Crawl budget è il numero di pagine che i motori di ricerca eseguiranno la scansione su un sito web entro un certo periodo di tempo.
I motori di ricerca calcolano il budget di scansione in base al limite di scansione (con quale frequenza possono eseguire la scansione senza causare problemi) e alla domanda di scansione (con quale frequenza vorrebbero eseguire la scansione di un sito).
Se stai sprecando il budget di scansione, i motori di ricerca non saranno in grado di eseguire la scansione del tuo sito Web in modo efficiente, il che finirebbe per danneggiare le tue prestazioni SEO.
- Che cosa è crawl budget?
- Perché i motori di ricerca assegnano il budget di scansione ai siti web?
- Come assegnano il budget di scansione ai siti web?
- Il crawl budget riguarda solo le pagine?
- Come funziona il limite di scansione / carico host nella pratica?
- Come funziona la pianificazione della richiesta di scansione / scansione nella pratica?
- Non dimenticare: capacità di scansione del sistema stesso
- Perché dovresti preoccuparti del budget di scansione?
- Qual è il budget di scansione per il mio sito web?
- Esegui la scansione del budget in Google Search Console
- Vai alla fonte: log del server
- Come ottimizzi il tuo budget di scansione?
- Accessibile Url con parametri
- Contenuti duplicati
- Contenuti di bassa qualità
- Collegamenti interrotti e reindirizzamenti
- URL errati nelle sitemap XML
- ContentKing
- Pagine con tempi di caricamento elevati / timeout
- Numero elevato di pagine non indicizzabili
- Bad struttura interna di collegamento
- Come aumentare il budget di scansione del tuo sito web?
- Domande frequenti su crawl budget
- 1. 🧾 Che cosa è crawl budget?
- 2. 🤔 Come posso aumentare il mio budget di scansione?
- 3. 🤷 Cosa può limitare il mio budget di scansione?
- 4. Should Dovrei usare URL canonici e meta robot?
Che cosa è crawl budget?
Crawl budget è il numero di pagine che i motori di ricerca eseguiranno su un sito Web entro un determinato periodo di tempo.
Perché i motori di ricerca assegnano il budget di scansione ai siti web?
Perché non hanno risorse illimitate e dividono la loro attenzione su milioni di siti web. Quindi hanno bisogno di un modo per dare la priorità al loro sforzo strisciante. Assegnare il budget di scansione a ciascun sito Web li aiuta a farlo.
Come assegnano il budget di scansione ai siti web?
Questo si basa su due fattori, crawl limit e crawl demand:
- Crawl limit / host load: quanto crawling può gestire un sito web e quali sono le preferenze del suo proprietario?
- Crawl demand / crawl scheduling: quali URL valgono (ri)la scansione più, in base alla sua popolarità e alla frequenza con cui viene aggiornato.
Crawl budget è un termine comune all’interno di SEO. Crawl budget è a volte indicato anche come crawl space o crawl time.

Il crawl budget riguarda solo le pagine?
In realtà non lo è, per facilità stiamo parlando di pagine, ma in realtà si tratta di qualsiasi documento che i motori di ricerca strisciano. Alcuni esempi di altri documenti: file JavaScript e CSS, varianti di pagina mobile, varianti hreflang e file PDF.
Come funziona il limite di scansione / carico host nella pratica?
Il limite di scansione, o il carico dell’host, se lo si desidera, è una parte importante del budget di scansione. I crawler dei motori di ricerca sono progettati per evitare di sovraccaricare un server Web con richieste, quindi sono attenti a questo.In che modo i motori di ricerca determinano il limite di scansione di un sito web? Ci sono una varietà di fattori che influenzano il limite di scansione. Per citarne alcuni:
- Segni di piattaforma in cattive condizioni: con quale frequenza timeout degli URL richiesti o errori del server di ritorno.
- La quantità di siti Web in esecuzione sull’host: se il tuo sito Web è in esecuzione su una piattaforma di hosting condiviso con centinaia di altri siti Web e hai un sito Web abbastanza grande, il limite di scansione per il tuo sito Web è molto limitato poiché il limite di scansione è determinato a livello di host. Devi condividere il limite di scansione dell’host con tutti gli altri siti in esecuzione su di esso. In questo caso saresti molto meglio su un server dedicato, che molto probabilmente ridurrà anche i tempi di caricamento per i tuoi visitatori.
Un’altra cosa da considerare è avere siti mobili e desktop separati in esecuzione sullo stesso host. Hanno anche un limite di scansione condiviso. Quindi tienilo a mente.
I motori di ricerca stanno strisciando le parti più importanti del tuo sito web? Eseguire un test rapido con ContentKing!
Come funziona la pianificazione della richiesta di scansione / scansione nella pratica?
La richiesta di scansione, o pianificazione di scansione, riguarda la determinazione del valore degli URL di nuova scansione. Ancora una volta, molti fattori influenzano la domanda di scansione tra cui:
- Popolarità: quanti link interni e esterni in entrata ha un URL, ma anche la quantità di query per cui è classificato.
- Freschezza: con quale frequenza viene aggiornato l’URL.
- Tipo di pagina: è il tipo di pagina che potrebbe cambiare. Prendi ad esempio una pagina di categoria di prodotto e una pagina di termini e condizioni – quale pensi che cambi più spesso e meriti di essere scansionato più frequentemente?

Costringendo i crawler di Google a tornare al tuo sito quando non c’è nulla di più importante per trovare (cioè cambiamento significativo) non è una buona strategia e sono abbastanza intelligente nel capire se la frequenza di queste pagine cambiare realmente un valore aggiunto. Il miglior consiglio che potrei dare è di concentrarmi sul rendere le pagine più importanti (aggiungendo più informazioni utili, rendendo ricchi i contenuti delle pagine (attiveranno naturalmente più query per impostazione predefinita finché viene mantenuto il focus di un argomento). Attivando naturalmente più query come parte del “richiamo” (impressioni) rendi le tue pagine più importanti ed ecco: probabilmente verrai strisciato più frequentemente.
Non dimenticare: capacità di scansione del sistema stesso
Mentre i sistemi di scansione dei motori di ricerca hanno una capacità di scansione massiccia, alla fine della giornata è limitata. Quindi, in uno scenario in cui l’ 80% dei data center di Google va offline allo stesso tempo, la loro capacità di scansione diminuisce in modo massiccio e, a sua volta, il budget di scansione di tutti i siti Web.
Massive grazie a Dawn Anderson (si apre in una nuova scheda) per averci fornito dettagli su crawl limit, crawl demand e crawl capacity!
Perché dovresti preoccuparti del budget di scansione?
Vuoi che i motori di ricerca trovino e comprendano il maggior numero possibile di pagine indicizzabili e vuoi che lo facciano il più rapidamente possibile. Quando aggiungi nuove pagine e aggiorni quelle esistenti, vuoi che i motori di ricerca le raccolgano il prima possibile. Prima hanno indicizzato le pagine, prima si può beneficiare di loro.
Se stai sprecando crawl budget, i motori di ricerca non saranno in grado di eseguire la scansione del tuo sito web in modo efficiente. Trascorreranno del tempo su parti del tuo sito che non contano, il che può comportare che parti importanti del tuo sito Web vengano lasciate da scoprire. Se non conoscono le pagine, non le indicizzeranno e non saranno in grado di portare i visitatori attraverso i motori di ricerca.
Si può vedere dove questo sta portando a: sprecare crawl budget fa male le prestazioni SEO.
Si prega di notare che crawl budget è generalmente solo qualcosa di cui preoccuparsi se hai un grande sito web, diciamo 10.000 pagine e oltre.

Uno degli aspetti più sottovalutati del budget di scansione è la velocità di caricamento. Un sito Web di caricamento più veloce significa che Google può eseguire la scansione di più URL nello stesso lasso di tempo. Recentemente sono stato coinvolto in un aggiornamento del sito in cui la velocità di carico era un obiettivo importante. Il nuovo sito caricato due volte più veloce di quello vecchio. Quando è stato spinto in diretta, il numero di URL di Google strisciato al giorno è salito da 150.000 a 600.000-e rimase lì. Per un sito di queste dimensioni e portata, il tasso di scansione migliorato significa che i contenuti nuovi e modificati vengono scansionati molto più velocemente e vediamo un impatto molto più rapido dei nostri sforzi SEO nelle SERP.

molto saggio SEO (ok, era AJ Kohn (si apre in una nuova scheda)) una volta ha detto “Tu sei quello che Googlebot mangia.”. Le tue classifiche e la visibilità della ricerca sono direttamente correlate non solo a ciò che Google esegue la scansione sul tuo sito, ma spesso, con quale frequenza lo esegue. Se Google manca il contenuto sul tuo sito, o non esegue la scansione di URL importanti abbastanza frequentemente a causa del budget di scansione limitato/non ottimizzato, allora avrai davvero un tempo molto difficile. Per i siti più grandi, l’ottimizzazione del budget di scansione può aumentare notevolmente il profilo delle pagine precedentemente invisibili. Mentre il sito più piccolo deve preoccuparsi meno del budget di scansione, gli stessi principi di ottimizzazione (velocità, priorità, struttura dei collegamenti, de-duplicazione, ecc.) può ancora aiutare a rango.

io per lo più d’accordo con Google e per la maggior parte molti i siti web non devono preoccuparsi di ricerca per indicizzazione di bilancio. Ma per i siti web che sono di grandi dimensioni e soprattutto quelli che vengono aggiornati frequentemente come gli editori, l’ottimizzazione può fare una differenza significativa.
Qual è il budget di scansione per il mio sito web?
Di tutti i motori di ricerca, Google è il più trasparente sul loro budget di scansione per il tuo sito web.
Esegui la scansione del budget in Google Search Console
Se hai verificato il tuo sito Web in Google Search Console, puoi ottenere informazioni sul budget di scansione del tuo sito web per Google.
Segui questi passaggi:
- Accedi a Google Search Console e scegli un sito web.
- Vai a
Crawl>Crawl Stats. Qui puoi vedere il numero di pagine che Google esegue la scansione al giorno.
Durante l’estate del 2016, il nostro budget di scansione era simile a questo:
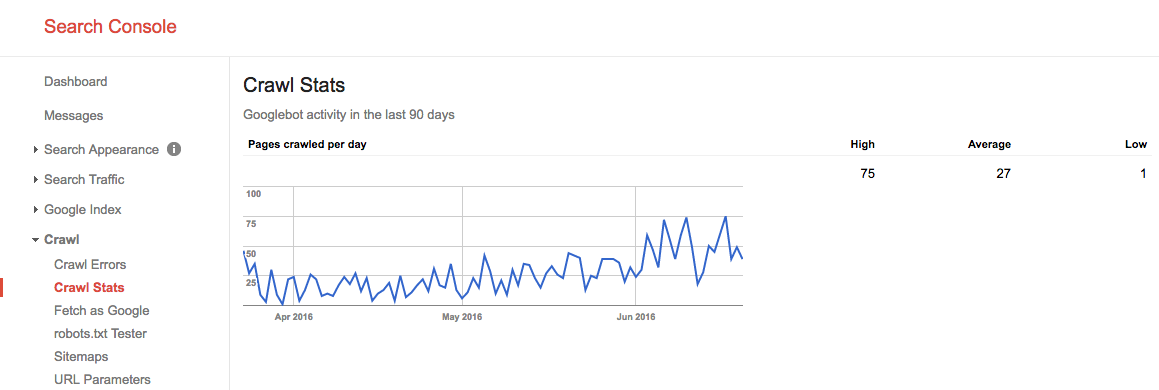
Vediamo qui che il budget medio di scansione è di 27 pagine / giorno. Quindi, in teoria, se questo budget medio di scansione rimane lo stesso, avresti un budget mensile di scansione di 27 pagine x 30 giorni = 810 pagine.
Avanti veloce di 2 anni e guarda qual è il nostro budget di scansione in questo momento:
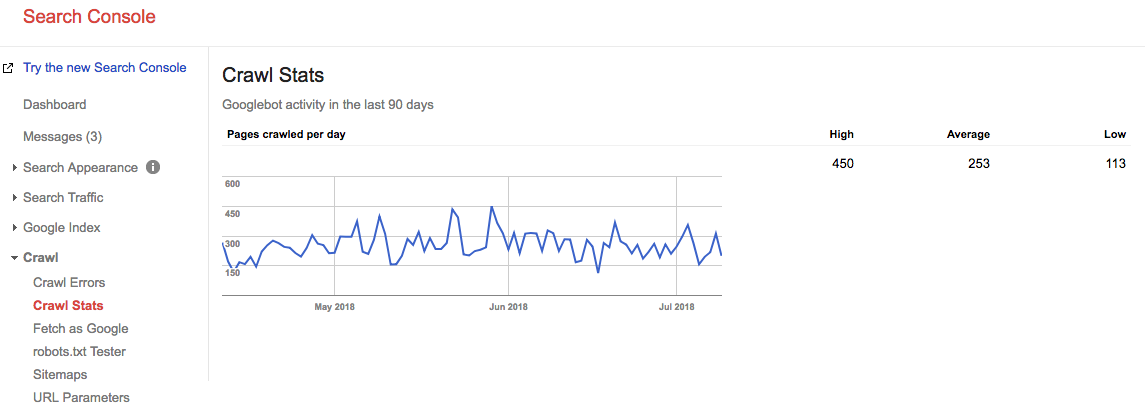
Il nostro budget medio di scansione medio è di 253 pagine / giorno, quindi potresti dire che il nostro budget di scansione è aumentato di 10 volte in 2 anni.
Vai alla fonte: log del server
È molto interessante controllare i log del server per vedere quanto spesso i crawler di Google colpiscono il tuo sito web. È interessante confrontare queste statistiche con quelle riportate in Google Search Console. È sempre meglio fare affidamento su più fonti.
Non lasciare che i problemi di scansione siano un’occasione persa. Monitorare continuamente il tuo sito con ContentKing ed essere avvisati dei problemi in tempo reale.
Come ottimizzi il tuo budget di scansione?
Ottimizzare il tuo budget di scansione si riduce a fare in modo che nessun budget di scansione venga sprecato. Essenzialmente, fissando le ragioni per il budget di scansione sprecato. Monitoriamo migliaia di siti web; se dovessi controllare ognuno di essi per problemi di budget di scansione, vedrai rapidamente uno schema: la maggior parte dei siti Web soffre dello stesso tipo di problemi.
Motivi comuni per il budget di scansione sprecato che incontriamo:
- URL accessibili con parametri: un esempio di URL con un parametro è
https://www.example.com/toys/cars?color=black. In questo caso, il parametro viene utilizzato per memorizzare la selezione di un visitatore in un filtro prodotto. - Contenuti duplicati: chiamiamo le pagine che sono molto simili, o esattamente le stesse, ” contenuti duplicati.”Esempi sono: pagine copiate, pagine interne dei risultati di ricerca e pagine di tag.
- Contenuto di bassa qualità: pagine con contenuti molto piccoli o pagine che non aggiungono alcun valore.
- Collegamenti interrotti e reindirizzamenti: i collegamenti interrotti sono collegamenti che fanno riferimento a pagine che non esistono più e i collegamenti reindirizzati sono collegamenti a URL che reindirizzano ad altri URL.
- Inclusi gli URL errati nelle sitemap XML: le pagine non indicizzabili e le non pagine come gli URL 3xx, 4xx e 5xx non dovrebbero essere incluse nella sitemap XML.
- Pagine con elevato tempo di caricamento / time-out: le pagine che richiedono molto tempo per essere caricate, o non caricate affatto, hanno un impatto negativo sul budget di scansione, perché è un segno per i motori di ricerca che il tuo sito Web non è in grado di gestire la richiesta e quindi potrebbero modificare il limite di scansione.
- Numero elevato di pagine non indicizzabili: il sito web contiene molte pagine che non sono indicizzabili.
- Struttura di collegamento interna errata: se la struttura di collegamento interna non è impostata correttamente, i motori di ricerca potrebbero non prestare sufficiente attenzione ad alcune pagine.

Ho spesso detto che Google è come il tuo capo. Non andresti in un incontro con il tuo capo a meno che tu non sapessi di cosa stavi per parlare, i punti salienti del tuo lavoro, gli obiettivi del tuo incontro. In breve, avrai un ordine del giorno. Quando si cammina in “ufficio” di Google, è necessario la stessa cosa. Una chiara gerarchia del sito senza molti cruft, un’utile sitemap XML e tempi di risposta rapidi aiuteranno Google a raggiungere ciò che è importante. Non trascurare questo elemento spesso frainteso del SEO.

Per me, il concetto di indicizzazione di bilancio è uno dei punti chiave di tecniche SEO. Quando ottimizzi per il budget di scansione, tutto il resto va a posto: collegamento interno, correzione degli errori, velocità della pagina, ottimizzazione degli URL, contenuti di bassa qualità e altro ancora. Le persone dovrebbero scavare nei loro file di registro più spesso per monitorare il budget di scansione per URL specifici, sottodomini, directory, ecc. Il monitoraggio della frequenza di scansione è molto correlato al budget di scansione e super potente.
Accessibile Url con parametri
Nella maggior parte dei casi, gli Url con parametri non dovrebbero essere accessibili per i motori di ricerca, perché sono in grado di generare un numero virtualmente infinito di quantità di Url.Abbiamo scritto ampiamente su questo tipo di problema nel nostro articolo sulle trappole cingolate.
Gli URL con parametri vengono comunemente utilizzati quando si implementano filtri di prodotto su siti di e-commerce. Va bene usarli,; basta assicurarsi che non siano accessibili ai motori di ricerca.
Come puoi renderli inaccessibili al motore di ricerca?
- Usa i tuoi robot.file txt per indicare ai motori di ricerca di non accedere a tali URL. Se questa non è un’opzione per qualche motivo, utilizzare le impostazioni di gestione dei parametri URL in Google Search Console e Bing Webmaster Tools per indicare a Google e Bing quali pagine non eseguire la scansione.
- Aggiungi il valore dell’attributo nofollow ai collegamenti sui collegamenti filtro. Si prega di notare che a partire da marzo 2020, Google può scegliere di ignorare il nofollow. Pertanto il passaggio 1 è ancora più importante.
Contenuti duplicati
Non vuoi che i motori di ricerca trascorrano il loro tempo su pagine di contenuti duplicati, quindi è importante prevenire, o per lo meno minimizzare, il contenuto duplicato nel tuo sito.
Come si fa? Da…
- Impostazione dei reindirizzamenti del sito Web per tutte le varianti di dominio(
HTTP,HTTPS,non-WWW, eWWW). - Rendere le pagine dei risultati di ricerca interne inaccessibili ai motori di ricerca che utilizzano i robot.txt. Ecco un esempio robot.txt per un sito web WordPress.
- Disabilitare le pagine dedicate per le immagini (ad esempio: le famigerate pagine di allegati di immagini in WordPress).
- Fare attenzione all’uso di tassonomie come categorie e tag.
Scopri alcuni motivi più tecnici per i contenuti duplicati e come risolverli.
Contenuti di bassa qualità
Le pagine con pochissimo contenuto non sono interessanti per i motori di ricerca. Tenerli al minimo, o evitarli completamente, se possibile. Un esempio di contenuti di bassa qualità è una sezione FAQ con link per mostrare le domande e le risposte, dove ogni domanda e risposta è servita su un URL separato.
Collegamenti interrotti e reindirizzamenti
Collegamenti interrotti e lunghe catene di reindirizzamenti sono vicoli ciechi per i motori di ricerca. Simile ai browser, Google sembra seguire un massimo di cinque reindirizzamenti concatenati in una scansione (potrebbero riprendere la scansione in un secondo momento). Non è chiaro quanto bene altri motori di ricerca si occupano di reindirizzamenti successivi, ma si consiglia vivamente di evitare reindirizzamenti incatenati interamente e mantenere l’utilizzo di reindirizzamenti al minimo.
È chiaro che risolvendo i collegamenti interrotti e reindirizzando i collegamenti, è possibile recuperare rapidamente il budget di scansione sprecato. Oltre a recuperare il budget di scansione, stai anche migliorando significativamente l’esperienza utente di un visitatore. I reindirizzamenti e le catene di reindirizzamenti in particolare, causano tempi di caricamento della pagina più lunghi e quindi danneggiano l’esperienza dell’utente.
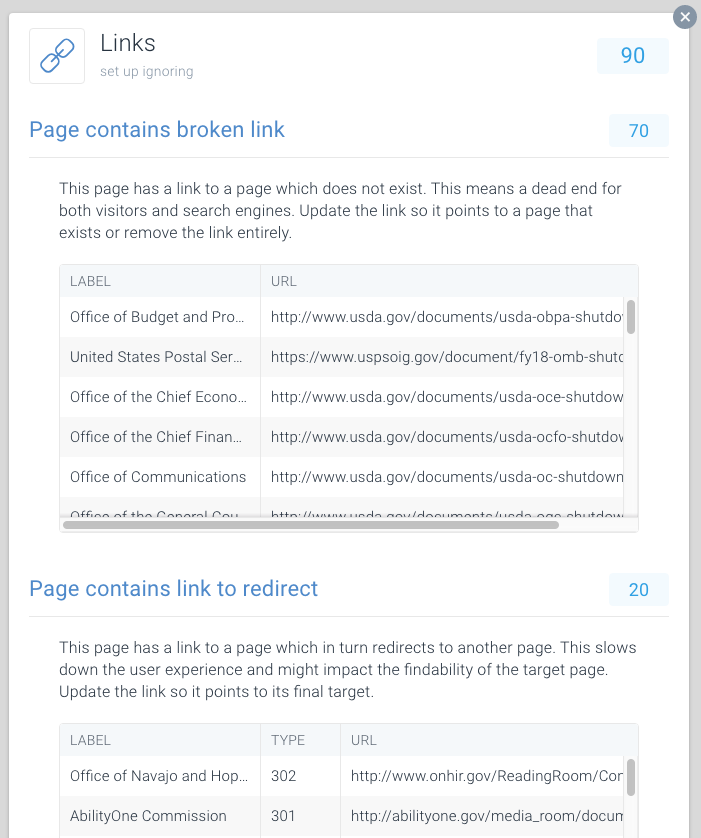
Per rendere facile la ricerca di collegamenti interrotti e reindirizzamenti, abbiamo dedicato problemi speciali a questo all’interno di ContentKing.
Vai a Issues > Links per scoprire se stai sprecando i budget di scansione a causa di collegamenti errati. Aggiorna ogni link in modo che si colleghi a una pagina indicizzabile o rimuovi il link se non è più necessario.
URL errati nelle sitemap XML
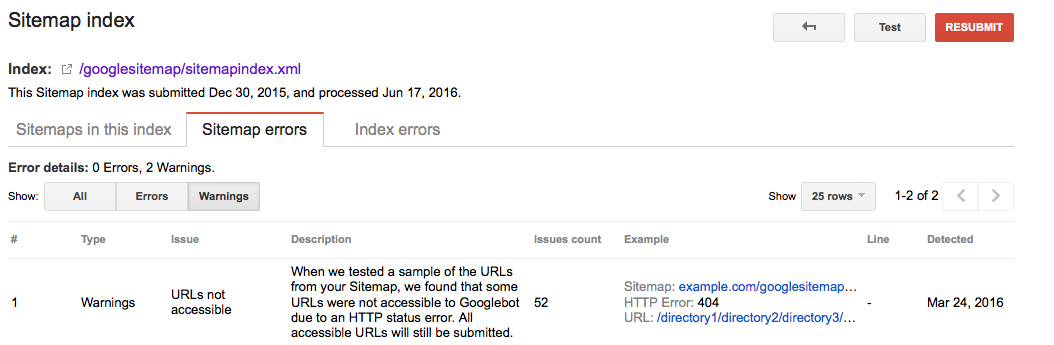
Tutti gli URL inclusi nelle sitemap XML devono essere per pagine indicizzabili. Soprattutto con i grandi siti web, i motori di ricerca si basano pesantemente su sitemap XML per trovare tutte le tue pagine. Se le tue sitemap XML sono ingombre di pagine che, ad esempio, non esistono più o stanno reindirizzando, stai sprecando il budget di scansione. Controlla regolarmente la tua sitemap XML per gli URL non indicizzabili che non appartengono a lì. Controlla anche il contrario: cerca le pagine che sono escluse in modo errato dalla sitemap XML. La sitemap XML è un ottimo modo per aiutare i motori di ricerca spendere budget scansione saggiamente.
Google Searche Console
- Accedere di Ricerca di Google Console
- Clic su
Crawlscheda - Clic su
Sitemapsscheda
Bing Webmaster Tools
- accedi sul tuo account Strumenti per i Webmaster di Bing
- Clic su
Configure My Sitescheda - Clic su
Sitemapsscheda
ContentKing
- Accedi sul tuo ContentKing account
- Clic su
- Clic su
- In caso di problemi con la vostra pagina verrà visualizzato questo messaggio:
Page is incorrectly included in XML sitemap
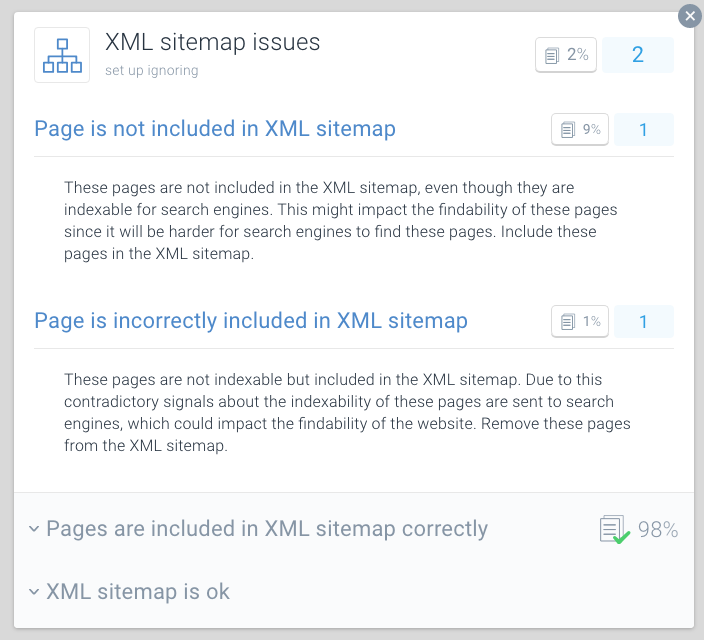
Una buona pratica per l’ottimizzazione del crawl-budget consiste nel dividere le sitemap XML in sitemap più piccole. Ad esempio, puoi creare sitemap XML per ciascuna delle sezioni del tuo sito web. Se hai fatto questo, è possibile determinare rapidamente se ci sono problemi in corso in alcune sezioni del tuo sito web.
Dì che la tua sitemap XML per la sezione A contiene 500 link e 480 sono indicizzati: allora stai andando abbastanza bene. Ma se la tua sitemap XML per la sezione B contiene 500 link e solo 120 sono indicizzati, è qualcosa da esaminare. Potresti aver incluso molti URL non indicizzabili nella sitemap XML per la sezione B.
Le cattive condizioni per i crawler possono danneggiare il tuo SEO. Utilizzare ContentKing per eseguire un rapido controllo del tuo sito web.
Pagine con tempi di caricamento elevati / timeout

Quando le pagine hanno tempi di caricamento elevati o scadono, i motori di ricerca possono visitare meno pagine all’interno del budget assegnato per la scansione del tuo sito web. Oltre a questo aspetto negativo, i tempi di caricamento e i timeout delle pagine elevati danneggiano in modo significativo l’esperienza utente del visitatore, con un tasso di conversione più basso.
I tempi di caricamento della pagina superiori a due secondi sono un problema. Idealmente, la tua pagina verrà caricata in meno di un secondo. Controllare regolarmente i tempi di caricamento della pagina con strumenti come Pingdom (si apre in una nuova scheda), WebPagetest (si apre in una nuova scheda) o GTmetrix (si apre in una nuova scheda).
Google riporta il tempo di caricamento della pagina sia in Google Analytics (sotto Behavior > Site Speed) e Google Search Console sotto Crawl > Crawl Stats.
Google Search Console e Bing Webmaster Tools riportano entrambi i timeout di pagina. In Google Search Console, questo può essere trovato sotto Crawl > Crawl Errors, e in Bing Strumenti per i Webmaster, è sotto Reports & Data > Crawl Information.
Controlla regolarmente se le tue pagine si caricano abbastanza velocemente e agisci immediatamente se non lo sono. Le pagine a caricamento rapido sono vitali per il tuo successo online.
Numero elevato di pagine non indicizzabili
Se il tuo sito web contiene un numero elevato di pagine non indicizzabili accessibili ai motori di ricerca, stai fondamentalmente mantenendo i motori di ricerca impegnati a spulciare le pagine irrilevanti.
Consideriamo i seguenti tipi di pagine non indicizzabili:
- Redirect (3xx)
- Pagine che non possono essere trovati (4xx)
- Pagine con errori di server (5xx)
- Pagine che non sono indicizzabili (le pagine che contengono i robots noindex di una direttiva o di canonical URL)
per scoprire se si dispone di un elevato numero di non indicizzabili pagine, cercare il numero totale di pagine che i crawler hanno trovato all’interno del tuo sito web e su come abbattere. Puoi farlo facilmente usando ContentKing:
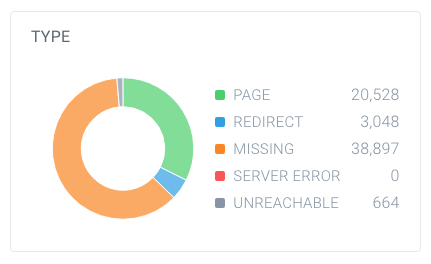
In questo esempio, sono stati trovati 63.137 URL, di cui solo 20.528 sono pagine.
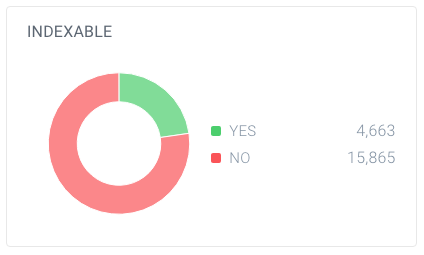
E di queste pagine, solo 4.663 sono indicizzabili per i motori di ricerca. Solo il 7,4% degli URL trovati da ContentKing può essere indicizzato dai motori di ricerca. Che non è un buon rapporto, e questo sito ha sicuramente bisogno di lavorare su quello con la pulizia di tutti i riferimenti che sono inutili, tra cui:
- La sitemap XML (vedi sezione precedente)
- Link
- Canonical Url
- Hreflang riferimenti
- Impaginazione riferimenti (link rel prev/next)
Bad struttura interna di collegamento
Come le pagine del tuo sito web link uno per l’altro gioca un ruolo importante nella ricerca per indicizzazione ottimizzare il budget. Noi chiamiamo questo la struttura di collegamento interno del tuo sito web. Backlinks a parte, pagine che hanno pochi collegamenti interni ottenere molto meno attenzione dai motori di ricerca rispetto alle pagine che sono collegati da un sacco di pagine.
Evita una struttura di collegamento molto gerarchica, con le pagine nel mezzo con pochi collegamenti. In molti casi, queste pagine non verranno sottoposte a scansione frequente. È ancora peggio per le pagine in fondo alla gerarchia: a causa della loro quantità limitata di link, possono benissimo essere trascurati dai motori di ricerca.
Assicurati che le tue pagine più importanti abbiano molti collegamenti interni. Le pagine che sono state recentemente scansionate in genere si classificano meglio nei motori di ricerca. Tienilo a mente e regola la tua struttura di collegamento interna per questo.
Ad esempio, se si dispone di un articolo del blog risalente al 2011 che guida un sacco di traffico organico, assicurarsi di mantenere il collegamento ad esso da altri contenuti. Perché hai prodotto molti altri articoli di blog nel corso degli anni, che l’articolo dal 2011 viene automaticamente spinto verso il basso nella struttura di collegamento interno del tuo sito web.

Di solito non devi preoccuparti della velocità di scansione delle tue pagine importanti. Di solito sono pagine nuove, a cui non hai linkato e che le persone non stanno andando a che potrebbero non essere scansionate spesso.
Come aumentare il budget di scansione del tuo sito web?
Durante un’intervista (si apre in una nuova scheda) tra Eric Enge e Google, l’ex capo del webspam team di Matt Cutts, il rapporto tra autorità e la ricerca per indicizzazione di bilancio è stato portato:

Il modo migliore di pensare è che il numero di pagine che la scansione è approssimativamente proporzionale al tuo PageRank. Quindi, se hai molti link in arrivo sulla tua pagina principale, lo eseguiremo sicuramente. Quindi la tua pagina principale potrebbe collegarsi ad altre pagine, e quelle otterranno PageRank e noi eseguiremo la scansione anche di quelle. Come si ottiene sempre più in profondità nel tuo sito, tuttavia, PageRank tende a diminuire.
Anche se Google ha abbandonato l’aggiornamento dei valori di PageRank delle pagine pubblicamente, pensiamo che (una forma di) PageRank sia ancora utilizzato nei loro algoritmi. Poiché PageRank è un termine incompreso e confuso, chiamiamolo autorità pagina. Il take-away qui è che Matt Cutts dice fondamentalmente: c’è una relazione piuttosto forte tra l’autorità della pagina e il budget di scansione.
Quindi, per aumentare il budget di scansione del tuo sito web, devi aumentare l’autorità del tuo sito web. Una grande parte di questo è fatto da guadagnare più link da siti web esterni. Maggiori informazioni su questo possono essere trovate nella nostra guida link building.

Quando sento l’industria parlare di crawl budget, di solito parliamo di on-page e modifiche tecniche che possiamo fare al fine di aumentare il budget crawl nel tempo. Tuttavia, provenendo da uno sfondo di link building, i picchi più grandi nelle pagine scansionate che vediamo in Google Search Console si riferiscono direttamente a quando vinciamo grandi collegamenti per i nostri clienti.
Domande frequenti su crawl budget
- 🧾 Che cosa è crawl budget?
- How come posso aumentare il mio budget di scansione?
- 🎛️ Cosa può limitare il mio budget di scansione?
- Should dovrei usare URL canonici e meta robot?
1. 🧾 Che cosa è crawl budget?
Crawl budget è il numero di pagine che i motori di ricerca eseguiranno su un sito Web entro un determinato periodo di tempo.
2. 🤔 Come posso aumentare il mio budget di scansione?
Google ha indicato che esiste una forte relazione tra l’autorità della pagina e il budget di scansione. Più autorità ha una pagina, più budget di scansione ha. In poche parole, per aumentare il tuo budget di scansione, costruisci l’autorità della tua pagina.
3. 🤷 Cosa può limitare il mio budget di scansione?
Crawl limit, noto anche come crawl host load, si basa su molti fattori, come le condizioni del sito web e le capacità di hosting. I crawler dei motori di ricerca sono impostati per evitare il sovraccarico di un server Web. Se il tuo sito web restituisce errori del server o se gli URL richiesti scadono spesso, il budget di scansione sarà più limitato. Allo stesso modo, se il tuo sito Web viene eseguito su una piattaforma di hosting condiviso, il limite di scansione sarà più alto in quanto devi condividere il tuo budget di scansione con altri siti Web in esecuzione sull’hosting.
4. Should Dovrei usare URL canonici e meta robot?
Sì, ed è importante capire le differenze tra i problemi di indicizzazione e i problemi di scansione.
I tag URL e meta robot canonici inviano un chiaro segnale ai motori di ricerca quale pagina dovrebbero mostrare nel loro indice, ma non impedisce loro di strisciare quelle altre pagine.
È possibile utilizzare i robot.file txt e la relazione di collegamento nofollow per gestire i problemi di scansione.