
kilde: Supercharge din Computer Vision modeller med Tensorstrøm objekt afsløring API,
Jonathan Huang, forsker og Vivek Rathod, programmel ingeniør,
Google AI Blog
- Object Detection som en opgave i Computer Vision
- YOLO som en realtids objektdetektor
- Hvad er YOLO?
- YOLO sammenlignet med andre detektorer
- versioner af YOLO
- eksempler på YOLO-applikationer
- YOLO som objektdetektor i Tensorstrøm & Keras
- Tensorstrøm & Keras rammer i maskinlæring
- Yolo-implementering i Tensorstrøm& Keras
- Sådan kører du præ-trænet YOLO uden for boksen og får resultater
- Sådan træner du din brugerdefinerede Yolo objektdetekteringsmodel
- Opgaveerklæring
- datasæt& kommentarer
- hvor kan man hente data fra
- sådan kommenteres data til YOLO
- sådan transformeres data fra andre formater til YOLO
- opdeling af data i undergrupper
- oprettelse af datageneratorer
- Installation & opsætning kræves til model træning
- Model træning
- forudsætninger
- initialisering af Modelobjekt
- definition af tilbagekald
- montering af model
- trænet brugerdefineret model i inferenstilstand
- konklusioner
- Anton Morgunov
- TENSORSTRØMSOBJEKTDETEKTERING API: bedste praksis til træning, evaluering & implementering
Object Detection som en opgave i Computer Vision
vi støder på objekter hver dag i vores liv. Kig rundt, og du vil finde flere objekter omkring dig. Som menneske kan du nemt opdage og identificere hvert objekt, du ser. Det er naturligt og kræver ikke meget indsats.
for computere er detektering af objekter imidlertid en opgave, der har brug for en kompleks løsning. For en computer at” opdage objekter ” betyder at behandle et inputbillede (eller en enkelt ramme fra en video) og reagere med oplysninger om objekter på billedet og deres position. I computer vision vilkår kalder vi disse to opgaver klassificering og lokalisering. Vi ønsker, at computeren skal sige, hvilken slags objekter der præsenteres på et givet billede, og hvor nøjagtigt de er placeret.
der er udviklet flere løsninger til at hjælpe computere med at registrere objekter. I dag skal vi udforske en avanceret algoritme kaldet YOLO, som opnår høj nøjagtighed ved realtidshastighed. Især lærer vi at træne denne algoritme på et brugerdefineret datasæt i Tensorstrøm / Keras.
lad os først se, hvad YOLO er, og hvad den er berømt for.
YOLO som en realtids objektdetektor
Hvad er YOLO?
YOLO er et akronym for” du ser kun en gang ” (ikke forveksle det med dig kun Live en gang fra The Simpsons). Som navnet antyder, er et enkelt “look” nok til at finde alle objekter på et billede og identificere dem.
i maskinlæringsbetingelser kan vi sige, at alle objekter registreres via en enkelt algoritmekørsel. Det gøres ved at opdele et billede i et gitter og forudsige afgrænsningsbokse og klassesandsynligheder for hver celle i et gitter. Hvis vi gerne vil ansætte YOLO til bildetektion, her er hvad gitteret og de forudsagte afgrænsningsbokse kan se ud:

afgrænsningsboks, som YOLO forudsiger for den første bil, er i rødt.
afgrænsningsboks, som YOLO forudsiger for den anden bil, er gul.
kilde til billedet.
ovenstående billede indeholder kun det endelige sæt kasser opnået efter filtrering. Det er værd at bemærke, at Yolos rå produktion indeholder mange afgrænsningsbokse til det samme objekt. Disse kasser er forskellige i form og størrelse. Som du kan se på billedet nedenfor, er nogle kasser bedre til at fange målobjektet, mens andre, der tilbydes af en algoritme, fungerer dårligt.

alle gule kasser er til den anden bil.
de fedte røde og gule kasser er de bedste til bildetektering.
kilde til billedet.
for at vælge det bedste afgrænsningsfelt for et givet objekt anvendes en ikke-maksimal undertrykkelse (NMS) algoritme.

kasser forudsagt for bilerne at holde kun dem, der bedst fange objekter.
kilde til billedet.
alle kasser, som YOLO forudsiger, har et konfidensniveau forbundet med dem. NMS bruger disse konfidensværdier til at fjerne de kasser, der blev forudsagt med lav sikkerhed. Normalt er disse alle kasser, der forudsiges med tillid under 0,5.

du kan se konfidensresultaterne i øverste venstre hjørne af hver boks ved siden af objektnavnet.
kilde til billedet.
når alle usikre afgrænsningsbokse fjernes, er det kun kasserne med det høje konfidensniveau, der er tilbage. For at vælge den bedste blandt de mest effektive kandidater vælger NMS boksen med det højeste konfidensniveau og beregner, hvordan det skærer med de andre felter rundt. Hvis et kryds er højere end et bestemt tærskelniveau, fjernes afgrænsningsboksen med lavere tillid. Hvis NMS sammenligner to felter, der har et kryds under en valgt tærskel, holdes begge felter i endelige forudsigelser.
YOLO sammenlignet med andre detektorer
selvom et konvolutionært neuralt net (CNN) bruges under hætten på YOLO, er det stadig i stand til at registrere objekter med ydeevne i realtid. Det er muligt takket være Yolos evne til at gøre forudsigelserne samtidigt i en enkelt-trins tilgang.
andre, langsommere algoritmer til objektdetektion (som hurtigere R-CNN) bruger typisk en to-trins tilgang:
- i første fase vælges interessante billedregioner. Dette er de dele af et billede, der kan indeholde objekter;
- i anden fase klassificeres hver af disse regioner ved hjælp af et indviklet neuralt net.
normalt er der mange regioner på et billede med objekterne. Alle disse regioner sendes til klassificering. Klassificering er en tidskrævende operation, hvorfor to-trins objektdetekteringsmetoden fungerer langsommere sammenlignet med et-trins detektion.
YOLO vælger ikke de interessante dele af et billede, der er ikke behov for det. I stedet forudsiger det afgrænsningsbokse og klasser for hele billedet i et enkelt fremadrettet netpas.
nedenfor kan du se, hvor hurtigt YOLO sammenlignes med andre populære detektorer.

SSD og YOLO er et-trins objektdetektorer, mens Faster-RCNN
og R-FCN er to-trins objektdetektorer.
kilde til billedet.
versioner af YOLO
YOLO blev først introduceret i 2015 af Joseph Redmon i hans forskningsartikel med titlen “You only Look Once: Unified, real-Time Object Detection”.
siden da har YOLO udviklet sig meget. I 2016 beskrev Joseph Redmon den anden YOLO-version i “YOLO9000: bedre, hurtigere, stærkere”.
cirka to år efter den anden Yolo-opdatering kom Joseph med en anden netopgradering. Hans papir, kaldet” YOLOv3: en trinvis forbedring”, fangede mange computeringeniørers opmærksomhed og blev populær i maskinlæringsfællesskabet.
i 2020 besluttede Joseph Redmon at stoppe med at undersøge computersyn, men det forhindrede ikke YOLO i at blive udviklet af andre. Samme år designede et team på tre ingeniører (Aleksey Bochkovskiy, Chien-Yao, Hong-Yuan Mark Liao) den fjerde version af YOLO, endnu hurtigere og mere præcis end før. Deres resultater er beskrevet i ” YOLOv4: Optimal hastighed og nøjagtighed af objektdetektering” papir, de offentliggjorde den 23.April 2020.
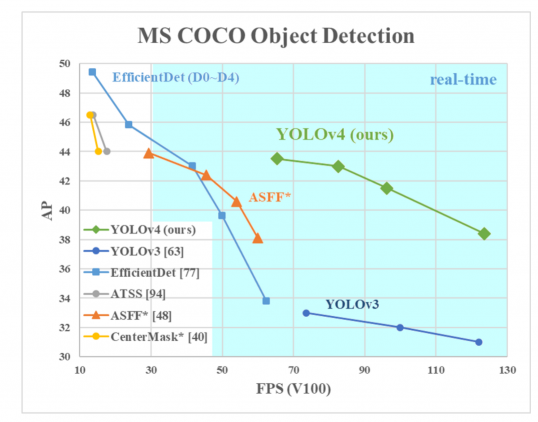
AP på Y-aksen er en metrisk kaldet”gennemsnitlig præcision”. Det beskriver nøjagtigheden af nettet.
FPS (billeder per sekund) på H-aksen er en metrisk, der beskriver hastighed.
kilde til billedet.
to måneder efter udgivelsen af den 4.version annoncerede en uafhængig udvikler, Glenn Jocher, den 5. version af YOLO. Denne gang blev der ikke offentliggjort noget forskningsdokument. Nettet blev tilgængeligt på Jochers GitHub-side som en pytorch-implementering. Den femte version havde stort set den samme nøjagtighed som den fjerde version, men den var hurtigere.
endelig fik vi i juli 2020 endnu en stor Yolo-opdatering. I et papir med titlen “PP-YOLO: en effektiv og effektiv implementering af Object Detector” kom yang Long og team med en ny version af YOLO. Denne iteration af YOLO var baseret på 3.modelversion og oversteg Yolo v4 ‘ s ydeevne.

kortet på Y-aksen er en metrisk kaldet”gennemsnitlig gennemsnitlig præcision”. Det beskriver nøjagtigheden af nettet.
FPS (billeder per sekund) på H-aksen er en metrisk, der beskriver hastighed.
kilde til billedet.
i denne tutorial vil vi se nærmere på YOLOv4 og dens implementering. Hvorfor YOLOv4? Tre grunde:
- det har bred godkendelse i maskinlæringsfællesskabet;
- denne version har bevist sin høje ydeevne i en bred vifte af detektionsopgaver;
- YOLOv4 er blevet implementeret i flere populære rammer, herunder Tensorstrøm og Keras, som vi skal arbejde med.
eksempler på YOLO-applikationer
før vi går videre til den praktiske del af denne artikel og implementerer vores brugerdefinerede YOLO-baserede objektdetektor, vil jeg gerne vise dig et par seje YOLOv4-implementeringer, og så skal vi gøre vores implementering.
Vær opmærksom på, hvor hurtigt og præcist forudsigelserne er!
her er det første imponerende eksempel på, hvad YOLOv4 kan gøre ved at opdage flere objekter fra forskellige spil-og filmscener.
Alternativt kan du tjekke denne object detection demo fra en real-life kamera visning.
YOLO som objektdetektor i Tensorstrøm & Keras
Tensorstrøm & Keras rammer i maskinlæring

kilde til billedet.
rammer er afgørende i alle informationsteknologi domæne. Machine learning er ingen undtagelse. Der er flere etablerede aktører på ML-markedet, som hjælper os med at forenkle den samlede programmeringserfaring. Pytorch, scikit-Lær, Tensorstrøm, Keras, Mknet og Caffe er blot nogle få værd at nævne.
i dag skal vi arbejde tæt sammen med Tensorfloden/Keras. Ikke overraskende er disse to blandt de mest populære rammer i maskinlæringsuniverset. Det skyldes stort set, at både Tensorstrøm og Keras giver rige muligheder for udvikling. Disse to rammer ligner hinanden meget. Uden at grave for meget i detaljer er den vigtigste ting at huske, at Keras kun er en indpakning til Tensorstrømrammen.
Yolo-implementering i Tensorstrøm& Keras
på tidspunktet for skrivningen af denne artikel var der 808 arkiver med YOLO-implementeringer på en Tensorstrøm / Keras-backend. YOLO version 4 er, hvad vi skal implementere. Begrænsning af søgningen til kun YOLO v4, jeg fik 55 repositories.
omhyggeligt gennemsøgning af dem alle fandt jeg en interessant kandidat at fortsætte med.
kilde til billedet.
denne implementering blev udviklet af taipingeric og jimmyaspire. Det er ret simpelt og meget intuitivt, hvis du har arbejdet med Keras før.
for at begynde at arbejde med denne implementering skal du bare klone repoen til din lokale maskine. Dernæst vil jeg vise dig, hvordan du bruger YOLO ud af kassen, og hvordan du træner din egen brugerdefinerede objektdetektor.
Sådan kører du præ-trænet YOLO uden for boksen og får resultater
når du ser på afsnittet “Hurtig Start” i repoen, kan du se, at for at få en model i gang, skal vi bare importere YOLO som et klasseobjekt og indlæse modelvægtene i modellen, så du kan:
from models import Yolov4model = Yolov4(weight_path='yolov4.weights', class_name_path='class_names/coco_classes.txt')
Bemærk, at du skal manuelt hente modelvægte på forhånd. Modelvægtfilen, der følger med YOLO, kommer fra COCO-datasættet, og den er tilgængelig på den officielle darknet-projektside på GitHub. Du kan hente vægtene direkte via dette link.
lige efter er modellen helt klar til at arbejde med billeder i inferensmodus. Brug bare predict () – metoden til et billede efter eget valg. Metoden er standard for Tensorstrøm og Keras rammer.
pred = model.predict('input.jpg')
for eksempel til dette inputbillede:

jeg fik følgende model output:

forudsigelser om, at modellen er lavet, returneres i en bekvem form af en pandas DataFrame. Vi får klassenavn, boksstørrelse og koordinater for hvert detekteret objekt:

masser af nyttige oplysninger om de detekterede objekter
der er flere parametre inden for predict () – metoden, der lader os specificere, om vi vil plotte billedet med de forudsagte afgrænsningsbokse, tekstnavne for hvert objekt osv. Tjek den docstring, der følger med predict () – metoden for at blive fortrolig med, hvad der er tilgængeligt for os:

du bør forvente, at din model kun vil kunne registrere objekttyper, der er strengt begrænset til COCO-datasættet. For at vide, hvilke objekttyper en forududdannet YOLO-model er i stand til at opdage, skal du tjekke coco_classes.tekstfil tilgængelig i … / yolo-v4-tf.kers / class_names/. Der er 80 objekttyper derinde.
Sådan træner du din brugerdefinerede Yolo objektdetekteringsmodel
Opgaveerklæring

for at designe en objektdetekteringsmodel skal du vide, hvilke objekttyper du vil registrere. Dette bør være et begrænset antal objekttyper, som du vil oprette din detektor til. Det er godt at have en liste over objekttyper udarbejdet, når vi flytter til den faktiske modeludvikling.
ideelt set bør du også have et kommenteret datasæt, der har objekter af din interesse. Dette datasæt vil blive brugt til at træne en detektor og validere den. Hvis du endnu ikke har enten et datasæt eller en kommentar til det, skal du ikke bekymre dig, Jeg viser dig, hvor og hvordan du kan få det.
datasæt& kommentarer
hvor kan man hente data fra
hvis du har et kommenteret datasæt at arbejde med, skal du bare springe denne del over og gå videre til næste kapitel. Men hvis du har brug for et datasæt til dit projekt, skal vi nu undersøge online ressourcer, hvor du kan få data.
det betyder ikke rigtig noget, hvilket felt du arbejder i, der er en stor chance for, at der allerede er et open source-datasæt, som du kan bruge til dit projekt.
den første ressource, jeg anbefaler, er artiklen “50+ Objektdetekteringsdatasæt fra forskellige branchedomæner” af Abhishek Annamraju, der har samlet vidunderlige kommenterede datasæt til industrier som mode, detailhandel, sport, medicin og mange flere.

kilde til billedet.
andre to gode steder at kigge efter dataene er paperswithcode.com og roboflow.com som giver adgang til datasæt af høj kvalitet til objektdetektering.
tjek disse ovenstående aktiver for at indsamle de data, du har brug for, eller for at berige det datasæt, du allerede har.
sådan kommenteres data til YOLO
hvis dit datasæt med billeder kommer uden kommentarer, skal du selv udføre annotationsjobbet. Denne manuelle betjening er ret tidskrævende, så sørg for at have tid nok til at gøre det.
som et annotationsværktøj kan du overveje flere muligheder. Personligt vil jeg anbefale at bruge LabelImg. Det er en letvægts og nem at bruge billede annotation værktøj, der direkte kan output anmærkninger til YOLO modeller.
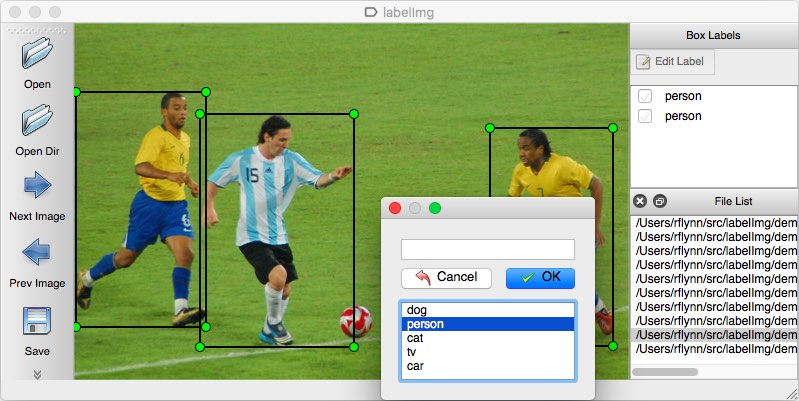
kilde til billedet.
sådan transformeres data fra andre formater til YOLO
kommentarer til YOLO er i form af tekstfiler. Hver linje i en tekstfil fol YOLO skal have følgende format:
image1.jpg 10,15,345,284,0image2.jpg 100,94,613,814,0 31,420,220,540,1
vi kan opdele hver linje fra tekstfilen og se, hvad den består af:
- den første del af en linje angiver basenavnene for billederne: image1.jpg, image2.jpg
- den anden del af en linje definerer afgrænsningsboksens koordinater og klassemærket. For eksempel 10,15,345,284,0 stater for hmin,ymin, hmaks,hmaks, class_id
- hvis et givet billede har mere end et objekt på det, vil der være flere kasser og klasseetiketter ved siden af billedbasenavnet divideret med et mellemrum.
afgrænsningskoordinater er et klart koncept, men hvad med det class_id-nummer, der angiver klassemærket? Hver class_id er knyttet til en bestemt klasse i en anden tekstfil. For eksempel kommer præ-uddannet YOLO med coco_classes.fil, der ser sådan ud:
personbicyclecarmotorbikeaeroplanebus...
antal linjer i klasserne filer skal matche antallet af klasser, som din detektor vil opdage. Nummerering starter fra nul, hvilket betyder, at class_id-nummeret for den første klasse i klassefilen bliver 0. Klasse, der er placeret på den anden linje i klassen tekstfil vil have nummer 1.
nu ved du hvordan annotationen til YOLO ser ud. For at fortsætte med at oprette en brugerdefineret objektdetektor opfordrer jeg dig til at gøre to ting nu:
- Opret en klasser tekstfil, hvor du vil palads af de klasser, som du vil have din detektor til at opdage. Husk, at klasseordre betyder noget.
- Opret en tekstfil med kommentarer. Hvis du allerede har annotation, men i VOC-format (.Kan du bruge denne fil til at omdanne fra YOLO til YOLO.
opdeling af data i undergrupper
som altid ønsker vi at opdele datasættet i 2 undergrupper: til træning og til validering. Det kan gøres så simpelt som:
from utils import read_annotation_lines train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1)
oprettelse af datageneratorer
når dataene er opdelt, kan vi gå videre til datageneratorens initialisering. Vi har en datagenerator for hver datafil. I vores tilfælde har vi en generator til træningsdelen og til valideringsdelen.
Sådan oprettes datageneratorerne:
from utils import DataGenerator FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
for at opsummere alt, her er hvad den komplette kode til dataopdeling og generatoroprettelse ser ud:
from utils import read_annotation_lines, DataGenerator train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1) FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
Installation & opsætning kræves til model træning
lad os tale om de forudsætninger, der er afgørende for at oprette din egen objektdetektor:
- du skal have Python allerede installeret på din computer. Hvis du har brug for at installere det, anbefaler jeg at følge denne officielle vejledning af Anaconda;
- hvis din computer har en CUDA-aktiveret GPU (en GPU lavet af NVIDIA), er der brug for et par relevante biblioteker for at understøtte GPU-baseret træning. Hvis du har brug for at aktivere GPU-support, skal du kontrollere retningslinjerne på Nvidias hjemmeside. Dit mål er at installere den nyeste version af både CUDA Toolkit, og cuDNN til dit operativsystem;
- du ønsker måske at organisere et uafhængigt virtuelt miljø at arbejde i. Dette projekt kræver Tensorstrøm 2 installeret. Alle andre biblioteker vil blive introduceret senere;
- hvad angår mig, byggede og trænede jeg min YOLOv4-model i et Jupyter Notebook-udviklingsmiljø. Selvom Jupyter Notebook virker som en rimelig mulighed at gå med, overveje udvikling i en IDE efter eget valg, hvis du ønsker det.
Model træning

forudsætninger
nu skal du have:
- en opdeling til dit datasæt;
- to datageneratorer initialiseret;
- en tekstfil med klasserne.
initialisering af Modelobjekt
for at gøre dig klar til et træningsjob skal du initialisere yolov4-modelobjektet. Sørg for, at du bruger ingen som en værdi for parameteren vægt_path. Du skal også angive en sti til din klassetekstfil på dette trin. Her er den initialiseringskode, jeg brugte i mit projekt:
class_name_path = 'path2project_folder/model_data/scans_file.txt' model = Yolov4(weight_path=None, class_name_path=class_name_path)
ovenstående modelinitialisering fører til oprettelse af et modelobjekt med et standard sæt parametre. Overvej at ændre konfigurationen af din model ved at sende en ordbog som en værdi til parameteren config model.

Config angiver et sæt parametre til YOLOv4-modellen.
standardmodelkonfiguration er et godt udgangspunkt, men du vil måske eksperimentere med andre configs for bedre modelkvalitet.
især anbefaler jeg stærkt at eksperimentere med ankre og img_størrelse. Ankre angiver geometrien for de ankre, der skal bruges til at fange objekter. Jo bedre formerne på ankrene passer til objektets former, jo højere vil modelydelsen være.
forøgelse af img_størrelse kan også være nyttigt i nogle tilfælde. Husk, at jo højere billedet er, jo længere vil modellen gøre indledningen.
hvis du gerne vil bruge Neptune som et sporingsværktøj, skal du også initialisere en eksperimentkørsel som denne:
import neptune.new as neptune run = neptune.init(project='projects/my_project', api_token=my_token)
definition af tilbagekald
Tensorstrøm & Keras lad os bruge tilbagekald til at overvåge træningsforløbet, foretage kontrolpunkter og styre træningsparametre (f.eks.
før du monterer din model, skal du definere tilbagekald, der vil være nyttige til dine formål. Sørg for at angive stier til at gemme model checkpoints og tilknyttede logfiler. Sådan gjorde jeg det i et af mine projekter:
# defining pathes and callbacks dir4saving = 'path2checkpoint/checkpoints'os.makedirs(dir4saving, exist_ok = True) logdir = 'path4logdir/logs'os.makedirs(logdir, exist_ok = True) name4saving = 'epoch_{epoch:02d}-val_loss-{val_loss:.4f}.hdf5' filepath = os.path.join(dir4saving, name4saving) rLrCallBack = keras.callbacks.ReduceLROnPlateau(monitor = 'val_loss', factor = 0.1, patience = 5, verbose = 1) tbCallBack = keras.callbacks.TensorBoard(log_dir = logdir, histogram_freq = 0, write_graph = False, write_images = False) mcCallBack_loss = keras.callbacks.ModelCheckpoint(filepath, monitor = 'val_loss', verbose = 1, save_best_only = True, save_weights_only = False, mode = 'auto', period = 1)esCallBack = keras.callbacks.EarlyStopping(monitor = 'val_loss', mode = 'min', verbose = 1, patience = 10)
du kunne have bemærket, at i ovenstående tilbagekald sæt Tensorbræt bruges som et sporingsværktøj. Overvej at bruge Neptune som et meget mere avanceret værktøj til eksperimentsporing. I så fald skal du ikke glemme at initialisere et andet tilbagekald for at aktivere integration med Neptune:
from neptune.new.integrations.tensorflow_keras import NeptuneCallback neptune_cbk = NeptuneCallback(run=run, base_namespace='metrics')
montering af model
for at starte træningsjobbet skal du blot montere modelobjektet ved hjælp af standard fit () – metoden i Tensorstrøm / Keras. Sådan begyndte jeg at træne min model:
model.fit(data_gen_train, initial_epoch=0, epochs=10000, val_data_gen=data_gen_val, callbacks= )
når træningen er startet, vil du se en standard statuslinje.

træningsprocessen vil evaluere modellen i slutningen af hver epoke. Hvis du bruger et sæt tilbagekald, der ligner det, jeg initialiserede og passerede under montering, gemmes de kontrolpunkter, der viser modelforbedring med hensyn til lavere tab, i en bestemt mappe.
hvis der ikke opstår fejl, og træningsprocessen går glat, stoppes træningsjobbet enten på grund af afslutningen af træningsepoch-nummeret, eller hvis det tidlige stopopkald ikke registrerer nogen yderligere modelforbedring og stopper den samlede proces.
under alle omstændigheder skal du ende med flere modelkontrolpunkter. Vi ønsker at vælge den bedste blandt alle tilgængelige og bruge den til slutning.
trænet brugerdefineret model i inferenstilstand
at køre en trænet model i inferenstilstand svarer til at køre en forududdannet model ud af kassen.

du initialiserer et modelobjekt, der passerer i stien til det bedste kontrolpunkt samt stien til tekstfilen med klasserne. Sådan ser modelinitialisering ud for mit projekt:
from models import Yolov4model = Yolov4(weight_path='path2checkpoint/checkpoints/epoch_48-val_loss-0.061.hdf5', class_name_path='path2classes_file/my_yolo_classes.txt')
når modellen initialiseres, skal du blot bruge predict () – metoden til et billede efter eget valg for at få forudsigelserne. Som en sammenfatning returneres detektioner, som modellen er lavet i en bekvem form af en pandas DataFrame. Vi får klassens navn, boksstørrelse og koordinater for hvert detekteret objekt.
konklusioner
du har lige lært, hvordan du opretter en brugerdefineret YOLOv4 objektdetektor. Vi er gået over end-to-end-processen, startende fra dataindsamling, annotation og transformation. Du har nok viden om den fjerde YOLO-version, og hvordan den adskiller sig fra andre detektorer.
intet forhindrer dig nu i at træne din egen model i Tensorstrøm og Keras. Du ved, hvor du kan få en forududdannet model fra, og hvordan du starter træningsjobbet.
i min kommende artikel vil jeg vise dig nogle af de bedste fremgangsmåder og livshacks, der hjælper med at forbedre kvaliteten af den endelige model. Bliv hos os!



Anton Morgunov
Computer Vision ingeniør på Basis.Center
Machine Learning entusiast. Lidenskabelig om computersyn. Ingen papir – flere træer! Arbejde hen imod eliminering af papirkopi ved at flytte til fuld digitalisering!
læs næste
TENSORSTRØMSOBJEKTDETEKTERING API: bedste praksis til træning, evaluering & implementering
13 minutter læst | forfatter Anton Morgunov | opdateret 28.maj 2021
denne artikel er den anden del af en serie, hvor du lærer en Slut-til-slut-arbejdsgang til Tensorstrømsobjektdetektering og dens API. I den første artikel lærte du, hvordan du opretter en brugerdefineret objektdetektor fra bunden, men der er stadig masser af ting, der har brug for din opmærksomhed for at blive virkelig dygtige.
vi undersøger emner, der er lige så vigtige som den modeloprettelsesproces, vi allerede har gennemgået. Her er nogle af de spørgsmål, vi besvarer:
- hvordan vurderer jeg min model og får et skøn over dens ydeevne?
- hvilke værktøjer kan jeg bruge til at spore modelydelse og sammenligne resultater på tværs af flere eksperimenter?
- Hvordan kan jeg eksportere min model til at bruge den i inferensmodus?
- er der en måde at øge modelydelsen endnu mere på?
Fortsæt læsning ->