bugetul Crawl este numărul de pagini pe care motoarele de căutare le vor accesa cu crawlere pe un site web într-un anumit interval de timp.
motoarele de căutare calculează bugetul de accesare cu crawlere pe baza limitei de accesare cu crawlere (cât de des pot accesa cu crawlere fără a cauza probleme) și a cererii de accesare cu crawlere (cât de des ar dori să acceseze cu crawlere un site).
dacă pierdeți bugetul de accesare cu crawlere, motoarele de căutare nu vor putea accesa cu crawlere site-ul dvs. eficient, ceea ce ar ajunge să vă afecteze performanța SEO.
- ce este bugetul crawl?
- de ce motoarele de căutare atribuie buget de accesare cu crawlere site-urilor web?
- cum atribuie bugetul de accesare cu crawlere site-urilor web?
- bugetul de accesare cu crawlere este doar despre pagini?
- cum funcționează în practică crawl limit / host load?
- cum funcționează în practică cererea de accesare cu crawlere / programarea cu crawlere?
- nu uitați: capacitatea de accesare cu crawlere a sistemului în sine
- De ce ar trebui să vă pese de bugetul crawl?
- care este bugetul de accesare cu crawlere pentru site-ul meu?
- buget de accesare cu crawlere în Google Search Console
- accesați sursa: jurnalele serverului
- cum vă optimizați bugetul de accesare cu crawlere?
- adresele URL accesibile cu parametrii
- conținut duplicat
- conținut de calitate scăzută
- link-uri rupte și redirecționarea
- URL-uri incorecte în sitemaps XML
- ContentKing
- pagini cu timpi mari de încărcare / timeout
- număr mare de pagini neindexabile
- Bad intern link structura
- cum creșteți bugetul de accesare cu crawlere al site-ului dvs. web?
- Întrebări frecvente despre bugetul crawl
- 1. Ce este bugetul crawl?
- 2. Cum pot crește bugetul meu de accesare cu crawlere?
- 3. Ce poate limita bugetul meu de accesare cu crawlere?
- 4. Ar trebui să folosesc URL-ul canonic și roboții meta?
ce este bugetul crawl?
bugetul de accesare cu crawlere este numărul de pagini pe care motoarele de căutare le vor accesa cu crawlere pe un site web într-un anumit interval de timp.
de ce motoarele de căutare atribuie buget de accesare cu crawlere site-urilor web?
pentru că nu au resurse nelimitate și își împart atenția pe milioane de site-uri web. Deci, au nevoie de o modalitate de a-și prioritiza efortul de târâre. Atribuirea bugetului de accesare cu crawlere fiecărui site web îi ajută să facă acest lucru.
cum atribuie bugetul de accesare cu crawlere site-urilor web?
care se bazează pe doi factori, limita de accesare cu crawlere și cererea de accesare cu crawlere:
- Crawl limit / host load: cât de mult crawling poate gestiona un site web și care sunt preferințele proprietarului său?
- cerere Accesare Cu Crawlere / programare accesare cu crawlere: care URL-uri sunt în valoare de (re)accesare cu crawlere cel mai mult, pe baza popularității sale și cât de des este actualizat.
bugetul Crawl este un termen comun în SEO. Bugetul de accesare cu crawlere este uneori denumit și spațiu de accesare cu crawlere sau timp de accesare cu crawlere.

bugetul de accesare cu crawlere este doar despre pagini?
nu este de fapt, de dragul ușurinței vorbim despre pagini, dar în realitate este vorba despre orice document pe care motoarele de căutare îl accesează cu crawlere. Câteva exemple de alte documente: fișiere JavaScript și CSS, variante de pagini mobile, variante hreflang și fișiere PDF.
cum funcționează în practică crawl limit / host load?
limita de accesare cu crawlere sau încărcarea gazdei, dacă doriți, este o parte importantă a bugetului de accesare cu crawlere. Crawlerele motoarelor de căutare sunt concepute pentru a preveni supraîncărcarea unui server web cu solicitări, astfel încât să fie atenți la acest lucru.Cum determină motoarele de căutare limita de accesare cu crawlere a unui site web? Există o varietate de factori care influențează limita de accesare cu crawlere. Pentru a numi câteva:
- semne de platformă în formă proastă: cât de des a solicitat timeout URL-uri sau erori de server de returnare.
- cantitatea de site-uri web care rulează pe gazdă: dacă site-ul dvs. web rulează pe o platformă de găzduire partajată cu sute de alte site-uri web și aveți un site web destul de mare, limita de accesare cu crawlere pentru site-ul dvs. web este foarte limitată, deoarece limita de accesare cu crawlere este determinată la nivel de gazdă. Trebuie să partajați limita de accesare cu crawlere a gazdei cu toate celelalte site-uri care rulează pe ea. În acest caz, veți fi mult mai bine pe un server dedicat, ceea ce va reduce, de asemenea, masiv timpii de încărcare pentru vizitatorii dvs.
un alt lucru de luat în considerare este să aveți site-uri mobile și desktop separate care rulează pe aceeași gazdă. Au și o limită comună de accesare cu crawlere. Așa că ține minte asta.
sunt motoarele de căutare crawling cele mai importante părți ale site-ului? Rulați un test rapid cu ContentKing!
cum funcționează în practică cererea de accesare cu crawlere / programarea cu crawlere?
cererea de accesare cu crawlere, sau programarea cu crawlere, se referă la determinarea valorii adreselor URL re-crawling. Din nou, mulți factori influențează cererea de accesare cu crawlere, printre care:
- Popularitate: câte linkuri interne și externe de intrare are o adresă URL, dar și cantitatea de interogări pentru care se clasează.
- prospețime: cât de des URL-ul este actualizat.
- tip de pagină: este tipul de pagină care se poate schimba. Luați, de exemplu, o pagină de categorii de produse și o pagină de termeni și condiții – care credeți că se schimbă cel mai des și merită să fie accesat cu crawlere mai frecvent?

forțarea crawlerelor Google să revină pe site-ul dvs. atunci când nu este nimic mai important de găsit (adică o schimbare semnificativă) nu este o strategie bună și sunt destul de deștepți să stabilească dacă frecvența acestor pagini care se schimbă adaugă de fapt valoare. Cel mai bun sfat pe care l-aș putea da este să mă concentrez pe a face paginile mai importante (adăugarea de informații mai utile, îmbogățirea conținutului paginilor (acestea vor declanșa în mod natural mai multe interogări în mod implicit, atâta timp cât focalizarea unui subiect este menținută). Declanșând în mod natural mai multe interogări ca parte a ‘rechemare’ (afișări), faceți paginile dvs. mai importante și iată: probabil că veți fi accesate cu crawlere mai frecvent.
nu uitați: capacitatea de accesare cu crawlere a sistemului în sine
în timp ce sistemele de accesare cu crawlere a motoarelor de căutare au o capacitate masivă de accesare cu crawlere, la sfârșitul zilei este limitată. Deci, într-un scenariu în care 80% din centrele de date Google merg offline în același timp, capacitatea lor de accesare cu crawlere scade masiv și, la rândul său, bugetul de accesare cu crawlere al tuturor site-urilor web.
mulțumiri masive pentru Dawn Anderson (se deschide într-o filă nouă) pentru a ne oferi detalii despre limita de accesare cu crawlere, cererea de accesare cu crawlere și capacitatea de accesare cu crawlere!
De ce ar trebui să vă pese de bugetul crawl?
doriți ca motoarele de căutare să găsească și să înțeleagă cât mai multe dintre paginile dvs. indexabile și doriți ca acestea să facă acest lucru cât mai repede posibil. Când adăugați pagini noi și actualizați cele existente, doriți ca motoarele de căutare să le ridice cât mai curând posibil. Cu cât au indexat mai repede paginile, cu atât mai repede puteți beneficia de ele.
dacă pierdeți bugetul de accesare cu crawlere, motoarele de căutare nu vor putea accesa cu crawlere site-ul dvs. eficient. Vor petrece timp pe părți ale site-ului dvs. care nu contează, ceea ce poate duce la lăsarea unor părți importante ale site-ului dvs. nedescoperite. Dacă nu știu despre pagini, nu le vor accesa cu crawlere și indexa și nu veți putea aduce vizitatori prin intermediul motoarelor de căutare.
puteți vedea unde duce acest lucru: irosirea bugetului de accesare cu crawlere vă dăunează performanței SEO.
vă rugăm să rețineți că bugetul de accesare cu crawlere este, în general, doar ceva de care să vă faceți griji dacă aveți un site web mare, să spunem 10.000 de pagini și peste.

unul dintre aspectele mai puțin apreciate ale bugetului de accesare cu crawlere este viteza de încărcare. Un site web cu încărcare mai rapidă înseamnă că Google poate accesa cu crawlere mai multe adrese URL în același timp. Recent am fost implicat cu un upgrade site-ul în cazul în care viteza de încărcare a fost un accent major. Noul site s-a încărcat de două ori mai repede decât cel vechi. Când a fost împins în direct, numărul de adrese URL pe care Google le – a accesat pe zi a crescut de la 150.000 la 600.000-și a rămas acolo. Pentru un site de această dimensiune și domeniu de aplicare, rata îmbunătățită de accesare cu crawlere înseamnă că conținutul nou și modificat este accesat cu crawlere mult mai rapid și vedem un impact mult mai rapid al eforturilor noastre SEO în SERP-uri.

un SEO foarte înțelept (bine, a fost AJ Kohn (se deschide într-o filă nouă)) a spus odată faimos „tu ești ceea ce mănâncă Googlebot.”. Clasamentul dvs. și vizibilitatea căutării sunt direct legate nu numai de ceea ce Google accesează cu crawlere pe site-ul dvs., ci frecvent, cât de des îl accesează cu crawlere. Dacă Google ratează conținutul de pe site-ul dvs. sau nu accesează URL-uri importante suficient de frecvent din cauza bugetului limitat/neoptimizat de accesare cu crawlere, atunci veți avea un timp foarte greu de clasat într-adevăr. Pentru site-urile mai mari, optimizarea bugetului de accesare cu crawlere poate crește foarte mult profilul paginilor invizibile anterior. În timp ce site-ul mai mic trebuie să vă faceți griji mai puțin despre bugetul crawl, aceleași principii de optimizare (viteză, prioritizare, structura link-ul, de-duplicarea, etc.) vă poate ajuta în continuare să rang.

în mare parte sunt de acord cu Google și, în cea mai mare parte, multe site-uri web nu trebuie să vă faceți griji cu privire la bugetul de accesare cu crawlere. Dar pentru site-urile web de dimensiuni mari și mai ales cele care sunt actualizate frecvent, cum ar fi editorii, optimizarea poate face o diferență semnificativă.
care este bugetul de accesare cu crawlere pentru site-ul meu?
dintre toate motoarele de căutare, Google este cel mai transparent cu privire la bugetul lor de accesare cu crawlere pentru site-ul dvs. web.
buget de accesare cu crawlere în Google Search Console
dacă aveți site-ul dvs. verificat în Google Search Console, puteți obține informații despre bugetul de accesare cu crawlere al site-ului dvs. pentru Google.
urmați acești pași:
- Conectați-vă la Google Search Console și alegeți un site web.
- Mergi la
Crawl>Crawl Stats. Acolo puteți vedea numărul de pagini pe care Google le accesează cu crawlere pe zi.
în vara anului 2016, bugetul nostru de accesare cu crawlere arăta astfel:
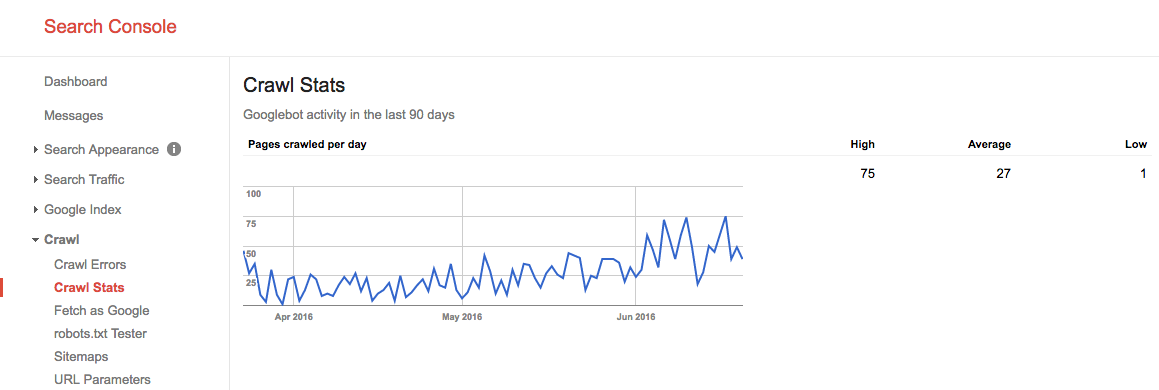
vedem aici că bugetul mediu de accesare cu crawlere este de 27 de pagini / zi. Deci, în teorie, dacă acest buget mediu de accesare cu crawlere rămâne același, ați avea un buget lunar de accesare cu crawlere de 27 de pagini x 30 de zile = 810 pagini.
Fast forward 2 ani, si uita-te la ceea ce bugetul nostru crawl este chiar acum:
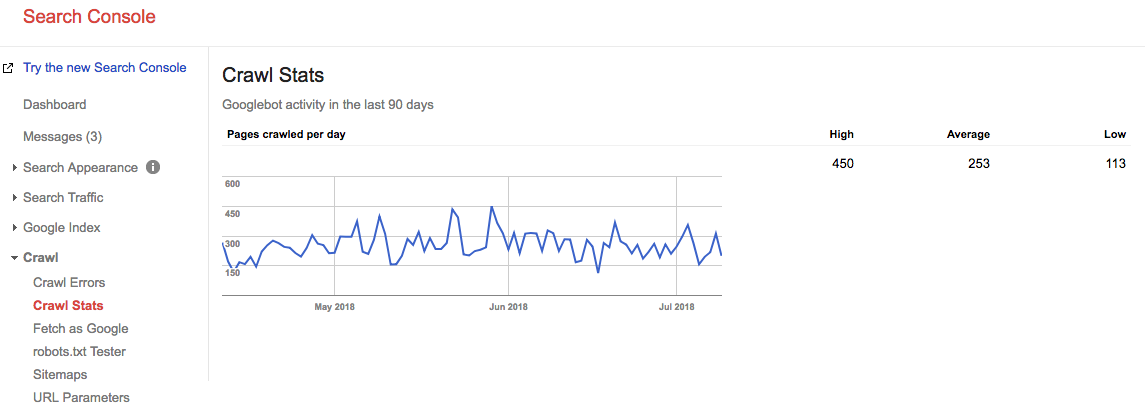
bugetul nostru mediu de accesare cu crawlere este de 253 de pagini / zi, deci puteți spune că bugetul nostru de accesare cu crawlere a crescut de 10 ori în 2 ani.
accesați sursa: jurnalele serverului
este foarte interesant să verificați jurnalele serverului pentru a vedea cât de des accesează Crawlerele Google site-ul dvs. web. Este interesant să comparăm aceste statistici cu cele raportate în Google Search Console. Este întotdeauna mai bine să te bazezi pe mai multe surse.
nu lăsați problemele de crawl să fie o oportunitate ratată. Monitoriza continuu site-ul dvs. cu ContentKing și să fie alertat cu privire la problemele în timp real.
cum vă optimizați bugetul de accesare cu crawlere?
Optimizarea bugetului dvs. de accesare cu crawlere se reduce la asigurarea faptului că niciun buget de accesare cu crawlere nu este irosit. În esență, stabilirea motivelor pentru bugetul de accesare cu crawlere irosit. Monitorizăm mii de site-uri web; dacă ar fi să verificați fiecare dintre ele pentru probleme de buget cu crawlere, ați vedea rapid un model: majoritatea site-urilor web suferă de același tip de probleme.
motive comune pentru bugetul de accesare cu crawlere irosit pe care le întâlnim:
- URL-uri accesibile cu parametri: un exemplu de URL cu un parametru este
https://www.example.com/toys/cars?color=black. În acest caz, parametrul este utilizat pentru a stoca selecția unui vizitator într-un filtru de produs. - conținut duplicat: numim pagini care sunt foarte similare, sau Exact la fel, „conținut duplicat.”Exemplele sunt: pagini copiate, pagini cu rezultate interne ale căutării și pagini de etichete.
- conținut de calitate scăzută: pagini cu conținut foarte mic sau pagini care nu adaugă nicio valoare.
- link-uri rupte și redirecționare: link-urile rupte sunt linkuri care fac referire la pagini care nu mai există, iar link-urile redirecționate sunt linkuri către URL-uri care redirecționează către alte URL-uri.
- includerea URL-urilor incorecte în Sitemap-urile XML: paginile care nu pot fi indexate și paginile care nu pot fi indexate, cum ar fi adresele URL 3xx, 4xx și 5xx, nu ar trebui incluse în sitemap-ul XML.
- pagini cu timp de încărcare mare / time-out: paginile care necesită mult timp pentru a se încărca sau nu se încarcă deloc au un impact negativ asupra bugetului dvs. de accesare cu crawlere, deoarece este un semn pentru motoarele de căutare că site-ul dvs. web nu poate gestiona solicitarea și, prin urmare, vă pot ajusta limita de accesare cu crawlere.
- număr mare de pagini care nu pot fi indexate: site-ul web conține o mulțime de pagini care nu pot fi indexate.
- structură de legături interne necorespunzătoare: dacă structura de legături interne nu este configurată corect, este posibil ca motoarele de căutare să nu acorde suficientă atenție unora dintre paginile dvs.

am spus de multe ori că Google este ca șeful tău. Nu ai intra într-o întâlnire cu șeful tău decât dacă ai ști despre ce vei vorbi, cele mai importante momente ale muncii tale, obiectivele întâlnirii tale. Pe scurt, veți avea o agendă. Când intri în „biroul” Google, ai nevoie de același lucru. O ierarhie clară a site-ului, fără o mulțime de cruft, un sitemap XML util și timpi de răspuns rapid vor ajuta Google să ajungă la ceea ce este important. Nu treceți cu vederea acest element adesea greșit înțeles al SEO.

pentru mine, conceptul de buget crawl este unul dintre punctele cheie ale SEO-ului tehnic. Când optimizați pentru bugetul de accesare cu crawlere, orice altceva intră în vigoare: legarea internă, Remedierea erorilor, viteza paginii, optimizarea adresei URL, conținutul de calitate scăzută și multe altele. Oamenii ar trebui să sape în fișierele lor jurnal mai des pentru a monitoriza bugetul crawl pentru anumite URL-uri, subdomenii, director, etc. Monitorizarea frecvenței de accesare cu crawlere este foarte legată de bugetul de accesare cu crawlere și super puternic.
adresele URL accesibile cu parametrii
în majoritatea cazurilor, adresele URL cu parametri nu ar trebui să fie accesibile pentru motoarele de căutare, deoarece pot genera o cantitate practic infinită de adrese URL.Am scris pe larg despre acest tip de problemă în articolul nostru despre capcanele pe șenile.
adresele URL cu parametri sunt utilizate în mod obișnuit la implementarea filtrelor de produse pe site-urile de comerț electronic. Este bine să le folosească,; doar asigurați-vă că acestea nu sunt accesibile pentru motoarele de căutare.
cum le puteți face inaccesibile motorului de căutare?
- folosiți-vă roboții.fișier txt pentru a instrui motoarele de căutare să nu acceseze astfel de adrese URL. Dacă aceasta nu este o opțiune dintr-un anumit motiv, utilizați setările de gestionare a parametrilor URL din Google Search Console și Bing Webmaster Tools pentru a instrui Google și Bing cu privire la ce pagini să nu acceseze cu crawlere.
- adăugați valoarea atributului nofollow la linkurile de pe linkurile de filtrare. Vă rugăm să rețineți că, începând cu martie 2020, Google poate alege să ignore nofollow. Prin urmare, pasul 1 este și mai important.
conținut duplicat
nu doriți ca motorul de căutare să-și petreacă timpul pe pagini de conținut duplicat, deci este important să preveniți sau cel puțin să minimalizați conținutul duplicat din site-ul dvs.
cum faci asta? Prin…
- Configurarea redirecționărilor site-ului web pentru toate variantele de domeniu(
HTTP,HTTPS,non-WWW, șiWWW). - făcând paginile cu rezultate interne ale căutării inaccesibile motoarelor de căutare folosind roboții dvs.txt. Iată un exemplu de roboți.txt pentru un site web WordPress.
- dezactivarea paginilor dedicate pentru imagini (de exemplu: infamele pagini de atașare a imaginilor din WordPress).
- fiind atent în jurul valorii de utilizarea de taxonomii, cum ar fi categorii și tag-uri.
consultați câteva motive mai tehnice pentru conținutul duplicat și cum să le remediați.
conținut de calitate scăzută
paginile cu conținut foarte mic nu sunt interesante pentru motoarele de căutare. Păstrați-le la minimum sau evitați-le complet, dacă este posibil. Un exemplu de conținut de calitate scăzută este o secțiune de întrebări frecvente cu linkuri pentru a afișa întrebările și răspunsurile, unde fiecare întrebare și răspuns este servit pe o adresă URL separată.
link-uri rupte și redirecționarea
link-uri rupte și lanțuri lungi de redirecționări sunt fundături pentru motoarele de căutare. Similar cu browserele, Google pare să urmeze maximum cinci redirecționări înlănțuite într-un singur crawl (pot relua accesarea cu crawlere mai târziu). Nu este clar cât de bine alte motoare de căutare se ocupă de redirecționările ulterioare, dar vă sfătuim cu tărie să evitați redirecționările înlănțuite în întregime și să mențineți utilizarea redirecționărilor la minimum.
este clar că prin remedierea linkurilor rupte și redirecționarea linkurilor, puteți recupera rapid bugetul de accesare cu crawlere irosit. Pe lângă recuperarea bugetului de accesare cu crawlere, îmbunătățiți în mod semnificativ experiența utilizatorului unui vizitator. Redirecționările și, în special, lanțurile de redirecționări provoacă un timp mai lung de încărcare a paginii și, prin urmare, afectează experiența utilizatorului.
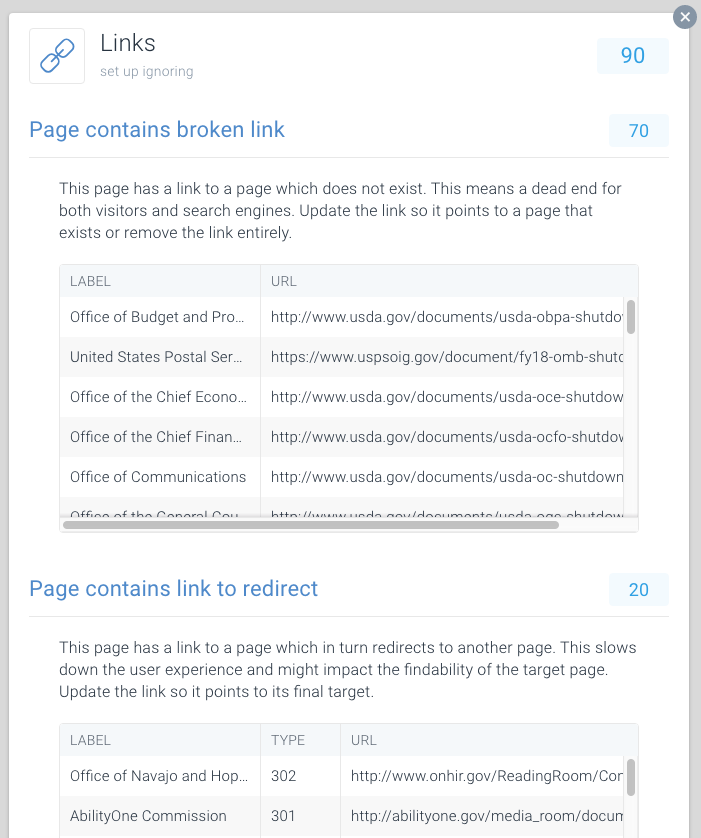
pentru a facilita găsirea legăturilor rupte și redirecționarea, am dedicat Probleme Speciale acestui lucru în cadrul ContentKing.
mergeți la Issues > Links pentru a afla dacă pierdeți bugetele de accesare cu crawlere din cauza legăturilor defecte. Actualizați fiecare legătură astfel încât să se conecteze la o pagină indexabilă sau eliminați linkul dacă nu mai este necesar.
URL-uri incorecte în sitemaps XML
toate URL-urile incluse în Sitemaps XML ar trebui să fie pentru pagini indexabile. Mai ales cu site-uri mari, motoarele de căutare se bazează foarte mult pe sitemap-uri XML pentru a găsi toate paginile dvs. Dacă Sitemap-urile XML sunt aglomerate cu pagini care, de exemplu, nu mai există sau redirecționează, pierdeți bugetul de accesare cu crawlere. Verificați în mod regulat sitemap-ul XML pentru URL-uri non-indexabile care nu aparțin acolo. Verificați și opusul: căutați pagini care sunt excluse incorect din sitemap-ul XML. Sitemap XML este o modalitate foarte bună de a ajuta motoarele de căutare cheltui bugetul crawl cu înțelepciune.
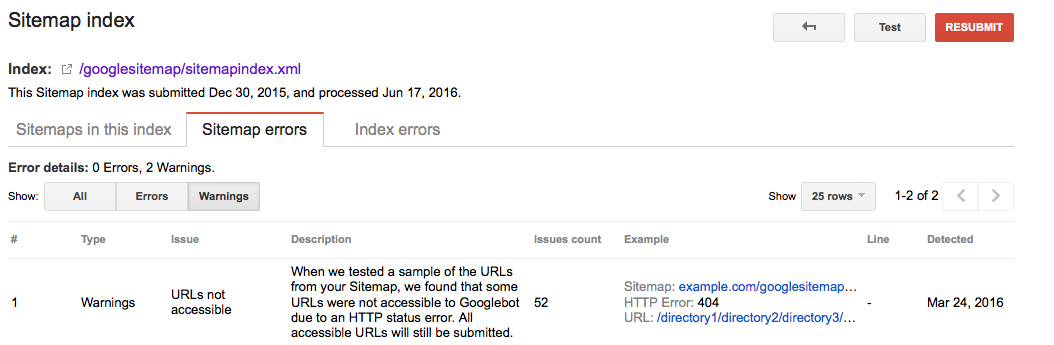
Google Searche Console
- Conectați-vă la Google Search Console
- Faceți clic pe fila
Crawl - Faceți clic pe fila
Sitemaps
Bing Webmaster Tools
- Conectați-vă la contul Bing Webmaster Tools
- Faceți clic pe fila
Configure My Site - Faceți clic pe fila
Sitemaps
ContentKing
- Conectați-vă la contul dvs. ContentKing
- Faceți clic pe butonul
Issues - Faceți clic pe butonul
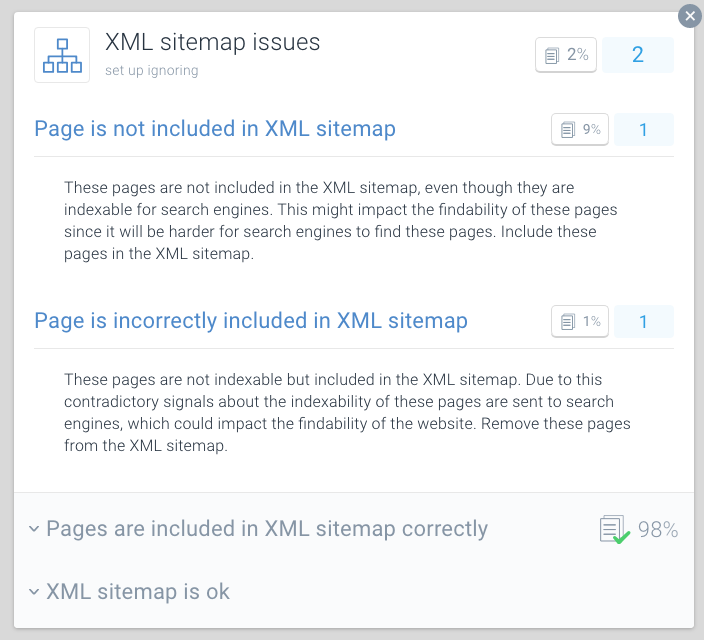
XML Sitemap - în cazul unor probleme cu pagina dvs., veți primi acest mesaj:
Page is incorrectly included in XML sitemap
una dintre cele mai bune practici pentru optimizarea bugetului crawl este de a împărți sitemap XML în sus în sitemap-uri mai mici. De exemplu, puteți crea sitemap-uri XML pentru fiecare secțiune a site-ului dvs. web. Dacă ați făcut acest lucru, puteți determina rapid dacă există probleme în anumite secțiuni ale site-ului dvs. web.
spune sitemap-ul XML pentru secțiunea A conține 500 de link-uri, și 480 sunt indexate: atunci faci destul de bine. XML pentru secțiunea B conține 500 de linkuri și doar 120 sunt indexate, este ceva de analizat. Este posibil să fi inclus o mulțime de URL-uri non-indexabile în sitemap XML pentru secțiunea B.
condițiile proaste pentru crawlere vă pot afecta SEO. Utilizați ContentKing pentru a rula un audit rapid al site-ului dvs. web.
pagini cu timpi mari de încărcare / timeout

când paginile au timpi mari de încărcare sau expiră, motoarele de căutare pot vizita mai puține pagini în cadrul bugetului alocat de accesare cu crawlere pentru site-ul dvs. web. Pe lângă acest dezavantaj, timpii mari de încărcare a paginii și timeout-urile afectează semnificativ experiența utilizatorului vizitatorului dvs., rezultând o rată de conversie mai mică.
timpii de încărcare a paginii peste două secunde reprezintă o problemă. În mod ideal, pagina dvs. se va încărca în mai puțin de o secundă. Verificați periodic timpul de încărcare a paginii cu instrumente precum Pingdom (se deschide într-o filă nouă), WebPagetest (se deschide într-o filă nouă) sau GTmetrix (se deschide într-o filă nouă).
Google raportează timpul de încărcare a paginii atât în Google Analytics (sub Behavior > Site Speed) și Google Search Console sub Crawl > Crawl Stats.
Google Search Console și Bing Webmaster Tools raportează ambele la expirarea paginii. În Google Search Console, acest lucru poate fi găsit sub Crawl > Crawl Errors, și în Bing Webmaster Tools, este sub Reports & Data > Crawl Information.
verificați în mod regulat dacă paginile dvs. se încarcă suficient de repede și luați măsuri imediat dacă nu. Încărcarea rapidă a paginilor este vitală pentru succesul dvs. online.
număr mare de pagini neindexabile
dacă site-ul dvs. web conține un număr mare de pagini neindexabile care sunt accesibile motoarelor de căutare, practic mențineți motoarele de căutare ocupate cu cernerea paginilor irelevante.
considerăm următoarele tipuri de pagini care nu pot fi indexate:
- redirecționări (3xx)
- pagini care nu pot fi găsite (4xx)
- pagini cu erori de server (5xx)
- pagini care nu sunt indexabile (pagini care conțin roboți noindex Directiva sau canonical URL)
pentru a afla dacă aveți un număr mare de pagini care nu pot fi indexate, căutați numărul total de pagini pe care crawlerele le-au găsit pe site-ul dvs. web și modul în care acestea se descompun. Puteți face acest lucru cu ușurință folosind ContentKing:
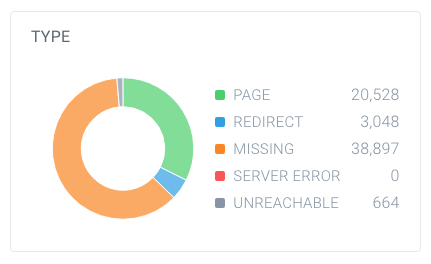
în acest exemplu, există 63,137 URL-uri găsite, din care doar 20,528 sunt pagini.
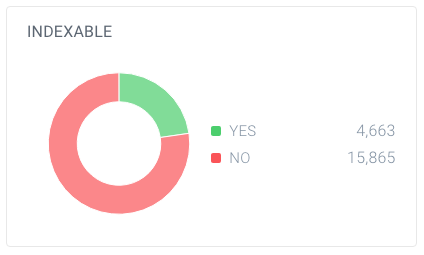
și din aceste pagini, doar 4.663 sunt indexabile pentru motoarele de căutare. Doar 7,4% din adresele URL găsite de ContentKing pot fi indexate de motoarele de căutare. Acesta nu este un raport bun, iar acest site web trebuie să lucreze cu siguranță la acest lucru, curățând toate referințele la acestea care nu sunt necesare, inclusiv:
- XML sitemap (a se vedea secțiunea anterioară)
- link-uri
- URL-uri canonice
- Hreflang referințe
- referințe paginare (link rel prev / next)
Bad intern link structura
cum pagini în site-ul dvs. link-ul unul de altul joacă un rol important în optimizarea bugetului crawl. Noi numim acest lucru structura internă link-ul de site-ul dumneavoastră. Backlink-urile deoparte, paginile care au puține link-uri interne primesc mult mai puțină atenție din partea motoarelor de căutare decât paginile care sunt legate de o mulțime de pagini.
evitați o structură de legături foarte ierarhică, paginile din mijloc având puține legături. În multe cazuri, aceste pagini nu vor fi frecvent accesate cu crawlere. Este și mai rău pentru paginile din partea de jos a ierarhiei: din cauza cantității limitate de linkuri, acestea pot fi foarte bine neglijate de motoarele de căutare.
asigurați-vă că paginile dvs. cele mai importante au o mulțime de link-uri interne. Paginile care au fost recent accesate cu crawlere de obicei rang mai bine în motoarele de căutare. Rețineți acest lucru și ajustați structura internă a legăturilor pentru aceasta.
de exemplu, dacă aveți un articol de blog datând din 2011 care generează mult trafic organic, asigurați-vă că continuați să vă conectați la acesta din alt conținut. Deoarece ați produs multe alte articole de blog de-a lungul anilor, acel articol din 2011 este automat împins în jos în structura internă a link-ului site-ului dvs. web.

de obicei, nu trebuie să vă faceți griji cu privire la rata de accesare cu crawlere a paginilor dvs. importante. De obicei, paginile sunt noi, la care nu v-ați conectat și la care oamenii nu merg, ceea ce poate să nu fie accesat cu crawlere des.
cum creșteți bugetul de accesare cu crawlere al site-ului dvs. web?
în timpul unui interviu (se deschide într-o filă nouă) între Eric Enge și fostul șef Google al echipei Webspam Matt Cutts, relația dintre autoritate și bugetul crawl a fost ridicată:

cel mai bun mod de a gândi este că numărul de pagini pe care le accesăm cu crawlere este aproximativ proporțional cu PageRank-ul dvs. Deci, dacă aveți o mulțime de link-uri primite pe pagina dvs. rădăcină, cu siguranță vom accesa cu crawlere acest lucru. Apoi, pagina dvs. rădăcină se poate conecta la alte pagini, iar acestea vor primi PageRank și le vom accesa cu crawlere și pe acestea. Cu toate acestea, pe măsură ce vă adânciți din ce în ce mai mult în site-ul dvs., PageRank tinde să scadă.
chiar dacă Google a abandonat actualizarea valorilor PageRank ale paginilor în mod public, credem că (o formă de) PageRank este încă utilizată în algoritmii lor. Deoarece PageRank este un termen greșit înțeles și confuz, să-l numim Autoritatea paginii. Preluarea aici este că Matt Cutts spune practic: există o relație destul de puternică între autoritatea paginii și bugetul de accesare cu crawlere.
deci, pentru a crește bugetul de accesare cu crawlere al site-ului dvs. web, trebuie să creșteți autoritatea site-ului dvs. web. O mare parte din acest lucru se face prin câștigarea mai multe link-uri de la site-uri externe. Mai multe informații despre acest lucru pot fi găsite în ghidul nostru de construire a linkurilor.

când aud industria vorbind despre bugetul de accesare cu crawlere, vorbim de obicei despre modificările de pe pagină și tehnice pe care le putem face pentru a crește bugetul de accesare cu crawlere în timp. Cu toate acestea, provenind dintr-un fundal de construire a linkurilor, cele mai mari vârfuri din paginile cu crawlere pe care le vedem în Google Search Console se referă direct la momentul în care câștigăm linkuri mari pentru clienții noștri.
Întrebări frecvente despre bugetul crawl
- 🧾 ce este bugetul crawl?
- 🤔 Cum îmi cresc crawl buget?
- XV ce poate limita bugetul meu de accesare cu crawlere?
- ar trebui să folosesc URL canonic și meta roboți?
1. Ce este bugetul crawl?
bugetul de accesare cu crawlere este numărul de pagini pe care motoarele de căutare le vor accesa cu crawlere pe un site web într-un anumit interval de timp.
2. Cum pot crește bugetul meu de accesare cu crawlere?
Google a indicat că există o relație puternică între autoritatea paginii și bugetul de accesare cu crawlere. Cu cât o pagină are mai multă autoritate, cu atât are mai mult buget de accesare cu crawlere. Pur și simplu, pentru a vă crește bugetul de accesare cu crawlere, construiți Autoritatea paginii dvs.
3. Ce poate limita bugetul meu de accesare cu crawlere?
limita de accesare cu crawlere, cunoscută și sub numele de încărcare a gazdei de accesare cu crawlere, se bazează pe mulți factori, cum ar fi starea site-ului web și abilitățile de găzduire. Crawlerele motoarelor de căutare sunt setate pentru a preveni supraîncărcarea unui server web. Dacă site-ul dvs. web returnează erori de server sau dacă adresele URL solicitate expiră des, bugetul de accesare cu crawlere va fi mai limitat. În mod similar, dacă site-ul dvs. web rulează pe o platformă de Găzduire Partajată, limita de accesare cu crawlere va fi mai mare, deoarece trebuie să partajați bugetul de accesare cu crawlere cu alte site-uri web care rulează pe găzduire.
4. Ar trebui să folosesc URL-ul canonic și roboții meta?
Da, și este important să înțelegem diferențele dintre problemele de indexare și problemele de accesare cu crawlere.
etichetele canonice URL și meta robots trimit un semnal clar motoarelor de căutare ce pagină ar trebui să arate în indexul lor, dar nu le împiedică să acceseze cu crawlere celelalte pagini.
puteți folosi roboții.fișier txt și relația nofollow link pentru a face față problemelor de accesare cu crawlere.