
Source : Boostez vos modèles de vision par ordinateur avec l’API de détection d’objets TensorFlow,
Jonathan Huang, Chercheur et Vivek Rathod, Ingénieur logiciel,
Blog Google AI
- La détection d’objets en tant que tâche en vision par ordinateur
- YOLO comme détecteur d’objets en temps réel
- Qu’est-ce que YOLO ?
- YOLO par rapport aux autres détecteurs
- Versions de YOLO
- Exemples d’applications YOLO
- YOLO comme détecteur d’objets dans TensorFlow & Keras
- TensorFlow & Frameworks Keras en apprentissage automatique
- Implémentation YOLO dans TensorFlow & Keras
- Comment exécuter YOLO pré-entraîné prêt à l’emploi et obtenir des résultats
- Comment former votre modèle de détection d’objet YOLO personnalisé
- Énoncé de tâche
- Jeu de données & annotations
- Où obtenir les données de
- Comment annoter des données pour YOLO
- Comment transformer des données d’autres formats en annotations YOLO
- Diviser les données en sous-ensembles
- Création de générateurs de données
- Installation & configuration requise pour la formation des modèles
- Formation de modèle
- Prérequis
- Initialisation de l’objet modèle
- Définition des rappels
- Ajustement du modèle
- Modèle personnalisé entraîné en mode d’inférence
- Conclusions
- Anton Morgunov
- API de Détection d’objets TensorFlow: Meilleures pratiques pour la formation, l’évaluation & Déploiement
La détection d’objets en tant que tâche en vision par ordinateur
Nous rencontrons des objets tous les jours de notre vie. Regardez autour de vous et vous trouverez plusieurs objets qui vous entourent. En tant qu’être humain, vous pouvez facilement détecter et identifier chaque objet que vous voyez. C’est naturel et ne demande pas beaucoup d’efforts.
Pour les ordinateurs, cependant, la détection d’objets est une tâche qui nécessite une solution complexe. Pour un ordinateur, « détecter des objets » signifie traiter une image d’entrée (ou une image unique d’une vidéo) et répondre avec des informations sur les objets sur l’image et leur position. En termes de vision par ordinateur, nous appelons ces deux tâches classification et localisation. Nous voulons que l’ordinateur dise quel type d’objets sont présentés sur une image donnée et où ils se trouvent exactement.
Plusieurs solutions ont été développées pour aider les ordinateurs à détecter les objets. Aujourd’hui, nous allons explorer un algorithme de pointe appelé YOLO, qui atteint une grande précision à une vitesse en temps réel. En particulier, nous allons apprendre à entraîner cet algorithme sur un ensemble de données personnalisé dans TensorFlow /Keras.
Tout d’abord, voyons ce qu’est exactement YOLO et ce pour quoi il est célèbre.
YOLO comme détecteur d’objets en temps réel
Qu’est-ce que YOLO ?
YOLO est un acronyme pour « Vous ne regardez qu’une fois » (ne le confondez pas avec Vous ne vivez qu’Une fois des Simpson). Comme son nom l’indique, un seul « look » suffit pour trouver tous les objets sur une image et les identifier.
En termes d’apprentissage automatique, on peut dire que tous les objets sont détectés via un seul algorithme exécuté. Cela se fait en divisant une image en une grille et en prédisant des boîtes englobantes et des probabilités de classe pour chaque cellule d’une grille. Dans le cas où nous aimerions utiliser YOLO pour la détection de voiture, voici à quoi pourraient ressembler la grille et les boîtes de délimitation prévues:

La boîte de délimitation que YOLO prédit pour la première voiture est en rouge.
La boîte de délimitation que YOLO prédit pour la deuxième voiture est jaune.
Source de l’image.
L’image ci-dessus ne contient que l’ensemble final de cases obtenues après filtrage. Il est à noter que la sortie brute de YOLO contient de nombreuses boîtes englobantes pour le même objet. Ces boîtes diffèrent par leur forme et leur taille. Comme vous pouvez le voir dans l’image ci-dessous, certaines boîtes capturent mieux l’objet cible alors que d’autres proposées par un algorithme fonctionnent mal.

Toutes les boîtes jaunes sont pour la deuxième voiture.
Les boîtes rouges et jaunes audacieuses sont les meilleures pour la détection de voiture.
Source de l’image.
Pour sélectionner la meilleure boîte englobante pour un objet donné, un algorithme de suppression non maximale (NMS) est appliqué.

prévues pour les voitures afin de ne conserver que celles qui capturent le mieux les objets.
Source de l’image.
Toutes les boîtes que YOLO prédit ont un niveau de confiance qui leur est associé. NMS utilise ces valeurs de confiance pour supprimer les cases qui ont été prédites avec une faible certitude. Habituellement, ce sont toutes des boîtes qui sont prédites avec une confiance inférieure à 0,5.

Vous pouvez voir les scores de confiance dans le coin supérieur gauche de chaque boîte, à côté du nom de l’objet.
Source de l’image.
Lorsque toutes les boîtes de délimitation incertaines sont supprimées, seules les boîtes avec le niveau de confiance élevé sont laissées. Pour sélectionner le meilleur parmi les candidats les plus performants, NMS sélectionne la boîte avec le niveau de confiance le plus élevé et calcule comment elle croise les autres boîtes autour. Si une intersection est supérieure à un niveau de seuil particulier, la boîte englobante avec une confiance inférieure est supprimée. Dans le cas où NMS compare deux cases dont l’intersection est inférieure à un seuil sélectionné, les deux cases sont conservées dans les prédictions finales.
YOLO par rapport aux autres détecteurs
Bien qu’un réseau neuronal convolutif (CNN) soit utilisé sous le capot de YOLO, il est toujours capable de détecter des objets avec des performances en temps réel. C’est possible grâce à la capacité de YOLO à faire les prédictions simultanément dans une approche en une seule étape.
D’autres algorithmes plus lents pour la détection d’objets (comme R-CNN plus rapide) utilisent généralement une approche en deux étapes:
- dans la première étape, des régions d’image intéressantes sont sélectionnées. Ce sont les parties d’une image qui peuvent contenir des objets;
- dans la deuxième étape, chacune de ces régions est classée à l’aide d’un réseau neuronal convolutif.
Habituellement, il y a beaucoup de régions sur une image avec les objets. Toutes ces régions sont envoyées à la classification. La classification est une opération qui prend beaucoup de temps, c’est pourquoi l’approche de détection d’objets en deux étapes est plus lente que la détection en une étape.
YOLO ne sélectionne pas les parties intéressantes d’une image, cela n’est pas nécessaire. Au lieu de cela, il prédit des boîtes englobantes et des classes pour l’ensemble de l’image en une seule passe nette avant.
Ci-dessous, vous pouvez voir à quelle vitesse YOLO est comparé à d’autres détecteurs populaires.

SSD et YOLO sont des détecteurs d’objets à un étage alors que Faster-RCNN
et R-FCN sont des détecteurs d’objets à deux étages.
Source de l’image.
Versions de YOLO
YOLO a été introduit pour la première fois en 2015 par Joseph Redmon dans son article de recherche intitulé « You Only Look Once: Unified, Real-Time Object Detection ».
Depuis, YOLO a beaucoup évolué. En 2016, Joseph Redmon a décrit la deuxième version de YOLO dans « YOLO9000: Mieux, Plus vite, Plus fort ».
Environ deux ans après la deuxième mise à jour de YOLO, Joseph a proposé une autre mise à jour nette. Son article, intitulé « YOLOv3: Une amélioration incrémentielle », a attiré l’attention de nombreux ingénieurs en informatique et est devenu populaire dans la communauté de l’apprentissage automatique.
En 2020, Joseph Redmon a décidé d’arrêter ses recherches en vision par ordinateur, mais cela n’a pas empêché YOLO d’être développé par d’autres. La même année, une équipe de trois ingénieurs (Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao) a conçu la quatrième version de YOLO, encore plus rapide et plus précise qu’auparavant. Leurs résultats sont décrits dans le « YOLOv4: Vitesse et Précision Optimales de Détection d’Objets » article qu’ils ont publié le 23 avril 2020.
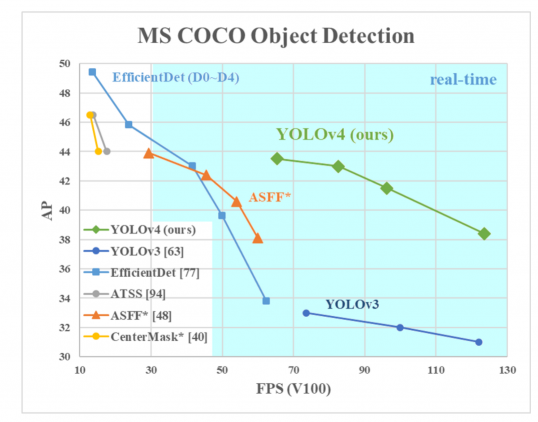
AP sur l’axe des ordonnées est une métrique appelée « précision moyenne ». Il décrit la précision du filet.
FPS (images par seconde) sur l’axe des abscisses est une métrique qui décrit la vitesse.
Source de l’image.
Deux mois après la sortie de la 4ème version, un développeur indépendant, Glenn Jocher, a annoncé la 5ème version de YOLO. Cette fois, aucun document de recherche n’a été publié. Le réseau est devenu disponible sur la page GitHub de Jocher en tant qu’implémentation PyTorch. La cinquième version avait à peu près la même précision que la quatrième version, mais elle était plus rapide.
Enfin, en juillet 2020, nous avons eu une autre grosse mise à jour de YOLO. Dans un article intitulé « PP-YOLO: Une mise en œuvre efficace et efficiente du détecteur d’objets », Xiang Long et son équipe ont proposé une nouvelle version de YOLO. Cette itération de YOLO était basée sur la 3ème version du modèle et dépassait les performances de YOLO v4.

La carte sur l’axe des ordonnées est une métrique appelée « précision moyenne moyenne ». Il décrit la précision du filet.
FPS (images par seconde) sur l’axe des abscisses est une métrique qui décrit la vitesse.
Source de l’image.
Dans ce tutoriel, nous allons examiner de plus près YOLOv4 et sa mise en œuvre. Pourquoi YOLOv4? Trois raisons:
- Elle a une large approbation dans la communauté de l’apprentissage automatique;
- Cette version a prouvé sa haute performance dans un large éventail de tâches de détection;
- YOLOv4 a été implémenté dans plusieurs frameworks populaires, y compris TensorFlow et Keras, avec lesquels nous allons travailler.
Exemples d’applications YOLO
Avant de passer à la partie pratique de cet article, implémentant notre détecteur d’objets basé sur YOLO personnalisé, j’aimerais vous montrer quelques implémentations YOLOv4 intéressantes, puis nous allons faire notre implémentation.
Faites attention à la rapidité et à la précision des prédictions!
Voici le premier exemple impressionnant de ce que YOLOv4 peut faire, en détectant plusieurs objets de différentes scènes de jeu et de film.
Vous pouvez également vérifier cette démonstration de détection d’objets à partir d’une vue de caméra réelle.
YOLO comme détecteur d’objets dans TensorFlow & Keras
TensorFlow & Frameworks Keras en apprentissage automatique

Source de l’image.
Les cadres sont essentiels dans tous les domaines des technologies de l’information. L’apprentissage automatique ne fait pas exception. Il existe plusieurs acteurs établis sur le marché du ML qui nous aident à simplifier l’expérience globale de programmation. PyTorch, scikit-learn, TensorFlow, Keras, MXNet et Caffe ne sont que quelques-uns à mentionner.
Aujourd’hui, nous allons travailler en étroite collaboration avec TensorFlow/Keras. Sans surprise, ces deux frameworks sont parmi les plus populaires de l’univers de l’apprentissage automatique. Cela est dû en grande partie au fait que TensorFlow et Keras fournissent des capacités de développement riches. Ces deux cadres sont assez similaires l’un à l’autre. Sans trop creuser dans les détails, la chose clé à retenir est que Keras n’est qu’un wrapper pour le framework TensorFlow.
Implémentation YOLO dans TensorFlow & Keras
Au moment de la rédaction de cet article, il y avait 808 dépôts avec des implémentations YOLO sur un backend TensorFlow/Keras. La version 4 de YOLO est ce que nous allons implémenter. En limitant la recherche à seulement YOLO v4, j’ai eu 55 dépôts.
En les parcourant attentivement, j’ai trouvé un candidat intéressant avec lequel continuer.
Source de l’image.
Cette implémentation a été développée par taipingeric et jimmyaspire. C’est assez simple et très intuitif si vous avez déjà travaillé avec TensorFlow et Keras.
Pour commencer à travailler avec cette implémentation, il suffit de cloner le dépôt sur votre machine locale. Ensuite, je vais vous montrer comment utiliser YOLO dès la sortie de la boîte et comment entraîner votre propre détecteur d’objets personnalisé.
Comment exécuter YOLO pré-entraîné prêt à l’emploi et obtenir des résultats
En regardant la section « Démarrage rapide » du dépôt, vous pouvez voir que pour qu’un modèle soit opérationnel, il suffit d’importer YOLO en tant qu’objet de classe et de charger les poids du modèle:
from models import Yolov4model = Yolov4(weight_path='yolov4.weights', class_name_path='class_names/coco_classes.txt')
Notez que vous devez télécharger manuellement les poids du modèle à l’avance. Le fichier de poids de modèle fourni avec YOLO provient de l’ensemble de données COCO et est disponible sur la page officielle du projet darknet d’AlexeyAB sur GitHub. Vous pouvez télécharger les poids directement via ce lien.
Juste après, le modèle est entièrement prêt à travailler avec des images en mode inférence. Utilisez simplement la méthode predict() pour une image de votre choix. La méthode est standard pour les frameworks TensorFlow et Keras.
pred = model.predict('input.jpg')
Par exemple pour cette image d’entrée:

J’ai obtenu la sortie de modèle suivante:

Les prédictions que le modèle a faites sont renvoyées sous la forme pratique d’une trame de données pandas. Nous obtenons le nom de la classe, la taille de la boîte et les coordonnées de chaque objet détecté:

Beaucoup d’informations utiles sur les objets détectés
Il existe plusieurs paramètres dans la méthode predict() qui nous permettent de spécifier si nous voulons tracer l’image avec les zones de délimitation prédites, les noms textuels de chaque objet, etc. Consultez la docstring qui va de pair avec la méthode predict() pour vous familiariser avec ce qui est à notre disposition:

Vous devez vous attendre à ce que votre modèle ne puisse détecter que des types d’objets strictement limités à l’ensemble de données COCO. Pour savoir quels types d’objets un modèle YOLO pré-formé est capable de détecter, consultez les coco_classes.fichier txt disponible en …/yolo-v4-tf.kers/noms de classe /. Il y a 80 types d’objets là-dedans.
Comment former votre modèle de détection d’objet YOLO personnalisé
Énoncé de tâche

Pour concevoir un modèle de détection d’objet, vous devez savoir quels types d’objets vous souhaitez détecter. Cela devrait être un nombre limité de types d’objets pour lesquels vous souhaitez créer votre détecteur. Il est bon d’avoir une liste de types d’objets préparée au fur et à mesure que nous passons au développement réel du modèle.
Idéalement, vous devriez également avoir un ensemble de données annoté contenant des objets qui vous intéressent. Cet ensemble de données sera utilisé pour entraîner un détecteur et le valider. Si vous n’avez pas encore d’ensemble de données ou d’annotation pour cela, ne vous inquiétez pas, je vais vous montrer où et comment vous pouvez l’obtenir.
Jeu de données & annotations
Où obtenir les données de
Si vous avez un jeu de données annoté avec lequel travailler, ignorez simplement cette partie et passez au chapitre suivant. Mais, si vous avez besoin d’un ensemble de données pour votre projet, nous allons maintenant explorer des ressources en ligne où vous pouvez obtenir des données.
Peu importe le domaine dans lequel vous travaillez, il y a de grandes chances qu’il existe déjà un ensemble de données open source que vous pouvez utiliser pour votre projet.
La première ressource que je recommande est l’article « Plus de 50 ensembles de données de détection d’objets provenant de différents domaines de l’industrie » d’Abhishek Annamraju qui a collecté de merveilleux ensembles de données annotés pour des industries telles que la Mode, la Vente au détail, le Sport, la Médecine et bien d’autres.

Source de l’image.
Les deux autres bons endroits pour rechercher les données sont paperswithcode.com et roboflow.com qui donnent accès à des jeux de données de haute qualité pour la détection d’objets.
Consultez ces ressources ci-dessus pour collecter les données dont vous avez besoin ou pour enrichir l’ensemble de données que vous avez déjà.
Comment annoter des données pour YOLO
Si votre jeu de données d’images est livré sans annotations, vous devez effectuer le travail d’annotation vous-même. Cette opération manuelle prend beaucoup de temps, alors assurez-vous d’avoir suffisamment de temps pour le faire.
En tant qu’outil d’annotation, vous pouvez envisager plusieurs options. Personnellement, je recommanderais d’utiliser LabelImg. C’est un outil d’annotation d’image léger et facile à utiliser qui peut directement générer des annotations pour les modèles YOLO.
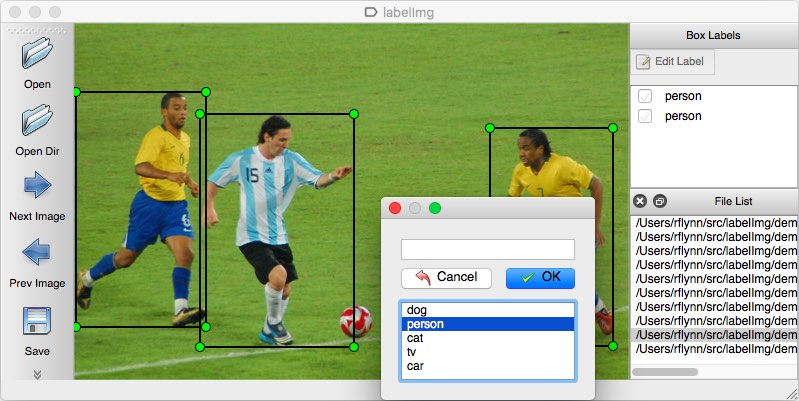
Source de l’image.
Comment transformer des données d’autres formats en annotations YOLO
sous forme de fichiers txt. Chaque ligne d’un fichier txt fol YOLO doit avoir le format suivant:
image1.jpg 10,15,345,284,0image2.jpg 100,94,613,814,0 31,420,220,540,1
Nous pouvons séparer chaque ligne du fichier txt et voir en quoi elle consiste:
- La première partie d’une ligne spécifie les noms de base des images : image1.jpg, image2.jpg
- La deuxième partie d’une ligne définit les coordonnées de la boîte englobante et l’étiquette de la classe. Par exemple, 10,15,345,284,0 états pour xmin, ymin, xmax, ymax, class_id
- Si une image donnée contient plusieurs objets, il y aura plusieurs cases et étiquettes de classe à côté du nom de base de l’image, divisées par un espace.
Les coordonnées de la boîte englobante sont un concept clair, mais qu’en est-il du numéro class_id qui spécifie l’étiquette de la classe? Chaque class_id est lié à une classe particulière dans un autre fichier txt. Par exemple, YOLO pré-formé est livré avec les coco_classes.fichier txt qui ressemble à ceci:
personbicyclecarmotorbikeaeroplanebus...
Le nombre de lignes dans les fichiers de classes doit correspondre au nombre de classes que votre détecteur va détecter. La numération commence à zéro, ce qui signifie que le numéro class_id de la première classe du fichier classes sera 0. La classe placée sur la deuxième ligne du fichier classes txt aura le numéro 1.
Maintenant, vous savez à quoi ressemble l’annotation pour YOLO. Pour continuer à créer un détecteur d’objets personnalisé, je vous invite à faire deux choses maintenant:
- créez un fichier txt de classes dans lequel vous pourrez sélectionner les classes que vous souhaitez que votre détecteur détecte. Rappelez-vous que l’ordre de classe compte.
- Créez un fichier txt avec des annotations. Dans le cas où vous avez déjà une annotation mais au format VOC (.XMLs), vous pouvez utiliser ce fichier pour transformer du XML en YOLO.
Diviser les données en sous-ensembles
Comme toujours, nous voulons diviser l’ensemble de données en 2 sous-ensembles: pour la formation et pour la validation. Cela peut être fait aussi simple que:
from utils import read_annotation_lines train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1)
Création de générateurs de données
Lorsque les données sont fractionnées, nous pouvons procéder à l’initialisation du générateur de données. Nous aurons un générateur de données pour chaque fichier de données. Dans notre cas, nous aurons un générateur pour le sous-ensemble de formation et pour le sous-ensemble de validation.
Voici comment les générateurs de données sont créés:
from utils import DataGenerator FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
Pour résumer, voici à quoi ressemble le code complet pour le fractionnement de données et la création de générateurs:
from utils import read_annotation_lines, DataGenerator train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1) FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
Installation & configuration requise pour la formation des modèles
Parlons des prérequis indispensables pour créer votre propre détecteur d’objets:
- Python devrait déjà être installé sur votre ordinateur. Au cas où vous auriez besoin de l’installer, je vous recommande de suivre ce guide officiel d’Anaconda;
- Si votre ordinateur dispose d’un GPU compatible CUDA (un GPU fabriqué par NVIDIA), quelques bibliothèques pertinentes sont nécessaires pour prendre en charge la formation basée sur le GPU. Si vous devez activer la prise en charge du GPU, consultez les directives sur le site Web de NVIDIA. Votre objectif est d’installer la dernière version de la boîte à outils CUDA et de cuDNN pour votre système d’exploitation;
- Vous voudrez peut-être organiser un environnement virtuel indépendant dans lequel travailler. Ce projet nécessite l’installation de TensorFlow 2. Toutes les autres bibliothèques seront introduites ultérieurement;
- Quant à moi, je construisais et entraînais mon modèle YOLOv4 dans un environnement de développement de notebook Jupyter. Bien que Jupyter Notebook semble être une option raisonnable, envisagez le développement dans unE de votre choix si vous le souhaitez.
Formation de modèle

Prérequis
Maintenant, vous devriez avoir:
- Une division pour votre jeu de données;
- Deux générateurs de données initialisés;
- Un fichier txt avec les classes.
Initialisation de l’objet modèle
Pour vous préparer à un travail d’entraînement, initialisez l’objet modèle YOLOv4. Assurez-vous d’utiliser None comme valeur pour le paramètre weight_path. Vous devez également fournir un chemin d’accès à votre fichier txt de classes à cette étape. Voici le code d’initialisation que j’ai utilisé dans mon projet:
class_name_path = 'path2project_folder/model_data/scans_file.txt' model = Yolov4(weight_path=None, class_name_path=class_name_path)
L’initialisation du modèle ci-dessus conduit à la création d’un objet modèle avec un ensemble de paramètres par défaut. Envisagez de modifier la configuration de votre modèle en transmettant un dictionnaire en tant que valeur au paramètre de modèle de configuration.

Config spécifie un ensemble de paramètres pour le modèle YOLOv4.
La configuration par défaut du modèle est un bon point de départ, mais vous voudrez peut-être expérimenter d’autres configurations pour une meilleure qualité du modèle.
En particulier, je recommande fortement d’expérimenter avec les ancres et img_size. Les ancres spécifient la géométrie des ancres qui seront utilisées pour capturer des objets. Plus les formes des ancrages s’adaptent aux formes des objets, plus les performances du modèle seront élevées.
L’augmentation de img_size peut également être utile dans certains cas. Gardez à l’esprit que plus l’image est haute, plus le modèle fera l’inférence longtemps.
Si vous souhaitez utiliser Neptune comme outil de suivi, vous devez également initialiser une expérience, comme ceci:
import neptune.new as neptune run = neptune.init(project='projects/my_project', api_token=my_token)
Définition des rappels
TensorFlow & Keras nous permet d’utiliser des rappels pour surveiller la progression de la formation, établir des points de contrôle et gérer les paramètres de formation (par exemple, taux d’apprentissage).
Avant d’adapter votre modèle, définissez des rappels qui vous seront utiles. Assurez-vous de spécifier des chemins pour stocker les points de contrôle du modèle et les journaux associés. Voici comment je l’ai fait dans l’un de mes projets:
# defining pathes and callbacks dir4saving = 'path2checkpoint/checkpoints'os.makedirs(dir4saving, exist_ok = True) logdir = 'path4logdir/logs'os.makedirs(logdir, exist_ok = True) name4saving = 'epoch_{epoch:02d}-val_loss-{val_loss:.4f}.hdf5' filepath = os.path.join(dir4saving, name4saving) rLrCallBack = keras.callbacks.ReduceLROnPlateau(monitor = 'val_loss', factor = 0.1, patience = 5, verbose = 1) tbCallBack = keras.callbacks.TensorBoard(log_dir = logdir, histogram_freq = 0, write_graph = False, write_images = False) mcCallBack_loss = keras.callbacks.ModelCheckpoint(filepath, monitor = 'val_loss', verbose = 1, save_best_only = True, save_weights_only = False, mode = 'auto', period = 1)esCallBack = keras.callbacks.EarlyStopping(monitor = 'val_loss', mode = 'min', verbose = 1, patience = 10)
Vous auriez pu remarquer que dans les rappels ci-dessus, TensorBoard est utilisé comme outil de suivi. Envisagez d’utiliser Neptune comme un outil beaucoup plus avancé pour le suivi des expériences. Si c’est le cas, n’oubliez pas d’initialiser un autre rappel pour permettre l’intégration avec Neptune:
from neptune.new.integrations.tensorflow_keras import NeptuneCallback neptune_cbk = NeptuneCallback(run=run, base_namespace='metrics')
Ajustement du modèle
Pour lancer le travail d’entraînement, ajustez simplement l’objet modèle à l’aide de la méthode standard fit() dans TensorFlow/Keras. Voici comment j’ai commencé à entraîner mon modèle:
model.fit(data_gen_train, initial_epoch=0, epochs=10000, val_data_gen=data_gen_val, callbacks= )
Lorsque la formation est lancée, vous verrez une barre de progression standard.

Le processus de formation évaluera le modèle à la fin de chaque époque. Si vous utilisez un ensemble de rappels similaires à ce que j’ai initialisé et transmis lors de l’ajustement, les points de contrôle qui montrent une amélioration du modèle en termes de perte inférieure seront enregistrés dans un répertoire spécifié.
Si aucune erreur ne se produit et que le processus de formation se déroule correctement, le travail de formation sera arrêté soit en raison de la fin du numéro d’époque de formation, soit si le rappel d’arrêt anticipé ne détecte aucune autre amélioration du modèle et arrête le processus global.
Dans tous les cas, vous devriez vous retrouver avec plusieurs points de contrôle de modèle. Nous voulons sélectionner le meilleur parmi tous ceux disponibles et l’utiliser pour l’inférence.
Modèle personnalisé entraîné en mode d’inférence
L’exécution d’un modèle entraîné en mode d’inférence est similaire à l’exécution d’un modèle préformé prêt à l’emploi.

Vous initialisez un objet modèle passant dans le chemin vers le meilleur point de contrôle ainsi que le chemin vers le fichier txt avec les classes. Voici à quoi ressemble l’initialisation du modèle pour mon projet:
from models import Yolov4model = Yolov4(weight_path='path2checkpoint/checkpoints/epoch_48-val_loss-0.061.hdf5', class_name_path='path2classes_file/my_yolo_classes.txt')
Lorsque le modèle est initialisé, utilisez simplement la méthode predict() pour une image de votre choix pour obtenir les prédictions. En résumé, les détections effectuées par le modèle sont renvoyées sous la forme pratique d’une trame de données pandas. Nous obtenons le nom de la classe, la taille de la boîte et les coordonnées de chaque objet détecté.
Conclusions
Vous venez d’apprendre à créer un détecteur d’objets YOLOv4 personnalisé. Nous avons parcouru le processus de bout en bout, en commençant par la collecte des données, l’annotation et la transformation. Vous avez suffisamment de connaissances sur la quatrième version de YOLO et en quoi elle diffère des autres détecteurs.
Rien ne vous empêche maintenant de former votre propre modèle en TensorFlow et Keras. Vous savez où trouver un modèle pré-formé et comment démarrer le travail de formation.
Dans mon prochain article, je vais vous montrer quelques-unes des meilleures pratiques et des astuces de vie qui aideront à améliorer la qualité du modèle final. Restez avec nous!



Anton Morgunov
Ingénieur en vision par ordinateur chez Basis.Centre
Passionné d’apprentissage automatique. Passionné par la vision par ordinateur. Pas de papier – plus d’arbres! Travailler à l’élimination des copies papier en passant à la numérisation complète!
LIRE LA SUITE
API de Détection d’objets TensorFlow: Meilleures pratiques pour la formation, l’évaluation & Déploiement
13 minutes de lecture / Auteur Anton Morgunov / Mis à jour le 28 mai 2021
Cet article est la deuxième partie d’une série où vous apprendrez un flux de travail de bout en bout pour la Détection d’objets TensorFlow et son API. Dans le premier article, vous avez appris à créer un détecteur d’objets personnalisé à partir de zéro, mais il y a encore beaucoup de choses qui ont besoin de votre attention pour devenir vraiment compétent.
Nous explorerons des sujets tout aussi importants que le processus de création de modèle que nous avons déjà traversé. Voici quelques-unes des questions auxquelles nous répondrons:
- Comment évaluer mon modèle et obtenir une estimation de ses performances ?
- Quels sont les outils que je peux utiliser pour suivre les performances du modèle et comparer les résultats de plusieurs expériences?
- Comment puis-je exporter mon modèle pour l’utiliser en mode d’inférence?
- Existe-t-il un moyen d’augmenter encore plus les performances du modèle?
Continuer la lecture ->