
Fonte: Turbinar o seu Computador Visão modelos com o TensorFlow de Detecção de objetos da API,
Jonathan Huang, Cientista de Pesquisa e Vivek Rathod, Engenheiro de Software,
Google AI do Blog
- a Detecção de objetos, como uma tarefa, na Visão de Computador
- YOLO como um detector de objetos em tempo real
- o que é YOLO?
- YOLO comparado a outros detectores
- Yolo foi introduzido pela primeira vez em 2015 por Joseph Redmon em seu artigo de pesquisa intitulado “You Only Look Once: Unified, real-Time Object Detection”.
- exemplos de aplicativos YOLO
- YOLO como um objeto detector em TensorFlow & Keras
- TensorFlow & Keras quadros em Aprendizado de Máquina
- implementação YOLO no TensorFlow & Keras
- Como executar o pré-formados YOLO out-of-the-box e obter resultados
- como treinar seu modelo de detecção de objetos Yolo personalizado
- declaração de Tarefas
- conjunto de dados & anotações
- onde obter dados de
- como anotar dados para YOLO
- Como transformar dados em outros formatos a YOLO
- dividindo dados em subconjuntos
- criando geradores de dados
- instalação& configuração necessária para o treinamento do modelo
- Modelo de formação
- pré-Requisitos
- inicialização do objeto modelo
- definindo callbacks
- ajustando o modelo
- modelo personalizado treinado no modo de inferência
- conclusões
- Anton Morgunov
- TensorFlow de Detecção de objetos da API: Melhores Práticas para a Formação, Avaliação & Implantação
a Detecção de objetos, como uma tarefa, na Visão de Computador
encontramos objetos de cada dia em nossa vida. Olhe ao redor e você encontrará vários objetos ao seu redor. Como ser humano, você pode facilmente detectar e identificar cada objeto que vê. É natural e não requer muito esforço.
para computadores, no entanto, detectar objetos é uma tarefa que precisa de uma solução complexa. Para um computador “detectar objetos” significa processar uma imagem de entrada (ou um único quadro de um vídeo) e responder com informações sobre objetos na imagem e sua posição. Em termos de visão computacional, chamamos essas duas tarefas de classificação e localização. Queremos que o computador diga que tipo de objetos são apresentados em uma determinada imagem e onde exatamente eles estão localizados.
várias soluções foram desenvolvidas para ajudar os computadores a detectar objetos. Hoje, vamos explorar um algoritmo de última geração chamado YOLO, que atinge alta precisão em velocidade em tempo real. Em particular, aprenderemos como treinar esse algoritmo em um conjunto de dados personalizado no TensorFlow / Keras.
Primeiro, vamos ver o que exatamente é YOLO e pelo que é famoso.
YOLO como um detector de objetos em tempo real
o que é YOLO?
YOLO é um acrônimo para ” você só olha uma vez “(não confunda com você só vive uma vez dos Simpsons). Como o nome sugere, um único “olhar” é suficiente para encontrar todos os objetos em uma imagem e identificá-los.
em termos de aprendizado de máquina, podemos dizer que todos os objetos são detectados por meio de uma única execução de algoritmo. É feito dividindo uma imagem em uma grade e prevendo caixas delimitadoras e probabilidades de classe para cada célula em uma grade. Caso queiramos empregar o YOLO para detecção de carros, veja como a grade e as caixas delimitadoras previstas podem ser:

caixa delimitadora que Yolo prevê para o primeiro carro está em vermelho.
caixa delimitadora que Yolo prevê para o segundo carro é amarelo.
fonte da imagem.
a imagem acima contém apenas o conjunto final de caixas obtidas após a filtragem. Vale a pena notar que a saída bruta de YOLO contém muitas caixas delimitadoras para o mesmo objeto. Essas caixas diferem em forma e tamanho. Como você pode ver na imagem abaixo, algumas caixas são melhores para capturar o objeto de destino, enquanto outras oferecidas por um algoritmo têm um desempenho ruim.

todas as caixas amarelas são para o segundo carro.
as caixas vermelhas e amarelas em negrito são as melhores para detecção de carros.
fonte da imagem.
para selecionar a melhor caixa delimitadora para um determinado objeto, um algoritmo de supressão não máxima (NMS) é aplicado.

previstas para os carros manterem apenas aquelas que melhor capturam objetos.
fonte da imagem.
todas as caixas que Yolo prevê têm um nível de confiança associado a elas. O NMS usa esses valores de confiança para remover as caixas que foram previstas com baixa certeza. Normalmente, estas são todas as caixas que são previstas com confiança abaixo de 0,5.

você pode ver as pontuações de confiança no canto superior esquerdo de cada caixa, ao lado do nome do objeto.
fonte da imagem.
quando todas as caixas delimitadoras incertas são removidas, apenas as caixas com alto nível de confiança são deixadas. Para selecionar o melhor entre os candidatos com melhor desempenho, o NMS seleciona a caixa com o nível de confiança mais alto e calcula como ela se cruza com as outras caixas ao redor. Se uma interseção for maior que um determinado nível de limite, a caixa delimitadora com menor confiança será removida. Caso o NMS Compare duas caixas que têm uma interseção abaixo de um limite selecionado, ambas as caixas são mantidas nas previsões finais.
YOLO comparado a outros detectores
embora uma rede neural convolucional (CNN) seja usada sob o capô do YOLO, ainda é capaz de detectar objetos com desempenho em tempo real. É possível graças à capacidade de YOLO de fazer as previsões simultaneamente em uma abordagem de estágio único.
outros algoritmos mais lentos para detecção de objetos (como R-CNN mais rápido) normalmente usam uma abordagem de dois estágios:
- na primeira etapa, regiões de imagem interessantes são selecionadas. Estas são as partes de uma imagem que podem conter quaisquer objetos;
- no segundo estágio, cada uma dessas regiões é classificada usando uma rede neural convolucional.
Normalmente, existem muitas regiões em uma imagem com os objetos. Todas essas regiões são enviadas para classificação. A classificação é uma operação demorada, razão pela qual a abordagem de detecção de objetos de dois estágios tem um desempenho mais lento em comparação com a detecção de um estágio.
YOLO não seleciona as partes interessantes de uma imagem, não há necessidade disso. Em vez disso, ele prevê caixas delimitadoras e classes para toda a imagem em um único passe de rede para frente.
abaixo você pode ver o quão rápido YOLO é comparado a outros detectores populares.

SSD e YOLO são Detectores de objetos de um estágio, enquanto mais rápido-RCNN
e R-FCN são Detectores de objetos de dois estágios.
fonte da imagem.
Yolo foi introduzido pela primeira vez em 2015 por Joseph Redmon em seu artigo de pesquisa intitulado “You Only Look Once: Unified, real-Time Object Detection”.
desde então, YOLO evoluiu muito. Em 2016, Joseph Redmon descreveu a segunda versão do YOLO em “YOLO9000: Better, Faster, Stronger”.
cerca de dois anos após a segunda atualização do YOLO, Joseph apresentou outra atualização do net. Seu artigo, chamado “YOLOv3: uma melhoria Incremental”, chamou a atenção de muitos engenheiros de computação e se tornou popular na comunidade de aprendizado de máquina.
em 2020, Joseph Redmon decidiu parar de pesquisar a visão computacional, mas não impediu que YOLO fosse desenvolvido por outros. Nesse mesmo ano, uma equipe de três engenheiros (Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao) projetou a quarta versão do YOLO, ainda mais rápida e precisa do que antes. Suas descobertas são descritas no ” YOLOv4: Velocidade ideal e precisão da detecção de objetos”, eles publicaram em 23 de abril de 2020.
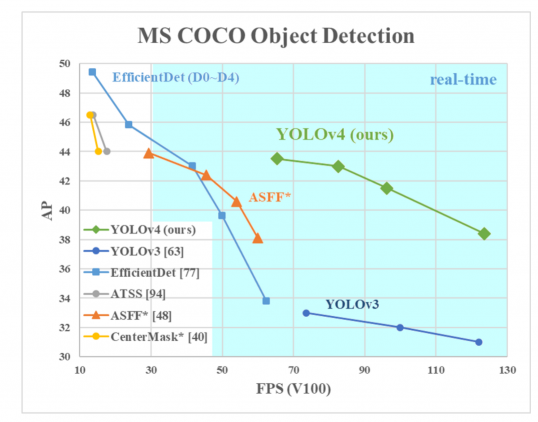
AP no eixo Y é uma métrica chamada “precisão média”. Ele descreve a precisão da rede.
FPS (quadros por segundo) no eixo X é uma métrica que descreve a velocidade.
fonte da imagem.
Dois meses após o lançamento da 4ª versão, um desenvolvedor independente, Glenn Jocher, anunciou a 5ª versão do YOLO. Desta vez, não foi publicado nenhum artigo de pesquisa. A rede ficou disponível na página GitHub da Jocher como uma implementação PyTorch. A quinta versão tinha praticamente a mesma precisão da quarta versão, mas era mais rápida.
por último, em julho de 2020, recebemos outra grande atualização do YOLO. Em um artigo intitulado “PP-YOLO: uma implementação eficaz e eficiente do detector de objetos”, Xiang Long e team criaram uma nova versão do YOLO. Essa iteração do YOLO foi baseada na 3ª versão do modelo e excedeu o desempenho do YOLO v4.

o mapa no eixo Y é uma métrica chamada “precisão média média média”. Ele descreve a precisão da rede.
FPS (quadros por segundo) no eixo X é uma métrica que descreve a velocidade.
fonte da imagem.
neste tutorial, vamos dar uma olhada mais de perto no YOLOv4 e sua implementação. Por Que YOLOv4? Três razões:
- tem ampla aprovação na comunidade de aprendizado de máquina;
- esta versão provou seu alto desempenho em uma ampla gama de tarefas de detecção;
- YOLOv4 foi implementado em várias estruturas populares, incluindo TensorFlow e Keras, com as quais vamos trabalhar.
exemplos de aplicativos YOLO
Antes de passarmos para a parte prática deste artigo, implementando nosso detector de objetos baseado em Yolo personalizado, gostaria de mostrar algumas implementações legais do YOLOv4 e, em seguida, faremos nossa implementação.
preste atenção em quão rápidas e precisas são as previsões!
aqui está o primeiro exemplo impressionante do que YOLOv4 pode fazer, detectando vários objetos de diferentes cenas de jogos e filmes.
Alternativamente, você pode verificar esta demonstração de detecção de objetos a partir de uma visão de câmera da vida real.
YOLO como um objeto detector em TensorFlow & Keras
TensorFlow & Keras quadros em Aprendizado de Máquina

fonte da imagem.
as estruturas são essenciais em todos os domínios da tecnologia da informação. O aprendizado de máquina não é exceção. Existem vários players estabelecidos no mercado de ML que nos ajudam a simplificar a experiência geral de programação. PyTorch, scikit-learn, TensorFlow, Keras, MXNet e Caffe são apenas alguns que valem a pena mencionar.
hoje, vamos trabalhar em estreita colaboração com TensorFlow/Keras. Não surpreendentemente, esses dois estão entre os frameworks mais populares no universo do aprendizado de máquina. É em grande parte devido ao fato de que tanto o TensorFlow quanto o Keras fornecem recursos avançados para o desenvolvimento. Essas duas estruturas são bastante semelhantes entre si. Sem cavar muito em detalhes, a principal coisa a lembrar é que Keras é apenas um wrapper para a estrutura TensorFlow.
implementação YOLO no TensorFlow & Keras
no momento da redação deste artigo, havia 808 repositórios com implementações YOLO em um backend TensorFlow / Keras. YOLO versão 4 é o que vamos implementar. Limitando a pesquisa a apenas YOLO v4, eu tenho 55 repositórios.
navegando cuidadosamente em todos eles, encontrei um candidato interessante para continuar.
fonte da imagem.
esta implementação foi desenvolvida por Taiping e jimmyaspire. É bastante simples e muito intuitivo se você já trabalhou com TensorFlow e Keras antes.
para começar a trabalhar com esta implementação, basta clonar o repo para sua máquina local. Em seguida, mostrarei como usar o YOLO fora da caixa e como treinar seu próprio detector de objetos personalizado.
Como executar o pré-formados YOLO out-of-the-box e obter resultados
Olhando para o “Início Rápido” do repositório, você pode ver que, para obter um modelo pronto e funcionando, só temos de importar YOLO como um objeto de classe e de carga no modelo de pesos:
from models import Yolov4model = Yolov4(weight_path='yolov4.weights', class_name_path='class_names/coco_classes.txt')
Note que você precisa para transferir manualmente o modelo de pesos antecipadamente. O arquivo de pesos do modelo que vem com o YOLO vem do conjunto de dados COCO e está disponível na página oficial do projeto darknet AlexeyAB no GitHub. Você pode baixar os pesos diretamente através deste link.Logo depois, o modelo está totalmente pronto para trabalhar com imagens no modo de inferência. Basta usar o método predict() para uma imagem de sua escolha. O método é padrão para estruturas TensorFlow e Keras.
pred = model.predict('input.jpg')
Por exemplo, para esta imagem de entrada:

eu tenho o seguinte modelo de saída:

as Previsões de que o modelo de são retornados em uma forma conveniente de um pandas DataFrame. Obtemos o nome da classe, o tamanho da caixa e as coordenadas para cada objeto detectado:

muitas informações úteis sobre os objetos detectados
existem vários parâmetros dentro do método predict () que nos permitem especificar se queremos plotar a imagem com as caixas delimitadoras previstas, nomes textuais para cada objeto, etc. Confira o docstring que acompanha o método predict () para se familiarizar com o que está disponível para nós:

você deve esperar que seu modelo só seja capaz de detectar tipos de objetos estritamente limitados ao conjunto de dados COCO. Para saber quais tipos de objeto um modelo YOLO pré-treinado é capaz de detectar, confira as coco_classes.arquivo txt disponível em … / yolo-v4-tf.kers/class_names/. Existem 80 tipos de objetos lá.
como treinar seu modelo de detecção de objetos Yolo personalizado
declaração de Tarefas

para projetar um modelo de detecção de objetos, você precisa saber quais tipos de objetos deseja detectar. Este deve ser um número limitado de tipos de objetos para os quais você deseja criar seu detector. É bom ter uma lista de tipos de objetos preparados à medida que avançamos para o desenvolvimento real do modelo.
idealmente, você também deve ter um conjunto de dados anotado que tenha objetos de seu interesse. Este conjunto de dados será usado para treinar um detector e validá-lo. Se você ainda não tiver um conjunto de dados ou anotação para ele, não se preocupe, mostrarei onde e como você pode obtê-lo.
conjunto de dados & anotações
onde obter dados de
se você tiver um conjunto de dados anotado para trabalhar, basta pular esta parte e passar para o próximo capítulo. Mas, se você precisar de um conjunto de dados para o seu projeto, agora vamos explorar recursos on-line onde você pode obter dados.
realmente não importa em que campo você está trabalhando, há uma grande chance de que já haja um conjunto de dados de código aberto que você pode usar para o seu projeto.
o primeiro recurso que recomendo é o artigo” mais de 50 conjuntos de Dados De Detecção de objetos de diferentes domínios da indústria” de Abhishek Annamraju, que coletou maravilhosos conjuntos de dados anotados para indústrias como moda, varejo, esportes, medicina e muito mais.

fonte da imagem.
Outros dois ótimos lugares para procurar os dados são paperswithcode.com e roboflow.com que fornecem acesso de alta qualidade conjuntos de dados para a detecção de objetos.
confira esses ativos acima para coletar os dados de que você precisa ou para enriquecer o conjunto de dados que você já possui.
como anotar dados para YOLO
se seu conjunto de dados de imagens vier sem anotações, você mesmo deve fazer o trabalho de anotação. Esta operação manual é bastante demorada, portanto, certifique-se de ter tempo suficiente para fazê-lo.
como uma ferramenta de anotação, você pode considerar várias opções. Pessoalmente, eu recomendaria usar LabelImg. É uma ferramenta de anotação de imagem leve e fácil de usar que pode produzir anotações diretamente para modelos YOLO.
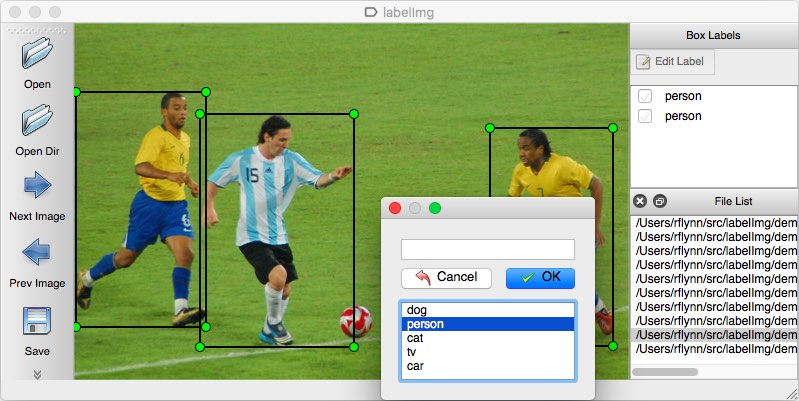
fonte da imagem.
Como transformar dados em outros formatos a YOLO
Anotações para YOLO estão na forma de arquivos txt. Cada linha em um arquivo txt fol YOLO deve ter o seguinte formato:
image1.jpg 10,15,345,284,0image2.jpg 100,94,613,814,0 31,420,220,540,1
podemos dividir cada linha do arquivo txt e veja o que é composto de:
- A primeira parte de uma linha especifica o basenames para as imagens: image1.jpg, image2.jpg
- a segunda parte de uma linha define as coordenadas da caixa delimitadora e o rótulo da classe. Por exemplo, 10,15,345,284,0 estados para xmin,ymin,xmax,ymax,class_id
- Se uma imagem tiver mais de um objeto, não haverá várias caixas de classe e etiquetas ao lado da imagem basename, dividido por um espaço.
as coordenadas da caixa delimitadora são um conceito claro, mas e o número class_id que especifica o rótulo da classe? Cada class_id está vinculado a uma classe específica em outro arquivo txt. Por exemplo, YOLO pré-treinado vem com o coco_classes.arquivo txt que se parece com isso:
personbicyclecarmotorbikeaeroplanebus...
o número de linhas nos arquivos de classes deve corresponder ao número de classes que seu detector irá detectar. A numeração começa a partir de zero, o que significa que o número class_id para a primeira classe no arquivo classes será 0. A classe que é colocada na segunda linha no arquivo classes txt terá o número 1.
Agora você sabe como é a anotação do YOLO. Para continuar criando um detector de objetos personalizado, peço que você faça duas coisas agora:
- crie um arquivo classes txt onde você vai Palácio das classes que você deseja que seu detector para detectar. Lembre-se de que a ordem de classe é importante.
- crie um arquivo txt com anotações. Caso você já tenha anotação, mas no formato VOC (.XMLs), você pode usar este arquivo para transformar de XML para YOLO.
dividindo dados em subconjuntos
como sempre, queremos dividir o conjunto de dados em 2 subconjuntos: para treinamento e validação. Isso pode ser feito tão simples quanto:
from utils import read_annotation_lines train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1)
criando geradores de dados
quando os dados são divididos, podemos prosseguir para a inicialização do gerador de dados. Teremos um gerador de dados para cada arquivo de dados. No nosso caso, teremos um gerador para o subconjunto de treinamento e para o subconjunto de validação.
veja como os geradores de dados são criados:
from utils import DataGenerator FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
para resumir tudo, aqui está como é o código completo para divisão de dados e criação de gerador:
from utils import read_annotation_lines, DataGenerator train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1) FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
instalação& configuração necessária para o treinamento do modelo
vamos falar sobre os pré-requisitos essenciais para criar seu próprio detector de objetos:
- você deve ter o Python já instalado no seu computador. Caso você precise instalá-lo, recomendo seguir este guia oficial da Anaconda;
- se o seu computador tiver uma GPU habilitada para CUDA (uma GPU feita pela NVIDIA), algumas bibliotecas relevantes serão necessárias para oferecer suporte ao treinamento baseado em GPU. Caso você precise habilitar o suporte à GPU, verifique as Diretrizes no site da NVIDIA. Seu objetivo é instalar a versão mais recente do CUDA Toolkit, e cuDNN para o seu sistema operativo;
- Você pode querer organizar um independentes ambiente virtual para trabalhar. Este projeto requer TensorFlow 2 instalado. Todas as outras bibliotecas serão introduzidas mais tarde;
- quanto a mim, eu estava construindo e treinando meu modelo YOLOv4 em um ambiente de desenvolvimento de Notebook Jupyter. Embora o Jupyter Notebook pareça uma opção razoável, considere o desenvolvimento em um IDE de sua escolha, se desejar.
Modelo de formação

pré-Requisitos
agora você deve ter:
- Uma divisão para o conjunto de dados;
- dados de Dois geradores inicializado;
- Um arquivo txt com as classes.
inicialização do objeto modelo
para se preparar para um trabalho de treinamento, inicialize o objeto modelo YOLOv4. Certifique-se de usar nenhum como um valor para o parâmetro weight_path. Você também deve fornecer um caminho para o arquivo classes txt nesta etapa. Aqui está o código de inicialização que usei no meu projeto:
class_name_path = 'path2project_folder/model_data/scans_file.txt' model = Yolov4(weight_path=None, class_name_path=class_name_path)
a inicialização do modelo acima leva à criação de um objeto modelo com um conjunto padrão de parâmetros. Considere alterar a configuração do seu modelo passando um dicionário como um valor para o parâmetro config model.

Config especifica um conjunto de parâmetros para o modelo YOLOv4.
a configuração do modelo padrão é um bom ponto de partida, mas você pode querer experimentar outras configurações para melhor qualidade do modelo.
em particular, recomendo experimentar âncoras e img_size. As âncoras especificam a geometria das âncoras que serão usadas para capturar objetos. Quanto melhor as formas das âncoras se ajustarem às formas dos objetos, maior será o desempenho do modelo.
aumentar o img_size também pode ser útil em alguns casos. Lembre-se de que quanto maior a imagem, mais tempo o modelo fará a inferência.
caso você queira usar o Neptune como uma ferramenta de rastreamento, você também deve inicializar uma execução de experimento, assim:
import neptune.new as neptune run = neptune.init(project='projects/my_project', api_token=my_token)
definindo callbacks
TensorFlow & Keras vamos usar callbacks para monitorar o progresso do treinamento, fazer checkpoints e gerenciar parâmetros de treinamento (por exemplo, taxa de aprendizado).
antes de ajustar seu modelo, defina retornos de chamada que serão úteis para seus propósitos. Certifique-se de especificar caminhos para armazenar pontos de verificação do modelo e logs associados. Veja como eu fiz isso em um dos meus projetos:
# defining pathes and callbacks dir4saving = 'path2checkpoint/checkpoints'os.makedirs(dir4saving, exist_ok = True) logdir = 'path4logdir/logs'os.makedirs(logdir, exist_ok = True) name4saving = 'epoch_{epoch:02d}-val_loss-{val_loss:.4f}.hdf5' filepath = os.path.join(dir4saving, name4saving) rLrCallBack = keras.callbacks.ReduceLROnPlateau(monitor = 'val_loss', factor = 0.1, patience = 5, verbose = 1) tbCallBack = keras.callbacks.TensorBoard(log_dir = logdir, histogram_freq = 0, write_graph = False, write_images = False) mcCallBack_loss = keras.callbacks.ModelCheckpoint(filepath, monitor = 'val_loss', verbose = 1, save_best_only = True, save_weights_only = False, mode = 'auto', period = 1)esCallBack = keras.callbacks.EarlyStopping(monitor = 'val_loss', mode = 'min', verbose = 1, patience = 10)
você poderia ter notado que nos retornos de chamada acima set TensorBoard é usado como uma ferramenta de rastreamento. Considere usar o Neptune como uma ferramenta muito mais avançada para rastreamento de experimentos. Nesse caso, não se esqueça de inicializar outro retorno de chamada para permitir a integração com o Neptune:
from neptune.new.integrations.tensorflow_keras import NeptuneCallback neptune_cbk = NeptuneCallback(run=run, base_namespace='metrics')
ajustando o modelo
para iniciar o trabalho de treinamento, basta ajustar o objeto modelo usando o método fit() padrão em TensorFlow / Keras. Veja como comecei a treinar meu modelo:
model.fit(data_gen_train, initial_epoch=0, epochs=10000, val_data_gen=data_gen_val, callbacks= )
quando o treinamento for iniciado, você verá uma barra de progresso padrão.

o processo de treinamento avaliará o modelo no final de cada época. Se você usar um conjunto de retornos de chamada semelhantes ao que inicializei e passei durante o encaixe, os pontos de verificação que mostram a melhoria do modelo em termos de menor perda serão salvos em um diretório especificado.
Se nenhum erro ocorrer e o processo de treinamento ocorrer sem problemas, o trabalho de treinamento será interrompido devido ao final do número das épocas de treinamento ou se o retorno de chamada de parada antecipada não detectar mais melhorias no modelo e interromper o processo geral.
em qualquer caso, você deve acabar com vários pontos de verificação do modelo. Queremos selecionar o melhor de todos os disponíveis e usá-lo para inferência.
modelo personalizado treinado no modo de inferência
executar um modelo treinado no modo de inferência é semelhante a executar um modelo pré-treinado fora da caixa.

você inicializa um objeto modelo passando no caminho para o melhor ponto de verificação, bem como o caminho para o arquivo txt com as classes. Veja como é a inicialização do modelo para o meu projeto:
from models import Yolov4model = Yolov4(weight_path='path2checkpoint/checkpoints/epoch_48-val_loss-0.061.hdf5', class_name_path='path2classes_file/my_yolo_classes.txt')
quando o modelo é inicializado, basta usar o método predict () para uma imagem de sua escolha para obter as previsões. Como recapitulação, as detecções feitas pelo modelo são retornadas em uma forma conveniente de um DataFrame pandas. Obtemos o nome da classe, o tamanho da caixa e as coordenadas para cada objeto detectado.
conclusões
você acabou de aprender como criar um detector de objetos yolov4 personalizado. Passamos pelo processo de ponta a ponta, a partir da coleta de dados, anotação e transformação. Você tem conhecimento suficiente sobre a quarta versão YOLO e como ela difere de outros detectores.
nada o impede agora de treinar seu próprio modelo no TensorFlow e no Keras. Você sabe de onde obter um modelo pré-treinado e como iniciar o trabalho de treinamento.
no meu próximo artigo, mostrarei algumas das melhores práticas e hacks de vida que ajudarão a melhorar a qualidade do modelo final. Fica connosco!



Anton Morgunov
Visão computacional Engenheiro de Base.Centro
entusiasta do aprendizado de máquina. Apaixonado por visão computacional. Sem papel – mais árvores! Trabalhando para a eliminação de cópias em papel, movendo-se para a digitalização completa!
LER PRÓXIMO
TensorFlow de Detecção de objetos da API: Melhores Práticas para a Formação, Avaliação & Implantação
13 minutos de leitura | Autor Anton Morgunov | Atualizado em 28 de Maio de 2021
Este artigo é a segunda parte da série onde você aprende uma ponta a ponta de fluxo de trabalho para TensorFlow de Detecção de objetos e de sua API. No primeiro artigo, você aprendeu a criar um detector de objetos personalizado do zero, mas ainda há muitas coisas que precisam de sua atenção para se tornarem verdadeiramente proficientes.
exploraremos tópicos tão importantes quanto o processo de criação do modelo pelo qual já passamos. Aqui estão algumas das perguntas que responderemos:
- como avaliar meu modelo e obter uma estimativa de seu desempenho?
- quais são as ferramentas que posso usar para rastrear o desempenho do modelo e comparar resultados em vários experimentos?
- Como posso exportar meu modelo para usá-lo no modo de inferência?
- existe uma maneira de aumentar ainda mais o desempenho do modelo?
Continue lendo ->