
Quelle: Laden Sie Ihre Computer Vision-Modelle mit der TensorFlow Object Detection API auf,
Jonathan Huang, Wissenschaftler und Vivek Rathod, Software Engineer,
Google AI Blog
- Objekterkennung als Aufgabe in der Computer Vision
- YOLO als Echtzeit-Objektdetektor
- Was ist YOLO?
- YOLO im Vergleich zu anderen Detektoren
- Versionen von YOLO
- Beispiele für YOLO-Anwendungen
- YOLO als Objektdetektor in TensorFlow & Keras
- TensorFlow & Keras-Frameworks im maschinellen Lernen
- YOLO-Implementierung in TensorFlow & Keras
- So führen Sie vortrainiertes YOLO sofort aus und erhalten Ergebnisse
- So trainieren Sie Ihr benutzerdefiniertes YOLO-Objekterkennungsmodell
- Aufgabenanweisung
- Datensatz & Anmerkungen
- Woher Sie Daten erhalten
- So kommentieren Sie Daten für YOLO
- So transformieren Sie Daten aus anderen Formaten in YOLO
- Aufteilung der Daten in Teilmengen
- Erstellen von Datengeneratoren
- Installation & Setup für die Modellschulung erforderlich
- Modellausbildung
- Voraussetzungen
- Modellobjektinitialisierung
- Definieren von Callbacks
- Anpassen des Modells
- Trainiertes benutzerdefiniertes Modell im Inferenzmodus
- Anton Morgunov
- TensorFlow-Objekterkennungs-API: Best Practices für Training, Bewertung & Bereitstellung
Objekterkennung als Aufgabe in der Computer Vision
Wir begegnen Objekten jeden Tag in unserem Leben. Schauen Sie sich um, und Sie werden mehrere Objekte um Sie herum finden. Als Mensch können Sie jedes Objekt, das Sie sehen, leicht erkennen und identifizieren. Es ist natürlich und erfordert nicht viel Aufwand.
Für Computer ist das Erkennen von Objekten jedoch eine Aufgabe, die eine komplexe Lösung erfordert. Damit ein Computer „Objekte erkennt“, bedeutet dies, ein Eingabebild (oder ein einzelnes Bild aus einem Video) zu verarbeiten und mit Informationen über Objekte auf dem Bild und deren Position zu antworten. In der Computer Vision bezeichnen wir diese beiden Aufgaben als Klassifikation und Lokalisierung. Wir möchten, dass der Computer sagt, welche Art von Objekten auf einem bestimmten Bild dargestellt werden und wo genau sie sich befinden.
Es wurden mehrere Lösungen entwickelt, um Computer bei der Erkennung von Objekten zu unterstützen. Heute werden wir einen hochmodernen Algorithmus namens YOLO untersuchen, der eine hohe Genauigkeit bei Echtzeitgeschwindigkeit erreicht. Insbesondere erfahren Sie, wie Sie diesen Algorithmus für ein benutzerdefiniertes Dataset in TensorFlow / Keras trainieren.
Zuerst wollen wir sehen, was genau YOLO ist und wofür es berühmt ist.
YOLO als Echtzeit-Objektdetektor
Was ist YOLO?
YOLO ist ein Akronym für „You Only Look Once“ (nicht zu verwechseln mit You Only Live Once aus den Simpsons). Wie der Name schon sagt, reicht ein einziger „Blick“ aus, um alle Objekte auf einem Bild zu finden und zu identifizieren.
In Bezug auf maschinelles Lernen können wir sagen, dass alle Objekte über einen einzigen Algorithmuslauf erkannt werden. Dies geschieht, indem ein Bild in ein Raster unterteilt und Begrenzungsrahmen und Klassenwahrscheinlichkeiten für jede Zelle in einem Raster vorhergesagt werden. Falls wir YOLO für die Fahrzeugerkennung verwenden möchten, sehen Sie hier, wie das Raster und die vorhergesagten Begrenzungsrahmen aussehen könnten:

Bounding Box, die YOLO für das erste Auto vorhersagt, ist rot.
Bounding Box, die YOLO für das zweite Auto vorhersagt, ist gelb.
Quelle des Bildes.
Das obige Bild enthält nur den endgültigen Satz von Feldern, die nach dem Filtern erhalten wurden. Es ist erwähnenswert, dass die Rohausgabe von YOLO viele Begrenzungsrahmen für dasselbe Objekt enthält. Diese Boxen unterscheiden sich in Form und Größe. Wie Sie im Bild unten sehen können, erfassen einige Boxen das Zielobjekt besser, während andere, die von einem Algorithmus angeboten werden, eine schlechte Leistung erbringen.

Alle gelben Kästchen sind für das zweite Auto.
Die fett gedruckten roten und gelben Kästchen eignen sich am besten für die Fahrzeugerkennung.
Quelle des Bildes.
Um den besten Begrenzungsrahmen für ein bestimmtes Objekt auszuwählen, wird ein NMS-Algorithmus (Non-Maximum Suppression) angewendet.

, um nur diejenigen zu behalten, die Objekte am besten erfassen.
Quelle des Bildes.
Allen Boxen, die YOLO vorhersagt, ist ein Konfidenzniveau zugeordnet. NMS verwendet diese Konfidenzwerte, um die Kästchen zu entfernen, die mit geringer Sicherheit vorhergesagt wurden. Normalerweise sind dies alles Felder, die mit einer Zuversicht unter 0,5 vorhergesagt werden.

Sie können die Konfidenzwerte in der oberen linken Ecke jedes Felds neben dem Objektnamen sehen.
Quelle des Bildes.
Wenn alle unsicheren Begrenzungsrahmen entfernt werden, bleiben nur die Felder mit dem hohen Konfidenzniveau übrig. Um den besten unter den leistungsstärksten Kandidaten auszuwählen, wählt NMS das Kästchen mit dem höchsten Konfidenzniveau aus und berechnet, wie es sich mit den anderen Kästchen schneidet. Wenn ein Schnittpunkt höher als ein bestimmter Schwellenwert ist, wird der Begrenzungsrahmen mit niedrigerer Konfidenz entfernt. Wenn NMS zwei Felder vergleicht, deren Schnittpunkt unter einem ausgewählten Schwellenwert liegt, werden beide Felder in den endgültigen Vorhersagen beibehalten.
YOLO im Vergleich zu anderen Detektoren
Obwohl ein Convolutional Neural Net (CNN) unter der Haube von YOLO verwendet wird, ist es immer noch in der Lage, Objekte mit Echtzeitleistung zu erkennen. Dies ist dank der Fähigkeit von YOLO möglich, die Vorhersagen gleichzeitig in einem einstufigen Ansatz durchzuführen.
Andere, langsamere Algorithmen zur Objekterkennung (wie schnellere R-CNN) verwenden typischerweise einen zweistufigen Ansatz:
- in der ersten Stufe werden interessante Bildbereiche ausgewählt. Dies sind die Teile eines Bildes, die Objekte enthalten können;
- In der zweiten Stufe wird jede dieser Regionen mithilfe eines faltungsneuralen Netzes klassifiziert.
Normalerweise gibt es viele Regionen auf einem Bild mit den Objekten. Alle diese Regionen werden zur Klassifizierung gesendet. Die Klassifizierung ist ein zeitaufwendiger Vorgang, weshalb der zweistufige Objekterkennungsansatz im Vergleich zur einstufigen Erkennung langsamer arbeitet.
YOLO wählt nicht die interessanten Teile eines Bildes aus, das ist nicht nötig. Stattdessen werden Begrenzungsrahmen und Klassen für das gesamte Bild in einem einzigen Vorwärtsnetzdurchlauf vorhergesagt.
Unten sehen Sie, wie schnell YOLO im Vergleich zu anderen gängigen Detektoren ist.

SSD und YOLO sind einstufige Objektdetektoren, während R-RCNN
und R-FCN zweistufige Objektdetektoren sind.
Quelle des Bildes.
Versionen von YOLO
YOLO wurde erstmals 2015 von Joseph Redmon in seiner Forschungsarbeit mit dem Titel „You Only Look Once: Unified, Real-Time Object Detection“ vorgestellt.
Seitdem hat sich YOLO stark weiterentwickelt. Im Jahr 2016 beschrieb Joseph Redmon die zweite YOLO-Version in „YOLO9000: Besser, schneller, stärker“.
Ungefähr zwei Jahre nach dem zweiten YOLO-Update kam Joseph mit einem weiteren Net-Upgrade. Sein Artikel mit dem Titel „YOLOv3: An Incremental Improvement“ erregte die Aufmerksamkeit vieler Computeringenieure und wurde in der Community für maschinelles Lernen populär.
Im Jahr 2020 beschloss Joseph Redmon, die Erforschung von Computer Vision einzustellen, aber es hinderte YOLO nicht daran, von anderen entwickelt zu werden. Im selben Jahr entwarf ein Team von drei Ingenieuren (Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao) die vierte Version von YOLO, noch schneller und genauer als zuvor. Ihre Ergebnisse sind in der „YOLOv4″ beschrieben: Optimale Geschwindigkeit und Genauigkeit der Objekterkennung“ Papier veröffentlichten sie am April 23rd, 2020.
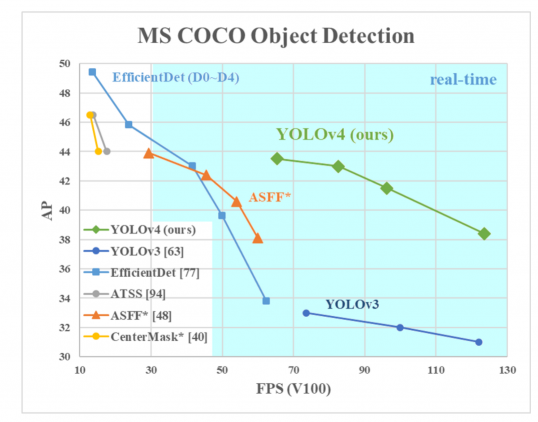
AP auf der Y-Achse ist eine Metrik namens „durchschnittliche Genauigkeit“. Es beschreibt die Genauigkeit des Netzes.
FPS (Frames per second) auf der X-Achse ist eine Metrik, die die Geschwindigkeit beschreibt.
Quelle des Bildes.
Zwei Monate nach der Veröffentlichung der 4. Version kündigte ein unabhängiger Entwickler, Glenn Jocher, die 5. Version von YOLO an. Dieses Mal wurde kein Forschungspapier veröffentlicht. Das Netz wurde auf Jochers GitHub-Seite als PyTorch-Implementierung verfügbar. Die fünfte Version hatte so ziemlich die gleiche Genauigkeit wie die vierte Version, war aber schneller.
Schließlich haben wir im Juli 2020 ein weiteres großes YOLO-Update erhalten. In einem Artikel mit dem Titel „PP-YOLO: Eine effektive und effiziente Implementierung des Objektdetektors“ haben Xiang Long und sein Team eine neue Version von YOLO entwickelt. Diese Iteration von YOLO basierte auf der 3. Modellversion und übertraf die Leistung von YOLO v4.

Die Karte auf der Y-Achse ist eine Metrik namens “ mean average precision“. Es beschreibt die Genauigkeit des Netzes.
FPS (Frames per second) auf der X-Achse ist eine Metrik, die die Geschwindigkeit beschreibt.
Quelle des Bildes.
In diesem Tutorial werden wir uns YOLOv4 und seine Implementierung genauer ansehen. Warum YOLOv4? Drei Gründe:
- Es hat breite Zustimmung in der maschinellen Lerngemeinschaft;
- Diese Version hat ihre hohe Leistung in einem breiten Spektrum von Erkennungsaufgaben bewiesen;
- YOLOv4 wurde in mehreren gängigen Frameworks implementiert, darunter TensorFlow und Keras, mit denen wir arbeiten werden.
Beispiele für YOLO-Anwendungen
Bevor wir zum praktischen Teil dieses Artikels übergehen und unseren benutzerdefinierten YOLO-basierten Objektdetektor implementieren, möchte ich Ihnen ein paar coole YOLOv4-Implementierungen zeigen, und dann werden wir unsere Implementierung vornehmen.
Achten Sie darauf, wie schnell und genau die Vorhersagen sind!
Hier ist das erste beeindruckende Beispiel dafür, was YOLOv4 kann, indem es mehrere Objekte aus verschiedenen Spiel- und Filmszenen erkennt.
Alternativ können Sie diese Objekterkennungsdemo aus einer realen Kameraansicht überprüfen.
YOLO als Objektdetektor in TensorFlow & Keras
TensorFlow & Keras-Frameworks im maschinellen Lernen

Quelle des Bildes.
Frameworks sind in jedem Bereich der Informationstechnologie unerlässlich. Maschinelles Lernen ist keine Ausnahme. Es gibt mehrere etablierte Akteure auf dem ML-Markt, die uns helfen, die gesamte Programmiererfahrung zu vereinfachen. PyTorch, scikit-learn, TensorFlow, Keras, MXNet und Caffe sind nur einige erwähnenswerte.
Heute werden wir eng mit TensorFlow/Keras zusammenarbeiten. Es überrascht nicht, dass diese beiden Frameworks zu den beliebtesten Frameworks im Universum des maschinellen Lernens gehören. Dies liegt vor allem daran, dass sowohl TensorFlow als auch Keras umfangreiche Entwicklungsfunktionen bieten. Diese beiden Frameworks sind einander sehr ähnlich. Ohne zu sehr ins Detail zu gehen, ist es wichtig, sich daran zu erinnern, dass Keras nur ein Wrapper für das TensorFlow-Framework ist.
YOLO-Implementierung in TensorFlow & Keras
Zum Zeitpunkt der Erstellung dieses Artikels gab es 808 Repositorys mit YOLO-Implementierungen in einem TensorFlow / Keras-Backend. YOLO Version 4 ist das, was wir implementieren werden. Wenn ich die Suche auf nur YOLO v4 beschränke, habe ich 55 Repositorys.
Nachdem ich alle sorgfältig durchsucht hatte, fand ich einen interessanten Kandidaten, mit dem ich fortfahren konnte.
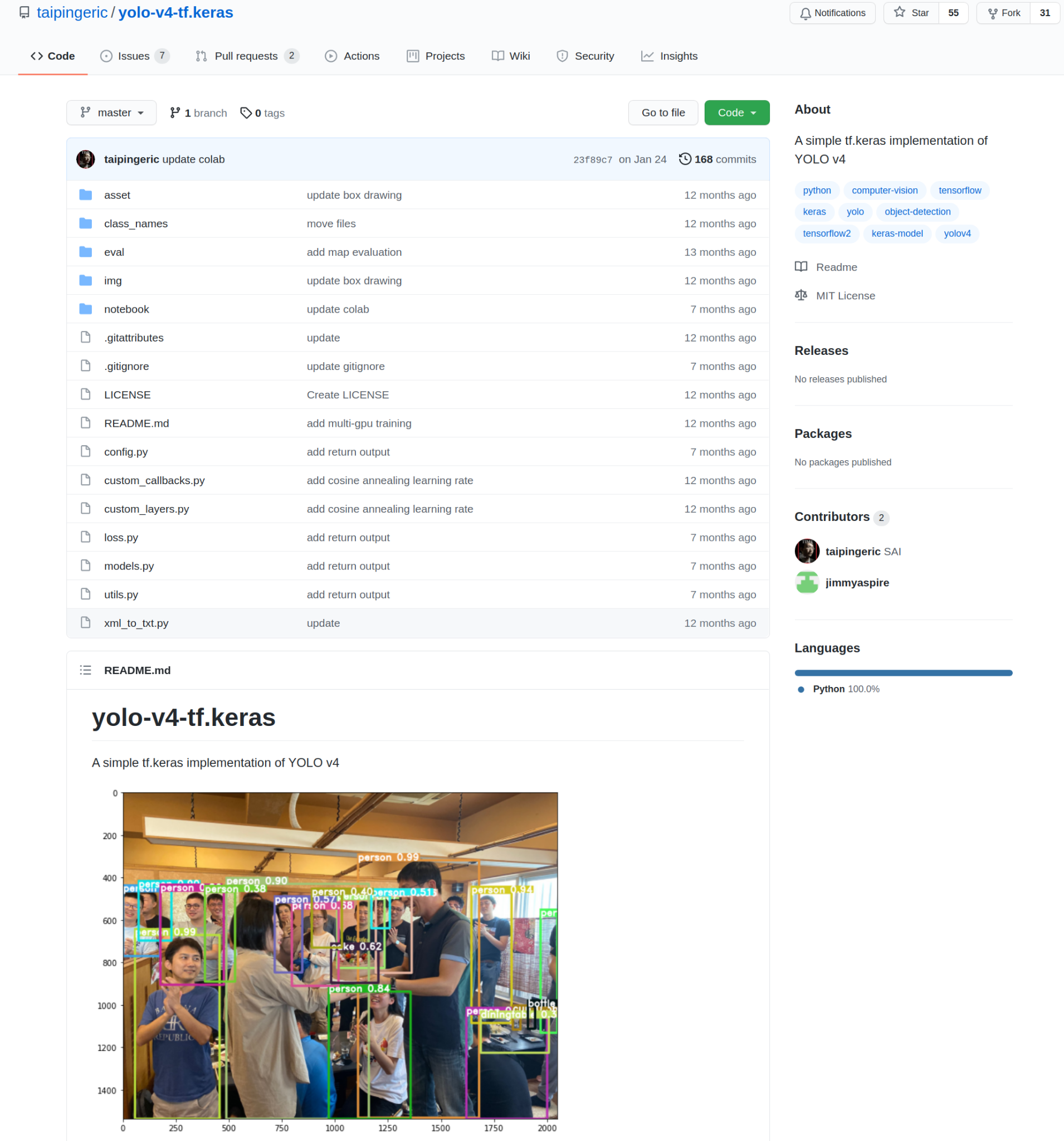
Quelle des Bildes.
Diese Implementierung wurde von taipingeric und jimmyaspire entwickelt. Es ist ziemlich einfach und sehr intuitiv, wenn Sie zuvor mit TensorFlow und Keras gearbeitet haben.
Um mit dieser Implementierung zu arbeiten, klonen Sie einfach das Repo auf Ihren lokalen Computer. Als nächstes zeige ich Ihnen, wie Sie YOLO sofort verwenden und wie Sie Ihren eigenen benutzerdefinierten Objektdetektor trainieren.
So führen Sie vortrainiertes YOLO sofort aus und erhalten Ergebnisse
Wenn Sie sich den Abschnitt „Schnellstart“ des Repos ansehen, können Sie sehen, dass wir YOLO nur als Klassenobjekt importieren und in das Modell laden müssen, um ein Modell zum Laufen zu bringen.:
from models import Yolov4model = Yolov4(weight_path='yolov4.weights', class_name_path='class_names/coco_classes.txt')
Beachten Sie, dass Sie die Modellgewichte im Voraus manuell herunterladen müssen. Die mit YOLO gelieferte Modellgewichtsdatei stammt aus dem COCO-Datensatz und ist auf der offiziellen Darknet-Projektseite von AlexeyAB unter GitHub verfügbar. Sie können die Gewichte direkt über diesen Link herunterladen.
Gleich danach ist das Modell vollständig bereit, mit Bildern im Inferenzmodus zu arbeiten. Verwenden Sie einfach die predict () -Methode für ein Bild Ihrer Wahl. Die Methode ist Standard für TensorFlow- und Keras-Frameworks.
pred = model.predict('input.jpg')
Zum Beispiel für dieses Eingabebild:

Ich habe die folgende Modellausgabe:

Vorhersagen, die das Modell gemacht hat, werden in einer bequemen Form eines Pandas-Datenrahmens zurückgegeben. Wir erhalten Klassennamen, Boxgröße und Koordinaten für jedes erkannte Objekt:

Viele nützliche Informationen zu den erkannten Objekten
Es gibt mehrere Parameter innerhalb der predict () -Methode, mit denen wir angeben können, ob wir das Bild mit den vorhergesagten Begrenzungsrahmen, Textnamen für jedes Objekt usw. zeichnen möchten. Schauen Sie sich den docstring an, der mit der predict() -Methode einhergeht, um sich mit den verfügbaren Funktionen vertraut zu machen:

Sie sollten erwarten, dass Ihr Modell nur Objekttypen erkennen kann, die streng auf das COCO-Dataset beschränkt sind. Um zu erfahren, welche Objekttypen ein vortrainiertes YOLO-Modell erkennen kann, lesen Sie die coco_classes .txt-Datei verfügbar in …/yolo-v4-tf.kers/class_names/. Es gibt 80 Objekttypen.
So trainieren Sie Ihr benutzerdefiniertes YOLO-Objekterkennungsmodell
Aufgabenanweisung

Um ein Objekterkennungsmodell zu entwerfen, müssen Sie wissen, welche Objekttypen Sie erkennen möchten. Dies sollte eine begrenzte Anzahl von Objekttypen sein, für die Sie Ihren Detektor erstellen möchten. Es ist gut, eine Liste von Objekttypen vorbereitet zu haben, wenn wir zur eigentlichen Modellentwicklung übergehen.
Idealerweise sollten Sie auch ein kommentiertes Dataset mit Objekten von Interesse haben. Dieser Datensatz wird verwendet, um einen Detektor zu trainieren und zu validieren. Wenn Sie noch keinen Datensatz oder keine Anmerkung dafür haben, machen Sie sich keine Sorgen, ich zeige Ihnen, wo und wie Sie ihn erhalten können.
Datensatz & Anmerkungen
Woher Sie Daten erhalten
Wenn Sie mit einem kommentierten Datensatz arbeiten möchten, überspringen Sie einfach diesen Teil und fahren Sie mit dem nächsten Kapitel fort. Wenn Sie jedoch einen Datensatz für Ihr Projekt benötigen, werden wir jetzt Online-Ressourcen untersuchen, in denen Sie Daten abrufen können.
Es spielt keine Rolle, in welchem Bereich Sie arbeiten, es besteht eine große Chance, dass es bereits einen Open-Source-Datensatz gibt, den Sie für Ihr Projekt verwenden können.
Die erste Ressource, die ich empfehle, ist der Artikel „50+ Object Detection Datasets from different industry domains“ von Abhishek Annamraju, der wunderbare kommentierte Datensätze für Branchen wie Mode, Einzelhandel, Sport, Medizin und viele mehr gesammelt hat.

Quelle des Bildes.
Andere zwei großartige Orte, um nach den Daten zu suchen, sind paperswithcode.com und roboflow.com die den Zugriff auf hochwertige Datensätze zur Objekterkennung ermöglichen.
Schauen Sie sich diese oben genannten Assets an, um die benötigten Daten zu sammeln oder den Datensatz, den Sie bereits haben, anzureichern.
So kommentieren Sie Daten für YOLO
Wenn Ihr Bilddatensatz keine Anmerkungen enthält, müssen Sie die Anmerkungen selbst ausführen. Stellen Sie daher sicher, dass Sie genügend Zeit dafür haben.
Als Annotationswerkzeug können Sie mehrere Optionen in Betracht ziehen. Persönlich würde ich die Verwendung von LabelImg empfehlen. Es ist ein leichtes und einfach zu bedienendes Bildanmerkungstool, das Anmerkungen für YOLO-Modelle direkt ausgeben kann.
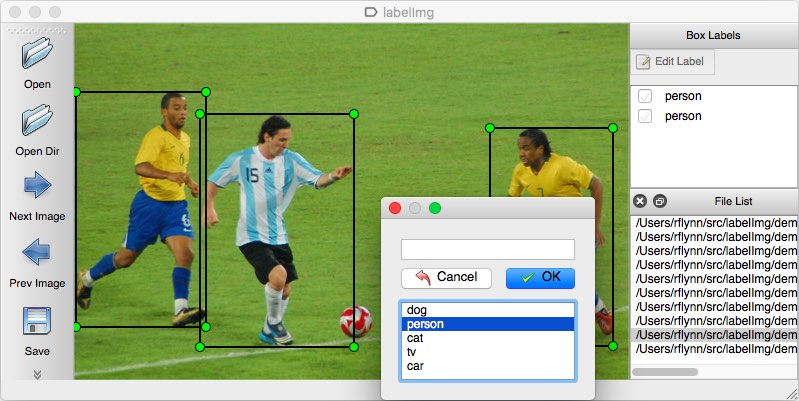
Quelle des Bildes.
So transformieren Sie Daten aus anderen Formaten in YOLO
Anmerkungen für YOLO liegen in Form von TXT-Dateien vor. Jede Zeile in einer TXT-Datei fol YOLO muss das folgende Format haben:
image1.jpg 10,15,345,284,0image2.jpg 100,94,613,814,0 31,420,220,540,1
Wir können jede Zeile aus der TXT-Datei aufteilen und sehen, woraus sie besteht:
- Der erste Teil einer Zeile gibt die Basisnamen für die Bilder an: image1.jpg, image2.jpeg
- Der zweite Teil einer Zeile definiert die Koordinaten des Begrenzungsrahmens und die Klassenbezeichnung. Beispiel: 10,15,345,284,0 Zustände für xmin, ymin, xmax, ymax, class_id
- Wenn ein bestimmtes Bild mehr als ein Objekt enthält, befinden sich neben dem Basisnamen des Bildes mehrere Kästchen und Klassenbeschriftungen, geteilt durch ein Leerzeichen.
Bounding-Box-Koordinaten sind ein klares Konzept, aber was ist mit der class_id-Nummer, die die Klassenbezeichnung angibt? Jede class_id ist mit einer bestimmten Klasse in einer anderen TXT-Datei verknüpft. Zum Beispiel kommt vortrainiertes YOLO mit den coco_classes.txt-Datei, die so aussieht:
personbicyclecarmotorbikeaeroplanebus...
Die Anzahl der Zeilen in den Klassendateien muss mit der Anzahl der Klassen übereinstimmen, die Ihr Detektor erkennen wird. Die Nummerierung beginnt bei Null, was bedeutet, dass die class_id-Nummer für die erste Klasse in der Klassendatei 0 ist. Klasse, die in der zweiten Zeile in der Klassen-TXT-Datei platziert wird, hat die Nummer 1.
Jetzt wissen Sie, wie die Annotation für YOLO aussieht. Um weiterhin einen benutzerdefinierten Objektdetektor zu erstellen, müssen Sie jetzt zwei Dinge tun:
- erstellen Sie eine Klassen-TXT-Datei, in der Sie die Klassen angeben, die Ihr Detektor erkennen soll. Denken Sie daran, dass die Klassenordnung wichtig ist.
- Erstellen Sie eine TXT-Datei mit Anmerkungen. Falls Sie bereits Anmerkungen haben, aber im VOC-Format (.XMLs), können Sie diese Datei verwenden, um von XML nach YOLO zu transformieren.
Aufteilung der Daten in Teilmengen
Wie immer möchten wir den Datensatz in 2 Teilmengen aufteilen: für das Training und für die Validierung. Es kann so einfach gemacht werden wie:
from utils import read_annotation_lines train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1)
Erstellen von Datengeneratoren
Wenn die Daten aufgeteilt sind, können wir mit der Initialisierung des Datengenerators fortfahren. Wir haben einen Datengenerator für jede Datendatei. In unserem Fall haben wir einen Generator für die Trainingsteilmenge und für die Validierungsteilmenge.
So werden die Datengeneratoren erstellt:
from utils import DataGenerator FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
Um alles zusammenzufassen, sieht der vollständige Code für die Datenaufteilung und Generatorerstellung folgendermaßen aus:
from utils import read_annotation_lines, DataGenerator train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1) FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
Installation & Setup für die Modellschulung erforderlich
Lassen Sie uns über die Voraussetzungen sprechen, die für die Erstellung eines eigenen Objektdetektors erforderlich sind:
- Sie sollten Python bereits auf Ihrem Computer installiert haben. Falls Sie es installieren müssen, empfehle ich, diesem offiziellen Leitfaden von Anaconda zu folgen;
- Wenn Ihr Computer über eine CUDA-fähige GPU (eine GPU von NVIDIA) verfügt, sind einige relevante Bibliotheken erforderlich, um GPU-basiertes Training zu unterstützen. Falls Sie die GPU-Unterstützung aktivieren müssen, lesen Sie die Richtlinien auf der NVIDIA-Website. Ihr Ziel ist es, die neueste Version des CUDA-Toolkits und von cuDNN für Ihr Betriebssystem zu installieren;
- Vielleicht möchten Sie eine unabhängige virtuelle Umgebung organisieren, in der Sie arbeiten können. Für dieses Projekt muss TensorFlow 2 installiert sein. Alle anderen Bibliotheken werden später eingeführt;
- Ich habe mein YOLOv4-Modell in einer Jupyter Notebook-Entwicklungsumgebung erstellt und trainiert. Obwohl Jupyter Notebook eine vernünftige Option zu sein scheint, sollten Sie die Entwicklung in einer IDE Ihrer Wahl in Betracht ziehen, wenn Sie dies wünschen.
Modellausbildung

Voraussetzungen
Inzwischen sollten Sie:
- Ein Split für Ihren Datensatz;
- Zwei Datengeneratoren initialisiert;
- Eine TXT-Datei mit den Klassen.
Modellobjektinitialisierung
Um sich auf einen Trainingsjob vorzubereiten, initialisieren Sie das YOLOv4-Modellobjekt. Stellen Sie sicher, dass Sie None als Wert für den Parameter weight_path verwenden. Sie sollten in diesem Schritt auch einen Pfad zu Ihrer Klassen-TXT-Datei angeben. Hier ist der Initialisierungscode, den ich in meinem Projekt verwendet habe:
class_name_path = 'path2project_folder/model_data/scans_file.txt' model = Yolov4(weight_path=None, class_name_path=class_name_path)
Die obige Modellinitialisierung führt zur Erstellung eines Modellobjekts mit einem Standardsatz von Parametern. Erwägen Sie, die Konfiguration Ihres Modells zu ändern, indem Sie ein Wörterbuch als Wert an den Parameter config model übergeben.

Config gibt einen Satz von Parametern für das YOLOv4-Modell an.
Die Standardmodellkonfiguration ist ein guter Ausgangspunkt, aber Sie können mit anderen Konfigurationen experimentieren, um eine bessere Modellqualität zu erzielen.
Insbesondere empfehle ich dringend, mit Ankern und img_size zu experimentieren. Anker Geben Sie die Geometrie der Anker an, die zum Erfassen von Objekten verwendet werden. Je besser die Formen der Anker zu den Objektformen passen, desto höher ist die Modellleistung.
Das Erhöhen von img_size kann in einigen Fällen auch nützlich sein. Beachten Sie, dass das Modell die Inferenz umso länger ausführt, je höher das Bild ist.
Falls Sie Neptun als Tracking-Tool verwenden möchten, sollten Sie auch einen Experimentlauf wie folgt initialisieren:
import neptune.new as neptune run = neptune.init(project='projects/my_project', api_token=my_token)
Definieren von Callbacks
TensorFlow & Mit Keras können wir Callbacks verwenden, um den Trainingsfortschritt zu überwachen, Checkpoints zu erstellen und Trainingsparameter (z. B. Lernrate) zu verwalten.
Bevor Sie Ihr Modell anpassen, definieren Sie Rückrufe, die für Ihre Zwecke nützlich sind. Stellen Sie sicher, dass Sie Pfade zum Speichern von Modellprüfpunkten und zugehörigen Protokollen angeben. So habe ich es in einem meiner Projekte gemacht:
# defining pathes and callbacks dir4saving = 'path2checkpoint/checkpoints'os.makedirs(dir4saving, exist_ok = True) logdir = 'path4logdir/logs'os.makedirs(logdir, exist_ok = True) name4saving = 'epoch_{epoch:02d}-val_loss-{val_loss:.4f}.hdf5' filepath = os.path.join(dir4saving, name4saving) rLrCallBack = keras.callbacks.ReduceLROnPlateau(monitor = 'val_loss', factor = 0.1, patience = 5, verbose = 1) tbCallBack = keras.callbacks.TensorBoard(log_dir = logdir, histogram_freq = 0, write_graph = False, write_images = False) mcCallBack_loss = keras.callbacks.ModelCheckpoint(filepath, monitor = 'val_loss', verbose = 1, save_best_only = True, save_weights_only = False, mode = 'auto', period = 1)esCallBack = keras.callbacks.EarlyStopping(monitor = 'val_loss', mode = 'min', verbose = 1, patience = 10)
Sie könnten bemerkt haben, dass in den obigen Rückrufen set TensorBoard als Tracking-Tool verwendet wird. Erwägen Sie, Neptun als ein viel fortschrittlicheres Werkzeug für die Experimentverfolgung zu verwenden. Wenn ja, vergessen Sie nicht, einen weiteren Rückruf zu initialisieren, um die Integration mit Neptun zu ermöglichen:
from neptune.new.integrations.tensorflow_keras import NeptuneCallback neptune_cbk = NeptuneCallback(run=run, base_namespace='metrics')
Anpassen des Modells
Um den Trainingsjob zu starten, passen Sie das Modellobjekt einfach mit der Standardmethode fit() in TensorFlow / Keras an. So habe ich angefangen, mein Modell zu trainieren:
model.fit(data_gen_train, initial_epoch=0, epochs=10000, val_data_gen=data_gen_val, callbacks= )
Wenn das Training gestartet wird, sehen Sie einen Standard-Fortschrittsbalken.

Der Trainingsprozess bewertet das Modell am Ende jeder Epoche. Wenn Sie eine Reihe von Rückrufen verwenden, die denen ähneln, die ich beim Anpassen initialisiert und übergeben habe, werden die Prüfpunkte, die eine Modellverbesserung in Bezug auf einen geringeren Verlust zeigen, in einem bestimmten Verzeichnis gespeichert.
Wenn keine Fehler auftreten und der Trainingsprozess reibungslos verläuft, wird der Trainingsjob entweder wegen des Endes der Trainingsepochennummer gestoppt, oder wenn der Early Stopping Callback keine weitere Modellverbesserung erkennt und den Gesamtprozess stoppt.
In jedem Fall sollten Sie mehrere Modellprüfpunkte erhalten. Wir wollen das beste aus allen verfügbaren auswählen und es für die Inferenz verwenden.
Trainiertes benutzerdefiniertes Modell im Inferenzmodus
Das Ausführen eines trainierten Modells im Inferenzmodus ähnelt dem Ausführen eines vortrainierten Modells.

Sie initialisieren ein Modellobjekt, indem Sie den Pfad zum besten Prüfpunkt sowie den Pfad zur TXT-Datei mit den Klassen übergeben. So sieht die Modellinitialisierung für mein Projekt aus:
from models import Yolov4model = Yolov4(weight_path='path2checkpoint/checkpoints/epoch_48-val_loss-0.061.hdf5', class_name_path='path2classes_file/my_yolo_classes.txt')
Wenn das Modell initialisiert ist, verwenden Sie einfach die predict() -Methode für ein Bild Ihrer Wahl, um die Vorhersagen zu erhalten. Zusammenfassend werden die vom Modell vorgenommenen Erkennungen in einer praktischen Form eines Pandas-Datenrahmens zurückgegeben. Wir erhalten den Klassennamen, die Boxgröße und die Koordinaten für jedes erkannte Objekt.
Sie haben gerade gelernt, wie Sie einen benutzerdefinierten YOLOv4-Objektdetektor erstellen. Wir haben den End-to-End-Prozess durchlaufen, beginnend mit der Datenerfassung, Annotation und Transformation. Sie haben genug Wissen über die vierte YOLO-Version und wie sie sich von anderen Detektoren unterscheidet.
Nichts hindert Sie jetzt daran, Ihr eigenes Modell in TensorFlow und Keras zu trainieren. Sie wissen, woher Sie ein vortrainiertes Modell erhalten und wie Sie den Trainingsjob starten.
In meinem kommenden Artikel werde ich Ihnen einige der Best Practices und Life Hacks zeigen, die dazu beitragen, die Qualität des endgültigen Modells zu verbessern. Bleib bei uns!



Anton Morgunov
Computer Vision Ingenieur bei Basis.Zentrum
Enthusiasten des maschinellen Lernens. Leidenschaft für Computer Vision. Kein Papier – mehr Bäume! Arbeiten Sie an der Beseitigung von Papierkopien, indem Sie zur vollständigen Digitalisierung übergehen!
WEITER LESEN
TensorFlow-Objekterkennungs-API: Best Practices für Training, Bewertung & Bereitstellung
13 Minuten Lesezeit | Autor Anton Morgunov | Aktualisiert am 28. Mai 2021
Dieser Artikel ist der zweite Teil einer Reihe, in der Sie einen End-to-End-Workflow für die TensorFlow-Objekterkennung und ihre API erlernen. Im ersten Artikel haben Sie gelernt, wie Sie einen benutzerdefinierten Objektdetektor von Grund auf neu erstellen, aber es gibt immer noch viele Dinge, die Ihre Aufmerksamkeit benötigen, um wirklich kompetent zu werden.
Wir werden Themen untersuchen, die genauso wichtig sind wie der Modellerstellungsprozess, den wir bereits durchlaufen haben. Hier sind einige der Fragen, die wir beantworten werden:
- Wie kann ich mein Modell bewerten und eine Schätzung seiner Leistung erhalten?
- Mit welchen Tools kann ich die Modellleistung verfolgen und die Ergebnisse mehrerer Experimente vergleichen?
- Wie kann ich mein Modell exportieren, um es im Inferenzmodus zu verwenden?
- Gibt es eine Möglichkeit, die Modellleistung noch weiter zu steigern?
Weiterlesen ->