
källa: Supercharge dina Datorvisionsmodeller med TensorFlow Object Detection API,
Jonathan Huang, forskare och Vivek Rathod, mjukvaruingenjör,
Google AI Blog
- objektdetektering som en uppgift i datorsyn
- YOLO som en realtidsobjektdetektor
- Vad är YOLO?
- YOLO jämfört med andra detektorer
- versioner av YOLO
- exempel på Yolo-applikationer
- YOLO som objektdetektor i TensorFlow & Keras
- TensorFlow & keras ramverk i maskininlärning
- Yolo-implementering i TensorFlow & Keras
- hur man kör pre-utbildad YOLO out-of-the-box och få resultat
- hur du tränar din anpassade YOLO object detection model
- Task statement
- Dataset & anteckningar
- var du kan hämta data från
- så här kommenterar du data för YOLO
- hur man omvandlar data från andra format till YOLO
- dela data i delmängder
- skapa datageneratorer
- Installation & inställning krävs för modellutbildning
- Modell utbildning
- förutsättningar
- initiering av modellobjekt
- definiera callbacks
- montera modellen
- utbildad anpassad modell i inferensläge
- slutsatser
- Anton Morgunov
- TensorFlow Object Detection API: Best Practices to Training, Evaluation & Deployment
objektdetektering som en uppgift i datorsyn
vi stöter på objekt varje dag i vårt liv. Titta runt, och du hittar flera objekt som omger dig. Som människa kan du enkelt upptäcka och identifiera varje objekt som du ser. Det är naturligt och tar inte mycket ansträngning.
för datorer är dock detektering av objekt en uppgift som behöver en komplex lösning. För en dator att” upptäcka objekt ” betyder att bearbeta en inmatningsbild (eller en enda bild från en video) och svara med information om objekt på bilden och deras position. I datorsyntermer kallar vi dessa två uppgifter klassificering och lokalisering. Vi vill att datorn ska säga vilken typ av objekt som presenteras på en viss bild och var exakt de finns.
flera lösningar har utvecklats för att hjälpa datorer att upptäcka objekt. Idag ska vi utforska en toppmodern algoritm som heter YOLO, som uppnår hög noggrannhet i realtid. I synnerhet lär vi oss att träna denna algoritm på en anpassad dataset i TensorFlow / Keras.
Låt oss först se vad exakt YOLO är och vad det är känt för.
YOLO som en realtidsobjektdetektor
Vad är YOLO?
YOLO är en akronym för” You only Look Once ” (förväxla inte det med You Only Live Once från The Simpsons). Som namnet antyder räcker en enda” look ” för att hitta alla objekt på en bild och identifiera dem.
i maskininlärningstermer kan vi säga att alla objekt detekteras via en enda algoritmkörning. Det görs genom att dela en bild i ett rutnät och förutsäga avgränsningsrutor och klass sannolikheter för varje cell i ett rutnät. Om vi skulle vilja anställa YOLO för bildetektering, här är vad nätet och de förutsagda avgränsningslådorna kan se ut:

Begränsningsbox som YOLO förutspår för den första bilen är i rött.
Begränsningsbox som YOLO förutspår för den andra bilen är gul.
källa till bilden.
ovanstående bild innehåller endast den slutliga uppsättningen lådor som erhållits efter filtrering. Det är värt att notera att Yolos raw-utgång innehåller många avgränsningslådor för samma objekt. Dessa lådor skiljer sig åt i form och storlek. Som du kan se i bilden nedan är vissa rutor bättre på att fånga målobjektet medan andra som erbjuds av en algoritm fungerar dåligt.

alla gula lådor är för den andra bilen.
de djärva röda och gula lådorna är bäst för bildetektering.
källa till bilden.
för att välja den bästa avgränsningsrutan för ett visst objekt tillämpas en icke-maximal undertryckningsalgoritm (NMS).

– lådorna som förutses för bilarna för att bara behålla de som bäst fångar objekt.
källa till bilden.
alla rutor som YOLO förutspår har en konfidensnivå associerad med dem. NMS använder dessa konfidensvärden för att ta bort rutorna som förutspåddes med låg säkerhet. Vanligtvis är det alla rutor som förutses med förtroende under 0,5.

du kan se förtroendepoängen i det övre vänstra hörnet av varje ruta, bredvid objektnamnet.
källa till bilden.
när alla osäkra avgränsningslådor tas bort är det bara lådorna med hög konfidensnivå kvar. För att välja den bästa bland de bästa kandidaterna väljer NMS rutan med högsta konfidensnivå och beräknar hur den skär med de andra rutorna runt. Om en korsning är högre än en viss tröskelnivå tas avgränsningsrutan med lägre förtroende bort. Om NMS jämför två rutor som har en korsning under en vald tröskel, hålls båda rutorna i Slutliga förutsägelser.
YOLO jämfört med andra detektorer
även om ett convolutional neural net (CNN) används under huven på YOLO, kan det fortfarande upptäcka objekt med realtidsprestanda. Det är möjligt tack vare Yolos förmåga att göra förutsägelserna samtidigt i ett enstegs tillvägagångssätt.
andra, långsammare algoritmer för objektdetektering (som snabbare r-CNN) använder vanligtvis en tvåstegsmetod:
- i det första steget väljs intressanta bildregioner. Dessa är de delar av en bild som kan innehålla några objekt;
- i det andra steget klassificeras var och en av dessa regioner med hjälp av ett konvolutionellt neuralt nät.
vanligtvis finns det många regioner på en bild med objekten. Alla dessa regioner skickas till klassificering. Klassificering är en tidskrävande operation, varför tvåstegsobjektdetekteringsmetoden fungerar långsammare jämfört med enstegsdetektering.
YOLO väljer inte de intressanta delarna av en bild, det finns inget behov av det. Istället förutspår det avgränsningsrutor och klasser för hela bilden i ett enda framåtriktat nätpass.
nedan kan du se hur snabbt YOLO jämförs med andra populära detektorer.

SSD och YOLO är enstegsobjektdetektorer medan Faster-RCNN
och R-FCN är tvåstegsobjektdetektorer.
källa till bilden.
versioner av YOLO
YOLO introducerades först 2015 av Joseph Redmon i sitt forskningspapper med titeln ”Du ser bara en gång: enhetlig, Realtidsobjektdetektering”.
sedan dess har YOLO utvecklats mycket. 2016 beskrev Joseph Redmon den andra YOLO-versionen i ”YOLO9000: bättre, snabbare, starkare”.
ungefär två år efter den andra Yolo-uppdateringen kom Joseph med en annan nettouppgradering. Hans papper, kallad ”YOLOv3: An Incremental Improvement”, fångade uppmärksamheten hos många datoringenjörer och blev populär i maskininlärningsgemenskapen.
år 2020 beslutade Joseph Redmon att sluta undersöka datorsyn, men det hindrade inte YOLO från att utvecklas av andra. Samma år designade ett team av tre ingenjörer (Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao) den fjärde versionen av YOLO, ännu snabbare och mer exakt än tidigare. Deras resultat beskrivs i ” YOLOv4: Optimal hastighet och noggrannhet för objektdetektering” papper de publicerade den 23 April 2020.
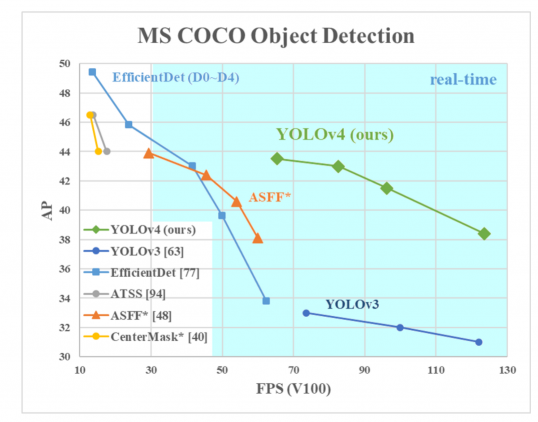
AP på Y-axeln är ett mått som kallas”Genomsnittlig precision”. Det beskriver nätets noggrannhet.
FPS (ramar per sekund) på X-axeln är ett mått som beskriver hastighet.
källa till bilden.
två månader efter lanseringen av den 4: e versionen tillkännagav en oberoende utvecklare, Glenn Jocher, den 5: e versionen av YOLO. Den här gången publicerades inget forskningspapper. Nätet blev tillgängligt på Jochers GitHub-sida som en PyTorch-implementering. Den femte versionen hade ungefär samma noggrannhet som den fjärde versionen men det var snabbare.
slutligen, i juli 2020 fick vi en annan stor Yolo-uppdatering. I ett papper med titeln ”PP-YOLO: en effektiv och effektiv implementering av Objektdetektor” kom Xiang Long och team med en ny version av YOLO. Denna iteration av YOLO baserades på 3: e modellversionen och överträffade Yolo v4: s prestanda.

kartan på Y-axeln är ett mått som kallas ”Genomsnittlig Genomsnittlig precision”. Det beskriver nätets noggrannhet.
FPS (ramar per sekund) på X-axeln är ett mått som beskriver hastighet.
källa till bilden.
i denna handledning kommer vi att titta närmare på YOLOv4 och dess implementering. Varför YOLOv4? Tre skäl:
- den har brett godkännande i maskininlärningsgemenskapen;
- denna version har visat sin höga prestanda i ett brett spektrum av detekteringsuppgifter;
- YOLOv4 har implementerats i flera populära ramar, inklusive TensorFlow och Keras, som vi ska arbeta med.
exempel på Yolo-applikationer
innan vi går vidare till den praktiska delen av den här artikeln, implementerar vår anpassade Yolo-baserade objektdetektor, skulle jag vilja visa dig ett par coola yolov4-implementeringar, och då ska vi göra vår implementering.
Var uppmärksam på hur snabbt och korrekt förutsägelserna är!
här är det första imponerande exemplet på vad YOLOv4 kan göra, upptäcka flera objekt från olika spel-och filmscener.
Alternativt kan du kontrollera denna objektdetekteringsdemo från en verklig kameravy.
YOLO som objektdetektor i TensorFlow & Keras
TensorFlow & keras ramverk i maskininlärning

källa till bilden.
ramar är väsentliga i varje informationsteknologi domän. Maskininlärning är inget undantag. Det finns flera etablerade aktörer på ML-marknaden som hjälper oss att förenkla den övergripande programmeringsupplevelsen. PyTorch, scikit-learn, TensorFlow, Keras, MXNet och Caffe är bara några värda att nämna.
idag kommer vi att arbeta nära TensorFlow / Keras. Inte överraskande är dessa två bland de mest populära ramarna i maskininlärningsuniverset. Det beror till stor del på att både TensorFlow och Keras ger rika utvecklingsmöjligheter. Dessa två ramar är ganska lika varandra. Utan att gräva för mycket i detaljer är det viktigaste att komma ihåg att Keras bara är ett omslag för TensorFlow-ramverket.
Yolo-implementering i TensorFlow & Keras
vid skrivandet av denna artikel fanns det 808 repositories med YOLO-implementeringar på en TensorFlow / Keras-backend. YOLO version 4 är vad vi ska implementera. Begränsa sökningen till endast YOLO v4, jag fick 55 repositories.
när jag bläddrade igenom dem alla hittade jag en intressant kandidat att fortsätta med.
källa till bilden.
denna implementering utvecklades av taipingeric och jimmyaspire. Det är ganska enkelt och mycket intuitivt om du har arbetat med TensorFlow och Keras tidigare.
för att börja arbeta med denna implementering, bara klona repo till din lokala maskin. Därefter visar jag dig hur du använder YOLO ur lådan och hur du tränar din egen anpassade objektdetektor.
hur man kör pre-utbildad YOLO out-of-the-box och få resultat
om man tittar på” Quick Start ” delen av repo, kan du se att för att få en modell igång, Vi måste bara importera YOLO som en klass objekt och ladda i modellen vikter:
from models import Yolov4model = Yolov4(weight_path='yolov4.weights', class_name_path='class_names/coco_classes.txt')
Observera att du måste ladda ner modellvikter manuellt i förväg. Modellen vikter fil som kommer med YOLO kommer från COCO dataset och det finns på AlexeyAB officiella darknet projektsida på GitHub. Du kan ladda ner vikterna direkt via den här länken.
direkt efter är modellen helt redo att arbeta med bilder i inferensläge. Använd bara predict () – metoden för en bild du väljer. Metoden är standard för TensorFlow och Keras ramverk.
pred = model.predict('input.jpg')
till exempel för denna inmatningsbild:

jag fick följande modellutgång:

förutsägelser som modellen görs returneras i en lämplig form av en pandas DataFrame. Vi får klassnamn, boxstorlek och Koordinater för varje upptäckt objekt:

massor av användbar information om de upptäckta objekten
det finns flera parametrar inom predict () – metoden som låter oss ange om vi vill plotta bilden med de förutsagda avgränsningsrutorna, textnamnen för varje objekt etc. Kolla in docstring som följer med predict () – metoden för att bli bekant med vad som är tillgängligt för oss:

du bör förvänta dig att din modell bara kommer att kunna upptäcka objekttyper som är strikt begränsade till COCO-datasetet. För att veta vilka objekttyper en förutbildad YOLO-modell kan upptäcka, kolla in coco_classes.txt-fil finns i … / yolo-v4-TF.kers / class_names/. Det finns 80 objekttyper där inne.
hur du tränar din anpassade YOLO object detection model
Task statement

för att utforma en objektdetekteringsmodell måste du veta vilka objekttyper du vill upptäcka. Detta bör vara ett begränsat antal objekttyper som du vill skapa din detektor för. Det är bra att ha en lista över objekttyper förberedda när vi flyttar till den faktiska modellutvecklingen.
helst bör du också ha en kommenterad dataset som har objekt av intresse. Denna dataset kommer att användas för att träna en detektor och validera den. Om du ännu inte har någon dataset eller anteckning för det, oroa dig inte, jag ska visa dig var och hur du kan få det.
Dataset & anteckningar
var du kan hämta data från
om du har en kommenterad dataset att arbeta med, hoppa bara över den här delen och gå vidare till nästa kapitel. Men om du behöver en dataset för ditt projekt kommer vi nu att utforska online-resurser där du kan få data.
det spelar ingen roll vilket fält du arbetar i, det finns en stor chans att det redan finns ett open source-dataset som du kan använda för ditt projekt.
den första resursen jag rekommenderar är artikeln” 50 + Object Detection dataset from different industry domains ” av Abhishek Annamraju som har samlat underbara kommenterade dataset för branscher som mode, detaljhandel, sport, medicin och många fler.

källa till bilden.
andra två bra ställen att leta efter data är paperswithcode.com och roboflow.com som ger tillgång till högkvalitativa datamängder för objektdetektering.
kolla in ovanstående resurser för att samla in de data du behöver eller för att berika datauppsättningen som du redan har.
så här kommenterar du data för YOLO
om din dataset av bilder kommer utan anteckningar måste du själv göra antecknings jobbet. Denna manuella operation är ganska tidskrävande, så se till att du har tillräckligt med tid att göra det.
som ett annoteringsverktyg kan du överväga flera alternativ. Personligen rekommenderar jag att du använder LabelImg. Det är ett lätt och lättanvänt bildnoteringsverktyg som direkt kan mata ut anteckningar för YOLO-modeller.
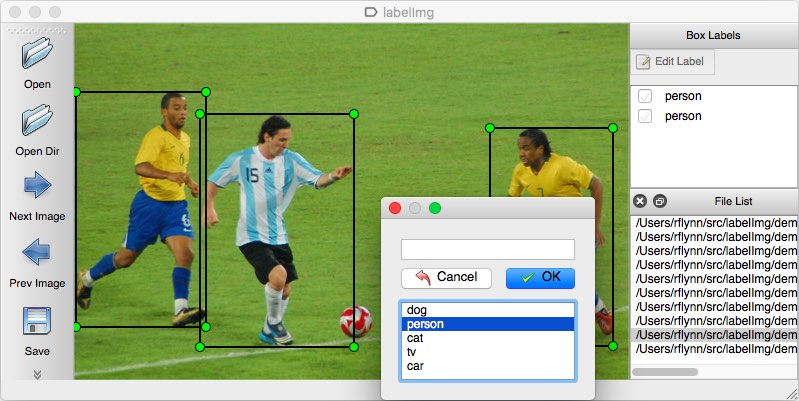
källa till bilden.
hur man omvandlar data från andra format till YOLO
anteckningar för YOLO är i form av txt-filer. Varje rad i en txt-fil fol YOLO måste ha följande format:
image1.jpg 10,15,345,284,0image2.jpg 100,94,613,814,0 31,420,220,540,1
vi kan bryta upp varje rad från txt-filen och se vad den består av:
- den första delen av en rad anger basnamnen för bilderna: image1.jpg, bild2.jpg
- den andra delen av en rad definierar avgränsningsboxkoordinaterna och klassetiketten. Till exempel, 10,15,345,284,0 stater för xmin, ymin, xmax, ymax, class_id
- om en viss bild har mer än ett objekt på det kommer det att finnas flera rutor och klassetiketter bredvid bildbasnamnet, dividerat med ett mellanslag.
avgränsningsboxkoordinater är ett tydligt koncept, men hur är det med class_id-numret som anger klassetiketten? Varje class_id är länkad till en viss klass i en annan txt-fil. Till exempel kommer förutbildad YOLO med coco_classes.txt-fil som ser ut så här:
personbicyclecarmotorbikeaeroplanebus...
antal rader i klasserna filerna måste matcha antalet klasser som din detektor kommer att upptäcka. Numerering börjar från noll, vilket innebär att class_id-numret för den första klassen i klassfilen kommer att bli 0. Klass som placeras på den andra raden i klasserna txt-fil kommer att ha nummer 1.
nu vet du hur annoteringen för YOLO ser ut. För att fortsätta skapa en anpassad objektdetektor uppmanar jag dig att göra två saker nu:
- skapa en klasser txt-fil där du kommer palace av de klasser som du vill att din detektor för att upptäcka. Kom ihåg att klassordningen är viktig.
- skapa en txt-fil med anteckningar. Om du redan har anteckning men i VOC-formatet (.XMLs), kan du använda den här filen för att omvandla från XML till YOLO.
dela data i delmängder
som alltid vill vi dela datauppsättningen i 2 delmängder: för utbildning och för validering. Det kan göras så enkelt som:
from utils import read_annotation_lines train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1)
skapa datageneratorer
när data delas kan vi gå vidare till datageneratorns initialisering. Vi har en datagenerator för varje datafil. I vårt fall har vi en generator för utbildningsundergruppen och för valideringsundergruppen.
så här skapas datageneratorerna:
from utils import DataGenerator FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
för att sammanfatta allt, så här ser den fullständiga koden för datadelning och generatorskapande ut:
from utils import read_annotation_lines, DataGenerator train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1) FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
Installation & inställning krävs för modellutbildning
Låt oss prata om förutsättningarna som är nödvändiga för att skapa din egen objektdetektor:
- du bör ha Python redan installerat på din dator. Om du behöver installera det rekommenderar jag att du följer den här officiella guiden av Anaconda;
- om din dator har en CUDA-aktiverad GPU (en GPU Tillverkad av NVIDIA) behövs några relevanta bibliotek för att stödja GPU-baserad utbildning. Om du behöver aktivera GPU-stöd, kolla riktlinjerna på NVIDIAs webbplats. Ditt mål är att installera den senaste versionen av både CUDA Toolkit och cuDNN för ditt operativsystem;
- du kanske vill organisera en oberoende virtuell miljö att arbeta i. Detta projekt kräver TensorFlow 2 installerat. Alla andra bibliotek kommer att introduceras senare;
- när det gäller mig byggde jag och tränade min YOLOv4-modell i en Jupyter Notebook-utvecklingsmiljö. Även om Jupyter Notebook verkar vara ett rimligt alternativ att gå med, överväga utveckling i en IDE efter eget val om du vill.
Modell utbildning

förutsättningar
nu borde du ha:
- en split för din dataset;
- två datageneratorer initierade;
- en txt-fil med klasserna.
initiering av modellobjekt
för att göra dig redo för ett träningsjobb, initiera yolov4-modellobjektet. Se till att du använder ingen som ett värde för parametern weight_path. Du bör också ange en sökväg till din klasser txt-fil i det här steget. Här är initialiseringskoden som jag använde i mitt projekt:
class_name_path = 'path2project_folder/model_data/scans_file.txt' model = Yolov4(weight_path=None, class_name_path=class_name_path)
ovanstående modellinitiering leder till skapandet av ett modellobjekt med en standarduppsättning parametrar. Överväg att ändra konfigurationen för din modell genom att skicka in en ordlista som ett värde till parametern config model.

Config anger en uppsättning parametrar för yolov4-modellen.
standardmodellkonfiguration är en bra utgångspunkt men du kanske vill experimentera med andra konfigurationer för bättre modellkvalitet.
i synnerhet rekommenderar jag starkt att experimentera med ankare och img_size. Ankare anger geometrin för ankarna som ska användas för att fånga objekt. Ju bättre ankarnas former passar objektets former, desto högre blir modellens prestanda.
att öka img_size kan också vara användbart i vissa fall. Tänk på att ju högre bilden är desto längre kommer modellen att göra slutsatsen.
om du vill använda Neptune som ett spårningsverktyg, bör du också initiera en experimentkörning, så här:
import neptune.new as neptune run = neptune.init(project='projects/my_project', api_token=my_token)
definiera callbacks
TensorFlow & Keras låt oss använda callbacks för att övervaka träningsförloppet, göra kontrollpunkter och hantera träningsparametrar (t.ex. inlärningsfrekvens).
innan du monterar din modell, definiera återuppringningar som kommer att vara användbara för dina ändamål. Se till att ange sökvägar för att lagra modellkontrollpunkter och tillhörande loggar. Så här gjorde jag det i ett av mina projekt:
# defining pathes and callbacks dir4saving = 'path2checkpoint/checkpoints'os.makedirs(dir4saving, exist_ok = True) logdir = 'path4logdir/logs'os.makedirs(logdir, exist_ok = True) name4saving = 'epoch_{epoch:02d}-val_loss-{val_loss:.4f}.hdf5' filepath = os.path.join(dir4saving, name4saving) rLrCallBack = keras.callbacks.ReduceLROnPlateau(monitor = 'val_loss', factor = 0.1, patience = 5, verbose = 1) tbCallBack = keras.callbacks.TensorBoard(log_dir = logdir, histogram_freq = 0, write_graph = False, write_images = False) mcCallBack_loss = keras.callbacks.ModelCheckpoint(filepath, monitor = 'val_loss', verbose = 1, save_best_only = True, save_weights_only = False, mode = 'auto', period = 1)esCallBack = keras.callbacks.EarlyStopping(monitor = 'val_loss', mode = 'min', verbose = 1, patience = 10)
du kunde ha märkt att i ovanstående callbacks set TensorBoard används som ett spårningsverktyg. Överväg att använda Neptun som ett mycket mer avancerat verktyg för experimentspårning. Om så är fallet, glöm inte att initiera en annan återuppringning för att möjliggöra integration med Neptune:
from neptune.new.integrations.tensorflow_keras import NeptuneCallback neptune_cbk = NeptuneCallback(run=run, base_namespace='metrics')
montera modellen
för att starta träningsjobbet, montera helt enkelt modellobjektet med standard fit () – metoden i TensorFlow / Keras. Så här började jag träna min modell:
model.fit(data_gen_train, initial_epoch=0, epochs=10000, val_data_gen=data_gen_val, callbacks= )
när träningen startas ser du en standard förloppsindikator.

utbildningen kommer att utvärdera modellen i slutet av varje epok. Om du använder en uppsättning återuppringningar som liknar vad jag initialiserade och passerade under montering, sparas de kontrollpunkter som visar modellförbättring när det gäller lägre förlust i en viss katalog.
om inga fel uppstår och träningsprocessen går smidigt, kommer träningsjobbet att stoppas antingen på grund av slutet av träningsperiodens nummer, eller om den tidiga stoppningen återuppringning upptäcker ingen ytterligare modellförbättring och stoppar den övergripande processen.
i alla fall bör du sluta med flera modellkontrollpunkter. Vi vill välja den bästa från alla tillgängliga och använda den för slutsats.
utbildad anpassad modell i inferensläge
att köra en utbildad modell i inferensläget liknar att köra en förutbildad modell ur lådan.

du initierar ett modellobjekt som passerar i sökvägen till den bästa kontrollpunkten samt sökvägen till txt-filen med klasserna. Så här ser modellinitiering ut för mitt projekt:
from models import Yolov4model = Yolov4(weight_path='path2checkpoint/checkpoints/epoch_48-val_loss-0.061.hdf5', class_name_path='path2classes_file/my_yolo_classes.txt')
när modellen initieras, använd bara predict () – metoden för en bild du väljer för att få förutsägelserna. Som en sammanfattning returneras upptäckter som modellen gjorde i en bekväm form av en pandas DataFrame. Vi får klassnamn, boxstorlek och Koordinater för varje detekterat objekt.
slutsatser
du har just lärt dig hur du skapar en anpassad yolov4-objektdetektor. Vi har gått över end-to-end-processen, från datainsamling, annotering och transformation. Du har tillräckligt med kunskap om den fjärde YOLO-versionen och hur den skiljer sig från andra detektorer.
ingenting hindrar dig nu från att träna din egen modell i TensorFlow och Keras. Du vet var du ska få en förutbildad modell från och hur du startar träningsjobbet.
i min kommande artikel kommer jag att visa dig några av de bästa metoderna och livshackarna som hjälper till att förbättra kvaliteten på den slutliga modellen. Stanna hos oss!



Anton Morgunov
datorseende ingenjör på Basis.Centrum
Maskininlärningsentusiast. Brinner för datorseende. Inget papper – fler träd! Arbeta mot eliminering av papperskopior genom att flytta till full digitalisering!
läs nästa
TensorFlow Object Detection API: Best Practices to Training, Evaluation & Deployment
13 mins read | författare Anton Morgunov | uppdaterad Maj 28th, 2021
den här artikeln är den andra delen av en serie där du lär dig ett slut-till-slut-arbetsflöde för TensorFlow Object Detection och dess API. I den första artikeln lärde du dig hur du skapar en anpassad objektdetektor från början, men det finns fortfarande många saker som behöver din uppmärksamhet för att bli riktigt skicklig.
vi utforskar ämnen som är lika viktiga som den modellskapande processen vi redan har gått igenom. Här är några av de frågor vi ska svara på:
- hur utvärderar jag min modell och får en uppskattning av dess prestanda?
- vilka är de verktyg som jag kan använda för att spåra modellprestanda och jämföra resultat över flera experiment?
- hur kan jag exportera min modell för att använda den i inferensläget?
- finns det ett sätt att öka modellens prestanda ännu mer?
Fortsätt läsa ->