso de capacitación se desarrolla sin problemas, el trabajo de capacitación se detendrá debido al final del número de épocas de capacitación, o si la devolución de llamada de detención temprana no detecta ninguna mejora adicional del modelo y detiene el proceso general.
En cualquier caso, debe terminar con varios puntos de control de modelos. Queremos seleccionar el mejor de todos los disponibles y usarlo para inferencia.
Modelo personalizado entrenado en modo de inferencia
Ejecutar un modelo entrenado en modo de inferencia es similar a ejecutar un modelo pre-entrenado fuera de la caja.

Inicializa un objeto de modelo que pasa la ruta al mejor punto de control, así como la ruta al archivo txt con las clases. Así es como se ve la inicialización del modelo para mi proyecto:
from models import Yolov4model = Yolov4(weight_path='path2checkpoint/checkpoints/epoch_48-val_loss-0.061.hdf5', class_name_path='path2classes_file/my_yolo_classes.txt')
Cuando el modelo se inicialice, simplemente use el método predict () para obtener una imagen de su elección para obtener las predicciones. Como resumen, las detecciones realizadas por el modelo se devuelven en una forma conveniente de un marco de datos pandas. Obtenemos el nombre de la clase, el tamaño de la caja y las coordenadas de cada objeto detectado.
Conclusiones
Acaba de aprender a crear un detector de objetos YOLOv4 personalizado. Hemos repasado el proceso de extremo a extremo, comenzando por la recopilación de datos, la anotación y la transformación. Tiene suficiente conocimiento sobre la cuarta versión de YOLO y en qué se diferencia de otros detectores.
Ahora nada le impide entrenar a su propio modelo en TensorFlow y Keras. Usted sabe de dónde obtener un modelo preentrenado y cómo comenzar el trabajo de capacitación.
En mi próximo artículo, te mostraré algunas de las mejores prácticas y trucos de vida que ayudarán a mejorar la calidad del modelo final. ¡Quédate con nosotros!



Anton Morgunov
Visión por Computador Ingeniero en la Base.Centro
Entusiasta del aprendizaje automático. Apasionado por la visión artificial. ¡Sin papel, más árboles! ¡Trabajando hacia la eliminación de copias en papel al pasar a la digitalización completa!
LEER A CONTINUACIÓN
API de Detección de objetos TensorFlow: Prácticas recomendadas para Capacitación, Evaluación & Implementación
13 minutos de lectura | Autor Anton Morgunov / Actualizado el 28 de mayo de 2021
Este artículo es la segunda parte de una serie en la que aprende un flujo de trabajo de extremo a extremo para la Detección de objetos TensorFlow y su API. En el primer artículo, aprendiste a crear un detector de objetos personalizado desde cero, pero todavía hay muchas cosas que necesitan tu atención para ser verdaderamente competentes.
Exploraremos temas que son tan importantes como el proceso de creación de modelos por el que ya hemos pasado. Estas son algunas de las preguntas que responderemos:
- ¿Cómo evaluar mi modelo y obtener una estimación de su rendimiento?
- ¿Cuáles son las herramientas que puedo usar para rastrear el rendimiento del modelo y comparar los resultados de varios experimentos?
- ¿Cómo puedo exportar mi modelo para usarlo en el modo de inferencia?
- ¿Hay alguna forma de aumentar aún más el rendimiento del modelo?
Continue reading ->