- Qu’est-ce que la Surveillance Réseau ?
- Comment Fonctionne La Surveillance Du Réseau ?Les réseaux
- Surveillance du matériel réseau
- Comment surveiller le matériel réseau
- Surveillance du trafic réseau en direct
- Couche d’application (Couche 7)
- Couche de transport (Couche 4)
- Comment surveiller le trafic réseau en direct
- Surveillance du réseau par rapport à la gestion du réseau
- Avantages de la surveillance du réseau
- Principaux cas d’utilisation pour la surveillance du réseau
- Défis de la surveillance du réseau
- Outils de surveillance réseau
Qu’est-ce que la Surveillance Réseau ?
La surveillance réseau suit la santé d’un réseau à travers ses couches matérielles et logicielles. Les ingénieurs utilisent la surveillance du réseau pour prévenir et dépanner les pannes et les pannes du réseau. Dans cet article, nous décrirons le fonctionnement de la surveillance du réseau, ses principaux cas d’utilisation, les défis typiques liés à une surveillance efficace du réseau et les principales fonctionnalités à rechercher dans un outil de surveillance du réseau.

Comment Fonctionne La Surveillance Du Réseau ?Les réseaux
permettent le transfert d’informations entre deux systèmes, y compris entre deux ordinateurs ou applications. Le modèle OSI (Open Systems Interconnection) décompose plusieurs fonctions sur lesquelles les systèmes informatiques s’appuient pour envoyer et recevoir des données. Pour que les données soient envoyées sur un réseau, elles passeront par chaque composant de l’OSI, en utilisant différents protocoles, commençant à la couche physique et se terminant à la couche application. La surveillance du réseau offre une visibilité sur les différents composants qui composent un réseau, garantissant ainsi que les ingénieurs peuvent résoudre les problèmes de réseau à n’importe quelle couche dans laquelle ils se produisent.
Surveillance du matériel réseau
Les entreprises qui exécutent des charges de travail sur site ou gèrent des centres de données doivent s’assurer que le matériel physique à travers lequel circule le trafic réseau est sain et opérationnel. Cela comprend généralement les couches physique, liaison de données et réseau du modèle OSI (couches 1, 2 et 3). Dans cette approche de surveillance centrée sur les périphériques, les entreprises surveillent les composants pour la transmission des données, tels que le câblage, et les périphériques réseau tels que les routeurs, les commutateurs et les pare-feu. Un périphérique réseau peut avoir plusieurs interfaces qui le connectent à d’autres périphériques, et des pannes de réseau peuvent survenir à n’importe quelle interface.
Comment surveiller le matériel réseau
La plupart des périphériques réseau sont équipés de la prise en charge de la norme SNMP (Simple Network Management Protocol). Via SNMP, vous pouvez surveiller le trafic réseau entrant et sortant et d’autres télémesures réseau importantes critiques pour assurer la santé et les performances des équipements sur site.
Le protocole Internet (IP) est une norme utilisée sur presque tous les réseaux pour fournir un système d’adresse et de routage pour les périphériques. Ce protocole permet d’acheminer les informations vers la bonne destination sur de grands réseaux, y compris l’Internet public.
Les ingénieurs et administrateurs réseau utilisent généralement des outils de surveillance réseau pour collecter les types de métriques suivants à partir des périphériques réseau:
-
Temps de disponibilité
Durée pendant laquelle un périphérique réseau envoie et reçoit des données avec succès.
-
Utilisation du processeur
Mesure dans laquelle un périphérique réseau a utilisé sa capacité de calcul pour traiter les entrées, stocker des données et créer des sorties.
-
Utilisation de la bande passante
Quantité de données, en octets, actuellement envoyées ou reçues par une interface réseau spécifique. Les ingénieurs suivent à la fois le volume de trafic envoyé et le pourcentage de bande passante totale utilisé.
-
Débit
Débit de trafic, en octets par seconde, passant par une interface sur un périphérique pendant une période de temps spécifique. Les ingénieurs suivent généralement le débit d’une seule interface et la somme du débit de toutes les interfaces sur un seul périphérique.
-
Erreurs/rejets d’interface
Il s’agit d’erreurs sur le périphérique de réception qui provoquent l’abandon d’un paquet de données par une interface réseau. Les erreurs d’interface et les rejets peuvent provenir d’erreurs de configuration, de problèmes de bande passante ou d’autres raisons.
-
Métriques IP
Les métriques IP, telles que la temporisation et le nombre de sauts, peuvent mesurer la vitesse et l’efficacité des connexions entre les périphériques.
Notez que dans les environnements cloud, les entreprises achètent des ressources de calcul et de réseau auprès de fournisseurs de cloud qui gèrent l’infrastructure physique qui exécutera leurs services ou applications. L’hébergement en nuage transfère donc la responsabilité de la gestion du matériel physique au fournisseur de cloud.
Surveillance du trafic réseau en direct
Au-dessus des couches matérielles du réseau, des couches logicielles de la pile réseau sont également impliquées chaque fois que des données sont envoyées sur un réseau. Cela concerne principalement les couches de transport et d’application du modèle OSI (couche 4 et couche 7). La surveillance de ces couches aide les équipes à suivre la santé des services, des applications et des dépendances réseau sous-jacentes lorsqu’elles communiquent sur un réseau. Les protocoles réseau suivants sont particulièrement importants à surveiller car ils sont à la base de la plupart des communications réseau:
Couche d’application (Couche 7)
-
Protocole de transfert hypertexte (HTTP)
Protocole utilisé par les clients (généralement les navigateurs Web) pour communiquer avec les serveurs Web. Les métriques HTTP principales incluent le volume des requêtes, les erreurs et la latence. HTTPS est une version plus sécurisée et cryptée de HTTP.
-
Domain Name System (DNS)
Le protocole qui traduit les noms d’ordinateurs (tels que « server1.example.com « ) aux adresses IP grâce à l’utilisation de divers serveurs de noms. Les métriques DNS incluent le volume des demandes, les erreurs, le temps de réponse et les délais d’attente.
Couche de transport (Couche 4)
-
Protocole Internet (IP) – Protocole TCP (Transmission Control Protocol)
Protocole qui séquence les paquets dans le bon ordre et délivre les paquets à l’adresse IP de destination. Les métriques TCP à surveiller peuvent inclure les paquets délivrés, le taux de transmission, la latence, les retransmissions et la gigue.
-
Protocole UDP (User Datagram Protocol)
UDP est un autre protocole de transport de données. Il offre des vitesses de transmission plus rapides, mais sans fonctionnalités avancées telles que la livraison garantie ou le séquençage des paquets.
Comment surveiller le trafic réseau en direct
Les applications de surveillance réseau peuvent s’appuyer sur une variété de méthodes pour surveiller ces protocoles de communication, y compris des technologies plus récentes telles que le filtre de paquets Berkeley étendu (eBPF). Avec une surcharge minimale, eBPF suit les paquets de données réseau lorsqu’ils circulent entre les dépendances de votre environnement et traduit les données dans un format lisible par l’homme.
Surveillance du réseau par rapport à la gestion du réseau
La surveillance du réseau suit la santé d’un réseau à travers ses couches matérielles et logicielles. Les ingénieurs utilisent la surveillance du réseau pour prévenir et dépanner les pannes et les pannes du réseau. Dans cet article, nous décrirons le fonctionnement de la surveillance du réseau, ses principaux cas d’utilisation, les défis typiques liés à une surveillance efficace du réseau et les principales fonctionnalités à rechercher dans un outil de surveillance du réseau.
Visibilité De Bout En Bout Sur Votre Réseau Cloud Sur Site &
Avantages de la surveillance du réseau
Les pannes de réseau peuvent entraîner des perturbations majeures de l’activité, et dans les réseaux distribués complexes, il est essentiel d’avoir une visibilité complète afin de comprendre et de résoudre les problèmes. Par exemple, un problème de connectivité dans une seule région ou zone de disponibilité peut avoir un impact considérable sur l’ensemble d’un service si des requêtes interrégionales sont abandonnées.
Un avantage commun de la surveillance des périphériques réseau est qu’elle aide à prévenir ou à minimiser les pannes ayant un impact sur l’activité. Les outils de surveillance réseau peuvent collecter périodiquement des informations sur les appareils pour s’assurer qu’ils sont disponibles et fonctionnent comme prévu, et peuvent vous alerter s’ils ne le sont pas. Si un problème survient sur un périphérique, tel qu’une saturation élevée sur une interface spécifique, les ingénieurs réseau peuvent agir rapidement pour éviter une panne ou tout impact sur l’utilisateur. Par exemple, les équipes peuvent implémenter l’équilibrage de charge pour répartir le trafic sur plusieurs serveurs si la surveillance révèle qu’un seul hôte n’est pas suffisant pour traiter le volume de demandes.
Un autre avantage de la surveillance du réseau est qu’elle peut aider les entreprises à améliorer les performances des applications. Par exemple, la perte de paquets réseau peut se manifester par une latence d’application face à l’utilisateur. Grâce à la surveillance du réseau, les ingénieurs peuvent identifier exactement où se produit la perte de paquets et remédier au problème. La surveillance des données réseau aide également les entreprises à réduire les coûts de trafic liés au réseau en mettant en évidence des modèles de trafic interrégional inefficaces. Enfin, les ingénieurs peuvent également utiliser la surveillance du réseau pour vérifier si leurs applications peuvent atteindre les serveurs DNS, sans lesquels les sites Web ne se chargeront pas correctement pour les utilisateurs.
Les outils de surveillance modernes peuvent unifier les données réseau avec des métriques d’infrastructure, des métriques d’application et d’autres métriques, permettant à tous les ingénieurs d’une organisation d’accéder aux mêmes informations lors du diagnostic et du dépannage des problèmes. Cette capacité à consolider les données de surveillance permet aux équipes de déterminer facilement si la latence ou les erreurs proviennent du réseau, du code, d’un problème au niveau de l’hôte ou d’une autre source.
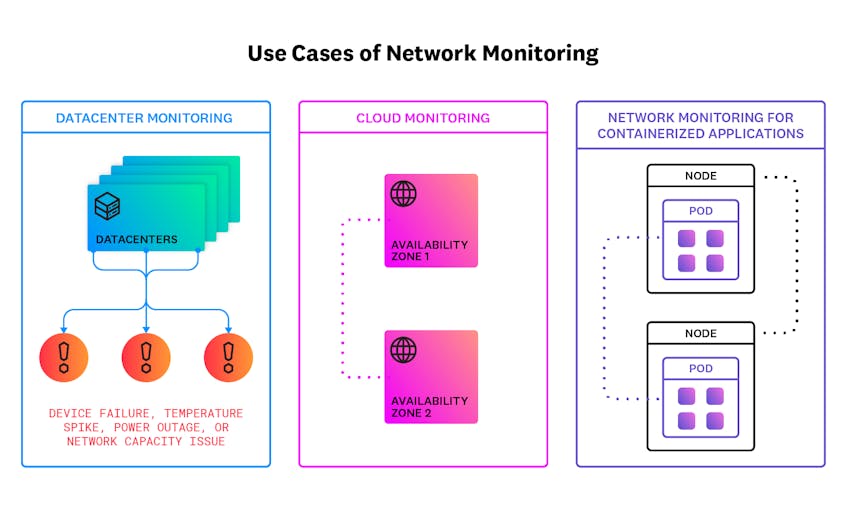
Principaux cas d’utilisation pour la surveillance du réseau
Certains cas d’utilisation spécifiques pour la surveillance du réseau sont les suivants:
-
Surveillance des centres de données
Les ingénieurs réseau peuvent utiliser la surveillance du réseau pour collecter des données en temps réel à partir de leurs centres de données et configurer des alertes lorsqu’un problème apparaît, tel qu’une panne de périphérique, un pic de température, une panne de courant ou un problème de capacité du réseau.
-
Surveillance du réseau Cloud
Les entreprises qui hébergent des services sur des réseaux cloud peuvent utiliser un outil de surveillance du réseau pour s’assurer que les dépendances des applications communiquent bien entre elles. Les ingénieurs peuvent également utiliser la surveillance du réseau pour aider à comprendre les coûts du réseau cloud, en analysant la quantité de trafic qui passe entre les régions ou la quantité de trafic traitée par différents fournisseurs de cloud.
-
Surveillance du réseau pour les applications conteneurisées
Les conteneurs permettent aux équipes d’empaqueter et de livrer des applications sur plusieurs systèmes d’exploitation. Les ingénieurs utilisent souvent des systèmes d’orchestration de conteneurs tels que Kubernetes pour créer des applications distribuées évolutives. Que leurs applications conteneurisées s’exécutent sur site ou dans le cloud, les équipes peuvent utiliser la surveillance du réseau pour s’assurer que les différents composants de l’application communiquent correctement entre eux.
Les entreprises qui adoptent une approche hybride dans l’hébergement de leurs services peuvent utiliser la surveillance du réseau de chacune de ces manières. Dans une approche hybride, certaines charges de travail dépendent de centres de données gérés en interne, tandis que d’autres sont externalisées vers le cloud. Dans ce cas, un outil de surveillance de réseau peut être utilisé pour obtenir une vue unifiée des métriques de réseau sur site et dans le cloud, ainsi que de la santé des données circulant entre les deux environnements. Il est courant d’utiliser une approche hybride lorsqu’une organisation est en train de migrer vers le cloud.
Défis de la surveillance du réseau
Les réseaux modernes sont incroyablement grands et complexes, transmettant des millions de paquets chaque seconde. Afin de résoudre les problèmes sur un réseau, les ingénieurs utilisent traditionnellement les journaux de flux pour étudier le trafic entre deux adresses IP, se connecter manuellement aux serveurs via un accès sécurisé au Shell (SSH) ou accéder à distance à l’équipement réseau pour exécuter des diagnostics. Aucun de ces processus ne fonctionne bien à grande échelle, ne fournit des heuristiques de santé de réseau limitées et ne contient pas de données contextuelles provenant d’applications et d’infrastructures susceptibles de mettre en lumière la cause profonde des problèmes de réseau potentiels.
Les ingénieurs sont également confrontés à des défis en matière de surveillance du réseau lorsque les entreprises passent au cloud. La complexité du réseau augmente car les charges de travail dans le cloud et leur infrastructure sous-jacente sont de nature dynamique et éphémère. Des instances cloud de courte durée peuvent apparaître et disparaître en fonction de l’évolution de la demande des utilisateurs. À mesure que ces instances de cloud tournent de haut en bas, leurs adresses IP changent également, ce qui rend difficile le suivi des connexions réseau en utilisant uniquement des données de connexion IP à IP. De nombreux outils de surveillance ne vous permettent pas de surveiller les connexions réseau entre des entités significatives telles que des services ou des pods. De plus, étant donné que le fournisseur de cloud fournit l’infrastructure réseau, les problèmes de réseau sont souvent hors du contrôle du client, ce qui oblige les charges de travail à être déplacées vers une zone ou une région de disponibilité différente pour éviter les problèmes jusqu’à ce qu’ils soient résolus.
Outils de surveillance réseau
Les solutions SaaS (Software-as-a-service), telles que Datadog, éliminent les silos entre les équipes d’ingénierie et apportent une approche holistique de la surveillance réseau. Les produits de surveillance réseau de Datadog unifient les données réseau avec les données d’infrastructure, d’application et d’expérience utilisateur dans un seul panneau de verre.
La surveillance des périphériques réseau (NDM) détecte automatiquement les périphériques d’un large éventail de fournisseurs et vous permet d’explorer la santé de chaque périphérique. Vous pouvez même surveiller de manière proactive l’état de l’appareil avec des moniteurs de détection d’anomalies pour l’utilisation de la bande passante et d’autres mesures.
La surveillance des performances réseau (NPM) offre une visibilité sur le reste de votre pile réseau et analyse le trafic en temps réel lorsqu’il circule dans votre environnement. Les équipes peuvent surveiller la communication entre les services, les hôtes, les pods Kubernetes et tout autre point de terminaison significatif, et pas seulement les données de connexion IP. Et en associant les métriques réseau à d’autres métriques et données de télémétrie, les équipes disposent d’un contexte riche pour identifier et résoudre tout problème de performance, où que ce soit dans leur pile.
Pour obtenir des informations supplémentaires du point de vue des utilisateurs finaux, vous pouvez utiliser la surveillance synthétique Datadog. Les tests synthétiques vous permettent de déterminer les performances de vos API et pages Web à différents niveaux de réseau (DNS, HTTP, ICMP, SSL, TCP). Datadog vous alerte en cas de comportement défectueux, tel qu’un temps de réponse élevé, un code d’état inattendu ou une fonctionnalité cassée.