Le budget d’exploration est le nombre de pages que les moteurs de recherche vont explorer sur un site Web dans un certain délai.
Les moteurs de recherche calculent le budget d’exploration en fonction de la limite d’exploration (à quelle fréquence ils peuvent explorer sans causer de problèmes) et de la demande d’exploration (à quelle fréquence ils souhaitent explorer un site).
Si vous gaspillez votre budget d’exploration, les moteurs de recherche ne pourront pas analyser efficacement votre site Web, ce qui finirait par nuire à vos performances de référencement.
- Qu’est-ce que le budget crawl ?
- Pourquoi les moteurs de recherche attribuent-ils un budget d’exploration aux sites Web?
- Comment attribuent-ils le budget d’analyse aux sites Web?
- Le budget d’exploration ne concerne-t-il que les pages?
- Comment fonctionne la limite d’exploration / la charge de l’hôte dans la pratique?
- Comment fonctionne la planification de la demande d’exploration / de l’exploration dans la pratique?
- N’oubliez pas: la capacité d’exploration du système lui-même
- Pourquoi devriez-vous vous soucier du budget d’exploration?
- Quel est le budget d’exploration pour mon site Web?
- Budget d’analyse dans la console de recherche Google
- Allez à la source: journaux du serveur
- Comment optimisez-vous votre budget crawl ?
- URL accessibles avec des paramètres
- Contenu en double
- Contenu de mauvaise qualité
- Liens brisés et de redirection
- URL incorrectes dans les sitemaps XML
- ContentKing
- Pages avec des temps de chargement / délais d’attente élevés
- Nombre élevé de pages non indexables
- Mauvaise structure de liens internes
- Comment augmentez-vous le budget d’exploration de votre site Web?
- Foire aux questions sur le budget crawl
- 1. budget Qu’est-ce que le budget crawl ?
- 2. How Comment puis-je augmenter mon budget d’exploration ?
- 3. What Qu’est-ce qui peut limiter mon budget d’exploration ?
- 4. Should Devrais-je utiliser des robots URL et méta canoniques ?
Qu’est-ce que le budget crawl ?
Le budget d’analyse est le nombre de pages que les moteurs de recherche exploreront sur un site Web dans un certain délai.
Pourquoi les moteurs de recherche attribuent-ils un budget d’exploration aux sites Web?
Parce qu’ils n’ont pas de ressources illimitées et qu’ils répartissent leur attention sur des millions de sites Web. Ils ont donc besoin d’un moyen de prioriser leur effort d’exploration. L’attribution d’un budget d’exploration à chaque site Web les aide à le faire.
Comment attribuent-ils le budget d’analyse aux sites Web?
Cela est basé sur deux facteurs, la limite d’exploration et la demande d’exploration:
- Limite d’exploration / charge de l’hôte: quelle quantité d’exploration un site Web peut-il gérer et quelles sont les préférences de son propriétaire?
- Demande d’exploration / planification d’exploration : quelles URL valent le plus la peine de (re)explorer, en fonction de sa popularité et de la fréquence à laquelle elles sont mises à jour.
Le budget d’exploration est un terme courant dans le référencement. Le budget d’exploration est parfois également appelé espace d’exploration ou temps d’exploration.

Le budget d’exploration ne concerne-t-il que les pages?
Ce n’est pas en fait, par souci de facilité, nous parlons de pages, mais en réalité, il s’agit de n’importe quel document que les moteurs de recherche explorent. Quelques exemples d’autres documents : fichiers JavaScript et CSS, variantes de pages mobiles, variantes hreflang et fichiers PDF.
Comment fonctionne la limite d’exploration / la charge de l’hôte dans la pratique?
La limite d’exploration, ou la charge de l’hôte si vous voulez, est une partie importante du budget d’exploration. Les robots d’exploration des moteurs de recherche sont conçus pour éviter de surcharger un serveur Web de requêtes, ils font donc attention à cela.Comment les moteurs de recherche déterminent la limite d’exploration d’un site Web? Il existe une variété de facteurs influençant la limite d’exploration. Pour n’en nommer que quelques-uns:
- Signes de plate-forme en mauvais état: à quelle fréquence les URL demandées expirent ou renvoient des erreurs de serveur.
- La quantité de sites Web en cours d’exécution sur l’hôte: si votre site Web fonctionne sur une plate-forme d’hébergement partagée avec des centaines d’autres sites Web et que vous avez un site Web assez volumineux, la limite d’exploration de votre site Web est très limitée car la limite d’exploration est déterminée au niveau de l’hôte. Vous devez partager la limite d’exploration de l’hôte avec tous les autres sites qui s’y exécutent. Dans ce cas, vous seriez bien mieux sur un serveur dédié, ce qui réduira très probablement également les temps de chargement de vos visiteurs.
Une autre chose à considérer est d’avoir des sites mobiles et de bureau distincts s’exécutant sur le même hôte. Ils ont également une limite d’exploration partagée. Alors gardez cela à l’esprit.
Les moteurs de recherche explorent-ils les parties les plus importantes de votre site Web? Faites un test rapide avec ContentKing!
Comment fonctionne la planification de la demande d’exploration / de l’exploration dans la pratique?
La demande d’exploration, ou la planification d’exploration, consiste à déterminer la valeur des URL de re-exploration. Encore une fois, de nombreux facteurs influencent la demande de crawl parmi lesquels:
- Popularité : le nombre de liens internes et externes entrants d’une URL, mais aussi la quantité de requêtes pour lesquelles elle se classe.
- Fraîcheur : à quelle fréquence l’URL est mise à jour.
- Type de page : est le type de page susceptible de changer. Prenez par exemple une page de catégorie de produits et une page de conditions générales – laquelle change le plus souvent et mérite d’être explorée plus fréquemment selon vous?

Forcer les robots d’exploration de Google à revenir sur votre site lorsqu’il n’y a rien de plus important à trouver (c’est-à-dire un changement significatif) n’est pas une bonne stratégie et ils sont assez intelligents pour déterminer si la fréquence de ces pages change réellement ajoute de la valeur. Le meilleur conseil que je pourrais donner est de me concentrer sur le fait de rendre les pages plus importantes (en ajoutant des informations plus utiles, en enrichissant le contenu des pages (elles déclencheront naturellement plus de requêtes par défaut tant que le focus d’un sujet est maintenu). En déclenchant naturellement plus de requêtes dans le cadre du « rappel » (impressions), vous rendez vos pages plus importantes et voilà: vous serez probablement plus fréquemment exploré.
N’oubliez pas: la capacité d’exploration du système lui-même
Alors que les systèmes d’exploration des moteurs de recherche ont une capacité d’exploration massive, à la fin de la journée, elle est limitée. Ainsi, dans un scénario où 80% des centres de données de Google se déconnectent en même temps, leur capacité d’analyse diminue massivement et, à son tour, le budget d’analyse de tous les sites Web.
Un grand merci à Dawn Anderson (ouvre dans un nouvel onglet) pour nous avoir fourni des détails sur la limite d’exploration, la demande d’exploration et la capacité d’exploration!
Pourquoi devriez-vous vous soucier du budget d’exploration?
Vous voulez que les moteurs de recherche trouvent et comprennent autant que possible vos pages indexables, et vous voulez qu’ils le fassent le plus rapidement possible. Lorsque vous ajoutez de nouvelles pages et mettez à jour celles qui existent déjà, vous souhaitez que les moteurs de recherche les récupèrent dès que possible. Plus tôt ils ont indexé les pages, plus tôt vous pourrez en bénéficier.
Si vous gaspillez votre budget d’exploration, les moteurs de recherche ne pourront pas analyser efficacement votre site Web. Ils passeront du temps sur des parties de votre site qui n’ont pas d’importance, ce qui peut entraîner des parties importantes de votre site Web non découvertes. S’ils ne connaissent pas les pages, ils ne les exploreront pas et ne les indexeront pas, et vous ne pourrez pas leur faire entrer des visiteurs via les moteurs de recherche.
Vous pouvez voir où cela mène: gaspiller le budget d’exploration nuit à vos performances SEO.
Veuillez noter que le budget d’exploration n’est généralement à craindre que si vous avez un grand site Web, disons 10 000 pages et plus.

L’un des aspects les plus sous-appréciés du budget d’exploration est la vitesse de charge. Un site Web à chargement plus rapide signifie que Google peut analyser plus d’URL dans le même laps de temps. Récemment, j’ai été impliqué dans une mise à niveau du site où la vitesse de charge était un objectif majeur. Le nouveau site s’est chargé deux fois plus vite que l’ancien. Lorsqu’il a été poussé en direct, le nombre d’URL explorées par Google par jour est passé de 150 000 à 600 000 – et y est resté. Pour un site de cette taille et de cette portée, le taux d’analyse amélioré signifie que le contenu nouveau et modifié est exploré beaucoup plus rapidement, et nous constatons un impact beaucoup plus rapide de nos efforts de référencement dans les SERPs.

Un SEO très sage (d’accord, c’était AJ Kohn (ouvre dans un nouvel onglet)) a dit un jour: « Vous êtes ce que mange Googlebot. ». Vos classements et votre visibilité de recherche sont directement liés non seulement à ce que Google explore sur votre site, mais aussi à la fréquence à laquelle ils l’explorent. Si Google manque de contenu sur votre site ou n’explore pas assez fréquemment les URL importantes en raison d’un budget d’exploration limité / non optimisé, vous aurez du mal à vous classer. Pour les sites plus grands, l’optimisation du budget d’exploration peut grandement améliorer le profil des pages auparavant invisibles. Alors que les sites plus petits doivent moins se soucier du budget d’exploration, les mêmes principes d’optimisation (vitesse, hiérarchisation, structure des liens, déduplication, etc.) peut toujours vous aider à vous classer.

Je suis surtout d’accord avec Google et pour la plupart, de nombreux sites Web n’ont pas à se soucier du budget d’exploration. Mais pour les sites Web de grande taille et en particulier ceux qui sont fréquemment mis à jour, tels que les éditeurs, l’optimisation peut faire une différence significative.
Quel est le budget d’exploration pour mon site Web?
De tous les moteurs de recherche, Google est le plus transparent quant à leur budget d’exploration pour votre site Web.
Budget d’analyse dans la console de recherche Google
Si votre site Web est vérifié dans la console de recherche Google, vous pouvez obtenir un aperçu du budget d’analyse de votre site Web pour Google.
Suivez ces étapes:
- Connectez-vous à Google Search Console et choisissez un site Web.
- Aller à
Crawl>Crawl Stats. Vous pouvez y voir le nombre de pages que Google explore par jour.
Pendant l’été 2016, notre budget crawl ressemblait à ceci:
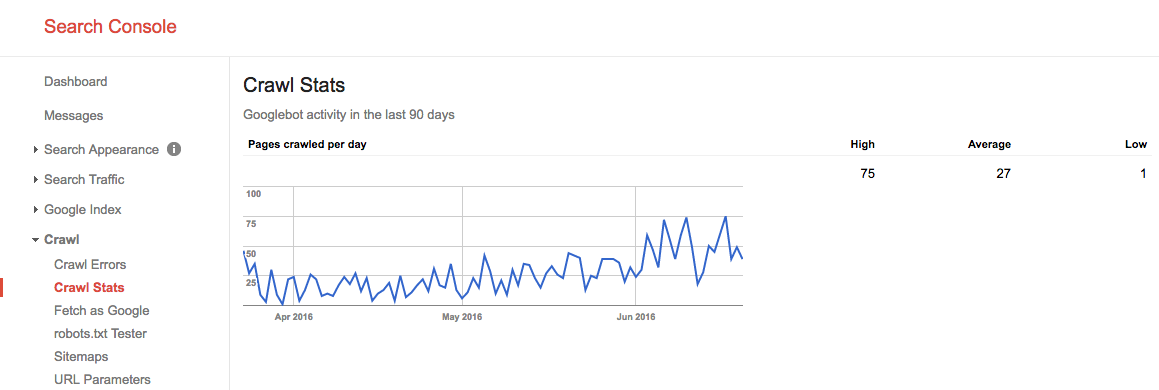
Nous voyons ici que le budget d’exploration moyen est de 27 pages/ jour. Donc, en théorie, si ce budget d’analyse moyen reste le même, vous auriez un budget d’analyse mensuel de 27 pages x 30 jours = 810 pages.
Avance rapide de 2 ans, et regardez quel est notre budget d’exploration en ce moment:
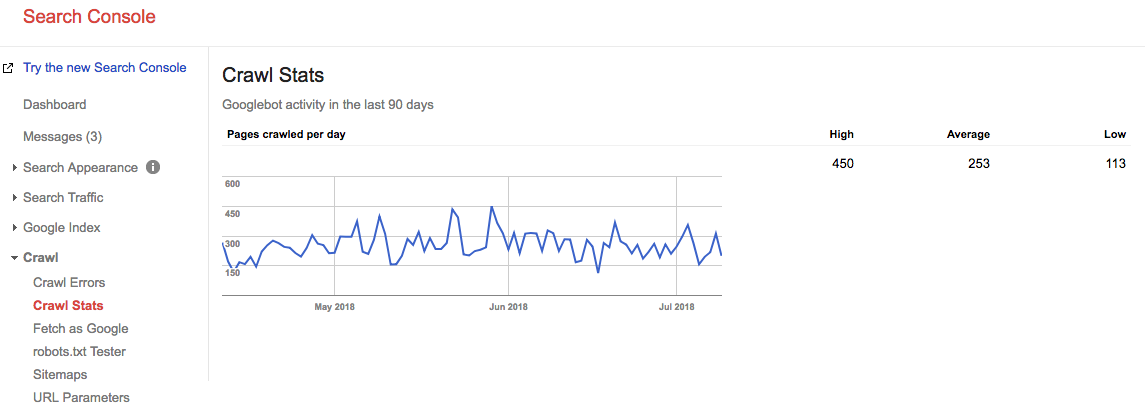
Notre budget d’exploration moyen est de 253 pages / jour, donc on peut dire que notre budget d’exploration a augmenté de 10 FOIS en 2 ans.
Allez à la source: journaux du serveur
Il est très intéressant de vérifier les journaux de votre serveur pour voir à quelle fréquence les robots d’exploration de Google visitent votre site Web. Il est intéressant de comparer ces statistiques à celles rapportées dans Google Search Console. Il est toujours préférable de s’appuyer sur plusieurs sources.
Ne laissez pas les problèmes d’exploration être une occasion manquée. Surveillez en permanence votre site avec ContentKing et soyez alerté des problèmes en temps réel.
Comment optimisez-vous votre budget crawl ?
Optimiser votre budget d’analyse revient à vous assurer qu’aucun budget d’analyse n’est gaspillé. Essentiellement, la fixation des raisons du budget d’exploration gaspillé. Nous surveillons des milliers de sites Web; si vous deviez vérifier chacun d’eux pour des problèmes de budget d’exploration, vous verriez rapidement un modèle: la plupart des sites Web souffrent du même genre de problèmes.
Raisons courantes du budget d’exploration gaspillé que nous rencontrons:
- URL accessibles avec paramètres : un exemple d’URL avec un paramètre est
https://www.example.com/toys/cars?color=black. Dans ce cas, le paramètre est utilisé pour stocker la sélection d’un visiteur dans un filtre de produit. - Contenu en double : nous appelons les pages très similaires, ou exactement les mêmes, » contenu en double. » Les exemples sont: pages copiées, pages de résultats de recherche internes et pages de balises.
- Contenu de mauvaise qualité : pages avec très peu de contenu, ou pages qui n’ajoutent aucune valeur.
- Liens brisés et de redirection: les liens brisés sont des liens faisant référence à des pages qui n’existent plus, et les liens redirigés sont des liens vers des URL qui redirigent vers d’autres URL.
- Y compris les URL incorrectes dans les sitemaps XML: les pages non indexables et les non-pages telles que les URL 3xx, 4xx et 5xx ne doivent pas être incluses dans votre sitemap XML.
- Pages avec des temps de chargement / temps morts élevés: les pages qui prennent beaucoup de temps à charger, ou qui ne se chargent pas du tout, ont un impact négatif sur votre budget d’analyse, car c’est un signe pour les moteurs de recherche que votre site Web ne peut pas gérer la demande, et qu’ils peuvent donc ajuster votre limite d’analyse.
- Nombre élevé de pages non indexables: le site Web contient beaucoup de pages qui ne sont pas indexables.
- Mauvaise structure de lien interne: si votre structure de lien interne n’est pas correctement configurée, les moteurs de recherche peuvent ne pas accorder suffisamment d’attention à certaines de vos pages.

J’ai souvent dit que Google est comme votre patron. Vous ne participeriez pas à une réunion avec votre patron à moins de savoir de quoi vous alliez parler, les points forts de votre travail, les objectifs de votre réunion. Bref, vous aurez un agenda. Lorsque vous entrez dans le « bureau » de Google, vous avez besoin de la même chose. Une hiérarchie de site claire sans beaucoup de brutalité, un plan de site XML utile et des temps de réponse rapides aideront Google à atteindre ce qui est important. Ne négligez pas cet élément souvent mal compris du référencement.

Pour moi, le concept de budget crawl est l’un des points clés du référencement technique. Lorsque vous optimisez le budget d’analyse, tout le reste se met en place: liaison interne, correction des erreurs, vitesse de la page, optimisation des URL, contenu de mauvaise qualité, etc. Les gens devraient creuser plus souvent dans leurs fichiers journaux pour surveiller le budget d’analyse pour des URL, des sous-domaines, des répertoires spécifiques, etc. La surveillance de la fréquence d’exploration est très liée au budget d’exploration et super puissante.
URL accessibles avec des paramètres
Dans la plupart des cas, les URL avec des paramètres ne devraient pas être accessibles pour les moteurs de recherche, car elles peuvent générer une quantité pratiquement infinie d’URL.Nous avons beaucoup écrit sur ce type de problème dans notre article sur les pièges à chenilles.
Les URL avec paramètres sont couramment utilisées lors de la mise en œuvre de filtres de produits sur les sites de commerce électronique. C’est bien de les utiliser, assurez-vous simplement qu’ils ne sont pas accessibles aux moteurs de recherche.
Comment pouvez-vous les rendre inaccessibles au moteur de recherche?
- Utilisez vos robots.fichier txt pour demander aux moteurs de recherche de ne pas accéder à ces URL. Si ce n’est pas une option pour une raison quelconque, utilisez les paramètres de gestion des paramètres d’URL de la Console de recherche Google et des outils pour les webmasters de Bing pour indiquer à Google et à Bing quelles pages ne doivent pas être explorées.
- Ajoutez la valeur de l’attribut nofollow aux liens sur les liens de filtre. Veuillez noter qu’à partir de mars 2020, Google peut choisir d’ignorer le nofollow. Par conséquent, l’étape 1 est encore plus importante.
Contenu en double
Vous ne voulez pas que les moteurs de recherche passent leur temps sur des pages de contenu en double, il est donc important d’empêcher, ou à tout le moins de minimiser, le contenu en double sur votre site.
Comment faites-vous cela? Par…
- Configuration des redirections de site Web pour toutes les variantes de domaine (
HTTP,HTTPS,non-WWW, etWWW). - Rendre les pages de résultats de recherche internes inaccessibles aux moteurs de recherche utilisant vos robots.txt. Voici un exemple de robots.txt pour un site web WordPress.
- Désactivation des pages dédiées aux images (par exemple : les infâmes pages de pièces jointes d’images dans WordPress).
- Attention à l’utilisation des taxonomies telles que les catégories et les balises.
Découvrez quelques raisons plus techniques pour le contenu en double et comment les corriger.
Contenu de mauvaise qualité
Les pages avec très peu de contenu ne sont pas intéressantes pour les moteurs de recherche. Gardez-les au minimum ou évitez-les complètement si possible. Un exemple de contenu de mauvaise qualité est une section FAQ avec des liens pour afficher les questions et réponses, où chaque question et réponse est servie sur une URL distincte.
Liens brisés et de redirection
Les liens brisés et les longues chaînes de redirections sont des impasses pour les moteurs de recherche. Semblable aux navigateurs, Google semble suivre un maximum de cinq redirections enchaînées en une seule exploration (elles peuvent reprendre l’exploration plus tard). On ne sait pas dans quelle mesure les autres moteurs de recherche traitent les redirections ultérieures, mais nous vous conseillons vivement d’éviter entièrement les redirections enchaînées et de réduire au minimum l’utilisation des redirections.
Il est clair qu’en réparant les liens brisés et en redirigeant les liens, vous pouvez rapidement récupérer le budget d’exploration gaspillé. En plus de récupérer le budget d’exploration, vous améliorez également considérablement l’expérience utilisateur d’un visiteur. Les redirections, et les chaînes de redirections en particulier, allongent le temps de chargement des pages et nuisent ainsi à l’expérience utilisateur.
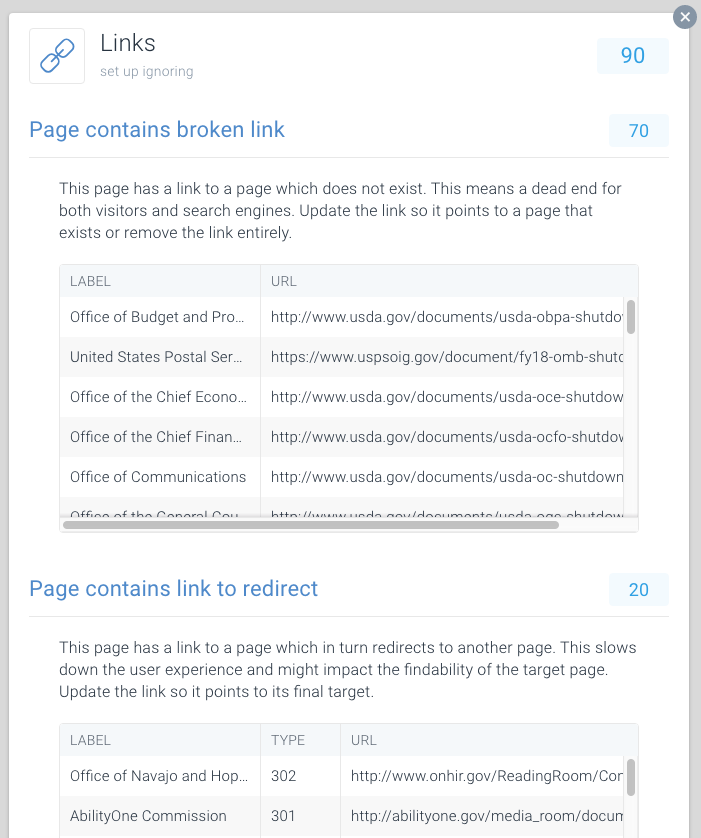
Pour faciliter la recherche de liens cassés et la redirection, nous avons consacré des numéros spéciaux à cela dans ContentKing.
Allez à Issues > Links pour savoir si vous gaspillez des budgets d’exploration à cause de liens défectueux. Mettez à jour chaque lien pour qu’il soit lié à une page indexable, ou supprimez le lien s’il n’est plus nécessaire.
URL incorrectes dans les sitemaps XML
Toutes les URL incluses dans les sitemaps XML doivent être pour des pages indexables. Surtout avec les grands sites Web, les moteurs de recherche s’appuient fortement sur les sitemaps XML pour trouver toutes vos pages. Si vos sitemaps XML sont encombrés de pages qui, par exemple, n’existent plus ou sont redirigées, vous gaspillez le budget d’analyse. Vérifiez régulièrement votre plan de site XML pour les URL non indexables qui n’y appartiennent pas. Vérifiez également le contraire: recherchez les pages qui sont incorrectement exclues du plan du site XML. Le sitemap XML est un excellent moyen d’aider les moteurs de recherche à dépenser judicieusement leur budget d’exploration.
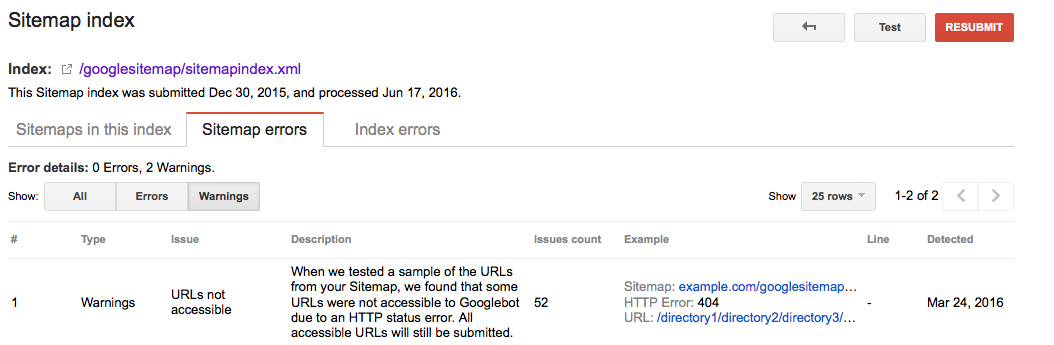
Console de recherche Google
- Connectez-vous à la Console de recherche Google
- Cliquez sur l’onglet
Crawl - Cliquez sur l’onglet
Sitemaps
Outils pour les webmasters Bing
- Connectez-vous à votre compte Bing Webmaster Tools
- Cliquez sur l’onglet
Configure My Site - Cliquez sur l’onglet
Sitemaps
ContentKing
- Connectez-vous à votre compte ContentKing
- Cliquez sur le bouton
Issues - Cliquez sur le bouton
XML Sitemap - En cas de problème avec votre page, vous recevrez ce message:
Page is incorrectly included in XML sitemap
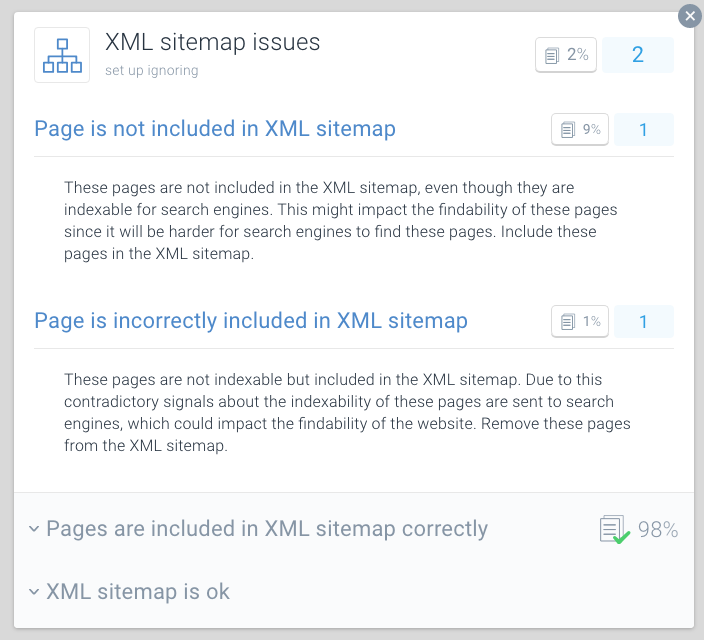
Une meilleure pratique pour l’optimisation du budget d’analyse consiste à diviser vos plans de site XML en plans de site plus petits. Vous pouvez par exemple créer des sitemaps XML pour chacune des sections de votre site Web. Si vous avez fait cela, vous pouvez rapidement déterminer s’il y a des problèmes dans certaines sections de votre site Web.
Disons que votre plan de site XML pour la section A contient 500 liens et que 480 sont indexés: alors vous vous en sortez plutôt bien. Mais si votre plan de site XML pour la section B contient 500 liens et que seuls 120 sont indexés, c’est quelque chose à examiner. Vous avez peut-être inclus de nombreuses URL non indexables dans le plan du site XML de la section B.
De mauvaises conditions pour les robots d’exploration peuvent nuire à votre référencement. Utilisez ContentKing pour effectuer un audit rapide de votre site Web.
Pages avec des temps de chargement / délais d’attente élevés

Lorsque les pages ont des temps de chargement élevés ou qu’elles s’arrêtent, les moteurs de recherche peuvent visiter moins de pages dans le budget d’analyse alloué à votre site Web. Outre cet inconvénient, les temps de chargement et les délais d’attente élevés nuisent considérablement à l’expérience utilisateur de votre visiteur, entraînant un taux de conversion plus faible.
Les temps de chargement des pages supérieurs à deux secondes sont un problème. Idéalement, votre page se chargera en moins d’une seconde. Vérifiez régulièrement les temps de chargement de votre page avec des outils tels que Pingdom (s’ouvre dans un nouvel onglet), WebPagetest (s’ouvre dans un nouvel onglet) ou GTMetrix (s’ouvre dans un nouvel onglet).
Rapports Google sur le temps de chargement des pages dans les deux Google Analytics (sous Behavior > Site Speed) et la console de recherche Google sous Crawl > Crawl Stats.
Les outils Google Search Console et Bing Webmaster signalent tous deux les délais d’expiration des pages. Dans la console de recherche Google, cela peut être trouvé sous Crawl > Crawl Errors, et dans Bing Webmaster Tools, c’est sous Reports & Data > Crawl Information.
Vérifiez régulièrement si vos pages se chargent suffisamment rapidement et agissez immédiatement si ce n’est pas le cas. Le chargement rapide des pages est essentiel à votre succès en ligne.
Nombre élevé de pages non indexables
Si votre site Web contient un nombre élevé de pages non indexables accessibles aux moteurs de recherche, vous gardez les moteurs de recherche occupés à passer au crible les pages non pertinentes.
Nous considérons les types suivants comme des pages non indexables:
- Redirige (3xx)
- Pages introuvables (4xx)
- Pages avec des erreurs de serveur (5xx)
- Pages non indexables (pages contenant la directive robots noindex ou l’URL canonique)
Afin de savoir si vous avez un nombre élevé de pages non indexables, recherchez le nombre total de pages que les robots d’exploration ont trouvées sur votre site Web et comment elles se décomposent. Vous pouvez facilement le faire en utilisant ContentKing:
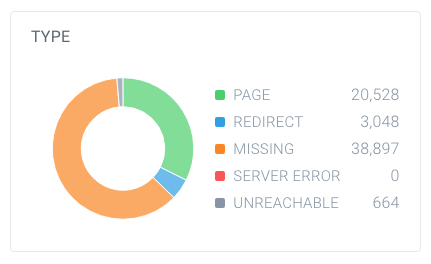
Dans cet exemple, il y a 63 137 URL trouvées, dont seulement 20 528 sont des pages.
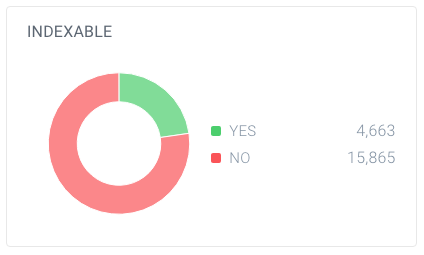
Et sur ces pages, seules 4 663 sont indexables pour les moteurs de recherche. Seulement 7,4% des URL trouvées par ContentKing peuvent être indexées par les moteurs de recherche. Ce n’est pas un bon ratio, et ce site Web doit absolument y travailler en nettoyant toutes les références inutiles, y compris:
- Le plan du site XML (voir section précédente)
- Liens
- URL canoniques
- Références Hreflang
- Références de pagination (lien rel précédent / suivant)
Mauvaise structure de liens internes
La façon dont les pages de votre site Web se lient les unes aux autres joue un rôle important dans l’optimisation du budget d’analyse. Nous appelons cela la structure de liens internes de votre site Web. Les Backlinks mis à part, les pages qui ont peu de liens internes attirent beaucoup moins l’attention des moteurs de recherche que les pages auxquelles sont liés de nombreuses pages.
Évitez une structure de liens très hiérarchisée, les pages du milieu ayant peu de liens. Dans de nombreux cas, ces pages ne seront pas fréquemment explorées. C’est encore pire pour les pages en bas de la hiérarchie: en raison de leur nombre limité de liens, elles peuvent très bien être négligées par les moteurs de recherche.
Assurez-vous que vos pages les plus importantes contiennent de nombreux liens internes. Les pages récemment explorées se classent généralement mieux dans les moteurs de recherche. Gardez cela à l’esprit et ajustez votre structure de lien interne pour cela.
Par exemple, si vous avez un article de blog datant de 2011 qui génère beaucoup de trafic organique, assurez-vous de continuer à le lier à partir d’autres contenus. Parce que vous avez produit de nombreux autres articles de blog au fil des ans, cet article de 2011 est automatiquement poussé vers le bas dans la structure de liens internes de votre site Web.

Vous n’avez généralement pas à vous soucier du taux d’exploration de vos pages importantes. Ce sont généralement des pages qui sont nouvelles, auxquelles vous n’avez pas de lien, et que les gens n’y vont pas qui ne sont peut-être pas souvent explorées.
Comment augmentez-vous le budget d’exploration de votre site Web?
Lors d’une interview (s’ouvre dans un nouvel onglet) entre Eric Enge et Matt Cutts, ancien responsable de l’équipe webspam de Google, la relation entre autorité et budget d’exploration a été évoquée:

La meilleure façon d’y penser est que le nombre de pages que nous explorons est à peu près proportionnel à votre PageRank. Donc, si vous avez beaucoup de liens entrants sur votre page racine, nous allons certainement explorer cela. Ensuite, votre page racine peut être liée à d’autres pages, et celles-ci obtiendront un PageRank et nous les explorerons également. Cependant, à mesure que vous approfondissez de plus en plus votre site, le PageRank a tendance à décliner.
Même si Google a abandonné la mise à jour publique des valeurs de PageRank des pages, nous pensons que (une forme de) PageRank est toujours utilisé dans leurs algorithmes. Puisque PageRank est un terme mal compris et confus, appelons-le autorité de page. Le point à retenir ici est que Matt Cutts dit en gros: il y a une relation assez forte entre l’autorité de la page et le budget d’exploration.
Ainsi, afin d’augmenter le budget d’exploration de votre site Web, vous devez augmenter l’autorité de votre site Web. Une grande partie de cela se fait en gagnant plus de liens à partir de sites Web externes. Vous trouverez plus d’informations à ce sujet dans notre guide de création de liens.

Lorsque j’entends l’industrie parler du budget de l’analyse, nous parlons généralement des modifications techniques et techniques que nous pouvons apporter afin d’augmenter le budget de l’analyse au fil du temps. Cependant, venant d’un contexte de création de liens, les plus grandes pointes de pages explorées que nous voyons dans la console de recherche Google se rapportent directement au moment où nous gagnons de gros liens pour nos clients.
Foire aux questions sur le budget crawl
- 🧾 Qu’est-ce que le budget crawl?
- How Comment puis-je augmenter mon budget d’exploration ?
- ️️ Qu’est-ce qui peut limiter mon budget d’exploration ?
- Should Devrais-je utiliser des robots URL et méta canoniques?
1. budget Qu’est-ce que le budget crawl ?
Le budget d’analyse est le nombre de pages que les moteurs de recherche exploreront sur un site Web dans un certain délai.
2. How Comment puis-je augmenter mon budget d’exploration ?
Google a indiqué qu’il existe une forte relation entre l’autorité de la page et le budget d’exploration. Plus une page a d’autorité, plus elle dispose d’un budget d’exploration. En termes simples, pour augmenter votre budget d’analyse, construisez l’autorité de votre page.
3. What Qu’est-ce qui peut limiter mon budget d’exploration ?
La limite d’exploration, également appelée charge d’hôte d’exploration, est basée sur de nombreux facteurs, tels que l’état du site Web et les capacités d’hébergement. Les robots d’exploration des moteurs de recherche sont configurés pour éviter de surcharger un serveur Web. Si votre site Web renvoie des erreurs de serveur ou si les URL demandées expirent souvent, le budget d’analyse sera plus limité. De même, si votre site Web fonctionne sur une plate-forme d’hébergement partagé, la limite d’analyse sera plus élevée car vous devrez partager votre budget d’analyse avec d’autres sites Web fonctionnant sur l’hébergement.
4. Should Devrais-je utiliser des robots URL et méta canoniques ?
Oui, et il est important de comprendre les différences entre les problèmes d’indexation et les problèmes d’analyse.
Les balises URL canoniques et méta robots envoient un signal clair aux moteurs de recherche sur la page qu’ils doivent afficher dans leur index, mais cela ne les empêche pas d’explorer ces autres pages.
Vous pouvez utiliser les robots.fichier txt et la relation de lien nofollow pour traiter les problèmes d’analyse.