
Fonte: Potenzia i tuoi modelli di visione artificiale con l’API TensorFlow Object Detection,
Jonathan Huang, ricercatore e Vivek Rathod, ingegnere del software,
Blog Google AI
- Rilevamento di oggetti come compito nella visione artificiale
- YOLO come rilevatore di oggetti in tempo reale
- Che cos’è YOLO?
- YOLO rispetto ad altri rivelatori
- Versioni di YOLO
- Esempi di applicazioni YOLO
- YOLO come rivelatore di oggetti in TensorFlow & Keras
- TensorFlow & Framework Keras nell’apprendimento automatico
- Implementazione YOLO in TensorFlow& Keras
- Come eseguire YOLO pre-addestrato e ottenere risultati
- Come addestrare il tuo modello di rilevamento oggetti YOLO personalizzato
- Dichiarazione di attività
- Dataset &annotazioni
- Dove ottenere i dati da
- Come annotare i dati per YOLO
- Come trasformare i dati da altri formati a YOLO
- Suddivisione dei dati in sottoinsiemi
- Creazione di generatori di dati
- Installazione & configurazione richiesta per la formazione del modello
- Modello di formazione
- Prerequisiti
- Inizializzazione dell’oggetto modello
- Definizione di callback
- Montaggio del modello
- Modello personalizzato addestrato in modalità inferenza
- Conclusioni
- Anton Morgunov
- TensorFlow Oggetto di Rilevazione API: le Migliori Pratiche per la Formazione, Valutazione & Distribuzione
Rilevamento di oggetti come compito nella visione artificiale
Incontriamo oggetti ogni giorno nella nostra vita. Guardati intorno e troverai più oggetti che ti circondano. Come essere umano puoi facilmente rilevare e identificare ogni oggetto che vedi. È naturale e non richiede molto sforzo.
Per i computer, tuttavia, il rilevamento di oggetti è un’attività che richiede una soluzione complessa. Per un computer “rilevare oggetti” significa elaborare un’immagine di input (o un singolo fotogramma da un video) e rispondere con informazioni sugli oggetti sull’immagine e sulla loro posizione. In termini di visione artificiale, chiamiamo questi due compiti classificazione e localizzazione. Vogliamo che il computer dica che tipo di oggetti sono presentati su una determinata immagine e dove si trovano esattamente.
Sono state sviluppate più soluzioni per aiutare i computer a rilevare gli oggetti. Oggi esploreremo un algoritmo all’avanguardia chiamato YOLO, che raggiunge un’elevata precisione a velocità in tempo reale. In particolare, impareremo come addestrare questo algoritmo su un set di dati personalizzato in TensorFlow / Keras.
Per prima cosa, vediamo cos’è esattamente YOLO e per cosa è famoso.
YOLO come rilevatore di oggetti in tempo reale
Che cos’è YOLO?
YOLO è l’acronimo di “You Only Look Once” (non confonderlo con You Only Live Once dei Simpson). Come suggerisce il nome, un singolo “look” è sufficiente per trovare tutti gli oggetti su un’immagine e identificarli.
In termini di apprendimento automatico, possiamo dire che tutti gli oggetti vengono rilevati tramite un singolo algoritmo eseguito. È fatto dividendo un’immagine in una griglia e prevedendo le caselle di delimitazione e le probabilità di classe per ogni cella in una griglia. Nel caso in cui vorremmo impiegare YOLO per il rilevamento dell’auto, ecco come potrebbero apparire la griglia e le caselle di delimitazione previste:

Il riquadro di delimitazione che YOLO prevede per la prima auto è in rosso.
Il riquadro di delimitazione che YOLO prevede per la seconda auto è giallo.
Fonte dell’immagine.
L’immagine sopra contiene solo il set finale di caselle ottenute dopo il filtraggio. Vale la pena notare che l’output raw di YOLO contiene molte caselle di delimitazione per lo stesso oggetto. Queste scatole differiscono per forma e dimensioni. Come puoi vedere nell’immagine qui sotto, alcune caselle sono migliori nel catturare l’oggetto di destinazione mentre altre offerte da un algoritmo funzionano male.

Tutte le scatole gialle sono per la seconda auto.
Il grassetto rosso e giallo scatole sono i migliori per auto di rilevamento.
Fonte dell’immagine.
Per selezionare il riquadro di delimitazione migliore per un determinato oggetto, viene applicato un algoritmo di soppressione non massima (NMS).

previste per le auto per mantenere solo quelle che catturano meglio gli oggetti.
Fonte dell’immagine.
Tutte le caselle che YOLO predice hanno un livello di confidenza associato a loro. NMS utilizza questi valori di confidenza per rimuovere le caselle che sono state previste con bassa certezza. Di solito, queste sono tutte le caselle che sono previste con sicurezza inferiore a 0,5.

Puoi vedere i punteggi di confidenza nell’angolo in alto a sinistra di ogni casella, accanto al nome dell’oggetto.
Fonte dell’immagine.
Quando tutte le caselle di delimitazione incerte vengono rimosse, rimangono solo le caselle con il livello di confidenza elevato. Per selezionare il migliore tra i candidati più performanti, NMS seleziona la casella con il più alto livello di confidenza e calcola come si interseca con le altre caselle intorno. Se un’intersezione è superiore a un determinato livello di soglia, il riquadro di delimitazione con confidenza inferiore viene rimosso. Nel caso in cui NMS confronti due caselle che hanno un’intersezione al di sotto di una soglia selezionata, entrambe le caselle vengono mantenute nelle previsioni finali.
YOLO rispetto ad altri rivelatori
Sebbene una rete neurale convoluzionale (CNN) sia utilizzata sotto il cofano di YOLO, è ancora in grado di rilevare oggetti con prestazioni in tempo reale. È possibile grazie alla capacità di YOLO di fare le previsioni contemporaneamente in un approccio a singolo stadio.
Altri algoritmi più lenti per il rilevamento di oggetti (come Più veloce R-CNN) utilizzano in genere un approccio a due stadi:
- nella prima fase vengono selezionate regioni di immagini interessanti. Queste sono le parti di un’immagine che potrebbero contenere oggetti;
- nella seconda fase, ciascuna di queste regioni viene classificata utilizzando una rete neurale convoluzionale.
Di solito, ci sono molte regioni su un’immagine con gli oggetti. Tutte queste regioni vengono inviate alla classificazione. La classificazione è un’operazione che richiede molto tempo, motivo per cui l’approccio di rilevamento di oggetti a due stadi è più lento rispetto al rilevamento a uno stadio.
YOLO non seleziona le parti interessanti di un’immagine, non ce n’è bisogno. Invece, predice i riquadri di delimitazione e le classi per l’intera immagine in un singolo passaggio netto in avanti.
Qui sotto puoi vedere quanto velocemente YOLO viene confrontato con altri rivelatori popolari.

SSD e YOLO sono rilevatori di oggetti a uno stadio mentre Faster-RCNN
e R-FCN sono rilevatori di oggetti a due stadi.
Fonte dell’immagine.
Versioni di YOLO
YOLO è stato introdotto per la prima volta nel 2015 da Joseph Redmon nel suo articolo di ricerca intitolato “You Only Look Once: Unified, Real-Time Object Detection”.
Da allora, YOLO si è evoluto molto. Nel 2016 Joseph Redmon descrisse la seconda versione di YOLO in “YOLO9000: Better, Faster, Stronger”.
Circa due anni dopo il secondo aggiornamento YOLO, Joseph si avvicinò con un altro aggiornamento netto. Il suo articolo, chiamato “YOLOv3: An Incremental Improvement”, attirò l’attenzione di molti ingegneri informatici e divenne popolare nella comunità di apprendimento automatico.
Nel 2020, Joseph Redmon ha deciso di interrompere la ricerca di computer vision, ma non ha impedito a YOLO di essere sviluppato da altri. Nello stesso anno, un team di tre ingegneri (Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao) progettò la quarta versione di YOLO, ancora più veloce e precisa di prima. Le loro scoperte sono descritte nel ” YOLOv4: Velocità ottimale e precisione del rilevamento degli oggetti ” documento pubblicato il 23 aprile 2020.
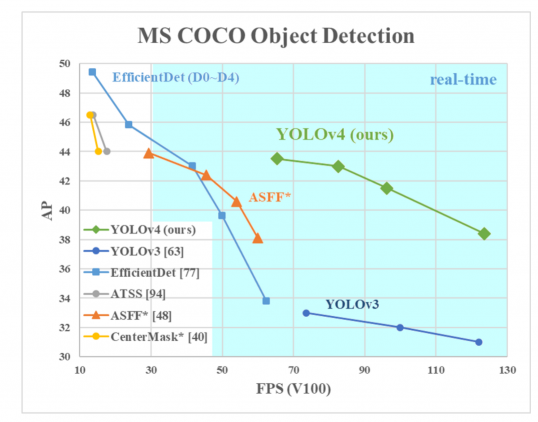
AP sull’asse Y è una metrica chiamata “precisione media”. Descrive l’accuratezza della rete.
FPS (fotogrammi al secondo) sull’asse X è una metrica che descrive la velocità.
Fonte dell’immagine.
Due mesi dopo il rilascio della 4a versione, uno sviluppatore indipendente, Glenn Jocher, ha annunciato la 5a versione di YOLO. Questa volta, non è stato pubblicato alcun documento di ricerca. La rete è diventata disponibile sulla pagina GitHub di Jocher come implementazione di PyTorch. La quinta versione aveva praticamente la stessa precisione della quarta versione, ma era più veloce.
Infine, a luglio 2020 abbiamo ottenuto un altro grande aggiornamento di YOLO. In un articolo intitolato “PP-YOLO: un’implementazione efficace ed efficiente del rilevatore di oggetti”, Xiang Long e il team hanno creato una nuova versione di YOLO. Questa iterazione di YOLO era basata sulla versione del modello 3rd e superava le prestazioni di YOLO v4.

La mappa sull’asse Y è una metrica chiamata “precisione media media”. Descrive l’accuratezza della rete.
FPS (fotogrammi al secondo) sull’asse X è una metrica che descrive la velocità.
Fonte dell’immagine.
In questo tutorial, stiamo andando ad avere uno sguardo più da vicino a YOLOv4 e la sua implementazione. Perché YOLOv4? Tre ragioni:
- Ha un’ampia approvazione nella comunità di apprendimento automatico;
- Questa versione ha dimostrato le sue elevate prestazioni in una vasta gamma di attività di rilevamento;
- YOLOv4 è stato implementato in più framework popolari, tra cui TensorFlow e Keras, con cui lavoreremo.
Esempi di applicazioni YOLO
Prima di passare alla parte pratica di questo articolo, implementando il nostro rilevatore di oggetti personalizzato basato su YOLO, mi piacerebbe mostrarvi un paio di fantastiche implementazioni YOLOv4, e poi faremo la nostra implementazione.
Presta attenzione alla velocità e precisione delle previsioni!
Ecco il primo esempio impressionante di ciò che YOLOv4 può fare, rilevando più oggetti da diverse scene di gioco e film.
In alternativa, è possibile controllare questa demo di rilevamento oggetti da una vista della telecamera reale.
YOLO come rivelatore di oggetti in TensorFlow & Keras
TensorFlow & Framework Keras nell’apprendimento automatico

Fonte dell’immagine.
I framework sono essenziali in ogni dominio della tecnologia dell’informazione. L’apprendimento automatico non fa eccezione. Ci sono diversi attori affermati nel mercato ML che ci aiutano a semplificare l’esperienza complessiva di programmazione. PyTorch, scikit-learn, TensorFlow, Keras, MXNet e Caffe sono solo alcuni degni di nota.
Oggi lavoreremo a stretto contatto con TensorFlow / Keras. Non sorprende che questi due siano tra i framework più popolari nell’universo dell’apprendimento automatico. È in gran parte dovuto al fatto che sia TensorFlow che Keras forniscono funzionalità avanzate per lo sviluppo. Questi due framework sono abbastanza simili tra loro. Senza scavare troppo nei dettagli, la cosa fondamentale da ricordare è che Keras è solo un wrapper per il framework TensorFlow.
Implementazione YOLO in TensorFlow& Keras
Al momento della stesura di questo articolo, c’erano 808 repository con implementazioni YOLO su un backend TensorFlow / Keras. YOLO versione 4 è quello che stiamo per implementare. Limitando la ricerca solo a YOLO v4, ho ottenuto 55 repository.
Navigando attentamente tutti, ho trovato un candidato interessante con cui continuare.
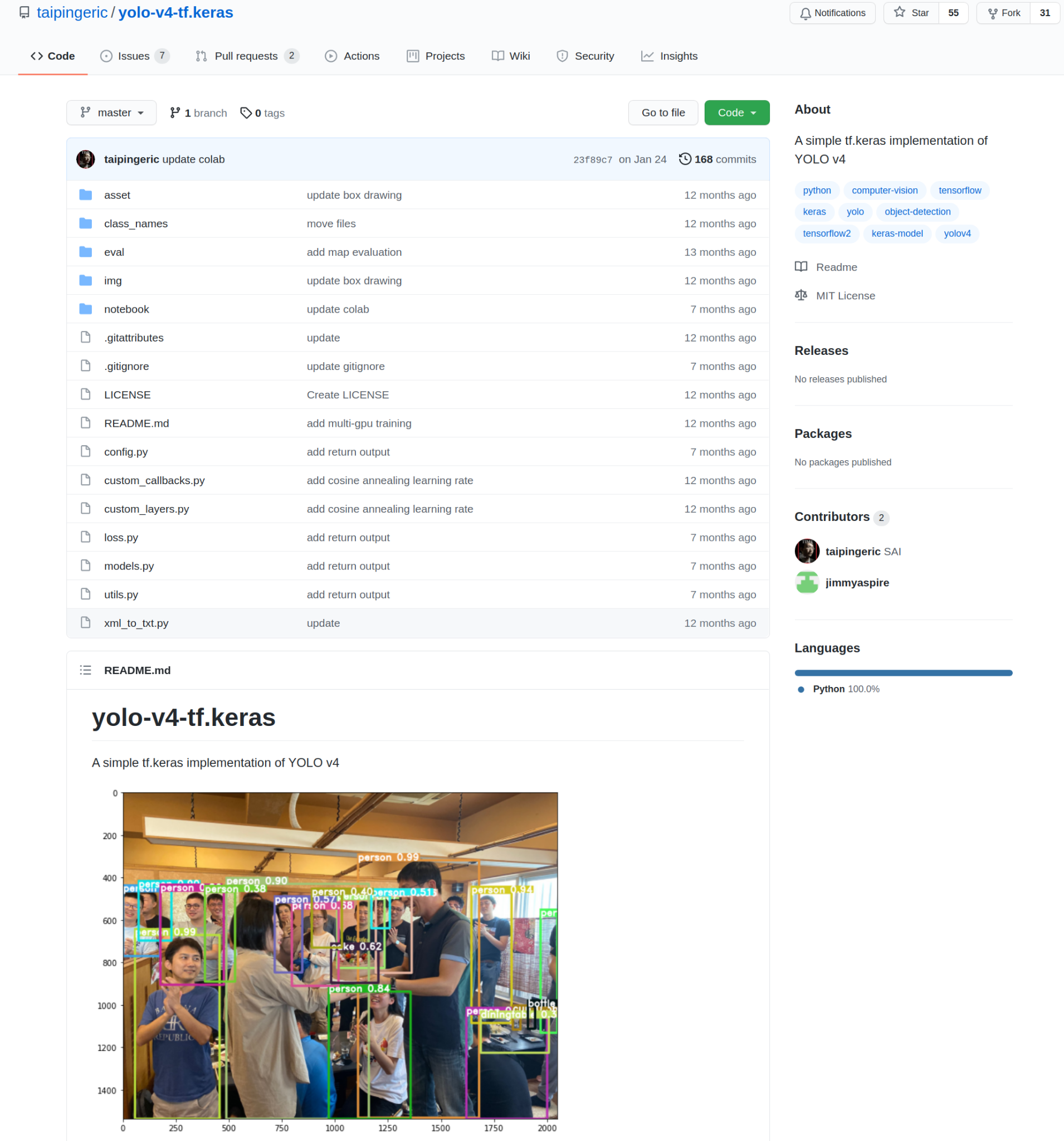
Fonte dell’immagine.
Questa implementazione è stata sviluppata da taipingeric e jimmyaspire. È abbastanza semplice e molto intuitivo se hai già lavorato con TensorFlow e Keras.
Per iniziare a lavorare con questa implementazione, basta clonare il repository sul computer locale. Successivamente, ti mostrerò come usare YOLO fuori dalla scatola e come addestrare il tuo rilevatore di oggetti personalizzato.
Come eseguire YOLO pre-addestrato e ottenere risultati
Guardando la sezione “Avvio rapido” del repository, puoi vedere che per ottenere un modello attivo e funzionante, dobbiamo solo importare YOLO come oggetto di classe e caricare i pesi del modello:
from models import Yolov4model = Yolov4(weight_path='yolov4.weights', class_name_path='class_names/coco_classes.txt')
Si noti che è necessario scaricare manualmente i pesi del modello in anticipo. Il file dei pesi del modello fornito con YOLO proviene dal set di dati COCO ed è disponibile nella pagina ufficiale del progetto darknet di AlexeyAB su GitHub. È possibile scaricare i pesi direttamente tramite questo link.
Subito dopo, il modello è completamente pronto per lavorare con le immagini in modalità inferenza. Basta usare il metodo predict () per un’immagine di tua scelta. Il metodo è standard per i framework TensorFlow e Keras.
pred = model.predict('input.jpg')
Ad esempio per questa immagine di input:

Ho ottenuto il seguente modello di output:

Le previsioni che il modello creato vengono restituite in una forma conveniente di un DataFrame pandas. Otteniamo il nome della classe, la dimensione della scatola e le coordinate per ogni oggetto rilevato:

Un sacco di informazioni utili sugli oggetti rilevati
Ci sono più parametri all’interno del metodo predict() che ci permettono di specificare se vogliamo tracciare l’immagine con i riquadri di delimitazione previsti, i nomi testuali per ogni oggetto, ecc. Controlla la docstring che accompagna il metodo predict () per familiarizzare con ciò che è disponibile per noi:

Dovresti aspettarti che il tuo modello sia in grado di rilevare solo i tipi di oggetto che sono strettamente limitati al set di dati COCO. Per sapere quali tipi di oggetto è in grado di rilevare un modello YOLO pre-addestrato, controlla coco_classes.file txt disponibile in … / yolo-v4-tf.kers / class_names/. Ci sono 80 tipi di oggetti.
Come addestrare il tuo modello di rilevamento oggetti YOLO personalizzato
Dichiarazione di attività

Per progettare un modello di rilevamento oggetti, è necessario sapere quali tipi di oggetti si desidera rilevare. Questo dovrebbe essere un numero limitato di tipi di oggetti per cui si desidera creare il rilevatore. È bene avere un elenco di tipi di oggetti preparati mentre passiamo allo sviluppo del modello effettivo.
Idealmente, dovresti anche avere un set di dati annotato con oggetti di tuo interesse. Questo set di dati verrà utilizzato per addestrare un rivelatore e convalidarlo. Se non hai ancora un set di dati o un’annotazione per questo, non preoccuparti, ti mostrerò dove e come puoi ottenerlo.
Dataset &annotazioni
Dove ottenere i dati da
Se si dispone di un dataset annotato con cui lavorare, basta saltare questa parte e passare al capitolo successivo. Ma, se hai bisogno di un set di dati per il tuo progetto, ora esploreremo le risorse online in cui puoi ottenere dati.
Non importa in quale campo stai lavorando, c’è una grande possibilità che ci sia già un set di dati open source che puoi usare per il tuo progetto.
La prima risorsa che raccomando è l’articolo “50 + Set di dati di rilevamento di oggetti provenienti da diversi domini del settore” di Abhishek Annamraju che ha raccolto meravigliosi set di dati annotati per settori come la moda, la vendita al dettaglio, lo sport, la medicina e molti altri.

Fonte dell’immagine.
Altri due ottimi posti per cercare i dati sono paperswithcode.com e roboflow.com che forniscono l’accesso a set di dati di alta qualità per il rilevamento di oggetti.
Controlla queste risorse di cui sopra per raccogliere i dati necessari o per arricchire il set di dati che hai già.
Come annotare i dati per YOLO
Se il set di dati di immagini viene fornito senza annotazioni, è necessario eseguire il lavoro di annotazione da soli. Questa operazione manuale richiede molto tempo, quindi assicurati di avere abbastanza tempo per farlo.
Come strumento di annotazione potresti considerare più opzioni. Personalmente, consiglierei di usare LabelImg. È uno strumento di annotazione delle immagini leggero e facile da usare che può emettere direttamente annotazioni per i modelli YOLO.
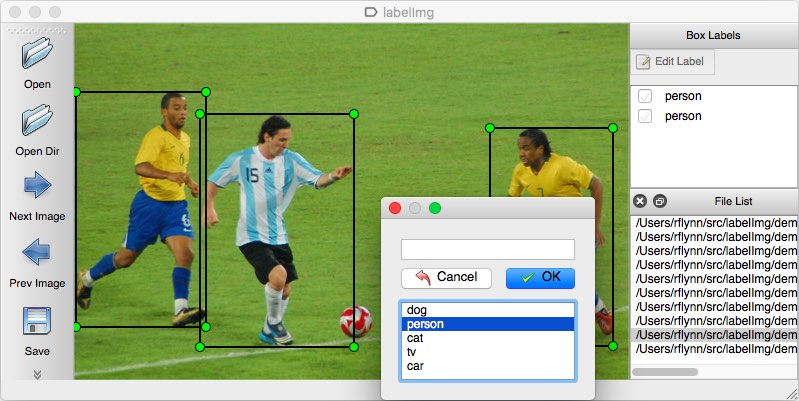
Fonte dell’immagine.
Come trasformare i dati da altri formati a YOLO
Le annotazioni per YOLO sono sotto forma di file txt. Ogni riga in un file txt fol YOLO deve avere il seguente formato:
image1.jpg 10,15,345,284,0image2.jpg 100,94,613,814,0 31,420,220,540,1
Possiamo suddividere ogni riga dal file txt e vedere in cosa consiste:
- La prima parte di una riga specifica i nomi di base per le immagini: image1.jpg, immagine2.jpg
- La seconda parte di una riga definisce le coordinate del riquadro di delimitazione e l’etichetta della classe. Ad esempio, 10,15,345,284,0 stati per xmin, ymin, xmax, ymax, class_id
- Se una determinata immagine ha più di un oggetto su di essa, ci saranno più caselle ed etichette di classe accanto al nome base dell’immagine, divise da uno spazio.
Le coordinate del riquadro di delimitazione sono un concetto chiaro, ma per quanto riguarda il numero class_id che specifica l’etichetta della classe? Ogni class_id è collegato con una particolare classe in un altro file txt. Ad esempio, YOLO pre-addestrato viene fornito con coco_classes.file txt che assomiglia a questo:
personbicyclecarmotorbikeaeroplanebus...
Il numero di righe nei file delle classi deve corrispondere al numero di classi che il rilevatore rileverà. La numerazione inizia da zero, il che significa che il numero class_id per la prima classe nel file classes sarà 0. Classe che si trova sulla seconda riga nel file classi txt avrà il numero 1.
Ora sai come appare l’annotazione per YOLO. Per continuare a creare un rilevatore di oggetti personalizzato ti esorto a fare due cose ora:
- creare un file txt classi in cui si palazzo delle classi che si desidera che il rilevatore di rilevare. Ricorda che l’ordine di classe è importante.
- Creare un file txt con annotazioni. Nel caso in cui tu abbia già annotazione ma nel formato VOC (.XMLs), è possibile utilizzare questo file per trasformare da XML a YOLO.
Suddivisione dei dati in sottoinsiemi
Come sempre, vogliamo dividere il set di dati in 2 sottoinsiemi: per la formazione e per la convalida. Può essere fatto semplice come:
from utils import read_annotation_lines train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1)
Creazione di generatori di dati
Quando i dati vengono divisi, possiamo procedere all’inizializzazione del generatore di dati. Avremo un generatore di dati per ogni file di dati. Nel nostro caso, avremo un generatore per il sottoinsieme di addestramento e per il sottoinsieme di convalida.
Ecco come vengono creati i generatori di dati:
from utils import DataGenerator FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
Per riassumere tutto, ecco come appare il codice completo per la suddivisione dei dati e la creazione del generatore:
from utils import read_annotation_lines, DataGenerator train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1) FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
Installazione & configurazione richiesta per la formazione del modello
Parliamo dei prerequisiti essenziali per creare il proprio rilevatore di oggetti:
- Dovresti avere Python già installato sul tuo computer. Nel caso in cui sia necessario installarlo, ti consiglio di seguire questa guida ufficiale di Anaconda;
- Se il computer dispone di una GPU abilitata a CUDA (una GPU prodotta da NVIDIA), sono necessarie alcune librerie rilevanti per supportare la formazione basata su GPU. Nel caso in cui sia necessario abilitare il supporto GPU, controllare le linee guida sul sito Web di NVIDIA. Il tuo obiettivo è installare l’ultima versione di CUDA Toolkit e cuDNN per il tuo sistema operativo;
- Potresti voler organizzare un ambiente virtuale indipendente in cui lavorare. Questo progetto richiede TensorFlow 2 installato. Tutte le altre librerie saranno introdotte in seguito;
- Per quanto mi riguarda, stavo costruendo e addestrando il mio modello YOLOv4 in un ambiente di sviluppo di notebook Jupyter. Sebbene Jupyter Notebook sembri un’opzione ragionevole, considera lo sviluppo in un IDE di tua scelta se lo desideri.
Modello di formazione

Prerequisiti
Da ora si dovrebbe avere:
- Una divisione per il set di dati;
- Due generatori inizializzato;
- Un file txt con le classi.
Inizializzazione dell’oggetto modello
Per prepararsi a un lavoro di formazione, inizializzare l’oggetto modello YOLOv4. Assicurarsi di utilizzare None come valore per il parametro weight_path. Dovresti anche fornire un percorso al file txt delle classi in questo passaggio. Ecco il codice di inizializzazione che ho usato nel mio progetto:
class_name_path = 'path2project_folder/model_data/scans_file.txt' model = Yolov4(weight_path=None, class_name_path=class_name_path)
L’inizializzazione del modello di cui sopra porta alla creazione di un oggetto modello con un set predefinito di parametri. Considerare di modificare la configurazione del modello passando un dizionario come valore al parametro config model.

Config specifica un insieme di parametri per il modello YOLOv4.
La configurazione del modello predefinito è un buon punto di partenza, ma potresti voler sperimentare altre configurazioni per una migliore qualità del modello.
In particolare, consiglio vivamente di sperimentare ancore e img_size. Le ancore specificano la geometria delle ancore che verranno utilizzate per catturare gli oggetti. Meglio le forme delle ancore si adattano alle forme degli oggetti, maggiore sarà la prestazione del modello.
Aumentare img_size potrebbe essere utile anche in alcuni casi. Tieni presente che più alta è l’immagine, più a lungo il modello farà l’inferenza.
Nel caso in cui desideri utilizzare Neptune come strumento di tracciamento, dovresti anche inizializzare un’esecuzione dell’esperimento, in questo modo:
import neptune.new as neptune run = neptune.init(project='projects/my_project', api_token=my_token)
Definizione di callback
TensorFlow & Keras usiamo callback per monitorare i progressi della formazione, fare checkpoint, e gestire i parametri di formazione (ad esempio tasso di apprendimento).
Prima di adattare il modello, definisci i callback che saranno utili per i tuoi scopi. Assicurati di specificare i percorsi per memorizzare i checkpoint del modello e i log associati. Ecco come l’ho fatto in uno dei miei progetti:
# defining pathes and callbacks dir4saving = 'path2checkpoint/checkpoints'os.makedirs(dir4saving, exist_ok = True) logdir = 'path4logdir/logs'os.makedirs(logdir, exist_ok = True) name4saving = 'epoch_{epoch:02d}-val_loss-{val_loss:.4f}.hdf5' filepath = os.path.join(dir4saving, name4saving) rLrCallBack = keras.callbacks.ReduceLROnPlateau(monitor = 'val_loss', factor = 0.1, patience = 5, verbose = 1) tbCallBack = keras.callbacks.TensorBoard(log_dir = logdir, histogram_freq = 0, write_graph = False, write_images = False) mcCallBack_loss = keras.callbacks.ModelCheckpoint(filepath, monitor = 'val_loss', verbose = 1, save_best_only = True, save_weights_only = False, mode = 'auto', period = 1)esCallBack = keras.callbacks.EarlyStopping(monitor = 'val_loss', mode = 'min', verbose = 1, patience = 10)
Potresti aver notato che nei callback precedenti set TensorBoard viene utilizzato come strumento di tracciamento. Considerare l’utilizzo di Nettuno come uno strumento molto più avanzato per il monitoraggio degli esperimenti. In tal caso, non dimenticare di inizializzare un altro callback per abilitare l’integrazione con Neptune:
from neptune.new.integrations.tensorflow_keras import NeptuneCallback neptune_cbk = NeptuneCallback(run=run, base_namespace='metrics')
Montaggio del modello
Per avviare il lavoro di formazione, è sufficiente adattare l’oggetto modello utilizzando il metodo standard fit() in TensorFlow / Keras. Ecco come ho iniziato ad allenare il mio modello:
model.fit(data_gen_train, initial_epoch=0, epochs=10000, val_data_gen=data_gen_val, callbacks= )
Quando viene avviato l’allenamento, verrà visualizzata una barra di avanzamento standard.

Il processo di formazione valuterà il modello alla fine di ogni epoca. Se si utilizza un set di callback simili a quelli che ho inizializzato e passato durante il fitting, i checkpoint che mostrano il miglioramento del modello in termini di perdita inferiore verranno salvati in una directory specificata.
Se non si verificano errori e il processo di formazione procede senza intoppi, il processo di formazione verrà interrotto a causa della fine del numero delle epoche di formazione o se il callback di arresto anticipato non rileva ulteriori miglioramenti del modello e interrompe il processo complessivo.
In ogni caso, si dovrebbe finire con più punti di controllo del modello. Vogliamo selezionare il migliore tra tutti quelli disponibili e usarlo per l’inferenza.
Modello personalizzato addestrato in modalità inferenza
L’esecuzione di un modello addestrato in modalità inferenza è simile all’esecuzione di un modello pre-addestrato.

Si inizializza un oggetto modello passando il percorso al checkpoint migliore e il percorso del file txt con le classi. Ecco come appare l’inizializzazione del modello per il mio progetto:
from models import Yolov4model = Yolov4(weight_path='path2checkpoint/checkpoints/epoch_48-val_loss-0.061.hdf5', class_name_path='path2classes_file/my_yolo_classes.txt')
Quando il modello viene inizializzato, è sufficiente utilizzare il metodo predict() per un’immagine di vostra scelta per ottenere le previsioni. Come riepilogo, i rilevamenti effettuati dal modello vengono restituiti in una comoda forma di DataFrame pandas. Otteniamo il nome della classe, la dimensione della casella e le coordinate per ogni oggetto rilevato.
Conclusioni
Hai appena imparato come creare un rilevatore di oggetti YOLOv4 personalizzato. Abbiamo esaminato il processo end-to-end, partendo dalla raccolta dei dati, dall’annotazione e dalla trasformazione. Hai abbastanza conoscenze sulla quarta versione di YOLO e su come si differenzia dagli altri rivelatori.
Nulla ti impedisce ora di addestrare il tuo modello in TensorFlow e Keras. Sai dove trovare un modello pre-addestrato da e come dare il via al lavoro di formazione.
Nel mio prossimo articolo, vi mostrerò alcune delle migliori pratiche e hack vita che contribuirà a migliorare la qualità del modello finale. Resta con noi!



Anton Morgunov
Ingegnere informatico presso Basis.Centro
Appassionato di apprendimento automatico. Appassionato di computer vision. Niente carta-più alberi! Lavorare per l’eliminazione della copia cartacea passando alla completa digitalizzazione!
continua a LEGGERE
TensorFlow Oggetto di Rilevazione API: le Migliori Pratiche per la Formazione, Valutazione & Distribuzione
13 minuti di lettura | Autore Anton Morgunov | Aggiornato: Maggio 28, 2021
Questo articolo è la seconda parte di una serie in cui si impara un flusso di lavoro per TensorFlow Oggetto di Rilevazione e le sue API. Nel primo articolo, hai imparato come creare un rilevatore di oggetti personalizzato da zero, ma ci sono ancora molte cose che richiedono la tua attenzione per diventare veramente abili.
Esploreremo argomenti importanti quanto il processo di creazione del modello che abbiamo già attraversato. Ecco alcune delle domande a cui risponderemo:
- Come valutare il mio modello e ottenere una stima delle sue prestazioni?
- Quali sono gli strumenti che posso utilizzare per monitorare le prestazioni del modello e confrontare i risultati in più esperimenti?
- Come posso esportare il mio modello per utilizzarlo in modalità inferenza?
- C’è un modo per aumentare ancora di più le prestazioni del modello?
Continua a leggere ->