Das Crawl Budget ist die Anzahl der Seiten, die Suchmaschinen innerhalb eines bestimmten Zeitraums auf einer Website crawlen.
Suchmaschinen berechnen das Crawling-Budget basierend auf dem Crawling-Limit (wie oft sie crawlen können, ohne Probleme zu verursachen) und der Crawling-Nachfrage (wie oft sie eine Website crawlen möchten).
Wenn Sie Crawl-Budget verschwenden, können Suchmaschinen Ihre Website nicht effizient crawlen, was Ihre SEO-Leistung beeinträchtigen würde.
- Was ist Crawl Budget?
- Warum weisen Suchmaschinen Websites ein Crawl Budget zu?
- Wie weisen sie Websites Crawl-Budget zu?
- Geht es beim Crawl Budget nur um Seiten?
- Wie funktioniert Crawl Limit / Host Load in der Praxis?
- Wie funktioniert Crawl Demand / Crawl Scheduling in der Praxis?
- Vergessen Sie nicht: Crawling-Kapazität des Systems selbst
- Warum sollten Sie sich für Crawl Budget interessieren?
- Was ist das Crawl Budget für meine Website?
- Crawling-Budget in der Google Search Console
- Gehe zur Quelle: Serverprotokolle
- Wie optimieren Sie Ihr Crawl Budget?
- Zugängliche URLs mit Parametern
- Duplicate content
- Minderwertiger Inhalt
- Defekte und umleitende Links
- Falsche URLs in XML-Sitemaps
- ContentKing
- Seiten mit hohen Ladezeiten / Timeouts
- Hohe Anzahl nicht indizierbarer Seiten
- Schlechte interne Linkstruktur
- Wie steigern Sie das Crawl Budget Ihrer Website?
- Häufig gestellte Fragen zum Crawl Budget
- 1. 🧾 Was ist Crawl Budget?
- 2. 🤔 Wie erhöhe ich mein Crawl Budget?
- 3. 🤷 Was kann mein Crawl Budget einschränken?
- 4. 🤖 Sollte ich überhaupt canonical URL und Meta Robots verwenden?
Was ist Crawl Budget?
Das Crawl-Budget ist die Anzahl der Seiten, die Suchmaschinen innerhalb eines bestimmten Zeitraums auf einer Website crawlen.
Warum weisen Suchmaschinen Websites ein Crawl Budget zu?
Weil sie nicht über unbegrenzte Ressourcen verfügen und ihre Aufmerksamkeit auf Millionen von Websites verteilen. Sie brauchen also eine Möglichkeit, ihren Crawling-Aufwand zu priorisieren. Das Zuweisen des Crawl-Budgets zu jeder Website hilft ihnen dabei.
Wie weisen sie Websites Crawl-Budget zu?
Das basiert auf zwei Faktoren, Crawl Limit und Crawl demand:
- Crawling-Limit / Host-Last: Wie viel Crawling kann eine Website verarbeiten und welche Präferenzen hat der Eigentümer?
- Crawling-Nachfrage / Crawling-Planung: Welche URLs es wert sind, am meisten (erneut) gecrawlt zu werden, basierend auf ihrer Beliebtheit und wie oft sie aktualisiert werden.
Crawl Budget ist ein gängiger Begriff innerhalb von SEO. Crawl Budget wird manchmal auch als Crawl Space oder Crawl Time bezeichnet.

Geht es beim Crawl Budget nur um Seiten?
Es ist nicht wirklich, der Einfachheit halber sprechen wir über Seiten, aber in Wirklichkeit geht es um jedes Dokument, das Suchmaschinen crawlen. Einige Beispiele für andere Dokumente: JavaScript- und CSS-Dateien, mobile Seitenvarianten, hreflang -Varianten und PDF-Dateien.
Wie funktioniert Crawl Limit / Host Load in der Praxis?
Crawl-Limit oder Host-Last, wenn Sie so wollen, ist ein wichtiger Teil des Crawl-Budgets. Suchmaschinen-Crawler sollen verhindern, dass ein Webserver mit Anforderungen überlastet wird.Wie bestimmen Suchmaschinen das Crawl-Limit einer Website? Es gibt eine Vielzahl von Faktoren, die das Crawl-Limit beeinflussen. Um nur einige zu nennen:
- Anzeichen einer Plattform in schlechtem Zustand: wie oft angeforderte URLs Timeout oder Rückkehr Serverfehler.
- Die Anzahl der Websites, die auf dem Host ausgeführt werden: Wenn Ihre Website auf einer Shared-Hosting-Plattform mit Hunderten anderer Websites ausgeführt wird und Sie eine ziemlich große Website haben, ist das Crawling-Limit für Ihre Website sehr begrenzt, da das Crawling-Limit auf Hostebene festgelegt wird. Sie müssen das Crawling-Limit des Hosts mit allen anderen darauf ausgeführten Sites teilen. In diesem Fall wären Sie viel besser auf einem dedizierten Server, was höchstwahrscheinlich auch die Ladezeiten für Ihre Besucher massiv verkürzen wird.
Eine weitere zu berücksichtigende Sache ist, dass separate mobile und Desktop-Sites auf demselben Host ausgeführt werden. Sie haben auch ein gemeinsames Crawl-Limit. Denken Sie also daran.
Crawlen Suchmaschinen die wichtigsten Teile Ihrer Website? Machen Sie einen Schnelltest mit ContentKing!
Wie funktioniert Crawl Demand / Crawl Scheduling in der Praxis?
Bei der Crawling-Anforderung oder Crawling-Planung geht es darum, den Wert des erneuten Crawlings von URLs zu bestimmen. Wiederum beeinflussen viele Faktoren die Nachfrage, darunter:
- Popularität: Wie viele eingehende interne und eingehende externe Links eine URL hat, aber auch die Anzahl der Abfragen, für die sie rangiert.
- Frische: wie oft die URL aktualisiert wird.
- Seitentyp: ist der Seitentyp, der sich wahrscheinlich ändert. Nehmen wir zum Beispiel eine Produktkategorieseite und eine Seite mit Allgemeinen Geschäftsbedingungen – welche ändert sich Ihrer Meinung nach am häufigsten und verdient es, häufiger gecrawlt zu werden?

Es ist keine gute Strategie, die Crawler von Google zu zwingen, auf Ihre Website zurückzukehren, wenn nichts Wichtigeres zu finden ist (dh sinnvolle Änderungen), und sie sind ziemlich klug darin, herauszufinden, ob die Häufigkeit dieser Seitenänderungen tatsächlich einen Mehrwert bietet. Der beste Rat, den ich geben kann, ist, sich darauf zu konzentrieren, die Seiten wichtiger zu machen (indem Sie nützlichere Informationen hinzufügen, die Seiten inhaltsreich machen (sie lösen natürlich standardmäßig mehr Abfragen aus, solange der Fokus eines Themas beibehalten wird). Indem Sie natürlich mehr Abfragen als Teil von ‚Recall‘ (Impressionen) auslösen, machen Sie Ihre Seiten wichtiger und siehe da: Sie werden wahrscheinlich häufiger gecrawlt.
Vergessen Sie nicht: Crawling-Kapazität des Systems selbst
Während Suchmaschinen-Crawling-Systeme eine massive Crawling-Kapazität haben, ist sie am Ende des Tages begrenzt. In einem Szenario, in dem 80% der Rechenzentren von Google gleichzeitig offline gehen, nimmt ihre Crawling-Kapazität massiv ab und damit das Crawling-Budget aller Websites.
Vielen Dank an Dawn Anderson (öffnet in einem neuen Tab) für die Bereitstellung von Details zu Crawl-Limit, Crawl-Nachfrage und Crawl-Kapazität!
Warum sollten Sie sich für Crawl Budget interessieren?
Sie möchten, dass Suchmaschinen so viele Ihrer indexierbaren Seiten wie möglich finden und verstehen, und Sie möchten, dass sie dies so schnell wie möglich tun. Wenn Sie neue Seiten hinzufügen und vorhandene aktualisieren, möchten Sie, dass Suchmaschinen diese so schnell wie möglich abrufen. Je früher sie die Seiten indiziert haben, desto eher können Sie davon profitieren.
Wenn Sie Crawl-Budget verschwenden, können Suchmaschinen Ihre Website nicht effizient crawlen. Sie verbringen Zeit mit Teilen Ihrer Website, die keine Rolle spielen, was dazu führen kann, dass wichtige Teile Ihrer Website unentdeckt bleiben. Wenn sie nichts über Seiten wissen, werden sie sie nicht crawlen und indizieren, und Sie werden nicht in der Lage sein, Besucher über Suchmaschinen zu ihnen zu bringen.
Sie können sehen, wohin dies führt: Die Verschwendung von Crawl-Budget schadet Ihrer SEO-Leistung.
Bitte beachten Sie, dass das Crawl-Budget im Allgemeinen nur dann ein Problem darstellt, wenn Sie eine große Website haben, sagen wir 10.000 Seiten und mehr.

Einer der unterschätztesten Aspekte des Crawl-Budgets ist die Ladegeschwindigkeit. Eine schneller ladende Website bedeutet, dass Google mehr URLs in der gleichen Zeit crawlen kann. Kürzlich war ich an einem Site-Upgrade beteiligt, bei dem die Ladegeschwindigkeit im Vordergrund stand. Die neue Seite wird doppelt so schnell geladen wie die alte. Als es live geschoben wurde, stieg die Anzahl der URLs, die Google pro Tag gecrawlt hat, von 150.000 auf 600.000 – und blieb dort. Für eine Website dieser Größe und dieses Umfangs bedeutet die verbesserte Crawling-Rate, dass neue und geänderte Inhalte viel schneller gecrawlt werden und wir einen viel schnelleren Einfluss unserer SEO-Bemühungen auf die SERPs sehen.

Ein sehr weiser SEO (okay, es war AJ Kohn (öffnet in einem neuen Tab)) sagte einmal berühmt: „Du bist, was Googlebot isst.“. Ihre Rankings und Suchsichtbarkeit hängen nicht nur direkt damit zusammen, was Google auf Ihrer Website crawlt, sondern auch, wie oft sie gecrawlt werden. Wenn Google Inhalte auf Ihrer Website vermisst oder wichtige URLs aufgrund eines begrenzten / nicht optimierten Crawling-Budgets nicht häufig genug crawlt, wird es Ihnen in der Tat sehr schwer fallen, ein Ranking zu erzielen. Bei größeren Websites kann die Optimierung des Crawl-Budgets das Profil zuvor unsichtbarer Seiten erheblich verbessern. Während kleinere Websites sich weniger um das Crawl-Budget kümmern müssen, gelten die gleichen Optimierungsprinzipien (Geschwindigkeit, Priorisierung, Linkstruktur, Deduplizierung usw.) kann Ihnen immer noch beim Rang helfen.

Ich stimme Google größtenteils zu und zum größten Teil müssen sich viele Websites keine Gedanken über das Crawl-Budget machen. Aber für Websites, die groß sind und vor allem solche, die häufig aktualisiert werden, wie Publisher, kann die Optimierung einen signifikanten Unterschied machen.
Was ist das Crawl Budget für meine Website?
Von allen Suchmaschinen ist Google das transparenteste Crawl-Budget für Ihre Website.
Crawling-Budget in der Google Search Console
Wenn Sie Ihre Website in der Google Search Console verifiziert haben, erhalten Sie einen Einblick in das Crawling-Budget Ihrer Website für Google.
Folgen Sie diesen Schritten:
- Melden Sie sich in der Google Search Console an und wählen Sie eine Website aus.
- Gehe zu
Crawl>Crawl Stats. Dort sehen Sie die Anzahl der Seiten, die Google pro Tag crawlt.
Im Sommer 2016 sah unser Crawl Budget so aus:
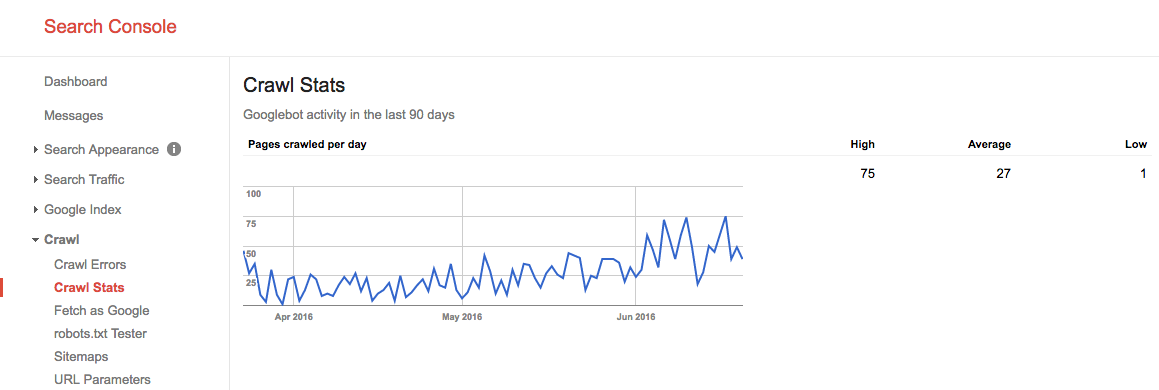
Wir sehen hier, dass das durchschnittliche Crawl-Budget 27 Seiten / Tag beträgt. Wenn dieses durchschnittliche Crawl-Budget also gleich bleibt, hätten Sie theoretisch ein monatliches Crawl-Budget von 27 Seiten x 30 Tagen = 810 Seiten.
Schneller Vorlauf 2 Jahre, und schauen Sie sich an, was unser Crawl-Budget gerade ist:
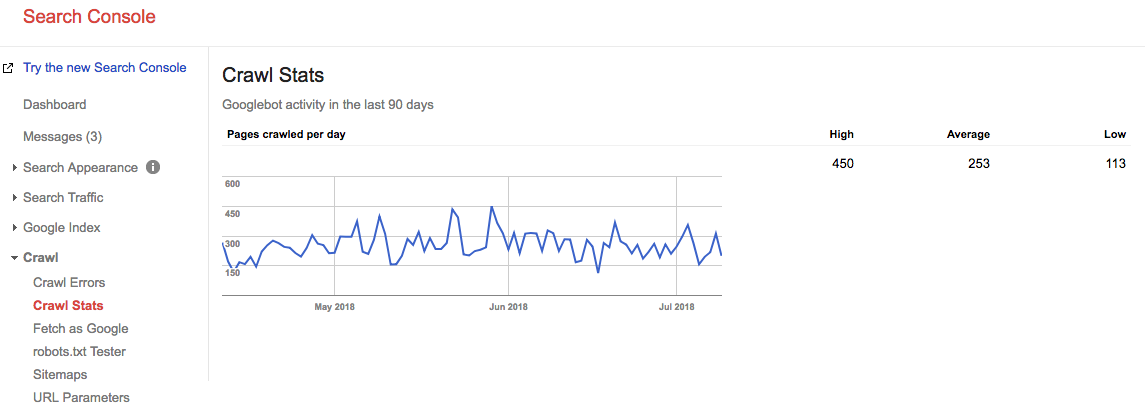
Unser durchschnittliches durchschnittliches Crawl-Budget beträgt 253 Seiten / Tag, man könnte also sagen, dass unser Crawl-Budget in 2 Jahren um das 10-fache gestiegen ist.
Gehe zur Quelle: Serverprotokolle
Es ist sehr interessant, Ihre Serverprotokolle zu überprüfen, um zu sehen, wie oft die Crawler von Google Ihre Website treffen. Es ist interessant, diese Statistiken mit denen zu vergleichen, die in der Google Search Console gemeldet werden. Es ist immer besser, sich auf mehrere Quellen zu verlassen.
Lassen Sie Crawling-Probleme nicht zu einer verpassten Gelegenheit werden. Überwachen Sie Ihre Website kontinuierlich mit ContentKing und lassen Sie sich in Echtzeit über Probleme informieren.
Wie optimieren Sie Ihr Crawl Budget?
Wenn Sie Ihr Crawl-Budget optimieren, müssen Sie sicherstellen, dass kein Crawl-Budget verschwendet wird. Im Wesentlichen werden die Gründe für verschwendetes Crawl-Budget behoben. Wir überwachen Tausende von Websites; Wenn Sie jede einzelne auf Crawl-Budget-Probleme überprüfen würden, würden Sie schnell ein Muster erkennen: Die meisten Websites leiden unter denselben Problemen.
Häufige Gründe für verschwendetes Crawl Budget:
- Zugängliche URLs mit Parametern: Ein Beispiel für eine URL mit einem Parameter ist
https://www.example.com/toys/cars?color=black. In diesem Fall wird der Parameter verwendet, um die Auswahl eines Besuchers in einem Produktfilter zu speichern. - Duplicate content: Wir nennen Seiten, die sehr ähnlich oder genau gleich sind, „duplicate content“.“ Beispiele sind: kopierte Seiten, interne Suchergebnisseiten und Tag-Seiten.
- Minderwertiger Inhalt: Seiten mit sehr wenig Inhalt oder Seiten, die keinen Mehrwert bieten.
- Defekte und umleitende Links: Defekte Links sind Links, die auf Seiten verweisen, die nicht mehr existieren, und umgeleitete Links sind Links zu URLs, die zu anderen URLs umleiten.
- Einschließlich falscher URLs in XML-Sitemaps: Nicht indexierbare Seiten und Nicht-Seiten wie 3xx-, 4xx- und 5xx-URLs sollten nicht in Ihre XML-Sitemap aufgenommen werden.
- Seiten mit hoher Ladezeit / Timeouts: seiten, die lange oder gar nicht geladen werden, wirken sich negativ auf Ihr Crawling-Budget aus, da dies ein Zeichen für Suchmaschinen ist, dass Ihre Website die Anforderung nicht verarbeiten kann.
- Hohe Anzahl nicht indexierbarer Seiten: Die Website enthält viele Seiten, die nicht indexierbar sind.
- Schlechte interne Linkstruktur: Wenn Ihre interne Linkstruktur nicht korrekt eingerichtet ist, schenken Suchmaschinen einigen Ihrer Seiten möglicherweise nicht genügend Aufmerksamkeit.

Ich habe oft gesagt, dass Google wie dein Chef ist. Sie würden nicht in ein Meeting mit Ihrem Chef gehen, wenn Sie nicht wüssten, worüber Sie sprechen würden, die Höhepunkte Ihrer Arbeit, die Ziele Ihres Meetings. Kurz gesagt, Sie haben eine Agenda. Wenn Sie in Googles „Büro“ gehen, brauchen Sie dasselbe. Eine klare Site-Hierarchie ohne viel Cruft, eine hilfreiche XML-Sitemap und schnelle Antwortzeiten helfen Google dabei, das Wichtige zu erreichen. Übersehen Sie nicht dieses oft missverstandene Element der SEO.

Für mich ist das Konzept des Crawl-Budgets einer der wichtigsten Punkte der technischen SEO. Wenn Sie für das Crawling-Budget optimieren, passt alles andere zusammen: interne Verlinkung, Fehlerbehebung, Seitengeschwindigkeit, URL-Optimierung, minderwertige Inhalte und mehr. Benutzer sollten häufiger in ihre Protokolldateien eintauchen, um das Crawling-Budget für bestimmte URLs, Subdomains, Verzeichnisse usw. zu überwachen. Die Überwachung der Crawling-Häufigkeit hängt stark mit dem Crawl-Budget zusammen und ist äußerst leistungsstark.
Zugängliche URLs mit Parametern
In den meisten Fällen sollten URLs mit Parametern für Suchmaschinen nicht zugänglich sein, da sie eine nahezu unendliche Anzahl von URLs generieren können.Wir haben ausführlich über diese Art von Problem in unserem Artikel über Crawler-Traps geschrieben.
URLs mit Parametern werden häufig bei der Implementierung von Produktfiltern auf E-Commerce-Websites verwendet. Es ist in Ordnung, sie zu verwenden; Stellen Sie nur sicher, dass sie für Suchmaschinen nicht zugänglich sind.
Wie können Sie sie für Suchmaschinen unzugänglich machen?
- Verwenden Sie Ihre Roboter.txt-Datei, um Suchmaschinen anzuweisen, nicht auf solche URLs zuzugreifen. Wenn dies aus irgendeinem Grund keine Option ist, verwenden Sie die URL-Parameterbehandlungseinstellungen in der Google Search Console und den Bing Webmaster-Tools, um Google und Bing anzuweisen, welche Seiten nicht gecrawlt werden sollen.
- Fügen Sie den Nofollow-Attributwert zu Links auf Filterlinks hinzu. Bitte beachten Sie, dass Google ab März 2020 das Nofollow ignorieren kann. Umso wichtiger ist Schritt 1.
Duplicate content
Sie möchten nicht, dass Suchmaschinen ihre Zeit auf Seiten mit doppelten Inhalten verbringen, daher ist es wichtig, den doppelten Inhalt auf Ihrer Website zu verhindern oder zumindest zu minimieren.
Wie machst du das? Von…
- Einrichten von Website-Weiterleitungen für alle Domain-Varianten (
HTTP,HTTPS,non-WWW, undWWW). - Machen Sie interne Suchergebnisseiten für Suchmaschinen mit Ihren Robotern unzugänglich.txt. Hier ist ein Beispiel Roboter.txt für eine WordPress-Website.
- Deaktivieren dedizierter Seiten für Bilder (zum Beispiel: die berüchtigten Bildanhangseiten in WordPress).
- Seien Sie vorsichtig bei der Verwendung von Taxonomien wie Kategorien und Tags.
Sehen Sie sich einige weitere technische Gründe für doppelte Inhalte an und erfahren Sie, wie Sie diese beheben können.
Minderwertiger Inhalt
Seiten mit sehr wenig Inhalt sind für Suchmaschinen nicht interessant. Halten Sie sie auf ein Minimum oder vermeiden Sie sie nach Möglichkeit vollständig. Ein Beispiel für minderwertige Inhalte ist ein FAQ-Bereich mit Links zu den Fragen und Antworten, wobei jede Frage und Antwort über eine separate URL bereitgestellt wird.
Defekte und umleitende Links
Defekte Links und lange Ketten von Weiterleitungen sind Sackgassen für Suchmaschinen. Ähnlich wie bei Browsern scheint Google maximal fünf verketteten Weiterleitungen in einem Crawling zu folgen (sie können das Crawlen später fortsetzen). Es ist unklar, wie gut andere Suchmaschinen mit nachfolgenden Weiterleitungen umgehen, aber wir empfehlen dringend, verkettete Weiterleitungen vollständig zu vermeiden und die Verwendung von Weiterleitungen auf ein Minimum zu beschränken.
Es ist klar, dass Sie durch das Beheben defekter Links und das Umleiten von Links verschwendetes Crawl-Budget schnell wiederherstellen können. Neben der Wiederherstellung des Crawl-Budgets verbessern Sie auch die Benutzererfahrung eines Besuchers erheblich. Weiterleitungen und insbesondere Ketten von Weiterleitungen verursachen eine längere Ladezeit der Seite und beeinträchtigen dadurch die Benutzererfahrung.
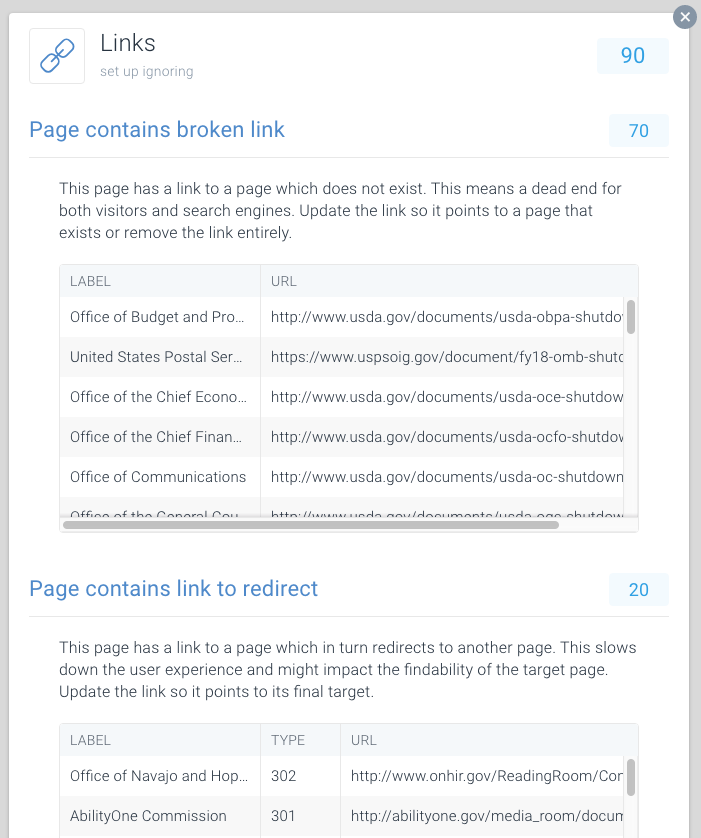
Um das Auffinden defekter Links und das Umleiten von Links zu vereinfachen, haben wir diesem Thema in ContentKing spezielle Ausgaben gewidmet.
Gehen Sie zu Issues > Links, um herauszufinden, ob Sie Crawl-Budgets aufgrund fehlerhafter Links verschwenden. Aktualisieren Sie jeden Link so, dass er auf eine indexierbare Seite verweist, oder entfernen Sie den Link, wenn er nicht mehr benötigt wird.
Falsche URLs in XML-Sitemaps
Alle in XML-Sitemaps enthaltenen URLs sollten für indexierbare Seiten bestimmt sein. Insbesondere bei großen Websites sind Suchmaschinen stark auf XML-Sitemaps angewiesen, um alle Ihre Seiten zu finden. Wenn Ihre XML-Sitemaps mit Seiten überladen sind, die beispielsweise nicht mehr existieren oder umgeleitet werden, verschwenden Sie Crawl-Budget. Überprüfen Sie Ihre XML-Sitemap regelmäßig auf nicht indizierbare URLs, die nicht dorthin gehören. Überprüfen Sie auch das Gegenteil: Suchen Sie nach Seiten, die fälschlicherweise von der XML-Sitemap ausgeschlossen sind. Die XML-Sitemap ist eine großartige Möglichkeit, Suchmaschinen dabei zu helfen, Ihr Crawl-Budget sinnvoll auszugeben.
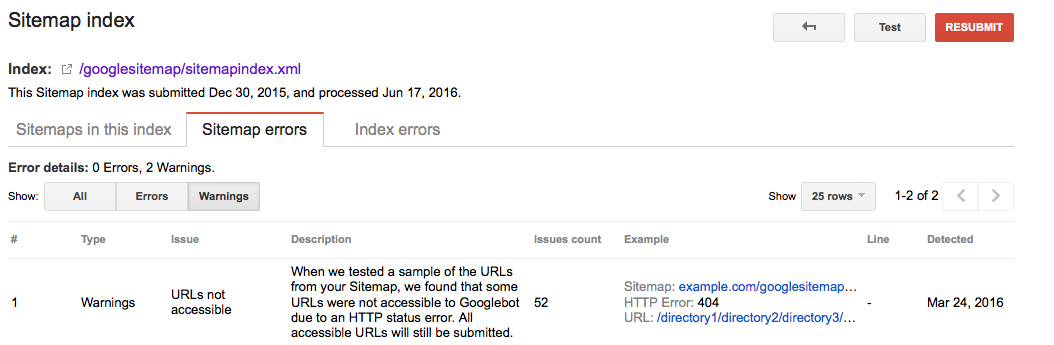
Google Searche Console
- Melden Sie sich in der Google Search Console an
- Klicken Sie auf die Registerkarte
Crawl - Klicken Sie auf die Registerkarte
Sitemaps
Bing Webmaster Tools
- Melden Sie sich bei Ihrem Bing Webmaster Tools-Konto an
- Klicken Sie auf die Registerkarte
Configure My Site - Klicken Sie auf die Registerkarte
Sitemaps
ContentKing
- Melden Sie sich in Ihrem ContentKing-Konto an
- Klicken Sie auf die Schaltfläche
Issues - Klicken Sie auf die Schaltfläche
XML Sitemap - Bei Problemen mit Ihrer Seite erhalten Sie diese Nachricht:
Page is incorrectly included in XML sitemap
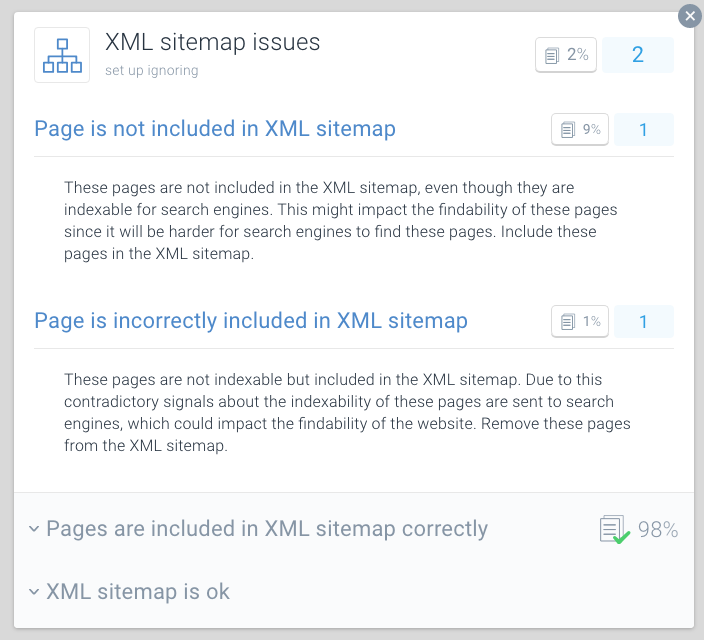
Eine bewährte Methode zur Optimierung des Crawling-Budgets besteht darin, Ihre XML-Sitemaps in kleinere Sitemaps aufzuteilen. Sie können beispielsweise XML-Sitemaps für jeden Abschnitt Ihrer Website erstellen. Wenn Sie dies getan haben, können Sie schnell feststellen, ob in bestimmten Bereichen Ihrer Website Probleme auftreten.
Angenommen, Ihre XML-Sitemap für Abschnitt A enthält 500 Links und 480 sind indiziert: Dann machen Sie es ziemlich gut. Wenn Ihre XML-Sitemap für Abschnitt B jedoch 500 Links enthält und nur 120 indiziert sind, sollten Sie dies prüfen. Möglicherweise haben Sie viele nicht indizierbare URLs in die XML-Sitemap für Abschnitt B aufgenommen.
Schlechte Bedingungen für Crawler können Ihrer SEO schaden. Verwenden Sie ContentKing, um eine schnelle Prüfung Ihrer Website durchzuführen.
Seiten mit hohen Ladezeiten / Timeouts

Wenn Seiten hohe Ladezeiten haben oder eine Zeitüberschreitung aufweisen, können Suchmaschinen weniger Seiten innerhalb ihres zugewiesenen Crawling-Budgets für Ihre Website besuchen. Neben diesem Nachteil beeinträchtigen hohe Seitenladezeiten und Timeouts die Benutzererfahrung Ihres Besuchers erheblich, was zu einer niedrigeren Conversion-Rate führt.
Seitenladezeiten über zwei Sekunden sind ein Problem. Im Idealfall wird Ihre Seite in weniger als einer Sekunde geladen. Überprüfen Sie regelmäßig Ihre Seitenladezeiten mit Tools wie Pingdom (wird in einem neuen Tab geöffnet), WebPagetest (wird in einem neuen Tab geöffnet) oder GTmetrix (wird in einem neuen Tab geöffnet).
Google meldet die Ladezeit der Seite sowohl in Google Analytics (unter Behavior > Site Speed) und Google Search Console unter Crawl > Crawl Stats.
Google Search Console und Bing Webmaster Tools melden beide Seiten-Timeouts. In der Google Search Console finden Sie dies unter Crawl > Crawl Errors, und in Bing Webmaster Tools ist es unter Reports & Data > Crawl Information.
Überprüfen Sie regelmäßig, ob Ihre Seiten schnell genug geladen werden, und ergreifen Sie sofort Maßnahmen, wenn dies nicht der Fall ist. Schnell ladende Seiten sind für Ihren Online-Erfolg von entscheidender Bedeutung.
Hohe Anzahl nicht indizierbarer Seiten
Wenn Ihre Website eine hohe Anzahl nicht indizierbarer Seiten enthält, auf die Suchmaschinen zugreifen können, halten Sie Suchmaschinen im Grunde damit beschäftigt, irrelevante Seiten zu durchsuchen.
Wir betrachten die folgenden Typen als nicht indexierbare Seiten:
- Weiterleitungen (3xx)
- Seiten, die nicht gefunden werden können (4xx)
- Seiten mit Serverfehlern (5xx)
- Seiten, die nicht indizierbar sind (Seiten, die die robots noindex Direktive oder die kanonische URL)
Um herauszufinden, ob Sie eine hohe Anzahl nicht indexierbarer Seiten haben, schauen Sie sich die Gesamtzahl der Seiten an, die Crawler auf Ihrer Website gefunden haben, und wie sie zusammenbrechen. Sie können dies ganz einfach mit ContentKing tun:
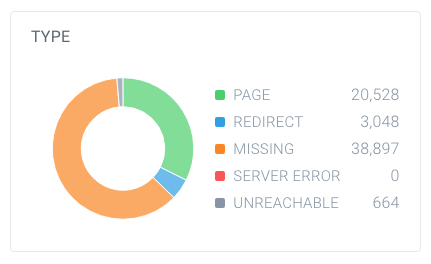
In diesem Beispiel wurden 63.137 URLs gefunden, von denen nur 20.528 Seiten sind.
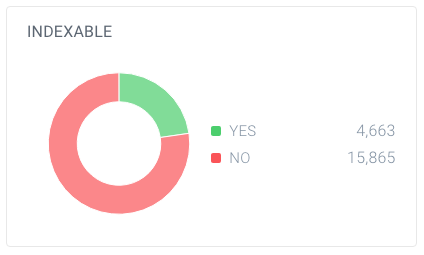
Und von diesen Seiten sind nur 4.663 für Suchmaschinen indizierbar. Nur 7,4% der von ContentKing gefundenen URLs können von Suchmaschinen indiziert werden. Das ist kein gutes Verhältnis, und diese Website muss definitiv daran arbeiten, indem sie alle unnötigen Verweise auf sie bereinigt, einschließlich:
- Die XML-Sitemap (siehe vorherigen Abschnitt)
- Links
- Kanonische URLs
- Hreflang-Referenzen
- Paginierungsreferenzen (Link rel prev/next)
Schlechte interne Linkstruktur
Wie Seiten innerhalb Ihrer Website miteinander verlinken, spielt eine große Rolle bei der Crawl-Budget-Optimierung. Wir nennen dies die interne Linkstruktur Ihrer Website. Backlinks beiseite, Seiten mit wenigen internen Links erhalten von Suchmaschinen viel weniger Aufmerksamkeit als Seiten, auf die viele Seiten verlinken.
Vermeiden Sie eine sehr hierarchische Linkstruktur, bei der Seiten in der Mitte nur wenige Links enthalten. In vielen Fällen werden diese Seiten nicht häufig gecrawlt. Noch schlimmer ist es für Seiten am Ende der Hierarchie: Aufgrund ihrer begrenzten Anzahl von Links können sie von Suchmaschinen sehr gut vernachlässigt werden.
Stellen Sie sicher, dass Ihre wichtigsten Seiten viele interne Links haben. Seiten, die kürzlich gecrawlt wurden, rangieren in der Regel besser in Suchmaschinen. Denken Sie daran und passen Sie Ihre interne Linkstruktur dafür an.
Wenn Sie beispielsweise einen Blogartikel aus dem Jahr 2011 haben, der viel organischen Traffic generiert, stellen Sie sicher, dass Sie weiterhin von anderen Inhalten darauf verlinken. Da Sie im Laufe der Jahre viele andere Blog-Artikel erstellt haben, wird dieser Artikel aus dem Jahr 2011 automatisch in der internen Linkstruktur Ihrer Website nach unten verschoben.

Normalerweise müssen Sie sich keine Gedanken über die Crawl-Rate Ihrer wichtigen Seiten machen. Es sind normalerweise Seiten, die neu sind, auf die Sie nicht verlinkt haben und auf die die Leute nicht gehen, die möglicherweise nicht oft gecrawlt werden.
Wie steigern Sie das Crawl Budget Ihrer Website?
Während eines Interviews (öffnet in einem neuen Tab) zwischen Eric Enge und Googles ehemaligem Leiter des Webspam-Teams Matt Cutts wurde das Verhältnis zwischen Autorität und Crawl-Budget angesprochen:

Der beste Weg, darüber nachzudenken, ist, dass die Anzahl der Seiten, die wir crawlen, ungefähr proportional zu Ihrem PageRank ist. Wenn Sie also viele eingehende Links auf Ihrer Stammseite haben, werden wir diese definitiv crawlen. Dann kann Ihre Stammseite auf andere Seiten verlinken, und diese erhalten PageRank und wir werden diese auch crawlen. Wenn Sie jedoch immer tiefer in Ihre Website eindringen, sinkt der PageRank tendenziell.
Obwohl Google die Aktualisierung der PageRank-Werte von Seiten öffentlich eingestellt hat, denken wir, dass (eine Form von) PageRank immer noch in ihren Algorithmen verwendet wird. Da PageRank ein missverstandener und verwirrender Begriff ist, nennen wir ihn Seitenautorität. Der Take-Away hier ist, dass Matt Cutts im Grunde sagt: Es gibt eine ziemlich starke Beziehung zwischen Seitenautorität und Crawl-Budget.
Um das Crawl-Budget Ihrer Website zu erhöhen, müssen Sie die Autorität Ihrer Website erhöhen. Ein großer Teil davon wird erreicht, indem mehr Links von externen Websites verdient werden. Weitere Informationen dazu finden Sie in unserem Link Building Guide.

Wenn ich höre, dass die Branche über Crawl-Budget spricht, sprechen wir normalerweise über die Onpage- und technischen Änderungen, die wir vornehmen können, um das Crawl-Budget im Laufe der Zeit zu erhöhen. Vor dem Hintergrund des Linkaufbaus beziehen sich die größten Spitzen bei den gecrawlten Seiten, die wir in der Google Search Console sehen, direkt darauf, wann wir große Links für unsere Kunden gewinnen.
Häufig gestellte Fragen zum Crawl Budget
- 🧾 Was ist Crawl Budget?
- 🤔 Wie erhöhe ich mein Crawl Budget?
- 🎛️ Was kann mein Crawl-Budget einschränken?
- 🤖 Sollte ich überhaupt canonical URL und Meta Robots verwenden?
1. 🧾 Was ist Crawl Budget?
Das Crawl-Budget ist die Anzahl der Seiten, die Suchmaschinen innerhalb eines bestimmten Zeitraums auf einer Website crawlen.
2. 🤔 Wie erhöhe ich mein Crawl Budget?
Google hat angegeben, dass es eine starke Beziehung zwischen Seitenautorität und Crawl-Budget gibt. Je mehr Autorität eine Seite hat, desto mehr Crawl-Budget hat sie. Um Ihr Crawl-Budget zu erhöhen, bauen Sie einfach die Autorität Ihrer Seite auf.
3. 🤷 Was kann mein Crawl Budget einschränken?
Das Crawl-Limit, auch als Crawl-Host-Last bezeichnet, basiert auf vielen Faktoren, z. B. dem Zustand der Website und den Hosting-Fähigkeiten. Suchmaschinen-Crawler sollen verhindern, dass ein Webserver überlastet wird. Wenn Ihre Website Serverfehler zurückgibt oder die angeforderten URLs häufig eine Zeitüberschreitung aufweisen, ist das Crawling-Budget begrenzter. Wenn Ihre Website auf einer Shared-Hosting-Plattform ausgeführt wird, ist das Crawling-Limit höher, da Sie Ihr Crawling-Budget mit anderen Websites teilen müssen, die auf dem Hosting ausgeführt werden.
4. 🤖 Sollte ich überhaupt canonical URL und Meta Robots verwenden?
Ja, und es ist wichtig, die Unterschiede zwischen Indexierungsproblemen und Crawling-Problemen zu verstehen.
Die Canonical URL- und Meta Robots-Tags senden ein klares Signal an Suchmaschinen, welche Seite sie in ihrem Index anzeigen sollen, aber es hindert sie nicht daran, diese anderen Seiten zu crawlen.
Sie können die Roboter verwenden.txt-Datei und die Nofollow-Link-Beziehung zum Umgang mit Crawling-Problemen.