
zdroj: Přeplňujte své modely počítačového vidění pomocí API pro detekci objektů TensorFlow,
Jonathan Huang, výzkumný vědec a Vivek Rathod, softwarový inženýr,
Google AI Blog
- detekce objektů jako úkol v počítačovém vidění
- YOLO jako detektor objektů v reálném čase
- co je YOLO?
- YOLO ve srovnání s jinými detektory
- verze YOLO
- příklady aplikací YOLO
- YOLO jako detektor objektů v TensorFlow & Keras
- TensorFlow & keras frameworks in Machine Learning
- implementace YOLO v TensorFlow & Keras
- jak spustit předem vyškolený YOLO out-of-the-box a získat výsledky
- jak trénovat svůj vlastní model detekce objektů YOLO
- prohlášení o úloze
- Dataset & anotace
- kde získat data z
- jak anotovat data pro YOLO
- jak transformovat data z jiných formátů na Yolo
- rozdělení dat do podmnožin
- vytvoření generátorů dat
- instalace & nastavení potřebné pro školení modelů
- modelové školení
- předpoklady
- inicializace objektu modelu
- definování callbacků
- montáž modelu
- vyškolený vlastní model v inferenčním režimu
- závěry
- Anton Morgunov
- TensorFlow Object Detection API: Best Practices to Training, Evaluation & nasazení
detekce objektů jako úkol v počítačovém vidění
s objekty se setkáváme každý den v našem životě. Rozhlédněte se kolem sebe a najdete několik objektů, které vás obklopují. Jako člověk můžete snadno detekovat a identifikovat každý objekt, který vidíte. Je to přirozené a nevyžaduje mnoho úsilí.
pro počítače je však detekce objektů úkolem, který vyžaduje komplexní řešení. Pro počítač „detekovat objekty“ znamená zpracovat vstupní obraz (nebo jeden snímek z videa) a reagovat s informacemi o objektech na obrázku a jejich poloze. Z hlediska počítačového vidění nazýváme tyto dva úkoly klasifikací a lokalizací. Chceme, aby počítač řekl, jaké objekty jsou prezentovány na daném obrázku a kde přesně se nacházejí.
bylo vyvinuto několik řešení, která pomáhají počítačům detekovat objekty. Dnes budeme zkoumat nejmodernější algoritmus zvaný YOLO, který dosahuje vysoké přesnosti při rychlosti v reálném čase. Zejména se naučíme, jak tento algoritmus trénovat na vlastní datové sadě v TensorFlow / Keras.
nejprve se podívejme, co přesně je YOLO a co je slavné.
YOLO jako detektor objektů v reálném čase
co je YOLO?
YOLO je zkratka pro „you Only Look Once“ (nezaměňujte ji s tím, že žijete pouze jednou ze Simpsonových). Jak název napovídá, jediný „vzhled“ stačí k nalezení všech objektů na obrázku a jejich identifikaci.
z hlediska strojového učení můžeme říci, že všechny objekty jsou detekovány pomocí jediného běhu algoritmu. Je to dělením obrazu do mřížky a předpovídáním ohraničujících políček a pravděpodobnosti tříd pro každou buňku v mřížce. V případě, že bychom chtěli zaměstnat YOLO pro detekci automobilů, tady je to, jak by mohla vypadat mřížka a předpokládaná ohraničující pole:

ohraničující rámeček, který YOLO předpovídá pro první auto, je červený.
ohraničující rámeček, který YOLO předpovídá pro druhé auto, je žlutý.
Zdroj obrázku.
výše uvedený obrázek obsahuje pouze konečnou sadu polí získaných po filtrování. Stojí za zmínku, že Yolo surový výstup obsahuje mnoho ohraničujících polí pro stejný objekt. Tyto krabice se liší tvarem a velikostí. Jak můžete vidět na obrázku níže, některé boxy jsou lepší při zachycení cílového objektu, zatímco jiné nabízené algoritmem fungují špatně.

všechny žluté boxy jsou pro druhé auto.
tučné červené a žluté boxy jsou nejlepší pro detekci automobilů.
Zdroj obrázku.
pro výběr nejlepšího ohraničovacího pole pro daný objekt se použije algoritmus bez maximálního potlačení (NMS).

boxy předpovídané pro automobily, aby zůstaly pouze ty, které nejlépe zachycují objekty.
Zdroj obrázku.
všechny boxy, které Yolo předpovídá, mají s nimi spojenou úroveň spolehlivosti. NMS používá tyto hodnoty spolehlivosti k odstranění krabic, které byly předpovězeny s nízkou jistotou. Obvykle se jedná o všechny krabice, které jsou předpovězeny s jistotou pod 0,5.

skóre spolehlivosti můžete vidět v levém horním rohu každého pole vedle názvu objektu.
Zdroj obrázku.
po odstranění všech nejistých ohraničujících políček zůstanou pouze krabice s vysokou úrovní spolehlivosti. Chcete-li vybrat ten nejlepší z nejvýkonnějších kandidátů, NMS vybere pole s nejvyšší úrovní spolehlivosti a vypočítá, jak se protíná s ostatními políčky kolem. Pokud je průsečík vyšší než určitá prahová úroveň, odstraní se ohraničující rámeček s nižší jistotou. V případě, že NMS porovná dvě políčka, která mají průsečík pod zvolenou prahovou hodnotou, jsou obě políčka uložena v konečných předpovědích.
YOLO ve srovnání s jinými detektory
přestože se pod kapotou YOLO používá konvoluční neuronová síť (CNN), je stále schopna detekovat objekty s výkonem v reálném čase. Je to možné díky YOLOVĚ schopnosti provádět předpovědi současně v jednostupňovém přístupu.
jiné pomalejší algoritmy pro detekci objektů (jako rychlejší R-CNN) obvykle používají dvoustupňový přístup:
- v první fázi jsou vybrány zajímavé obrazové oblasti. Toto jsou části obrazu, které mohou obsahovat libovolné objekty;
- ve druhé fázi je každá z těchto oblastí klasifikována pomocí konvoluční neuronové sítě.
obvykle je na obrázku s objekty mnoho oblastí. Všechny tyto regiony jsou odeslány do klasifikace. Klasifikace je časově náročná operace, a proto dvoustupňový přístup detekce objektů funguje pomaleji ve srovnání s jednostupňovou detekcí.
YOLO nevybere zajímavé části obrázku, není to nutné. Místo toho předpovídá ohraničující políčka a třídy pro celý obraz v jediném průchodu vpřed.
níže vidíte, jak rychle je YOLO ve srovnání s jinými populárními detektory.

SSD a YOLO jsou jednostupňové detektory objektů, zatímco Faster-RCNN
a R-FCN jsou dvoustupňové detektory objektů.
Zdroj obrázku.
verze YOLO
YOLO poprvé představil v roce 2015 Joseph Redmon ve své výzkumné práci s názvem „you Only Look Once: Unified, real-Time Object Detection“.
od té doby se YOLO hodně vyvinulo. V roce 2016 Joseph Redmon popsal druhou verzi YOLO v „YOLO9000: lepší, rychlejší, silnější“.
asi dva roky po druhé aktualizaci YOLO přišel Joseph s dalším upgradem sítě. Jeho práce s názvem „YOLOv3: Inkrementální zlepšení“ upoutala pozornost mnoha počítačových inženýrů a stala se populární v komunitě strojového učení.
v roce 2020 se Joseph Redmon rozhodl přestat zkoumat počítačové vidění, ale nezabránilo tomu, aby byl Yolo vyvíjen jinými. Téhož roku navrhl tým tří inženýrů (Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao) čtvrtou verzi YOLO, ještě rychlejší a přesnější než dříve. Jejich nálezy jsou popsány v “ YOLOv4: Optimální rychlost a přesnost detekce objektů “ článek, který zveřejnili 23. Dubna 2020.
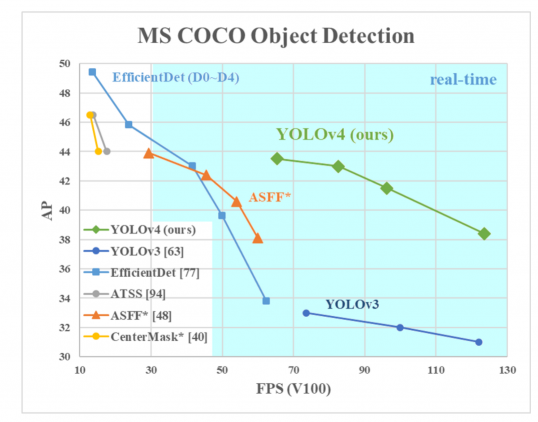
AP na ose Y je metrika zvaná „průměrná přesnost“. Popisuje přesnost sítě.
FPS (snímků za sekundu) na ose X je metrika, která popisuje rychlost.
Zdroj obrázku.
dva měsíce po vydání 4. verze oznámil nezávislý vývojář Glenn Jocher 5. verzi YOLO. Tentokrát nebyl publikován Žádný výzkumný dokument. Síť byla k dispozici na Jocherově stránce GitHub jako implementace PyTorch. Pátá verze měla téměř stejnou přesnost jako čtvrtá verze, ale byla rychlejší.
a konečně, v červenci 2020 jsme dostali další velkou aktualizaci YOLO. V článku s názvem „PP-YOLO: efektivní a efektivní implementace detektoru objektů“, Xiang Long a tým přišli s novou verzí YOLO. Tato iterace YOLO byla založena na verzi 3. modelu a překročila výkon YOLO v4.

mapa na ose Y je metrika zvaná „střední průměrná přesnost“. Popisuje přesnost sítě.
FPS (snímků za sekundu) na ose X je metrika, která popisuje rychlost.
Zdroj obrázku.
v tomto tutoriálu se blíže podíváme na YOLOv4 a jeho implementaci. Proč YOLOv4? Tři důvody:
- má široké schválení v komunitě strojového učení;
- Tato verze prokázala svůj vysoký výkon v široké škále detekčních úkolů;
- YOLOv4 byl implementován do několika populárních rámců, včetně TensorFlow a Keras, se kterými budeme pracovat.
příklady aplikací YOLO
než přejdeme k praktické části tohoto článku, implementujeme náš vlastní detektor objektů založený na YOLO, rád bych vám ukázal pár skvělých implementací YOLOv4 a pak provedeme naši implementaci.
věnujte pozornost tomu, jak rychlé a přesné jsou předpovědi!
zde je první působivý příklad toho, co YOLOv4 dokáže, detekce více objektů z různých herních a filmových scén.
Alternativně můžete zkontrolovat toto demo detekce objektů z pohledu kamery v reálném životě.
YOLO jako detektor objektů v TensorFlow & Keras
TensorFlow & keras frameworks in Machine Learning

Zdroj obrázku.
rámce jsou nezbytné v každé oblasti informačních technologií. Strojové učení není výjimkou. Na trhu ML existuje několik zavedených hráčů, kteří nám pomáhají zjednodušit celkovou zkušenost s programováním. PyTorch, scikit-learn, TensorFlow, Keras, MXNet a Caffe jsou jen některé, které stojí za zmínku.
dnes budeme úzce spolupracovat s TensorFlow/Keras. Není divu, že tito dva patří mezi nejoblíbenější rámce ve vesmíru strojového učení. Je to z velké části způsobeno skutečností, že TensorFlow i Keras poskytují bohaté možnosti pro vývoj. Tyto dva rámce jsou velmi podobné. Aniž bychom se příliš zabývali detaily, je třeba si uvědomit, že Keras je jen obal pro rámec TensorFlow.
implementace YOLO v TensorFlow & Keras
v době psaní tohoto článku bylo na backendu TensorFlow / Keras 808 repozitářů s implementacemi YOLO. YOLO verze 4 je to, co budeme implementovat. Omezením vyhledávání pouze na YOLO v4 jsem dostal 55 úložišť.
pečlivě procházel všechny z nich, našel jsem zajímavého kandidáta pokračovat.
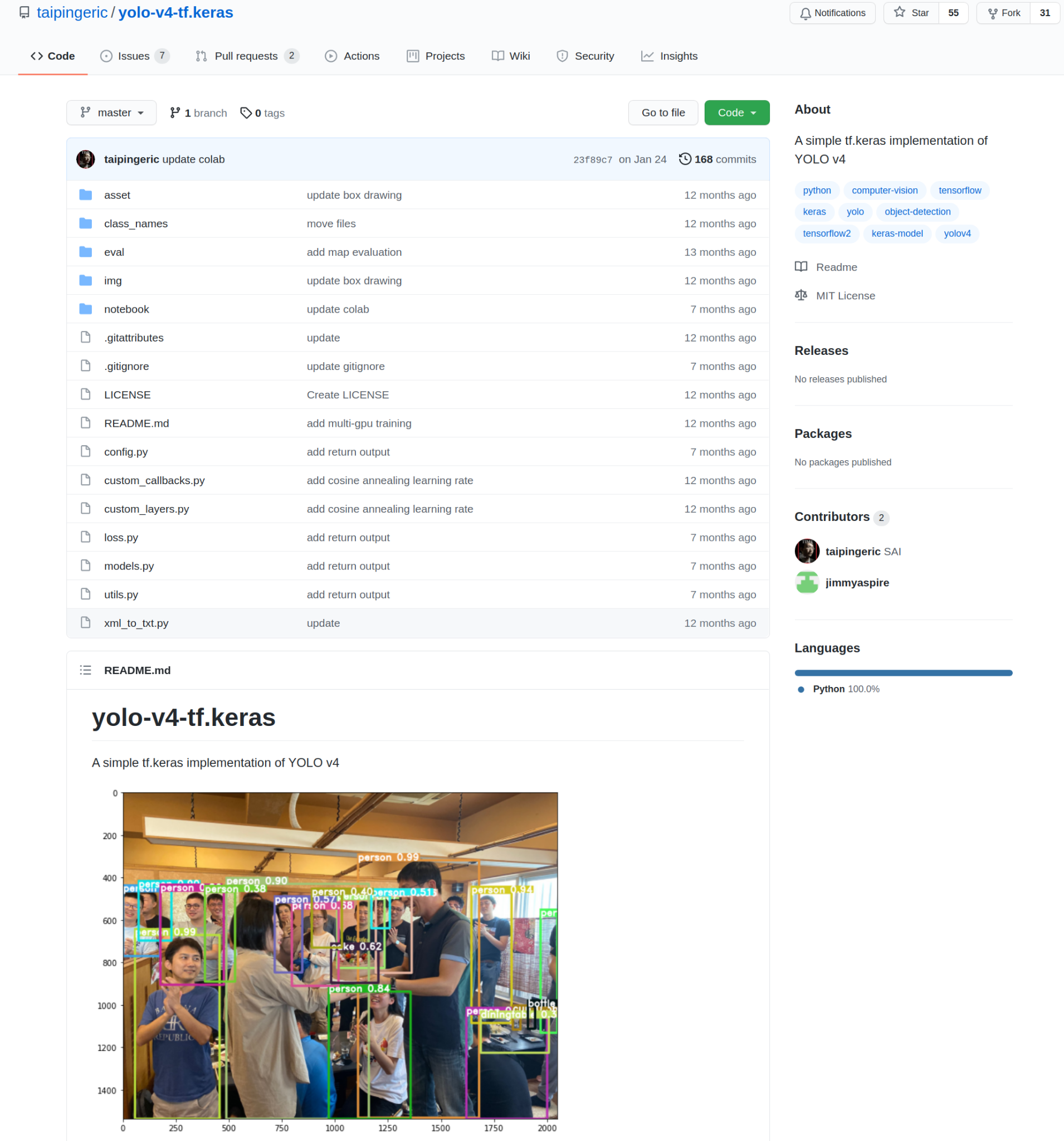
Zdroj obrázku.
Tato implementace byla vyvinuta taipingeric a jimmyaspire. Je to docela jednoduché a velmi intuitivní, pokud jste dříve pracovali s TensorFlow a Keras.
Chcete-li začít pracovat s touto implementací, stačí klonovat repo do místního počítače. Dále vám ukážu, jak používat YOLO po vybalení z krabice a jak trénovat svůj vlastní detektor objektů.
jak spustit předem vyškolený YOLO out-of-the-box a získat výsledky
při pohledu na sekci“ rychlý Start “ repo můžete vidět, že pro uvedení modelu do provozu stačí importovat YOLO jako objekt třídy a načíst do hmotnosti modelu:
from models import Yolov4model = Yolov4(weight_path='yolov4.weights', class_name_path='class_names/coco_classes.txt')
Všimněte si, že musíte ručně stáhnout závaží modelu předem. Soubor modelových hmotností, který je dodáván s YOLO, pochází z datové sady COCO a je k dispozici na oficiální stránce projektu AlexeyAB darknet na Githubu. Váhy si můžete stáhnout přímo prostřednictvím tohoto odkazu.
ihned poté je model plně připraven pracovat s obrázky v režimu inference. Stačí použít metodu predict () pro obrázek dle vašeho výběru. Metoda je standardní pro rámce TensorFlow a keras.
pred = model.predict('input.jpg')
například pro tento vstupní obraz:

mám následující modelový výstup:

předpovědi, že model vyrobený jsou vráceny ve vhodné formě pandas DataFrame. Získáme název třídy, velikost pole a souřadnice pro každý detekovaný objekt:

spousta užitečných informací o zjištěných objektech
v metodě predict() existuje více parametrů, které nám umožňují určit, zda chceme vykreslit obrázek s předpovězenými ohraničujícími rámečky, textovými názvy pro každý objekt atd. Podívejte se na docstring, který jde spolu s metodou predict (), abyste se seznámili s tím, co máme k dispozici:

měli byste očekávat, že váš model bude schopen detekovat pouze typy objektů, které jsou přísně omezeny na datovou sadu Coco. Chcete-li vědět, jaké typy objektů je předem vyškolený model YOLO schopen detekovat, podívejte se na coco_classes.txt soubor dostupný v … / yolo-v4-tf.kers / class_names/. Je tam 80 typů objektů.
jak trénovat svůj vlastní model detekce objektů YOLO
prohlášení o úloze

Chcete-li navrhnout model detekce objektů, musíte vědět, jaké typy objektů chcete detekovat. Mělo by to být omezený počet typů objektů, pro které chcete vytvořit detektor. Je dobré mít připravený seznam typů objektů, když přejdeme ke skutečnému vývoji modelu.
v ideálním případě byste měli mít také anotovaný datový soubor, který obsahuje objekty Vašeho zájmu. Tato datová sada bude použita k trénování detektoru a jeho ověření. Pokud ještě nemáte datovou sadu nebo anotaci, nebojte se, ukážu vám, kde a jak ji můžete získat.
Dataset & anotace
kde získat data z
pokud máte anotovanou datasetovou sadu pro práci, přeskočte tuto část a přejděte k další kapitole. Pokud však pro svůj projekt potřebujete datovou sadu, nyní prozkoumáme online zdroje, kde můžete získat data.
nezáleží na tom, v jakém oboru pracujete, existuje velká šance, že již existuje soubor dat s otevřeným zdrojovým kódem, který můžete použít pro svůj projekt.
první zdroj, který doporučuji, je článek“ 50 + datových souborů detekce objektů z různých průmyslových domén “ od Abhishek Annamraju, který shromáždil nádherné anotované datové sady pro průmyslová odvětví, jako je Móda, Maloobchod, Sport, medicína a mnoho dalších.

Zdroj obrázku.
další dvě skvělá místa pro vyhledávání dat jsou paperswithcode.com a roboflow.com které poskytují přístup k vysoce kvalitním datovým sadám pro detekci objektů.
podívejte se na výše uvedená aktiva a sbírejte potřebná data nebo obohatte datovou sadu, kterou již máte.
jak anotovat data pro YOLO
pokud vaše datová sada obrázků přichází bez anotací, musíte provést anotační práci sami. Tento ruční provoz je poměrně časově náročný, takže se ujistěte, že máte dostatek času na to.
jako nástroj pro anotaci můžete zvážit více možností. Osobně bych doporučil používat LabelImg. Je to lehký a snadno použitelný nástroj pro anotaci obrázků, který může přímo vytvářet anotace pro modely YOLO.
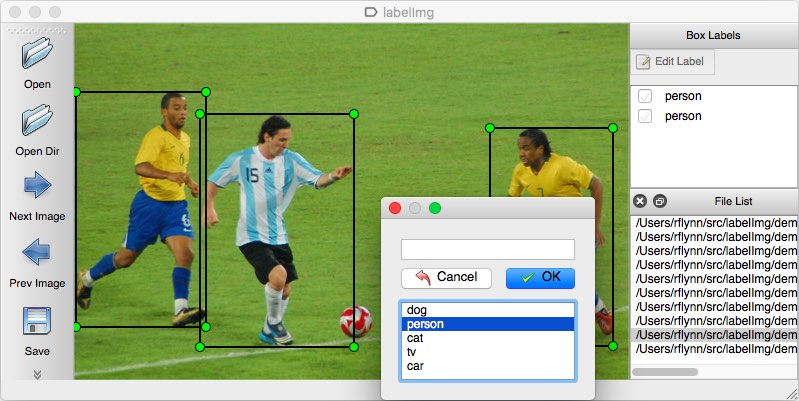
Zdroj obrázku.
jak transformovat data z jiných formátů na Yolo
anotace pro YOLO jsou ve formě souborů txt. Každý řádek v souboru txt fol YOLO musí mít následující formát:
image1.jpg 10,15,345,284,0image2.jpg 100,94,613,814,0 31,420,220,540,1
můžeme rozdělit každý řádek ze souboru txt a zjistit, z čeho se skládá:
- první část řádku určuje základní názvy obrázků: image1.jpg, image2.jpg
- druhá část řádku definuje souřadnice ohraničujícího pole a štítek třídy. Například 10,15,345,284,0 stavy pro xmin, ymin, xmax, ymax, class_id
- pokud má daný obrázek více než jeden objekt, bude vedle základního názvu obrázku více políček a štítků tříd, děleno mezerou.
souřadnice ohraničujícího pole jsou jasným konceptem,ale co číslo class_id, které určuje štítek třídy? Každý class_id je spojen s určitou třídou v jiném souboru txt. Například předem vyškolený YOLO přichází s coco_classes.txt soubor, který vypadá takto:
personbicyclecarmotorbikeaeroplanebus...
počet řádků v souborech tříd musí odpovídat počtu tříd, které váš detektor detekuje. Číslování začíná od nuly, což znamená, že číslo class_id pro první třídu v souboru classes bude 0. Třída, která je umístěna na druhém řádku v souboru classes txt, bude mít číslo 1.
nyní víte, jak vypadá anotace pro YOLO. Chcete-li pokračovat ve vytváření vlastního detektoru objektů, vyzývám vás, abyste nyní udělali dvě věci:
- vytvořte soubor txt tříd, kde budete mít přehled o třídách, které má detektor detekovat. Pamatujte, že na pořadí tříd záleží.
- Vytvořte soubor txt s anotacemi. V případě, že již máte anotaci, ale ve formátu VOC (.XMLs), můžete použít tento soubor k transformaci z XML na YOLO.
rozdělení dat do podmnožin
jako vždy chceme datovou sadu rozdělit na 2 podmnožiny: pro školení a validaci. To může být provedeno tak jednoduché, jak:
from utils import read_annotation_lines train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1)
vytvoření generátorů dat
když jsou data rozdělena, můžeme přistoupit k inicializaci generátoru dat. Budeme mít generátor dat pro každý datový soubor. V našem případě budeme mít generátor pro podmnožinu školení a pro podmnožinu ověření.
zde je návod, jak jsou generátory dat vytvořeny:
from utils import DataGenerator FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
abych to shrnul, tady je to, jak vypadá kompletní kód pro rozdělení dat a vytvoření generátoru:
from utils import read_annotation_lines, DataGenerator train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1) FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
instalace & nastavení potřebné pro školení modelů
pojďme se bavit o předpokladech, které jsou nezbytné pro vytvoření vlastního detektoru objektů:
- v počítači byste měli mít již nainstalovaný Python. V případě, že ji potřebujete nainstalovat, doporučuji postupovat podle tohoto oficiálního průvodce Anaconda;
- pokud má váš počítač GPU s podporou CUDA (GPU od společnosti NVIDIA), je zapotřebí několik relevantních knihoven, aby bylo možné podporovat školení založené na GPU. V případě, že potřebujete povolit podporu GPU, podívejte se na pokyny na webových stránkách NVIDIA. Vaším cílem je nainstalovat nejnovější verzi sady nástrojů CUDA a cuDNN pro váš operační systém;
- možná budete chtít uspořádat nezávislé virtuální prostředí, ve kterém budete pracovat. Tento projekt vyžaduje instalaci TensorFlow 2. Všechny ostatní knihovny budou představeny později;
- pokud jde o mě, stavěl jsem a trénoval svůj model YOLOv4 ve vývojovém prostředí notebooku Jupyter. Přestože se notebook Jupyter jeví jako rozumná možnost, zvažte vývoj v IDE podle vašeho výběru, pokud si přejete.
modelové školení

předpoklady
Nyní byste měli mít:
- rozdělení pro vaši datovou sadu;
- inicializovány dva generátory dat;
- soubor txt s třídami.
inicializace objektu modelu
Chcete-li se připravit na tréninkovou úlohu, inicializujte objekt modelu YOLOv4. Ujistěte se, že používáte None jako hodnotu pro parametr weight_path. V tomto kroku byste také měli poskytnout cestu k souboru txt tříd. Zde je inicializační kód, který jsem použil ve svém projektu:
class_name_path = 'path2project_folder/model_data/scans_file.txt' model = Yolov4(weight_path=None, class_name_path=class_name_path)
výše uvedená inicializace modelu vede k vytvoření objektu modelu s výchozí sadou parametrů. Zvažte změnu konfigurace vašeho modelu předáním slovníku jako hodnoty parametru config model.

Config určuje sadu parametrů pro model YOLOv4.
výchozí konfigurace modelu je dobrým výchozím bodem, ale možná budete chtít experimentovat s jinými konfiguracemi pro lepší kvalitu modelu.
zejména vřele doporučuji experimentovat s kotvami a img_size. Kotvy určují geometrii kotev, které budou použity k zachycení objektů. Čím lepší tvary kotev odpovídají tvarům objektů, tím vyšší bude výkon modelu.
zvýšení img_size může být v některých případech také užitečné. Mějte na paměti, že čím vyšší je obraz, tím déle model provede závěr.
v případě, že byste chtěli použít Neptun jako sledovací nástroj, měli byste také inicializovat běh experimentu, jako je tento:
import neptune.new as neptune run = neptune.init(project='projects/my_project', api_token=my_token)
definování callbacků
TensorFlow & Keras nám umožňuje pomocí callbacků sledovat průběh tréninku, provádět kontrolní body a spravovat tréninkové parametry (např. rychlost učení).
před montáží modelu definujte zpětná volání, která budou užitečná pro vaše účely. Nezapomeňte zadat cesty pro uložení kontrolních bodů modelu a přidružených protokolů. Zde je návod, jak jsem to udělal v jednom z mých projektů:
# defining pathes and callbacks dir4saving = 'path2checkpoint/checkpoints'os.makedirs(dir4saving, exist_ok = True) logdir = 'path4logdir/logs'os.makedirs(logdir, exist_ok = True) name4saving = 'epoch_{epoch:02d}-val_loss-{val_loss:.4f}.hdf5' filepath = os.path.join(dir4saving, name4saving) rLrCallBack = keras.callbacks.ReduceLROnPlateau(monitor = 'val_loss', factor = 0.1, patience = 5, verbose = 1) tbCallBack = keras.callbacks.TensorBoard(log_dir = logdir, histogram_freq = 0, write_graph = False, write_images = False) mcCallBack_loss = keras.callbacks.ModelCheckpoint(filepath, monitor = 'val_loss', verbose = 1, save_best_only = True, save_weights_only = False, mode = 'auto', period = 1)esCallBack = keras.callbacks.EarlyStopping(monitor = 'val_loss', mode = 'min', verbose = 1, patience = 10)
mohli jste si všimnout, že ve výše uvedených zpětných vazbách se TensorBoard používá jako sledovací nástroj. Zvažte použití Neptunu jako mnohem pokročilejšího nástroje pro sledování experimentů. Pokud ano, nezapomeňte inicializovat další zpětné volání, abyste umožnili integraci s Neptunem:
from neptune.new.integrations.tensorflow_keras import NeptuneCallback neptune_cbk = NeptuneCallback(run=run, base_namespace='metrics')
montáž modelu
Chcete-li zahájit tréninkovou práci, jednoduše namontujte objekt modelu pomocí standardní metody fit() v TensorFlow / Keras. Zde je návod, jak jsem začal trénovat svůj model:
model.fit(data_gen_train, initial_epoch=0, epochs=10000, val_data_gen=data_gen_val, callbacks= )
po zahájení tréninku uvidíte standardní ukazatel průběhu.

tréninkový proces vyhodnotí model na konci každé epochy. Pokud použijete sadu zpětných volání podobnou tomu, co jsem inicializoval a předal při montáži, budou kontrolní body, které ukazují zlepšení modelu z hlediska nižší ztráty, uloženy do zadaného adresáře.
pokud nedojde k žádným chybám a tréninkový proces probíhá hladce, tréninková práce bude zastavena buď kvůli konci čísla tréninkových epoch, nebo pokud včasné zastavení zpětného volání nezjistí žádné další zlepšení modelu a zastaví celkový proces.
v každém případě byste měli skončit s více kontrolními body modelu. Chceme vybrat ten nejlepší ze všech dostupných a použít jej pro odvození.
vyškolený vlastní model v inferenčním režimu
spuštění vyškoleného modelu v inferenčním režimu je podobné spuštění předem vyškoleného modelu z krabice.

inicializujete objekt modelu, který prochází cestou k nejlepšímu kontrolnímu bodu, stejně jako cestu k souboru txt s třídami. Takto vypadá inicializace modelu pro můj projekt:
from models import Yolov4model = Yolov4(weight_path='path2checkpoint/checkpoints/epoch_48-val_loss-0.061.hdf5', class_name_path='path2classes_file/my_yolo_classes.txt')
když je model inicializován, jednoduše použijte metodu predict () pro obrázek podle vašeho výběru, abyste získali předpovědi. Jako rekapitulaci, detekce, že model vyrobený jsou vráceny ve vhodné formě pandas DataFrame. Získáme název třídy, velikost pole a souřadnice pro každý detekovaný objekt.
závěry
právě jste se naučili, jak vytvořit vlastní detektor objektů YOLOv4. Prošli jsme procesem end-to-end, počínaje sběrem dat, anotací a transformací. Máte dostatek znalostí o čtvrté verzi YOLO a o tom, jak se liší od ostatních detektorů.
nic vám nyní nebrání v tréninku vlastního modelu v TensorFlow a Keras. Víte, odkud získat předem vyškolený model a jak zahájit tréninkovou práci.
v mém nadcházejícím článku vám ukážu některé z osvědčených postupů a životních hacků, které pomohou zlepšit kvalitu konečného modelu. Zůstaňte s námi!



Anton Morgunov
Computer Vision Engineer at Basis.Centrum
nadšenec strojového učení. Vášnivý pro počítačové vidění. Žádný papír-více stromů! Práce na odstranění papírové kopie přechodem na plnou digitalizaci!
přečtěte si další
TensorFlow Object Detection API: Best Practices to Training, Evaluation & nasazení
13 mins read / autor Anton Morgunov / Aktualizováno 28. května 2021
tento článek je druhou částí série, kde se naučíte end to end workflow pro detekci objektů TensorFlow a jeho API. V prvním článku jste se naučili, jak vytvořit vlastní detektor objektů od nuly, ale stále existuje spousta věcí, které potřebují vaši pozornost, aby se staly skutečně zdatnými.
prozkoumáme témata, která jsou stejně důležitá jako proces vytváření modelu, kterým jsme již prošli. Zde jsou některé z otázek, na které odpovíme:
- jak zhodnotit svůj model a získat odhad jeho výkonu?
- jaké jsou nástroje, které mohu použít ke sledování výkonu modelu a porovnání výsledků napříč více experimenty?
- Jak mohu exportovat svůj model pro použití v režimu inference?
- existuje způsob, jak zvýšit výkon modelu ještě více?
pokračovat ve čtení ->