
źródło: doładuj swoje komputerowe modele wizji za pomocą interfejsu API wykrywania obiektów TensorFlow,
Jonathan Huang, naukowiec i Vivek Rathod, inżynier oprogramowania,
Blog Google AI
- detekcja obiektów jako zadanie w wizji komputerowej
- YOLO jako detektor obiektów w czasie rzeczywistym
- co to jest YOLO?
- YOLO w porównaniu z innymi detektorami
- wersje YOLO
- przykłady aplikacji YOLO
- YOLO jako detektor obiektów w TensorFlow & Keras
- TensorFlow & struktury Keras w uczeniu maszynowym
- implementacja YOLO w TensorFlow& Keras
- jak uruchomić wstępnie wyszkolony YOLO po wyjęciu z pudełka i uzyskać wyniki
- jak trenować niestandardowy model wykrywania obiektów YOLO
- Instrukcja Zadań
- Dataset & adnotacje
- gdzie pobrać dane z
- jak adnotować dane dla YOLO
- jak przekształcić dane z innych formatów NA Yolo
- dzielenie danych na podzbiory
- Tworzenie generatorów danych
- instalacja & konfiguracja wymagana do szkolenia modeli
- szkolenia modelarskie
- inicjalizacja obiektu modelu
- Definiowanie wywołań zwrotnych
- dopasowanie modelu
- wytrenowany model niestandardowy w trybie wnioskowania
- wnioski
- Anton Morgunov
- TensorFlow object Detection API: najlepsze praktyki do szkolenia, ewaluacji & wdrażanie
detekcja obiektów jako zadanie w wizji komputerowej
każdego dnia spotykamy się z obiektami. Rozejrzyj się, a znajdziesz wiele obiektów wokół siebie. Jako istota ludzka możesz łatwo wykryć i zidentyfikować każdy obiekt, który widzisz. To naturalne i nie wymaga wiele wysiłku.
jednak w przypadku komputerów wykrywanie obiektów jest zadaniem wymagającym złożonego rozwiązania. Dla komputera „wykrywanie obiektów” oznacza przetwarzanie obrazu wejściowego (lub pojedynczej klatki z wideo) i reagowanie informacjami o obiektach na obrazie i ich pozycji. W kategoriach wizji komputerowej nazywamy te dwa zadania klasyfikacją i lokalizacją. Chcemy, aby komputer powiedział, jakie obiekty są prezentowane na danym obrazie i gdzie dokładnie się znajdują.
opracowano wiele rozwiązań, które pomagają komputerom wykrywać obiekty. Dzisiaj zbadamy najnowocześniejszy algorytm o nazwie YOLO, który osiąga wysoką dokładność w czasie rzeczywistym. W szczególności nauczymy się trenować ten algorytm na niestandardowym zbiorze danych w TensorFlow / Keras.
najpierw zobaczmy, czym dokładnie jest YOLO i z czego słynie.
YOLO jako detektor obiektów w czasie rzeczywistym
co to jest YOLO?
YOLO to skrót od „You Only Look Once” (nie myl tego Z You Only Live Once z The Simpsons). Jak sama nazwa wskazuje, wystarczy jedno „spojrzenie”, aby znaleźć wszystkie obiekty na obrazie i je zidentyfikować.
w kategoriach uczenia maszynowego możemy powiedzieć, że wszystkie obiekty są wykrywane za pomocą jednego algorytmu. Odbywa się to poprzez podzielenie obrazu na siatkę i przewidywanie obwiedni i prawdopodobieństwa klas dla każdej komórki w siatce. W przypadku, gdy chcielibyśmy zatrudnić YOLO do wykrywania samochodów, oto jak może wyglądać siatka i przewidywane pola obwiedni:

Bounding box, który Yolo przewiduje dla pierwszego samochodu jest w kolorze czerwonym.
Bounding box, który Yolo przewiduje dla drugiego samochodu jest żółty.
Źródło zdjęcia .
powyższy obrazek zawiera tylko końcowy zestaw pól uzyskanych po filtrowaniu. Warto zauważyć, że wyjście raw Yolo zawiera wiele obwiedni dla tego samego obiektu. Pudełka te różnią się kształtem i rozmiarem. Jak widać na poniższym obrazku, niektóre pola są lepsze w przechwytywaniu obiektu docelowego, podczas gdy inne oferowane przez algorytm działają słabo.

wszystkie żółte pudełka są na drugi samochód.
pogrubione czerwone i żółte pola są najlepsze do wykrywania samochodów.
Źródło zdjęcia .
aby wybrać najlepszą obwiednię dla danego obiektu, stosuje się algorytm tłumienia innego niż maksymalne (NMS).

przewidziane dla samochodów, aby zachować tylko te, które najlepiej przechwytywają obiekty.
Źródło zdjęcia .
wszystkie pola, które przewiduje YOLO, mają poziom zaufania związany z nimi. NMS wykorzystuje te wartości ufności, aby usunąć pola, które były przewidywane z małą pewnością. Zazwyczaj są to wszystkie pola, które są przewidywane z ufnością poniżej 0,5.

możesz zobaczyć wyniki ufności w lewym górnym rogu każdego pola, obok nazwy obiektu.
Źródło zdjęcia .
po usunięciu wszystkich niepewnych obwiedni zostają tylko te z wysokim poziomem pewności. Aby wybrać najlepszą spośród najlepszych kandydatów, NMS wybiera skrzynkę o najwyższym poziomie zaufania i oblicza, w jaki sposób przecina się z innymi skrzynkami wokół. Jeśli przecięcie jest wyższe niż określony poziom progu, obwiednię o niższym poziomie ufności usuwa się. W przypadku, gdy NMS porównuje dwa pola, które mają przecięcie poniżej wybranego progu, oba pola są utrzymywane w ostatecznych prognozach.
YOLO w porównaniu z innymi detektorami
chociaż pod maską YOLO używana jest konwolutacyjna sieć neuronowa (CNN), nadal jest w stanie wykrywać obiekty z wydajnością w czasie rzeczywistym. Jest to możliwe dzięki zdolności YOLO do wykonywania prognoz jednocześnie w podejściu jednoetapowym.
Inne, wolniejsze algorytmy wykrywania obiektów (np. szybszy R-CNN) zazwyczaj wykorzystują dwustopniowe podejście:
- w pierwszym etapie wybierane są interesujące regiony obrazu. Są to części obrazu, które mogą zawierać dowolne obiekty;
- w drugim etapie każdy z tych regionów jest klasyfikowany za pomocą splotowej sieci neuronowej.
zazwyczaj na obrazie z obiektami znajduje się wiele regionów. Wszystkie te regiony są wysyłane do klasyfikacji. Klasyfikacja jest operacją czasochłonną, dlatego dwustopniowe podejście do wykrywania obiektów działa wolniej w porównaniu z detekcją jednostopniową.
YOLO nie wybiera interesujących części obrazu, nie ma takiej potrzeby. Zamiast tego przewiduje obwiedniowe pola i klasy dla całego obrazu w jednym przejściu sieciowym.
poniżej możesz zobaczyć jak szybko YOLO jest porównywane do innych popularnych detektorów.

SSD i YOLO są jednostopniowymi detektorami obiektów, podczas gdy Faster-rcnn
i R-FCN są dwustopniowymi detektorami obiektów.
Źródło zdjęcia .
wersje YOLO
YOLO zostały po raz pierwszy wprowadzone w 2015 roku przez Josepha Redmona w jego pracy badawczej zatytułowanej „you Only Look Once: Unified, Real-Time Object Detection”.
od tego czasu YOLO bardzo się rozwinęło. W 2016 Joseph Redmon opisał drugą wersję YOLO w „YOLO9000: Better, Faster, Stronger”.
około dwóch lat po drugiej aktualizacji YOLO Joseph wymyślił kolejną aktualizację sieci. Jego praca, zatytułowana „YOLOv3: an Incremental Improvement”, przyciągnęła uwagę wielu inżynierów komputerowych i stała się popularna w społeczności uczenia maszynowego.
w 2020 roku Joseph Redmon postanowił przestać badać wizję komputerową, ale nie powstrzymało to YOLO przed rozwojem przez innych. W tym samym roku zespół trzech inżynierów (Alexey Boczkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao) zaprojektował czwartą wersję YOLO, jeszcze szybszą i dokładniejszą niż wcześniej. Ich ustalenia opisane są w ” YOLOv4: Optymalna szybkość i dokładność detekcji obiektów”, opublikowano 23 kwietnia 2020 roku.
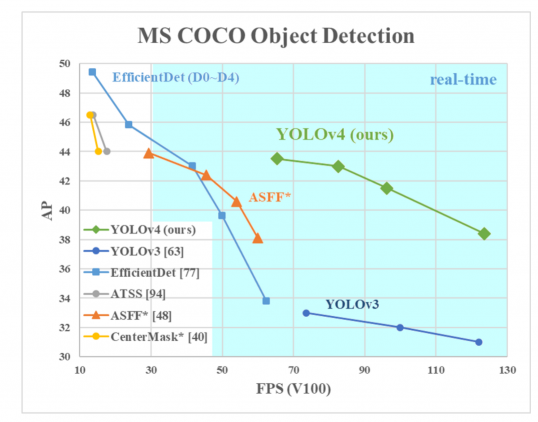
AP na osi Y jest metryką zwaną „średnią precyzją”. Opisuje dokładność sieci.
FPS (klatek na sekundę)na osi X jest metryką opisującą prędkość.
Źródło zdjęcia .
dwa miesiące po wydaniu czwartej wersji, niezależny deweloper, Glenn Jocher, ogłosił piątą wersję YOLO. Tym razem nie opublikowano pracy naukowej. Net stał się dostępny na stronie GitHub Jochera jako implementacja PyTorch. Piąta wersja miała prawie taką samą dokładność jak czwarta, ale była szybsza.
wreszcie, w lipcu 2020 roku mamy kolejną dużą aktualizację YOLO. W artykule zatytułowanym „PP-YOLO: skuteczna i wydajna implementacja detektora obiektów” Xiang Long i zespół opracowali nową wersję YOLO. Ta iteracja YOLO była oparta na trzeciej wersji modelu i przewyższała osiągi Yolo v4.

mapa na osi Y jest metryką o nazwie „średnia średnia precyzja”. Opisuje dokładność sieci.
FPS (klatek na sekundę)na osi X jest metryką opisującą prędkość.
Źródło zdjęcia .
w tym samouczku przyjrzymy się bliżej YOLOv4 i jego implementacji. Dlaczego YOLOv4? Trzy powody:
- ma szerokie uznanie w społeczności uczenia maszynowego;
- ta wersja udowodniła swoją wysoką wydajność w szerokim zakresie zadań wykrywania;
- YOLOv4 został zaimplementowany w wielu popularnych frameworkach, w tym TensorFlow i Keras, z którymi będziemy pracować.
przykłady aplikacji YOLO
zanim przejdziemy do praktycznej części tego artykułu, implementując nasz Niestandardowy detektor obiektów oparty na YOLO, chciałbym pokazać wam kilka fajnych implementacji YOLOv4, a następnie zrobimy naszą implementację.
zwróć uwagę na to, jak szybkie i dokładne są prognozy!
oto pierwszy imponujący przykład tego, co może zrobić YOLOv4, wykrywając wiele obiektów z różnych scen z gier i filmów.
Alternatywnie możesz sprawdzić to demo wykrywania obiektów z rzeczywistego widoku kamery.
YOLO jako detektor obiektów w TensorFlow & Keras
TensorFlow & struktury Keras w uczeniu maszynowym

Źródło zdjęcia .
ramy są niezbędne w każdej dziedzinie technologii informatycznych. Uczenie maszynowe nie jest wyjątkiem. Istnieje kilka uznanych graczy na rynku ML, które pomagają nam uprościć ogólne doświadczenie programistyczne. PyTorch, scikit-learn, TensorFlow, Keras, Mxnet i Caffe to tylko niektóre z nich.
dzisiaj będziemy ściśle współpracować z TensorFlow/Keras. Nic dziwnego, że są to jedne z najpopularniejszych frameworków we wszechświecie uczenia maszynowego. W dużej mierze wynika to z faktu, że zarówno TensorFlow, jak i Keras zapewniają bogate możliwości rozwoju. Te dwie ramy są do siebie bardzo podobne. Nie zagłębiając się zbytnio w szczegóły, kluczową rzeczą do zapamiętania jest to, że Keras jest tylko opakowaniem dla frameworka TensorFlow.
implementacja YOLO w TensorFlow& Keras
w momencie pisania tego artykułu istniało 808 repozytoriów z implementacjami YOLO na zapleczu TensorFlow / Keras. YOLO wersja 4 jest to, co zamierzamy wdrożyć. Ograniczając wyszukiwanie tylko do YOLO v4, mam 55 repozytoriów.
uważnie przeglądając je wszystkie, znalazłem ciekawego kandydata do kontynuowania.
Źródło zdjęcia .
implementacja ta została opracowana przez taipingerica i jimmyaspire. Jest to dość proste i bardzo intuicyjne, jeśli pracowałeś wcześniej z TensorFlow i Keras.
aby rozpocząć pracę z tą implementacją, wystarczy sklonować repo na komputerze lokalnym. Następnie pokażę Ci, jak używać YOLO po wyjęciu z pudełka i jak trenować własny niestandardowy detektor obiektów.
jak uruchomić wstępnie wyszkolony YOLO po wyjęciu z pudełka i uzyskać wyniki
patrząc na sekcję „Szybki Start” w repo, widać, że aby uruchomić model i uruchomić, wystarczy zaimportować YOLO jako obiekt klasy i załadować wagi modelu:
from models import Yolov4model = Yolov4(weight_path='yolov4.weights', class_name_path='class_names/coco_classes.txt')
należy pamiętać, że należy ręcznie pobrać wagi modeli z wyprzedzeniem. Plik wagi modelu dostarczany z YOLO pochodzi ze zbioru danych COCO i jest dostępny na oficjalnej stronie projektu darknet alexeyab na GitHub. Możesz pobrać wagi bezpośrednio za pomocą tego linku.
zaraz po tym model jest w pełni gotowy do pracy z obrazami w trybie wnioskowania. Wystarczy użyć metody predict () dla wybranego obrazu. Metoda jest standardem dla frameworków TensorFlow i Keras.
pred = model.predict('input.jpg')
na przykład dla tego obrazu wejściowego:

mam następujące wyjście modelu:

przewidywania, że wykonany model są zwracane w wygodnej formie ramki danych pandy. Otrzymujemy nazwę klasy, rozmiar pola i Współrzędne dla każdego wykrytego obiektu:

wiele przydatnych informacji o wykrytych obiektach
w metodzie predict () jest wiele parametrów, które pozwalają nam określić, czy chcemy wykreślić obraz z przewidywanymi obwiedniami, nazwami tekstowymi dla każdego obiektu itp. Sprawdź docstring, który idzie wraz z predict() metoda, aby zapoznać się z tym, co jest dla nas dostępne:

powinieneś oczekiwać, że twój model będzie w stanie wykryć tylko typy obiektów, które są ściśle ograniczone do zbioru danych COCO. Aby dowiedzieć się, jakie typy obiektów jest w stanie wykryć wstępnie wyszkolony model YOLO, sprawdź coco_classes.plik txt dostępny w … / yolo-v4-tf.kers/class_names/. Jest tam 80 typów obiektów.
jak trenować niestandardowy model wykrywania obiektów YOLO
Instrukcja Zadań

aby zaprojektować model wykrywania obiektów, musisz wiedzieć, jakie typy obiektów chcesz wykryć. To powinna być ograniczona liczba typów obiektów, dla których chcesz utworzyć detektor. Dobrze jest mieć przygotowaną listę typów obiektów, gdy przejdziemy do rzeczywistego rozwoju modelu.
idealnie, powinieneś również mieć adnotowany zbiór danych, który zawiera interesujące Cię obiekty. Ten zestaw danych zostanie użyty do wytrenowania detektora i jego weryfikacji. Jeśli nie masz jeszcze zestawu danych ani adnotacji, nie martw się, pokażę Ci, gdzie i jak możesz go uzyskać.
Dataset & adnotacje
gdzie pobrać dane z
jeśli masz przypisany zestaw danych do pracy, po prostu pomiń tę część i przejdź do następnego rozdziału. Ale jeśli potrzebujesz zestawu danych dla swojego projektu, teraz zbadamy zasoby online, w których możesz uzyskać dane.
nie ma znaczenia, w jakim obszarze pracujesz, istnieje duża szansa, że istnieje już zbiór danych open-source, którego możesz użyć do swojego projektu.
pierwszym zasobem, który polecam, jest Artykuł” 50 + zestawów danych do wykrywania obiektów z różnych domen branżowych ” autorstwa Abhisheka Annamraju, który zebrał wspaniałe zbiory danych z adnotacjami dla branż takich jak moda, Handel detaliczny, Sport, Medycyna i wiele innych.

Źródło zdjęcia .
Inne dwa świetne miejsca do wyszukiwania danych to paperswithcode.com oraz roboflow.com które zapewniają dostęp do wysokiej jakości zbiorów danych do wykrywania obiektów.
Sprawdź powyższe zasoby, aby zebrać potrzebne dane lub wzbogacić zestaw danych, który już posiadasz.
jak adnotować dane dla YOLO
jeśli twój zbiór danych obrazów jest bez adnotacji, musisz wykonać zadanie adnotacji samodzielnie. Ta ręczna operacja jest dość czasochłonna, więc upewnij się, że masz wystarczająco dużo czasu, aby to zrobić.
jako narzędzie do adnotacji możesz rozważyć wiele opcji. Osobiście polecam korzystanie z LabelImg. Jest to lekkie i łatwe w użyciu narzędzie do adnotacji obrazu, które może bezpośrednio generować adnotacje dla modeli YOLO.
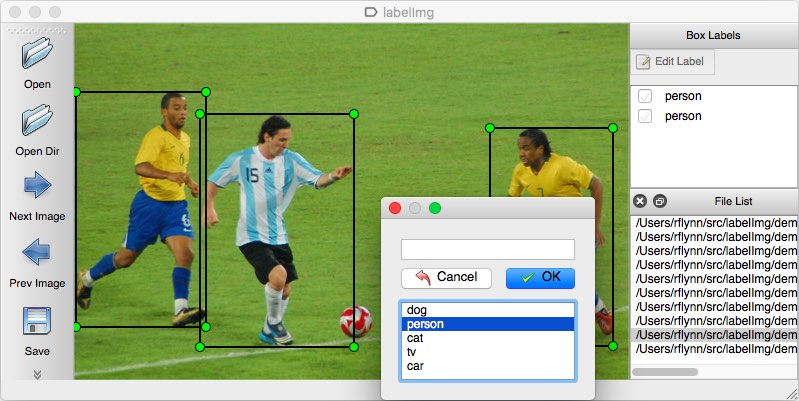
Źródło zdjęcia .
jak przekształcić dane z innych formatów NA Yolo
adnotacje dla YOLO są w formie plików txt. Każda linia w pliku TXT fol Yolo musi mieć następujący format:
image1.jpg 10,15,345,284,0image2.jpg 100,94,613,814,0 31,420,220,540,1
możemy podzielić każdą linię z pliku txt i zobaczyć z czego się składa:
- pierwsza część linii określa nazwy bazowe obrazów: image1.jpg, image2.. jpg
- druga część linii definiuje współrzędne obwiedni i etykietę klasy. Na przykład 10,15,345,284,0 stanów dla xmin, ymin, xmax, ymax, class_id
- jeśli dany obraz ma więcej niż jeden obiekt, obok nazwy bazowej obrazu będzie znajdować się wiele pól i etykiet klas, podzielonych spacją.
współrzędne obwiedni są jasnym pojęciem, ale co z numerem class_id, który określa Etykietę klasy? Każdy class_id jest połączony z konkretną klasą w innym pliku txt. Na przykład, wstępnie wyszkolony YOLO jest wyposażony w coco_classes.plik txt, który wygląda tak:
personbicyclecarmotorbikeaeroplanebus...
Liczba linii w plikach klas musi odpowiadać liczbie klas, które detektor wykryje. Numeracja zaczyna się od zera, co oznacza, że liczba class_id dla pierwszej klasy w pliku classes będzie równa 0. Klasa, która znajduje się w drugiej linii w pliku classes txt będzie miała numer 1.
teraz wiesz, jak wygląda adnotacja dla YOLO. Aby kontynuować tworzenie niestandardowego detektora obiektów, zachęcam do zrobienia dwóch rzeczy teraz:
- Utwórz plik TXT klas, w którym znajdziesz klasy, które ma wykryć twój detektor. Pamiętaj, że porządek klasowy ma znaczenie.
- Utwórz plik txt z adnotacjami. W przypadku, gdy masz już adnotację, ale w formacie VOC (.XMLs), możesz użyć tego pliku do przekształcenia z XML do YOLO.
dzielenie danych na podzbiory
jak zawsze chcemy podzielić zbiór danych na 2 podzbiory: do treningu i do walidacji. Można to zrobić tak prosto jak:
from utils import read_annotation_lines train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1)
Tworzenie generatorów danych
gdy dane są podzielone, możemy przejść do inicjalizacji generatora danych. Będziemy mieli generator danych dla każdego pliku danych. W naszym przypadku będziemy mieli generator dla podzbioru szkolenia i dla podzbioru walidacji.
oto jak powstają Generatory danych:
from utils import DataGenerator FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
podsumowując, oto jak wygląda kompletny kod dzielenia danych i tworzenia generatora:
from utils import read_annotation_lines, DataGenerator train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1) FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
instalacja & konfiguracja wymagana do szkolenia modeli
porozmawiajmy o wymaganiach wstępnych, które są niezbędne do stworzenia własnego detektora obiektów:
- powinieneś mieć już zainstalowany Python na swoim komputerze. Jeśli potrzebujesz go zainstalować, polecam postępować zgodnie z tym oficjalnym przewodnikiem Anaconda;
- jeśli twój komputer ma procesor graficzny z obsługą CUDA (GPU firmy NVIDIA), potrzebne jest kilka odpowiednich bibliotek do obsługi szkoleń opartych na GPU. Jeśli potrzebujesz włączyć obsługę GPU, zapoznaj się z wytycznymi na stronie internetowej firmy NVIDIA. Twoim celem jest zainstalowanie najnowszej wersji zarówno zestawu narzędzi CUDA, jak i cuDNN dla Twojego systemu operacyjnego;
- możesz zorganizować niezależne środowisko wirtualne do pracy. Ten projekt wymaga zainstalowania TensorFlow 2. Wszystkie pozostałe biblioteki zostaną wprowadzone później;
- jeśli chodzi o mnie, budowałem i trenowałem mój model YOLOv4 w środowisku programistycznym notebooków Jupyter. Chociaż Jupyter Notebook wydaje się rozsądną opcją, rozważ rozwój w wybranym przez siebie IDE, jeśli chcesz.
szkolenia modelarskie

teraz powinieneś mieć:
- podział dla Twojego zbioru danych;
- zainicjowano dwa generatory danych;
- plik txt z klasami.
inicjalizacja obiektu modelu
aby przygotować się do zadania szkoleniowego, zainicjuj obiekt modelu YOLOv4. Upewnij się, że jako wartości parametru weight_path użyto None. Na tym etapie należy również podać ścieżkę do pliku TXT klas. Oto kod inicjalizacyjny, którego użyłem w moim projekcie:
class_name_path = 'path2project_folder/model_data/scans_file.txt' model = Yolov4(weight_path=None, class_name_path=class_name_path)
powyższa inicjalizacja modelu prowadzi do wytworzenia obiektu modelu z domyślnym zestawem parametrów. Rozważ zmianę konfiguracji swojego modelu, przekazując słownik jako wartość do parametru Config model.

Konfiguracja określa zestaw parametrów dla modelu YOLOv4.
domyślna konfiguracja modelu jest dobrym punktem wyjścia, ale możesz poeksperymentować z innymi konfiguracjami dla lepszej jakości modelu.
w szczególności Gorąco polecam eksperymentowanie z kotwicami i img_size. Kotwy określają geometrię kotew, które będą używane do przechwytywania obiektów. Im lepsze kształty kotew pasują do kształtów obiektów, tym wyższa będzie wydajność modelu.
zwiększenie img_size może być również przydatne w niektórych przypadkach. Należy pamiętać, że im wyższy jest obraz, tym dłużej model będzie wyciągał wnioski.
w przypadku, gdy chcesz użyć Neptuna jako narzędzia śledzącego, powinieneś również zainicjować uruchomienie eksperymentu, w ten sposób:
import neptune.new as neptune run = neptune.init(project='projects/my_project', api_token=my_token)
Definiowanie wywołań zwrotnych
TensorFlow & keras pozwala nam używać zwrotów zwrotnych do monitorowania postępów w treningu, tworzenia punktów kontrolnych i zarządzania parametrami szkolenia (np.
przed dopasowaniem modelu określ wywołania zwrotne, które będą przydatne do Twoich celów. Pamiętaj, aby określić ścieżki do przechowywania punktów kontrolnych modelu i powiązanych dzienników. Oto jak to zrobiłem w jednym z moich projektów:
# defining pathes and callbacks dir4saving = 'path2checkpoint/checkpoints'os.makedirs(dir4saving, exist_ok = True) logdir = 'path4logdir/logs'os.makedirs(logdir, exist_ok = True) name4saving = 'epoch_{epoch:02d}-val_loss-{val_loss:.4f}.hdf5' filepath = os.path.join(dir4saving, name4saving) rLrCallBack = keras.callbacks.ReduceLROnPlateau(monitor = 'val_loss', factor = 0.1, patience = 5, verbose = 1) tbCallBack = keras.callbacks.TensorBoard(log_dir = logdir, histogram_freq = 0, write_graph = False, write_images = False) mcCallBack_loss = keras.callbacks.ModelCheckpoint(filepath, monitor = 'val_loss', verbose = 1, save_best_only = True, save_weights_only = False, mode = 'auto', period = 1)esCallBack = keras.callbacks.EarlyStopping(monitor = 'val_loss', mode = 'min', verbose = 1, patience = 10)
mogłeś zauważyć, że w powyższych wywołaniach zwrotnych zestaw tensorboard jest używany jako narzędzie śledzące. Rozważ użycie Neptuna jako znacznie bardziej zaawansowanego narzędzia do śledzenia eksperymentów. Jeśli tak, nie zapomnij zainicjować kolejnego wywołania zwrotnego, aby włączyć integrację z Neptune:
from neptune.new.integrations.tensorflow_keras import NeptuneCallback neptune_cbk = NeptuneCallback(run=run, base_namespace='metrics')
dopasowanie modelu
aby rozpocząć trening, wystarczy dopasować obiekt modelu za pomocą standardowej metody fit() w TensorFlow / Keras. Oto jak zacząłem trenować mój model:
model.fit(data_gen_train, initial_epoch=0, epochs=10000, val_data_gen=data_gen_val, callbacks= )
po rozpoczęciu szkolenia zobaczysz standardowy pasek postępu.

proces szkolenia oceni model pod koniec każdej epoki. Jeśli użyjesz zestawu wywołań zwrotnych podobnych do tych, które zainicjowałem i przekazałem podczas dopasowywania, te punkty kontrolne, które pokazują poprawę modelu pod względem mniejszej straty, zostaną zapisane do określonego katalogu.
jeśli nie wystąpią żadne błędy i proces szkolenia przebiegnie płynnie, zadanie szkoleniowe zostanie zatrzymane z powodu zakończenia liczby epok szkoleniowych lub jeśli wczesne zatrzymanie wywołania zwrotnego nie wykryje dalszej poprawy modelu i zatrzyma cały proces.
w każdym razie powinieneś skończyć z wieloma punktami kontrolnymi modelu. Chcemy wybrać najlepszy ze wszystkich dostępnych i wykorzystać go do wnioskowania.
wytrenowany model niestandardowy w trybie wnioskowania
uruchamianie wytrenowanego modelu w trybie wnioskowania jest podobne do uruchamiania wstępnie wytrenowanego modelu po wyjęciu z pudełka.

inicjalizujesz obiekt modelu przechodzący w ścieżce do najlepszego punktu kontrolnego, a także ścieżkę do pliku txt z klasami. Oto jak wygląda inicjalizacja modelu dla mojego projektu:
from models import Yolov4model = Yolov4(weight_path='path2checkpoint/checkpoints/epoch_48-val_loss-0.061.hdf5', class_name_path='path2classes_file/my_yolo_classes.txt')
gdy model jest inicjalizowany, po prostu użyj metody predict() dla wybranego obrazu, aby uzyskać prognozy. Podsumowując, detekcje wykonane przez model są zwracane w wygodnej formie ramki danych pandy. Otrzymujemy nazwę klasy, rozmiar pola i Współrzędne dla każdego wykrytego obiektu.
wnioski
właśnie nauczyłeś się tworzyć Niestandardowy detektor obiektów YOLOv4. Omówiliśmy cały proces, począwszy od zbierania danych, adnotacji i transformacji. Masz wystarczającą wiedzę na temat czwartej wersji YOLO i tego, jak różni się od innych detektorów.
nic nie powstrzymuje cię od szkolenia własnego modelu w TensorFlow i Keras. Wiesz, skąd wziąć wstępnie przeszkolony model i jak rozpocząć pracę szkoleniową.
w moim nadchodzącym artykule pokażę Ci niektóre z najlepszych praktyk i hacków życiowych, które pomogą poprawić jakość ostatecznego modelu. Zostań z nami!



Anton Morgunov
inżynier wizyjny w bazie./ Align = „Center” / 2,7688 Pasjonat wizji komputerowej. Bez papieru – więcej drzew! Praca w kierunku eliminacji kopii papierowych poprzez przejście do pełnej digitalizacji!
Czytaj dalej
TensorFlow object Detection API: najlepsze praktyki do szkolenia, ewaluacji & wdrażanie
13 minut Czytaj | autor Anton Morgunov | Zaktualizowano 28/05/2021
ten artykuł jest drugą częścią serii, w której poznasz kompleksowy przepływ pracy dla wykrywania obiektów TensorFlow i jego API. W pierwszym artykule nauczyłeś się tworzyć Niestandardowy detektor obiektów od podstaw, ale nadal istnieje wiele rzeczy, które wymagają twojej uwagi, aby stać się naprawdę biegłym.
przyjrzymy się tematom, które są równie ważne jak proces tworzenia modelu, który już przeszliśmy. Oto niektóre z pytań, na które odpowiemy:
- jak ocenić mój model i uzyskać szacunkową jego wydajność?
- jakie narzędzia mogę wykorzystać do śledzenia wydajności modelu i porównywania wyników w wielu eksperymentach?
- Jak mogę wyeksportować mój model, aby użyć go w trybie wnioskowania?
- czy można jeszcze bardziej zwiększyć wydajność modelu?
Czytaj dalej ->