- ce este monitorizarea rețelei?
- Cum Funcționează Monitorizarea Rețelei?
- monitorizarea Hardware-ului de rețea
- cum se monitorizează Hardware-ul de rețea
- monitorizarea traficului de rețea Live
- strat de aplicare (strat 7)
- strat de Transport (strat 4)
- cum se monitorizează traficul de rețea Live
- monitorizarea rețelei vs.gestionarea rețelei
- beneficiile monitorizării rețelei
- cazuri de utilizare primară pentru monitorizarea rețelei
- provocările monitorizării rețelei
- instrumente de monitorizare a rețelei
ce este monitorizarea rețelei?
monitorizarea rețelei urmărește starea de sănătate a unei rețele în straturile sale hardware și software. Inginerii folosesc monitorizarea rețelei pentru a preveni și depana întreruperile și defecțiunile rețelei. În acest articol, vom descrie modul în care funcționează monitorizarea rețelei, cazurile sale principale de utilizare, provocările tipice legate de monitorizarea eficientă a rețelei și principalele caracteristici de căutat într-un instrument de monitorizare a rețelei.

Cum Funcționează Monitorizarea Rețelei?
rețelele permit transferul de informații între două sisteme, inclusiv între două computere sau aplicații. Modelul Open Systems Interconnection (OSI) descompune mai multe funcții pe care sistemele informatice se bazează pentru a trimite și primi date. Pentru ca datele să fie trimise într-o rețea, acestea vor trece prin fiecare componentă a OSI, utilizând protocoale diferite, începând de la stratul fizic și terminând la stratul de aplicație. Monitorizarea rețelei oferă vizibilitate asupra diferitelor componente care alcătuiesc o rețea, asigurându-se că inginerii pot depana problemele de rețea la orice nivel în care apar.
monitorizarea Hardware-ului de rețea
companiile care rulează sarcini de lucru Prem sau gestionează centre de date trebuie să se asigure că hardware-ul fizic prin care circulă traficul de rețea este sănătos și operațional. Aceasta cuprinde de obicei straturile fizice, de legătură de date și de rețea din modelul OSI (straturile 1, 2 și 3). În această abordare a monitorizării centrate pe dispozitive, companiile monitorizează componentele pentru transmiterea datelor, cum ar fi cablarea și dispozitivele de rețea, cum ar fi routerele, comutatoarele și firewall-urile. Un dispozitiv de rețea poate avea mai multe interfețe care îl conectează cu alte dispozitive și pot apărea defecțiuni de rețea la orice interfață.
cum se monitorizează Hardware-ul de rețea
majoritatea dispozitivelor de rețea sunt echipate cu suport pentru standardul SNMP (Simple Network Management Protocol). Prin SNMP, puteți monitoriza traficul de rețea de intrare și de ieșire și alte telemetrii importante de rețea critice pentru asigurarea sănătății și performanței echipamentelor la fața locului.
Protocolul Internet (IP) este un standard utilizat pe aproape toate rețelele pentru a furniza o adresă și un sistem de rutare pentru dispozitive. Acest protocol permite direcționarea informațiilor către destinația corectă prin rețele mari, inclusiv internetul public.
inginerii și administratorii de rețea folosesc de obicei instrumente de monitorizare a rețelei pentru a colecta următoarele tipuri de valori de pe dispozitivele de rețea:
-
Uptime
perioada de timp în care un dispozitiv de rețea trimite și primește cu succes date.
-
utilizarea procesorului
măsura în care un dispozitiv de rețea și-a folosit capacitatea de calcul pentru a procesa intrarea, a stoca date și a crea ieșire.
-
utilizarea lățimii de bandă
cantitatea de date, în octeți, care este în prezent trimisă sau primită de o anumită interfață de rețea. Inginerii urmăresc atât volumul de trafic trimis, cât și procentul de lățime de bandă totală utilizată.
-
Throughput
rata de trafic, în octeți pe secundă, care trece printr-o interfață pe un dispozitiv într-o anumită perioadă de timp. Inginerii urmăresc de obicei debitul unei singure interfețe și suma debitului tuturor interfețelor pe un singur dispozitiv.
-
erori de interfață / capturi aruncate înapoi în mare
acestea sunt erori pe dispozitivul receptor care determină o interfață de rețea să renunțe la un pachet de date. Erorile de interfață și aruncarea înapoi în mare pot rezulta din erori de configurare, probleme de lățime de bandă sau din alte motive.
-
valorile IP
valorile IP, cum ar fi întârzierea timpului și numărul de hamei, pot măsura viteza și eficiența conexiunilor dintre dispozitive.
rețineți că în mediile cloud, companiile achiziționează resurse de calcul și de rețea de la furnizorii de cloud care întrețin infrastructura fizică care le va rula serviciile sau aplicațiile. Prin urmare, găzduirea în Cloud transferă responsabilitatea gestionării hardware-ului fizic asupra furnizorului de cloud.
monitorizarea traficului de rețea Live
deasupra straturilor hardware ale rețelei, straturile software ale stivei de rețea sunt, de asemenea, implicate ori de câte ori datele sunt trimise printr-o rețea. Aceasta implică în principal straturile de transport și aplicare ale modelului OSI (stratul 4 și stratul 7). Monitorizarea acestor straturi ajută echipele să urmărească starea de sănătate a serviciilor, aplicațiilor și dependențelor de rețea subiacente pe măsură ce comunică printr-o rețea. Următoarele protocoale de rețea sunt deosebit de importante de monitorizat, deoarece sunt fundamentul majorității comunicațiilor în rețea:
strat de aplicare (strat 7)
-
Hypertext Transfer Protocol(HTTP)
protocolul utilizat de clienți (de obicei browsere web) pentru a comunica cu serverele web. Valorile HTTP primare includ volumul solicitării, erorile și latența. HTTPS este o versiune mai sigură, criptată a HTTP.
-
Domain Name System (DNS)
protocolul care traduce numele computerului (cum ar fi „server1.example.com”) la adresele IP prin utilizarea diferitelor servere de nume. Valorile DNS includ volumul solicitării, Erorile, timpul de răspuns și timeout-urile.
strat de Transport (strat 4)
-
Protocol Internet (IP) – protocol de control al transmisiei (TCP)
un protocol care secvențează pachetele în ordinea corectă și livrează pachete la adresa IP de destinație. Valorile TCP de monitorizat pot include pachete livrate, rata de transmisie, latență, retransmiteri și bruiaj.
-
User Datagram Protocol(UDP)
UDP este un alt protocol pentru transportul datelor. Oferă viteze de transmisie mai rapide, dar fără funcții avansate, cum ar fi livrarea garantată sau secvențierea pachetelor.
cum se monitorizează traficul de rețea Live
aplicațiile de monitorizare a rețelei se pot baza pe o varietate de metode pentru a monitoriza aceste protocoale de comunicare, inclusiv tehnologii mai noi, cum ar fi extended Berkeley Packet Filter (eBPF). Cu cheltuieli minime, eBPF urmărește pachetele de date de rețea pe măsură ce curg între dependențele din mediul dvs. și traduce datele într-un format care poate fi citit de om.
monitorizarea rețelei vs.gestionarea rețelei
monitorizarea rețelei urmărește starea de sănătate a unei rețele în straturile sale hardware și software. Inginerii folosesc monitorizarea rețelei pentru a preveni și depana întreruperile și defecțiunile rețelei. În acest articol, vom descrie modul în care funcționează monitorizarea rețelei, cazurile sale principale de utilizare, provocările tipice legate de monitorizarea eficientă a rețelei și principalele caracteristici de căutat într-un instrument de monitorizare a rețelei.
vizibilitate End-to-End în rețeaua Cloud on-Prem &
beneficiile monitorizării rețelei
eșecurile rețelei pot provoca perturbări majore ale afacerii, iar în rețelele complexe, distribuite, este esențial să aveți vizibilitate completă pentru a înțelege și rezolva problemele. De exemplu, o problemă de conectivitate într-o singură regiune sau zonă de disponibilitate poate avea un impact de anvergură asupra unui întreg serviciu dacă se renunță la interogările interregionale.
un beneficiu comun al monitorizării dispozitivelor de rețea este că ajută la prevenirea sau minimizarea întreruperilor cu impact asupra afacerii. Instrumentele de monitorizare a rețelei pot colecta periodic informații de la dispozitive pentru a se asigura că acestea sunt disponibile și funcționează conform așteptărilor și vă pot avertiza dacă nu sunt. Dacă apare o problemă pe un dispozitiv, cum ar fi saturația ridicată pe o anumită interfață, inginerii de rețea pot acționa rapid pentru a preveni o întrerupere sau orice impact orientat către utilizator. De exemplu, echipele pot implementa echilibrarea încărcării pentru a distribui traficul pe mai multe servere dacă monitorizarea arată că o gazdă nu este suficientă pentru a servi volumul de solicitări.
un alt beneficiu al monitorizării rețelei este că poate ajuta companiile să îmbunătățească performanța aplicațiilor. De exemplu, pierderea pachetelor de rețea se poate manifesta ca latență a aplicației orientată către utilizator. Cu monitorizarea rețelei, inginerii pot identifica exact unde se produce pierderea pachetelor și pot remedia problema. Monitorizarea datelor de rețea ajută, de asemenea, companiile să reducă costurile de trafic legate de rețea prin apariția unor modele ineficiente de trafic transregional. În cele din urmă, inginerii pot utiliza, de asemenea, monitorizarea rețelei pentru a verifica dacă aplicațiile lor pot ajunge la serverele DNS, fără de care site-urile web nu se vor încărca corect pentru utilizatori.
instrumentele moderne de monitorizare pot unifica datele de rețea cu valorile infrastructurii, valorile aplicațiilor și alte valori, oferind tuturor inginerilor dintr-o organizație acces la aceleași informații atunci când diagnostichează și depanează probleme. Această capacitate de consolidare a datelor de monitorizare permite echipelor să determine cu ușurință dacă latența sau erorile provin din rețea, Cod, o problemă la nivel de gazdă sau o altă sursă.
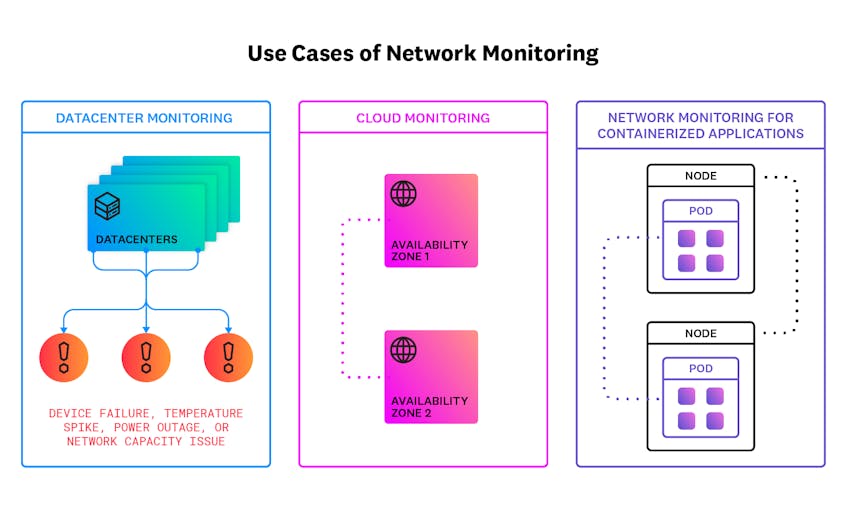
cazuri de utilizare primară pentru monitorizarea rețelei
unele cazuri de utilizare specifice pentru monitorizarea rețelei includ următoarele:
-
Datacenter Monitoring
inginerii de rețea pot utiliza monitorizarea rețelei pentru a colecta date în timp real din centrele lor de date și pentru a configura alerte atunci când apare o problemă, cum ar fi o defecțiune a dispozitivului, o creștere a temperaturii, o pană de curent sau o problemă de capacitate a rețelei.
-
monitorizarea rețelei Cloud
companiile care găzduiesc servicii în rețelele cloud pot utiliza un instrument de monitorizare a rețelei pentru a se asigura că dependențele aplicațiilor comunică bine între ele. Inginerii pot utiliza, de asemenea, monitorizarea rețelei pentru a ajuta la înțelegerea costurilor rețelei cloud, analizând cât de mult trafic trece între regiuni sau cât de mult trafic este gestionat de diferiți furnizori de cloud.
-
monitorizarea rețelei pentru aplicații containerizate
containerele permit echipelor să împacheteze și să livreze aplicații pe mai multe sisteme de operare. Adesea, inginerii folosesc sisteme de orchestrare a containerelor, cum ar fi Kubernetes, pentru a construi aplicații distribuite scalabile. Indiferent dacă aplicațiile lor containerizate rulează on-prem sau în cloud, echipele pot utiliza monitorizarea rețelei pentru a se asigura că diferitele componente ale aplicației comunică corect între ele.
companiile care adoptă o abordare hibridă în găzduirea serviciilor lor pot utiliza monitorizarea rețelei în fiecare dintre aceste moduri. Într-o abordare hibridă, unele sarcini de lucru depind de centrele de date gestionate intern, în timp ce altele sunt externalizate către cloud. În acest caz, un instrument de monitorizare a rețelei poate fi utilizat pentru a obține o vizualizare unificată a valorilor rețelei on-premise și cloud, precum și starea de sănătate a datelor care curg între ambele medii. Este obișnuit să folosiți o abordare hibridă atunci când o organizație este în proces de migrare către cloud.
provocările monitorizării rețelei
rețelele moderne sunt incredibil de mari și complexe, transmitând milioane de pachete în fiecare secundă. Pentru a depana problemele dintr-o rețea, inginerii folosesc în mod tradițional jurnalele de flux pentru a investiga traficul între două adrese IP, conectați-vă manual la servere prin Secure Shell Access (SSH) sau accesați de la distanță echipamente de rețea pentru a rula diagnostice. Niciunul dintre aceste procese nu funcționează bine la scară, nu oferă euristici limitate de sănătate a rețelei și nu are date contextuale din aplicații și infrastructură care ar putea arunca lumină asupra cauzei principale a potențialelor probleme de rețea.
inginerii se confruntă, de asemenea, cu provocări în monitorizarea rețelei atunci când companiile se mută în cloud. Complexitatea rețelei crește, deoarece volumul de lucru în cloud și infrastructura lor de bază sunt dinamice și efemere. Instanțele cloud de scurtă durată pot apărea și dispărea pe baza modificărilor cererii utilizatorilor. Pe măsură ce aceste instanțe cloud se rotesc în sus și în jos, adresele lor IP se schimbă, ceea ce face dificilă urmărirea conexiunilor de rețea folosind doar date de conexiune IP-IP. Multe instrumente de monitorizare nu vă permit să monitorizați conexiunile de rețea între entități semnificative, cum ar fi servicii sau pod-uri. În plus, deoarece furnizorul de cloud furnizează infrastructura rețelei, problemele de rețea sunt adesea în afara controlului clientului, forțând sarcinile de lucru să fie mutate într-o altă zonă sau regiune de disponibilitate pentru a evita problemele până când acestea sunt remediate.
instrumente de monitorizare a rețelei
soluții bazate pe Software-as-a-service (SaaS), cum ar fi Datadog, descompun Silozurile între echipele de inginerie și aduc o abordare holistică a monitorizării rețelei. Produsele de monitorizare a rețelei Datadog unifică datele de rețea cu datele privind infrastructura, aplicațiile și experiența utilizatorului într-un singur panou de sticlă.
Network Device Monitoring (NDM) autodescoperă dispozitivele de la o gamă largă de furnizori și vă permite să detaliați pentru a monitoriza starea de sănătate a dispozitivelor individuale. Puteți chiar să monitorizați în mod proactiv sănătatea dispozitivului cu monitoare de detectare a anomaliilor pentru utilizarea lățimii de bandă și alte valori.
monitorizarea performanței rețelei (NPM) oferă vizibilitate în restul stivei dvs. de rețea și analizează traficul în timp real pe măsură ce curge în mediul dvs. Echipele pot monitoriza comunicarea între servicii, gazde, pod—uri Kubernetes și orice alte puncte finale semnificative-nu doar date de conexiune IP. Și prin legarea valorilor de rețea împreună cu alte valori și date de telemetrie, echipele au un context bogat pentru a identifica și rezolva orice problemă de performanță oriunde în stiva lor.
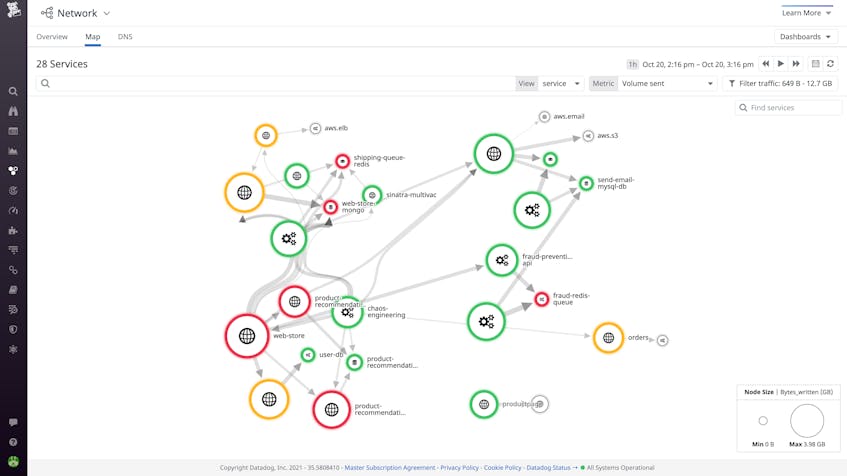
pentru informații suplimentare din perspectiva utilizatorilor finali, puteți utiliza Datadog Synthetic Monitoring. Testele sintetice vă permit să determinați modul în care API-urile și paginile web funcționează la diferite niveluri de rețea (DNS, HTTP, ICMP, SSL, TCP). Datadog vă avertizează asupra comportamentului defect, cum ar fi un timp de răspuns ridicat, un cod de stare neașteptat sau o caracteristică defectă.