
Sursa: supraîncărcați-vă modelele de viziune pe Computer cu API-ul TensorFlow Object Detection,
Jonathan Huang, cercetător științific și Vivek Rathod, inginer Software,
Google ai Blog
- detectarea obiectelor ca sarcină în viziunea computerizată
- YOLO ca detector de obiecte în timp real
- ce este YOLO?
- YOLO comparativ cu alți detectori
- versiunile lui YOLO
- Exemple de aplicații YOLO
- YOLO ca detector de obiecte în TensorFlow & Keras
- TensorFlow & cadrele Keras în învățarea mașinilor
- implementarea YOLO în TensorFlow & Keras
- cum să rulați Yolo pre-instruit în afara casetei și să obțineți rezultate
- cum să vă antrenați modelul personalizat de detectare a obiectelor YOLO
- declarație de sarcină
- set de date & adnotări
- unde să obțineți date de la
- cum să adnotați datele pentru YOLO
- cum se transformă datele din alte formate în Yolo
- împărțirea datelor în subseturi
- crearea de generatoare de date
- instalare & configurare necesară pentru formarea modelului
- model de formare
- cerințe preliminare
- inițializarea obiectului modelului
- definirea callback
- montarea modelului
- model personalizat instruit în modul inferență
- concluzii
- Anton Morgunov
- TensorFlow Object Detection API: cele mai bune practici pentru instruire, evaluare & implementare
detectarea obiectelor ca sarcină în viziunea computerizată
întâlnim obiecte în fiecare zi din viața noastră. Uită-te în jur și vei găsi mai multe obiecte care te înconjoară. Ca ființă umană, puteți detecta și identifica cu ușurință fiecare obiect pe care îl vedeți. Este natural și nu necesită mult efort.
pentru computere, totuși, detectarea obiectelor este o sarcină care necesită o soluție complexă. Pentru ca un computer să” detecteze obiecte ” înseamnă să proceseze o imagine de intrare (sau un singur cadru dintr-un videoclip) și să răspundă cu informații despre obiectele din imagine și poziția lor. În termeni de viziune computerizată, numim aceste două sarcini clasificare și localizare. Vrem ca computerul să spună ce fel de obiecte sunt prezentate pe o anumită imagine și unde se află exact.
au fost dezvoltate mai multe soluții pentru a ajuta computerele să detecteze obiecte. Astăzi, vom explora un algoritm de ultimă generație numit YOLO, care obține o precizie ridicată la viteză în timp real. În special, vom învăța cum să instruim acest algoritm pe un set de date personalizat în TensorFlow / Keras.
în primul rând, să vedem ce este exact YOLO și pentru ce este faimos.
YOLO ca detector de obiecte în timp real
ce este YOLO?
YOLO este un acronim pentru „you Only Look Once” (nu-l confunda cu You Only Live Once from The Simpsons). După cum sugerează și numele, un singur „aspect” este suficient pentru a găsi toate obiectele de pe o imagine și a le identifica.
în termeni de învățare automată, putem spune că toate obiectele sunt detectate printr-un singur algoritm rulat. Se face prin împărțirea unei imagini într-o grilă și prezicerea cutii de încadrare și probabilități de clasă pentru fiecare celulă într-o grilă. În cazul în care am dori să angajăm YOLO pentru detectarea mașinii, iată cum ar putea arăta grila și casetele de delimitare prevăzute:

caseta de delimitare pe care Yolo o prezice pentru prima mașină este în roșu.
caseta de delimitare pe care Yolo o prezice pentru a doua mașină este galbenă.
sursa imaginii.
imaginea de mai sus conține numai setul final de cutii obținute după filtrare. Este demn de remarcat faptul că producția brută a lui YOLO conține multe cutii de încadrare pentru același obiect. Aceste cutii diferă în formă și dimensiune. După cum puteți vedea în imaginea de mai jos, unele casete sunt mai bune la captarea obiectului țintă, în timp ce altele oferite de un algoritm au performanțe slabe.

toate cutiile galbene sunt pentru a doua mașină.
cutiile roșii și galbene îndrăznețe sunt cele mai bune pentru detectarea mașinii.
sursa imaginii.
pentru a selecta cea mai bună casetă de încadrare pentru un obiect dat, se aplică un algoritm de suprimare non-maximă (NMS).

prezise pentru ca mașinile să păstreze doar cele care captează cel mai bine obiectele.
sursa imaginii.
toate casetele pe care Yolo le prezice au un nivel de încredere asociat cu acestea. NMS utilizează aceste valori de încredere pentru a elimina casetele care au fost prezise cu certitudine scăzută. De obicei, acestea sunt toate casetele care sunt prezise cu încredere sub 0,5.

puteți vedea scorurile de încredere în colțul din stânga sus al fiecărei casete, lângă numele obiectului.
sursa imaginii.
când toate casetele de încadrare incerte sunt eliminate, sunt lăsate doar casetele cu un nivel ridicat de încredere. Pentru a-l selecta pe cel mai bun dintre candidații cu cele mai bune performanțe, NMS selectează caseta cu cel mai înalt nivel de încredere și calculează modul în care se intersectează cu celelalte casete din jur. Dacă o intersecție este mai mare decât un anumit nivel de prag, caseta de delimitare cu încredere mai mică este eliminată. În cazul în care NMS compară două casete care au o intersecție sub un prag selectat, ambele casete sunt păstrate în predicțiile finale.
YOLO comparativ cu alți detectori
deși o rețea neurală convoluțională (CNN) este utilizată sub capota lui YOLO, este încă capabilă să detecteze obiecte cu performanțe în timp real. Este posibil datorită capacității lui YOLO de a face predicțiile simultan într-o abordare cu o singură etapă.
alți algoritmi mai lenți pentru detectarea obiectelor (cum ar fi R-CNN mai rapid) folosesc de obicei o abordare în două etape:
- în prima etapă, sunt selectate regiuni de imagine interesante. Acestea sunt părțile unei imagini care ar putea conține orice obiecte;
- în a doua etapă, fiecare dintre aceste regiuni este clasificată folosind o rețea neuronală convoluțională.
de obicei, există multe regiuni pe o imagine cu obiectele. Toate aceste regiuni sunt trimise la clasificare. Clasificarea este o operație consumatoare de timp, motiv pentru care abordarea de detectare a obiectelor în două etape funcționează mai lent în comparație cu detectarea într-o singură etapă.
YOLO nu selectează părțile interesante ale unei imagini, nu este nevoie de asta. În schimb, ea prezice cutii de încadrare și clase pentru întreaga imagine într-o singură trecere net înainte.
mai jos puteți vedea cât de rapid este YOLO în comparație cu alte detectoare populare.

SSD și YOLO sunt detectoare de obiecte într-o etapă, în timp ce Faster-RCNN
și R-FCN sunt detectoare de obiecte în două etape.
sursa imaginii.
versiunile lui YOLO
YOLO au fost introduse pentru prima dată în 2015 de Joseph Redmon în lucrarea sa de cercetare intitulată „you Only Look Once: Unified, real-Time Object Detection”.
de atunci, YOLO a evoluat foarte mult. În 2016, Joseph Redmon a descris a doua versiune YOLO în „YOLO9000: mai bine, mai rapid, mai puternic”.
aproximativ doi ani după a doua actualizare YOLO, Joseph a venit cu un alt upgrade net. Lucrarea sa, numită „YOLOv3: o îmbunătățire incrementală”, a atras atenția multor ingineri de calculatoare și a devenit populară în comunitatea de învățare automată.
în 2020, Joseph Redmon a decis să înceteze cercetarea viziunii computerizate, dar nu a împiedicat YOLO să fie dezvoltat de alții. În același an, o echipă de trei ingineri (Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao) a proiectat a patra versiune a lui YOLO, chiar mai rapidă și mai precisă decât înainte. Descoperirile lor sunt descrise în ” YOLOv4: Viteza optimă și precizia detectării obiectelor” hârtie pe care au publicat-o pe 23 aprilie 2020.
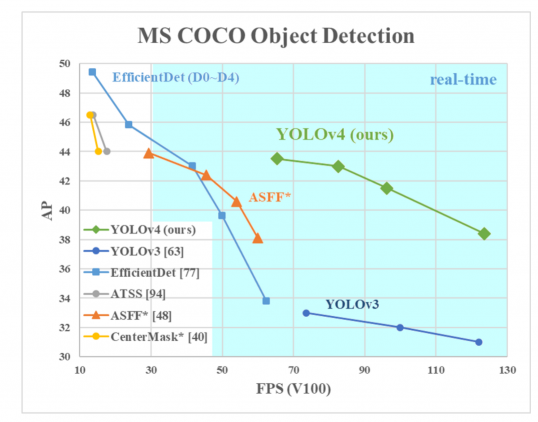
AP pe axa Y este o metrică numită „precizie medie”. Descrie exactitatea rețelei.
FPS (cadre pe secundă) pe axa X este o metrică care descrie viteza.
sursa imaginii.
la două luni de la lansarea celei de-a 4-A versiuni, un dezvoltator independent, Glenn Jocher, a anunțat cea de-a 5-a versiune a lui YOLO. De data aceasta, nu a fost publicată nicio lucrare de cercetare. Rețeaua a devenit disponibilă pe pagina Github a lui Jocher ca implementare PyTorch. A cincea versiune a avut aproape aceeași precizie ca a patra versiune, dar a fost mai rapidă.
în cele din urmă, în Iulie 2020 am primit o altă mare actualizare YOLO. Într-o lucrare intitulată „PP-YOLO: o implementare eficientă și eficientă a detectorului de obiecte”, Xiang Long și team au venit cu o nouă versiune a YOLO. Această iterație a YOLO s-a bazat pe versiunea modelului 3 și a depășit performanța YOLO v4.

harta de pe axa Y este o metrică numită „precizie medie medie”. Descrie exactitatea rețelei.
FPS (cadre pe secundă) pe axa X este o metrică care descrie viteza.
sursa imaginii.
în acest tutorial, vom avea o privire mai atentă la YOLOv4 și implementarea acestuia. De Ce YOLOv4? Trei motive:
- are aprobare largă în comunitatea de învățare automată;
- această versiune și-a dovedit performanțele ridicate într-o gamă largă de sarcini de detectare;
- YOLOv4 a fost implementat în mai multe cadre populare, inclusiv TensorFlow și Keras, cu care vom lucra.
Exemple de aplicații YOLO
înainte de a trece la partea practică a acestui articol, implementând detectorul nostru de obiecte personalizat bazat pe YOLO, aș dori să vă arăt câteva implementări yolov4 interesante și apoi vom face implementarea noastră.
fiți atenți la cât de rapide și exacte sunt predicțiile!
Iată primul exemplu impresionant a ceea ce poate face YOLOv4, detectând mai multe obiecte din diferite scene de joc și film.
alternativ, puteți verifica această demonstrație de detectare a obiectelor dintr-o vizualizare a camerei din viața reală.
YOLO ca detector de obiecte în TensorFlow & Keras
TensorFlow & cadrele Keras în învățarea mașinilor

sursa imaginii.
cadrele sunt esențiale în fiecare domeniu al tehnologiei informației. Învățarea automată nu face excepție. Există mai mulți jucători consacrați pe piața ML care ne ajută să simplificăm experiența generală de programare. PyTorch, scikit-learn, TensorFlow, Keras, Mxnet și Caffe sunt doar câteva demn de menționat.
astăzi, vom lucra îndeaproape cu TensorFlow/Keras. Nu este surprinzător că aceste două sunt printre cele mai populare cadre din universul de învățare automată. Se datorează în mare parte faptului că atât TensorFlow, cât și Keras oferă capacități bogate de dezvoltare. Aceste două cadre sunt destul de asemănătoare între ele. Fără a săpa prea mult în detalii, lucrul cheie de reținut este că Keras este doar un înveliș pentru cadrul TensorFlow.
implementarea YOLO în TensorFlow & Keras
la momentul scrierii acestui articol, existau 808 depozite cu implementări YOLO pe un backend TensorFlow / Keras. YOLO versiunea 4 este ceea ce vom implementa. Limitând căutarea doar la YOLO v4, am 55 de depozite.
navigând cu atenție pe toate, am găsit un candidat interesant pentru a continua.
sursa imaginii.
această implementare a fost dezvoltată de taipingeric și jimmyaspire. Este destul de simplu și foarte intuitiv Dacă ați lucrat cu TensorFlow și Keras înainte.
pentru a începe să lucrați cu această implementare, trebuie doar să clonați repo-ul pe mașina dvs. locală. În continuare, vă voi arăta cum să utilizați YOLO din cutie și cum să vă antrenați propriul detector de obiecte personalizate.
cum să rulați Yolo pre-instruit în afara casetei și să obțineți rezultate
privind secțiunea „pornire rapidă” a repo, puteți vedea că pentru a pune în funcțiune un model, trebuie doar să importăm YOLO ca obiect de clasă și să încărcăm în greutățile modelului:
from models import Yolov4model = Yolov4(weight_path='yolov4.weights', class_name_path='class_names/coco_classes.txt')
rețineți că trebuie să descărcați manual greutățile modelului în avans. Fișierul greutăți model care vine cu YOLO vine de la setul de date COCO și este disponibil la pagina oficială a proiectului Darknet AlexeyAB la GitHub. Puteți descărca greutățile direct prin acest link.
imediat după, modelul este pe deplin pregătit să lucreze cu imagini în modul de inferență. Doar folosi prezice () metoda pentru o imagine de alegerea ta. Metoda este standard pentru cadrele TensorFlow și Keras.
pred = model.predict('input.jpg')
de exemplu pentru această imagine de intrare:

am primit următorul model de ieșire:

predicțiile pe care modelul le-a făcut sunt returnate într-o formă convenabilă a unui cadru de date pandas. Obținem numele clasei, dimensiunea casetei și coordonatele pentru fiecare obiect detectat:

o mulțime de informații utile despre obiectele detectate
există mai mulți parametri în cadrul metodei prezic() care ne permit să specificăm dacă dorim să trasăm imaginea cu casetele de delimitare prezise, numele textuale pentru fiecare obiect etc. Check out docstring care merge împreună cu prezice () metoda de a se familiariza cu ceea ce este disponibil pentru noi:

ar trebui să vă așteptați ca modelul dvs. să poată detecta numai tipurile de obiecte care sunt strict limitate la setul de date COCO. Pentru a ști ce tipuri de obiecte este capabil să detecteze un model Yolo pre-instruit, consultați coco_classes.fișier txt Disponibil în … / yolo-v4-tf.kers / class_names/. Sunt 80 de tipuri de obiecte acolo.
cum să vă antrenați modelul personalizat de detectare a obiectelor YOLO
declarație de sarcină

pentru a proiecta un model de detectare a obiectelor, trebuie să știți ce tipuri de obiecte doriți să detectați. Acesta ar trebui să fie un număr limitat de tipuri de obiecte pentru care doriți să creați detectorul. Este bine să avem o listă de tipuri de obiecte pregătite pe măsură ce trecem la dezvoltarea reală a modelului.
în mod ideal, ar trebui să aveți și un set de date adnotat care să conțină obiecte de interes. Acest set de date va fi folosit pentru a instrui un detector și a-l valida. Dacă nu aveți încă un set de date sau o adnotare pentru acesta, nu vă faceți griji, vă voi arăta unde și cum îl puteți obține.
set de date & adnotări
unde să obțineți date de la
dacă aveți un set de date adnotat cu care să lucrați, săriți peste această parte și treceți la capitolul următor. Dar, dacă aveți nevoie de un set de date pentru proiectul dvs., acum vom explora resursele online de unde puteți obține date.
nu contează cu adevărat în ce domeniu lucrați, există șanse mari să existe deja un set de date open-source pe care îl puteți utiliza pentru proiectul dvs.
prima resursă pe care o recomand este articolul „50+ seturi de date de detectare a obiectelor din diferite domenii ale industriei” de Abhishek Annamraju, care a colectat seturi de date adnotate minunate pentru industrii precum moda, Retail, Sport, Medicină și multe altele.

sursa imaginii.
alte două locuri minunate pentru a căuta datele sunt paperswithcode.com și roboflow.com care oferă acces la seturi de date de înaltă calitate pentru detectarea obiectelor.
consultați aceste elemente de mai sus pentru a colecta datele de care aveți nevoie sau pentru a îmbogăți setul de date pe care îl aveți deja.
cum să adnotați datele pentru YOLO
dacă setul dvs. de date de imagini vine fără adnotări, trebuie să faceți singur lucrarea de adnotare. Această operație manuală consumă destul de mult timp, așa că asigurați-vă că aveți suficient timp pentru a o face.
ca instrument de adnotare, puteți lua în considerare mai multe opțiuni. Personal, aș recomanda utilizarea LabelImg. Este un instrument de adnotare a imaginilor ușor de utilizat și ușor de utilizat, care poate emite direct adnotări pentru modelele YOLO.
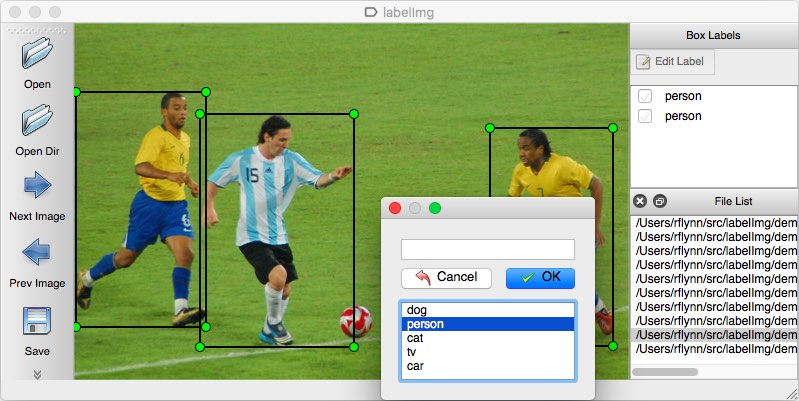
sursa imaginii.
cum se transformă datele din alte formate în Yolo
adnotările pentru YOLO sunt sub formă de fișiere txt. Fiecare linie într-un fișier txt fol YOLO trebuie să aibă următorul format:
image1.jpg 10,15,345,284,0image2.jpg 100,94,613,814,0 31,420,220,540,1
putem rupe fiecare linie din fișierul txt și să vedem în ce constă:
- prima parte a unei linii specifică numele de bază pentru imagini: image1.jpg, imagine2.jpg
- a doua parte a unei linii definește coordonatele cutiei de încadrare și eticheta clasei. De exemplu, 10,15,345,284,0 state pentru xmin,ymin,xmax,Ymax, class_id
- dacă o anumită imagine are mai multe obiecte pe ea, vor exista mai multe casete și etichete de clasă lângă numele de bază al imaginii, împărțite la un spațiu.
coordonatele cutiei de încadrare sunt un concept clar, dar ce se întâmplă cu numărul class_id care specifică eticheta clasei? Fiecare class_id este legat cu o anumită clasă într-un alt fișier txt. De exemplu, Yolo pre-instruit vine cu coco_classes.fișier txt care arată astfel:
personbicyclecarmotorbikeaeroplanebus...
Numărul de linii din fișierele claselor trebuie să corespundă numărului de clase pe care detectorul dvs. le va detecta. Numerotarea începe de la zero, ceea ce înseamnă că numărul class_id pentru prima clasă din fișierul classes va fi 0. Clasa care este plasat pe a doua linie în fișierul clase txt va avea numărul 1.
acum știi cum arată adnotarea pentru YOLO. Pentru a continua crearea unui detector de obiecte personalizate vă îndemn să faceți două lucruri acum:
- creați un fișier clase txt în cazul în care vă va Palatul claselor pe care doriți detector pentru a detecta. Amintiți-vă că ordinea clasei contează.
- creați un fișier txt cu adnotări. În cazul în care aveți deja adnotare, dar în format VOC (.XMLs), puteți utiliza acest fișier pentru a transforma de la XML la YOLO.
împărțirea datelor în subseturi
ca întotdeauna, dorim să împărțim setul de date în 2 subseturi: pentru instruire și pentru validare. Se poate face la fel de simplu ca:
from utils import read_annotation_lines train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1)
crearea de generatoare de date
când datele sunt împărțite, putem trece la inițializarea generatorului de date. Vom avea un generator de date pentru fiecare fișier de date. În cazul nostru, vom avea un generator pentru subsetul de instruire și pentru subsetul de validare.
Iată cum sunt create generatoarele de date:
from utils import DataGenerator FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
pentru a rezuma totul, iată cum arată codul complet pentru divizarea datelor și crearea generatorului:
from utils import read_annotation_lines, DataGenerator train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1) FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
instalare & configurare necesară pentru formarea modelului
să vorbim despre premisele esențiale pentru a vă crea propriul detector de obiecte:
- ar trebui să aveți Python deja instalat pe computer. În cazul în care trebuie să îl instalați, vă recomand să urmați acest ghid oficial de Anaconda;
- dacă computerul dvs. are un GPU activat CUDA (un GPU realizat de NVIDIA), atunci sunt necesare câteva biblioteci relevante pentru a sprijini instruirea bazată pe GPU. În cazul în care trebuie să activați suportul GPU, verificați instrucțiunile de pe site-ul NVIDIA. Scopul tău este să instalezi cea mai recentă versiune atât a setului de instrumente CUDA, cât și a cuDNN pentru sistemul tău de operare;
- poate doriți să organizați un mediu virtual independent în care să lucrați. Acest proiect necesită TensorFlow 2 instalat. Toate celelalte biblioteci vor fi introduse ulterior;
- în ceea ce mă privește, îmi construiam și antrenam modelul YOLOv4 într-un mediu de dezvoltare a Notebook-urilor Jupyter. Deși Jupyter Notebook pare a fi o opțiune rezonabilă pentru a merge cu, ia în considerare dezvoltarea într-un IDE la alegere, dacă doriți.
model de formare

cerințe preliminare
până acum ar trebui să aveți:
- o împărțire pentru setul dvs. de date;
- două generatoare de date inițializate;
- un fișier txt cu clasele.
inițializarea obiectului modelului
pentru a vă pregăti pentru un loc de muncă de formare, inițializați obiectul modelului YOLOv4. Asigurați-vă că utilizați nici unul ca valoare pentru parametrul weight_path. De asemenea, ar trebui să ofere o cale la fișierul clase txt la acest pas. Iată codul de inițializare pe care l-am folosit în proiectul meu:
class_name_path = 'path2project_folder/model_data/scans_file.txt' model = Yolov4(weight_path=None, class_name_path=class_name_path)
inițializarea modelului de mai sus duce la crearea unui obiect model cu un set implicit de parametri. Luați în considerare modificarea configurației modelului dvs. trecând într-un dicționar ca valoare la parametrul config model.

Config specifică un set de parametri pentru modelul YOLOv4.
configurația implicită a modelului este un bun punct de plecare, dar poate doriți să experimentați cu alte Config-uri pentru o calitate mai bună a modelului.
în special, am foarte recomanda experimentarea cu ancore și img_size. Ancorele specifică geometria ancorelor care vor fi utilizate pentru captarea obiectelor. Cu cât formele ancorelor se potrivesc mai bine formelor obiectelor, cu atât va fi mai mare performanța modelului.
creșterea img_size ar putea fi utilă și în unele cazuri. Rețineți că cu cât imaginea este mai mare, cu atât modelul va face mai mult inferența.
în cazul în care doriți să utilizați Neptun ca instrument de urmărire, ar trebui să inițializați și o rulare experimentală, astfel:
import neptune.new as neptune run = neptune.init(project='projects/my_project', api_token=my_token)
definirea callback
TensorFlow & Keras să ne utilizeze callback pentru a monitoriza progresul de formare, face puncte de control, și de a gestiona parametrii de formare (de exemplu, rata de învățare).
înainte de montarea modelului dvs., definiți apelurile care vor fi utile pentru scopurile dvs. Asigurați-vă că specificați căi pentru a stoca punctele de control ale modelului și jurnalele asociate. Iată cum am făcut-o într-unul din proiectele mele:
# defining pathes and callbacks dir4saving = 'path2checkpoint/checkpoints'os.makedirs(dir4saving, exist_ok = True) logdir = 'path4logdir/logs'os.makedirs(logdir, exist_ok = True) name4saving = 'epoch_{epoch:02d}-val_loss-{val_loss:.4f}.hdf5' filepath = os.path.join(dir4saving, name4saving) rLrCallBack = keras.callbacks.ReduceLROnPlateau(monitor = 'val_loss', factor = 0.1, patience = 5, verbose = 1) tbCallBack = keras.callbacks.TensorBoard(log_dir = logdir, histogram_freq = 0, write_graph = False, write_images = False) mcCallBack_loss = keras.callbacks.ModelCheckpoint(filepath, monitor = 'val_loss', verbose = 1, save_best_only = True, save_weights_only = False, mode = 'auto', period = 1)esCallBack = keras.callbacks.EarlyStopping(monitor = 'val_loss', mode = 'min', verbose = 1, patience = 10)
ai putea fi observat că în callback set TensorBoard de mai sus este folosit ca un instrument de urmărire. Luați în considerare utilizarea Neptun ca un instrument mult mai avansat pentru urmărirea experimentelor. Dacă da, nu uitați să inițializați un alt apel invers pentru a permite integrarea cu Neptun:
from neptune.new.integrations.tensorflow_keras import NeptuneCallback neptune_cbk = NeptuneCallback(run=run, base_namespace='metrics')
montarea modelului
pentru a începe lucrarea de antrenament, pur și simplu potriviți obiectul modelului folosind metoda Standard fit() în TensorFlow / Keras. Iată cum am început să-mi antrenez modelul:
model.fit(data_gen_train, initial_epoch=0, epochs=10000, val_data_gen=data_gen_val, callbacks= )
când începe antrenamentul, veți vedea o bară de progres standard.

procesul de instruire va evalua modelul la sfârșitul fiecărei epoci. Dacă utilizați un set de callback-uri similare cu ceea ce am inițializat și am trecut în timp ce se potrivesc, acele puncte de control care arată îmbunătățirea modelului în ceea ce privește pierderea mai mică vor fi salvate într-un director specificat.
dacă nu apar erori și procesul de instruire merge fără probleme, lucrarea de instruire va fi oprită fie din cauza sfârșitului numărului de epoci de formare, fie dacă apelul de oprire timpurie nu detectează nicio îmbunătățire suplimentară a modelului și oprește procesul general.
în orice caz, ar trebui să ajungeți la mai multe puncte de control ale modelului. Vrem să o selectăm pe cea mai bună dintre toate cele disponibile și să o folosim pentru inferență.
model personalizat instruit în modul inferență
rularea unui model instruit în modul inferență este similară cu rularea unui model pre-instruit din cutie.

inițializați un obiect model care trece în calea către cel mai bun punct de control, precum și calea către fișierul txt cu clasele. Iată cum arată inițializarea modelului pentru proiectul meu:
from models import Yolov4model = Yolov4(weight_path='path2checkpoint/checkpoints/epoch_48-val_loss-0.061.hdf5', class_name_path='path2classes_file/my_yolo_classes.txt')
când modelul este inițializat, pur și simplu utilizați metoda prezice() pentru o imagine la alegere pentru a obține predicțiile. Ca o recapitulare, detectările pe care modelul le-a făcut sunt returnate într-o formă convenabilă a unui cadru de date pandas. Obținem numele clasei, dimensiunea casetei și coordonatele pentru fiecare obiect detectat.
concluzii
tocmai ați învățat cum să creați un detector de obiecte yolov4 personalizat. Am trecut peste procesul end-to-end, pornind de la colectarea datelor, adnotare și transformare. Aveți suficiente cunoștințe despre a patra versiune YOLO și cum diferă de alte detectoare.
nimic nu te oprește acum să-ți antrenezi propriul model în TensorFlow și Keras. Știți de unde să obțineți un model pre-instruit și cum să începeți slujba de antrenament.
în următorul meu articol, vă voi arăta câteva dintre cele mai bune practici și hack-uri de viață care vor ajuta la îmbunătățirea calității modelului final. Rămâi cu noi!



Anton Morgunov
inginer de viziune computerizată la bază.Centrul
entuziast de învățare automată. Pasionat de viziunea pe calculator. Fără hârtie – mai mulți copaci! Lucrul spre eliminarea copiei pe hârtie prin trecerea la digitalizarea completă!
citiți următorul
TensorFlow Object Detection API: cele mai bune practici pentru instruire, evaluare & implementare
13 minute citire | autor Anton Morgunov | actualizat pe 28 mai 2021
acest articol este a doua parte a unei serii în care învățați un flux de lucru end to end pentru TensorFlow Object Detection și API-ul său. În primul articol, ați învățat cum să creați un detector de obiecte personalizat de la zero, dar există încă o mulțime de lucruri care au nevoie de atenția dvs. pentru a deveni cu adevărat competenți.
vom explora subiecte care sunt la fel de importante ca procesul de creare a modelului prin care am trecut deja. Iată câteva dintre întrebările la care vom răspunde:
- cum să-mi evaluez modelul și să obțin o estimare a performanței sale?
- care sunt instrumentele pe care le pot folosi pentru a urmări performanța modelului și pentru a compara rezultatele în mai multe experimente?
- Cum pot exporta modelul meu să-l folosească în modul de inferență?
- există o modalitate de a spori performanța modelului și mai mult?
Continue reading ->