
Source: geef uw computer Vision models een boost met de TensorFlow Object Detection API,
Jonathan Huang, Research Scientist en Vivek Rathod, Software Engineer,
Google AI Blog
- objectdetectie als taak in Computer Vision
- YOLO als real-time objectdetector
- Wat is YOLO?
- YOLO vergeleken met andere detectoren
- versies van YOLO
- voorbeelden van YOLO applicaties
- YOLO als objectdetector in TensorFlow & Keras
- TensorFlow & Keras frameworks in Machine Learning
- Yolo-implementatie in TensorFlow & Keras
- pre-trained YOLO Out-of-the-box draaien en resultaten krijgen
- uw aangepaste Yolo-objectdetectiemodel trainen
- Taakstatement
- Dataset & annotaties
- waar gegevens van
- gegevens annoteren voor YOLO
- hoe gegevens van andere formaten te converteren naar Yolo
- gegevens splitsen in subsets
- gegevensgeneratoren aanmaken
- installatie & setup vereist voor modeltraining
- Model training
- Vereisten
- modelobject initialisatie
- het definiëren van callbacks
- aanpassen van het model
- getraind aangepast model in inferentiemodus
- conclusies
- Anton Morgunov
- TensorFlow Object Detection API: Best Practices to Training, Evaluation & Deployment
objectdetectie als taak in Computer Vision
komen we elke dag in ons leven objecten tegen. Kijk om je heen en je vindt meerdere objecten om je heen. Als mens kun je gemakkelijk elk object dat je ziet detecteren en identificeren. Het is natuurlijk en kost niet veel moeite.
voor computers is het detecteren van objecten echter een taak waarvoor een complexe oplossing nodig is. Voor een computer om “objecten te detecteren” betekent het verwerken van een invoerafbeelding (of een enkel frame van een video) en reageren met informatie over objecten op de afbeelding en hun positie. In termen van computervisie noemen we deze twee taken classificatie en lokalisatie. We willen dat de computer zegt wat voor soort objecten op een gegeven beeld worden gepresenteerd en waar ze zich precies bevinden.
er zijn meerdere oplossingen ontwikkeld om computers te helpen objecten te detecteren. Vandaag gaan we een state-of-the-art algoritme verkennen genaamd YOLO, dat hoge nauwkeurigheid bereikt met real-time snelheid. In het bijzonder leren we hoe we dit algoritme kunnen trainen op een aangepaste dataset in TensorFlow / Keras.
laten we eerst eens kijken wat YOLO precies is en waar het beroemd om is.
YOLO als real-time objectdetector
Wat is YOLO?
YOLO is een acroniem voor “You Only Look Once” (verwar het niet met “You Only Live Once from The Simpsons”). Zoals de naam al doet vermoeden, is een enkele “look” voldoende om alle objecten op een afbeelding te vinden en te identificeren.
in termen van machine learning kunnen we zeggen dat alle objecten worden gedetecteerd via een enkel algoritme. Het wordt gedaan door een afbeelding te delen in een raster en het voorspellen van bounding boxes en klasse waarschijnlijkheden voor elke cel in een raster. Voor het geval we YOLO willen gebruiken voor autodetectie, hier is hoe het raster en de voorspelde bounding boxes eruit zouden kunnen zien:

Bounding box die YOLO voorspelt voor de eerste auto is in rood.
Bounding box die YOLO voorspelt voor de tweede auto is geel.
bron van de afbeelding.
de bovenstaande afbeelding bevat alleen de uiteindelijke set van dozen verkregen na het filteren. Het is vermeldenswaard dat YOLO ‘ s raw-uitvoer veel bounding boxes voor hetzelfde object bevat. Deze dozen verschillen in vorm en grootte. Zoals u kunt zien in de afbeelding hieronder, sommige dozen zijn beter in het vastleggen van het doel object, terwijl anderen aangeboden door een algoritme slecht presteren.

alle gele dozen zijn voor de tweede auto.
de vetgedrukte rode en gele dozen zijn het beste voor autodetectie.
bron van de afbeelding.
om het beste begrenzingskader voor een bepaald object te selecteren, wordt een niet-maximaal onderdrukkingsalgoritme (NMS) toegepast.

dozen voorspeld voor de auto ‘ s om alleen die te houden die het beste vast te leggen objecten.
bron van de afbeelding.
alle boxen die YOLO voorspelt hebben een betrouwbaarheidsniveau dat ermee verbonden is. NMS gebruikt deze betrouwbaarheidswaarden om de kaders te verwijderen die met weinig zekerheid werden voorspeld. Meestal zijn dit allemaal kaders die worden voorspeld met een vertrouwen van minder dan 0,5.

u kunt de vertrouwens-scores zien in de linkerbovenhoek van elk vak, naast De objectnaam.
bron van de afbeelding.
wanneer alle onzekere bounding boxes zijn verwijderd, blijven alleen de boxes met het hoge betrouwbaarheidsniveau over. Om de beste van de best presterende kandidaten te selecteren, selecteert NMS het kader met het hoogste betrouwbaarheidsniveau en berekent het hoe het kruist met de andere vakken rond. Als een kruising hoger is dan een bepaald drempelniveau, wordt het begrenzingsvak met een lagere betrouwbaarheid verwijderd. In het geval dat NMS twee kaders vergelijkt die een snijpunt hebben onder een geselecteerde drempel, worden beide kaders bewaard in definitieve voorspellingen.
YOLO vergeleken met andere detectoren
hoewel een convolutioneel neuraal net (CNN) wordt gebruikt onder de motorkap van YOLO, is het nog steeds in staat om objecten met real-time prestaties te detecteren. Het is mogelijk dankzij YOLO ‘ s vermogen om de voorspellingen tegelijkertijd te doen in een één-fase aanpak.
andere, langzamere algoritmen voor objectdetectie (zoals snellere R-CNN) gebruiken doorgaans een tweefasenaanpak:
- in de eerste fase worden interessante beeldgebieden geselecteerd. Dit zijn de delen van een afbeelding die objecten kunnen bevatten;
- in de tweede fase wordt elk van deze gebieden geclassificeerd met behulp van een convolutioneel neuraal net.
meestal zijn er veel gebieden op een afbeelding met de objecten. Al deze regio ‘ s worden ingedeeld. Classificatie is een tijdrovende operatie, dat is de reden waarom de twee-fase object detectie aanpak langzamer presteert in vergelijking met een-fase detectie.
YOLO selecteert geen interessante delen van een afbeelding, dat is niet nodig. In plaats daarvan voorspelt het bounding dozen en klassen voor de hele afbeelding in een enkele forward net pass.
hieronder kunt u zien hoe snel YOLO wordt vergeleken met andere populaire detectoren.

SSD en YOLO zijn eenfasige objectdetectoren, terwijl Faster-RCNN
en R-FCN tweefasige objectdetectoren zijn.
bron van de afbeelding.
versies van YOLO
YOLO werd voor het eerst geïntroduceerd in 2015 door Joseph Redmon in zijn onderzoeksartikel getiteld “You Only Look Once: Unified, Real-Time Object Detection”.
sindsdien is YOLO sterk geëvolueerd. In 2016 beschreef Joseph Redmon de tweede YOLO-versie in “YOLO9000: Better, Faster, Stronger”.
ongeveer twee jaar na de tweede Yolo-update kwam Joseph met een nieuwe net-upgrade. Zijn paper, genaamd “YOLOv3: An Incremental Improvement”, trok de aandacht van vele computeringenieurs en werd populair in de machine learning gemeenschap.In 2020 besloot Joseph Redmon te stoppen met het onderzoek naar computervisie, maar het weerhield YOLO er niet van om door anderen te worden ontwikkeld. Datzelfde jaar ontwierp een team van drie ingenieurs (Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao) de vierde versie van YOLO, nog sneller en nauwkeuriger dan voorheen. Hun bevindingen worden beschreven in de ” YOLOv4: Optimale snelheid en nauwkeurigheid van objectdetectie ” paper ze gepubliceerd op 23 April 2020.
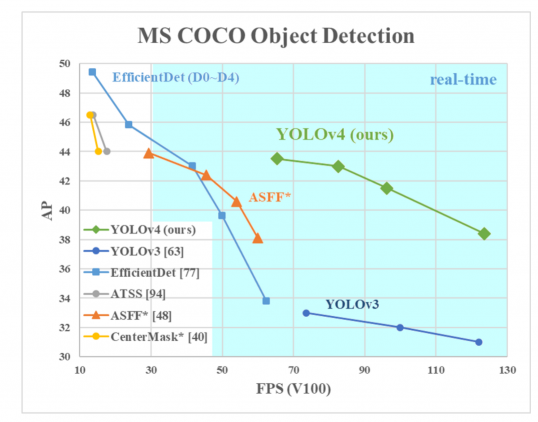
AP op de Y-as is een metriek die “gemiddelde precisie”wordt genoemd. Het beschrijft de nauwkeurigheid van het net.
FPS (frames per seconde) op de X-as is een metriek die snelheid beschrijft.
bron van de afbeelding.
twee maanden na de release van de 4e versie, een onafhankelijke Ontwikkelaar, Glenn Jocher, kondigde de 5e versie van YOLO. Deze keer werd er geen onderzoekspaper gepubliceerd. Het net werd beschikbaar op Jocher ‘ s GitHub pagina als een PyTorch implementatie. De vijfde versie had ongeveer dezelfde nauwkeurigheid als de vierde versie, maar het was sneller.
tot slot kregen we in juli 2020 nog een grote Yolo-update. In een paper getiteld “PP-YOLO: An Effective and Efficient Implementation of Object Detector”, kwamen Xiang Long en team met een nieuwe versie van YOLO. Deze iteratie van YOLO was gebaseerd op de 3e modelversie en overtrof de prestaties van YOLO v4.

de afbeelding op de Y-as is een metriek genaamd “mean average precision”. Het beschrijft de nauwkeurigheid van het net.
FPS (frames per seconde) op de X-as is een metriek die snelheid beschrijft.
bron van de afbeelding.
In deze tutorial gaan we een kijkje nemen op YOLOv4 en de implementatie ervan. Waarom YOLOv4? Drie redenen:
- het heeft brede goedkeuring in de machine learning gemeenschap;
- deze versie heeft zijn hoge prestaties bewezen in een breed scala van detectietaken;
- YOLOv4 is geïmplementeerd in meerdere populaire frameworks, waaronder TensorFlow en Keras, waarmee we gaan werken.
voorbeelden van YOLO applicaties
voordat we verder gaan met het praktische deel van dit artikel, het implementeren van onze aangepaste Yolo gebaseerde object detector, wil ik jullie graag een paar coole YOLOv4 implementaties laten zien, en dan gaan we onze implementatie maken.
let op hoe snel en accuraat de voorspellingen zijn!
hier is het eerste indrukwekkende voorbeeld van wat YOLOv4 kan doen, het detecteren van meerdere objecten uit verschillende spel-en filmscènes.
u kunt deze objectdetectiedemo ook bekijken vanuit een echte cameraweergave.
YOLO als objectdetector in TensorFlow & Keras
TensorFlow & Keras frameworks in Machine Learning

bron van de afbeelding.
kaders zijn essentieel in elk IT-domein. Machine learning is geen uitzondering. Er zijn verschillende gevestigde spelers op de ML-markt die ons helpen de algehele ervaring met programmeren te vereenvoudigen. PyTorch, scikit-learn, TensorFlow, Keras, MXNet en Caffe zijn slechts een paar het vermelden waard.
vandaag gaan we nauw samenwerken met TensorFlow/Keras. Niet verrassend, deze twee behoren tot de meest populaire frameworks in het machine learning universum. Het is grotendeels te wijten aan het feit dat zowel TensorFlow en Keras bieden rijke mogelijkheden voor ontwikkeling. Deze twee kaders zijn vrij vergelijkbaar met elkaar. Zonder te veel in details te graven, is het belangrijkste om te onthouden dat Keras slechts een wrapper is voor het TensorFlow framework.
Yolo-implementatie in TensorFlow & Keras
ten tijde van het schrijven van dit artikel waren er 808 repositories met YOLO-implementaties op een TensorFlow / Keras-backend. YOLO versie 4 is wat we gaan implementeren. Het beperken van de zoekopdracht naar alleen YOLO v4, ik kreeg 55 repositories.
toen ik ze allemaal zorgvuldig doorbladerde, vond ik een interessante kandidaat om mee door te gaan.
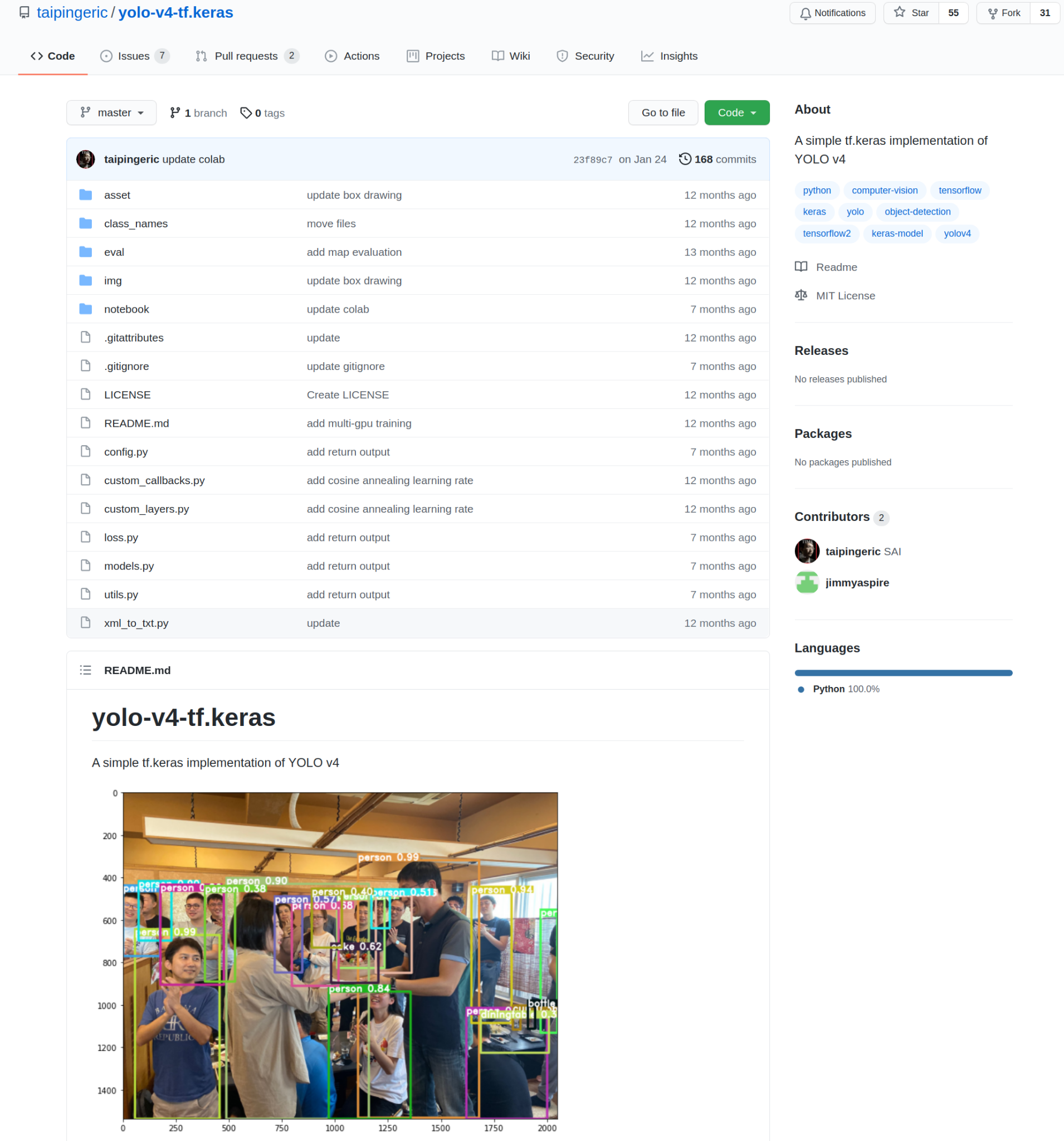
bron van de afbeelding.
deze implementatie werd ontwikkeld door taipingeric en jimmyaspire. Het is heel eenvoudig en zeer intuïtief als je eerder met TensorFlow en Keras hebt gewerkt.
om met deze implementatie te beginnen, kloon je de repo naar je lokale machine. Vervolgens zal ik u laten zien hoe u YOLO out of the box kunt gebruiken en hoe u uw eigen aangepaste objectdetector kunt trainen.
pre-trained YOLO Out-of-the-box draaien en resultaten krijgen
kijkend naar de “Quick Start” sectie van de repo, kunt u zien dat om een model draaiend te krijgen, we gewoon YOLO als een klasse-object moeten importeren en de modelgewichten moeten laden:
from models import Yolov4model = Yolov4(weight_path='yolov4.weights', class_name_path='class_names/coco_classes.txt')
merk op dat u modelgewichten van tevoren handmatig moet downloaden. Het model gewichten bestand dat wordt geleverd met YOLO komt uit de coco dataset en het is beschikbaar op de AlexeyAB officiële darknet project pagina op GitHub. U kunt de gewichten direct downloaden via deze link.
direct daarna is het model volledig klaar om te werken met afbeeldingen in de inferentiemodus. Gebruik gewoon de predict () methode voor een afbeelding van uw keuze. De methode is standaard voor TensorFlow en Keras frameworks.
pred = model.predict('input.jpg')
bijvoorbeeld voor deze invoerafbeelding:

ik kreeg de volgende modeluitvoer:

voorspellingen dat het gemaakte model wordt geretourneerd in een handige vorm van een panda DataFrame. We krijgen class naam, box grootte, en Coördinaten voor elk gedetecteerd object:

veel nuttige informatie over de gedetecteerde objecten
er zijn meerdere parameters binnen de predict () methode die ons laten specificeren of we de afbeelding willen plotten met de voorspelde bounding boxes, tekstuele namen voor elk object, enz. Bekijk de docstring die samengaat met de predict () methode om vertrouwd te raken met wat er voor ons beschikbaar is:

je mag verwachten dat je model alleen objecttypes kan detecteren die strikt beperkt zijn tot de coco dataset. Om te weten welke objecttypes een voorgetraind YOLO model kan detecteren, bekijk de coco_classes.txt-bestand beschikbaar in … / yolo-v4-tf.kers / class_namen/. Er zitten 80 objecttypes in.
uw aangepaste Yolo-objectdetectiemodel trainen
Taakstatement

om een objectdetectiemodel te ontwerpen, moet u weten welke objecttypen u wilt detecteren. Dit moet een beperkt aantal objecttypen zijn waarvoor u uw detector wilt maken. Het is goed om een lijst van objecttypes te hebben opgesteld terwijl we naar de werkelijke modelontwikkeling gaan.
idealiter zou u ook een geannoteerde dataset moeten hebben met objecten van uw interesse. Deze dataset zal worden gebruikt om een detector te trainen en te valideren. Als je er nog geen dataset of annotatie voor hebt, maak je geen zorgen, Ik zal je laten zien waar en hoe je het kunt krijgen.
Dataset & annotaties
waar gegevens van
te krijgen als u een geannoteerde dataset hebt om mee te werken, sla dit deel dan over en ga verder met het volgende hoofdstuk. Maar als u een dataset voor uw project nodig hebt, gaan we nu online bronnen verkennen waar u gegevens kunt krijgen.
het maakt niet echt uit in welk veld U werkt, er is een grote kans dat er al een open-source dataset is die u kunt gebruiken voor uw project.
de eerste bron die ik aanbeveel is het artikel “50+ Object Detection Datasets from different industry domains” van Abhishek Annamraju die prachtige geannoteerde datasets heeft verzameld voor industrieën zoals mode, Retail, Sport, Geneeskunde en nog veel meer.

bron van de afbeelding.
andere twee geweldige plaatsen om te zoeken naar de gegevens zijn paperswithcode.com en roboflow.com die toegang bieden tot hoogwaardige datasets voor objectdetectie.
bekijk deze bovenstaande assets om de gegevens te verzamelen die u nodig hebt of om de dataset die u al hebt te verrijken.
gegevens annoteren voor YOLO
als uw dataset met afbeeldingen zonder annotaties wordt geleverd, moet u de annotatietaak zelf uitvoeren. Deze handmatige bediening is vrij tijdrovend, dus zorg ervoor dat je genoeg tijd hebt om het te doen.
als annotatietool kunt u meerdere opties overwegen. Persoonlijk zou ik het gebruik van LabelImg aanraden. Het is een lichtgewicht en eenvoudig te gebruiken image annotation tool die direct annotaties voor YOLO-modellen kan uitvoeren.
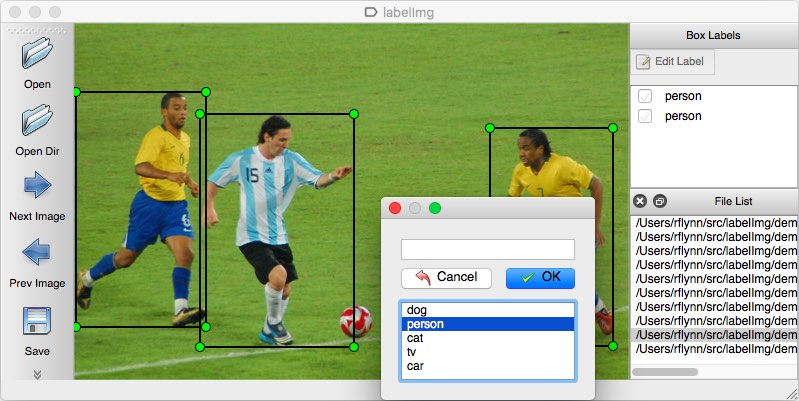
bron van de afbeelding.
hoe gegevens van andere formaten te converteren naar Yolo
annotaties voor YOLO zijn in de vorm van txt-bestanden. Elke regel in een txt-bestand fol YOLO moet het volgende formaat hebben:
image1.jpg 10,15,345,284,0image2.jpg 100,94,613,814,0 31,420,220,540,1
we kunnen elke regel uit het txt-bestand breken en zien waaruit het bestaat:
- het eerste deel van een regel specificeert de basisnamen voor de afbeeldingen: image1.jpg, image2.jpg
- het tweede deel van een regel definieert de coördinaten van het begrenzingsvak en het klassenlabel. Bijvoorbeeld, 10,15,345,284,0 Staten voor xmin, ymin, xmax, ymax, class_id
- als een gegeven afbeelding meer dan één object bevat, zullen er meerdere kaders en klassenlabels naast de afbeeldingsbasnaam staan, gedeeld door een spatie.
Bounding box coördinaten zijn een duidelijk concept, maar hoe zit het met het class_id nummer dat het class label specificeert? Elke class_id is gekoppeld aan een bepaalde klasse in een ander txt bestand. Bijvoorbeeld, pre-getrainde YOLO wordt geleverd met de coco_classes.txt-bestand dat er zo uitziet:
personbicyclecarmotorbikeaeroplanebus...
aantal regels in de klassen bestanden moeten overeenkomen met het aantal klassen dat uw detector gaat detecteren. De nummering begint bij nul, wat betekent dat het class_id-nummer voor de eerste klasse in het classes-bestand 0 zal zijn. Klasse die op de tweede regel in het classes txt bestand wordt geplaatst zal nummer 1 hebben.
nu weet u hoe de annotatie voor YOLO eruit ziet. Om door te gaan met het maken van een aangepaste object detector ik dring er bij u op aan om twee dingen nu te doen:
- Maak een klassen txt-bestand waar u palace van de klassen die u wilt dat uw detector te detecteren. Onthoud dat klassenorde belangrijk is.
- Maak een txt-bestand met annotaties. In het geval u al annotatie maar in de VOC-formaat (.XMLs), kunt u dit bestand gebruiken om te transformeren van XML naar YOLO.
gegevens splitsen in subsets
Zoals altijd willen we de dataset splitsen in 2 subsets: voor training en voor validatie. Het kan zo eenvoudig worden gedaan als:
from utils import read_annotation_lines train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1)
gegevensgeneratoren aanmaken
wanneer de gegevens worden gesplitst, kunnen we overgaan tot de initialisatie van de gegevensgenerator. We hebben een datagenerator voor elk databestand. In ons geval hebben we een generator voor de training subset en voor de validatie subset.
zo worden de gegevensgeneratoren gemaakt:
from utils import DataGenerator FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
om alles samen te vatten, hier is wat de volledige code voor data splitsen en generator creatie eruit ziet als:
from utils import read_annotation_lines, DataGenerator train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1) FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
installatie & setup vereist voor modeltraining
laten we het hebben over de vereisten die essentieel zijn om uw eigen objectdetector te maken:
- je zou Python al op je computer moeten hebben geïnstalleerd. In het geval dat je nodig hebt om het te installeren, Ik beveel het volgen van deze officiële gids door Anaconda;
- als uw computer een CUDA-enabled GPU (een GPU gemaakt door NVIDIA), dan zijn een paar relevante bibliotheken nodig om GPU-gebaseerde training te ondersteunen. In het geval dat u GPU-ondersteuning moet inschakelen, controleer de richtlijnen op de website van NVIDIA. Uw doel is om de nieuwste versie van zowel de CUDA Toolkit te installeren, en cuDNN voor uw besturingssysteem;
- u wilt misschien een onafhankelijke virtuele omgeving organiseren om in te werken. Dit project vereist dat TensorFlow 2 geïnstalleerd is. Alle andere bibliotheken zullen later worden geïntroduceerd;
- wat mij betreft, ik was het bouwen en trainen van mijn YOLOv4 model in een Jupyter Notebook ontwikkelomgeving. Hoewel Jupyter Notebook lijkt een redelijke optie om te gaan met, overwegen ontwikkeling in een IDE van uw keuze als u dat wilt.
Model training

Vereisten
nu moet je hebben:
- Een split voor uw dataset;
- Twee gegevens generatoren geïnitialiseerd;
- Een txt-bestand met de lessen.
modelobject initialisatie
initialiseer het YOLOv4 modelobject om klaar te zijn voor een trainingstaak. Zorg ervoor dat je geen gebruikt als waarde voor de weight_path parameter. U moet ook een pad naar uw klassen txt-bestand bij deze stap. Hier is de initialisatiecode die ik gebruikte in mijn project:
class_name_path = 'path2project_folder/model_data/scans_file.txt' model = Yolov4(weight_path=None, class_name_path=class_name_path)
de bovenstaande model initialisatie leidt tot het maken van een model object met een standaard set parameters. Overweeg om de configuratie van je model te veranderen door in een woordenboek een waarde te geven aan de parameter config model.

Config specificeert een set parameters voor het YOLOv4 model.
standaard modelconfiguratie is een goed startpunt, maar u wilt misschien experimenteren met andere configuraties voor een betere modelkwaliteit.
in het bijzonder raad ik ten zeerste aan om te experimenteren met ankers en img_size. Ankers specificeer de geometrie van de ankers die zullen worden gebruikt om objecten vast te leggen. Hoe beter de vormen van de ankers passen bij de objecten vormen, hoe hoger de prestaties van het model zal zijn.
het verhogen van de img_size kan ook in sommige gevallen nuttig zijn. Houd er rekening mee dat hoe hoger de afbeelding is, hoe langer het model de gevolgtrekking doet.
in het geval dat u Neptune als een tracking tool wilt gebruiken, moet u ook een experiment starten, zoals dit:
import neptune.new as neptune run = neptune.init(project='projects/my_project', api_token=my_token)
het definiëren van callbacks
TensorFlow & Keras laat ons callbacks gebruiken om de voortgang van de training te controleren, controlepunten te maken en trainingsparameters te beheren (bijvoorbeeld Leersnelheid).
voordat u uw model aanpast, definieert u callbacks die nuttig zijn voor uw doeleinden. Zorg ervoor dat u paden opgeeft om modelcontrolepunten en bijbehorende logboeken op te slaan. Hier is hoe ik het deed in een van mijn projecten:
# defining pathes and callbacks dir4saving = 'path2checkpoint/checkpoints'os.makedirs(dir4saving, exist_ok = True) logdir = 'path4logdir/logs'os.makedirs(logdir, exist_ok = True) name4saving = 'epoch_{epoch:02d}-val_loss-{val_loss:.4f}.hdf5' filepath = os.path.join(dir4saving, name4saving) rLrCallBack = keras.callbacks.ReduceLROnPlateau(monitor = 'val_loss', factor = 0.1, patience = 5, verbose = 1) tbCallBack = keras.callbacks.TensorBoard(log_dir = logdir, histogram_freq = 0, write_graph = False, write_images = False) mcCallBack_loss = keras.callbacks.ModelCheckpoint(filepath, monitor = 'val_loss', verbose = 1, save_best_only = True, save_weights_only = False, mode = 'auto', period = 1)esCallBack = keras.callbacks.EarlyStopping(monitor = 'val_loss', mode = 'min', verbose = 1, patience = 10)
u zou kunnen hebben gemerkt dat in de bovenstaande callbacks Set TensorBoard wordt gebruikt als een tracking tool. Overweeg Neptune te gebruiken als een veel geavanceerdere tool voor het volgen van experimenten. Als dat zo is, vergeet dan niet om een andere callback te initialiseren om integratie met Neptune mogelijk te maken:
from neptune.new.integrations.tensorflow_keras import NeptuneCallback neptune_cbk = NeptuneCallback(run=run, base_namespace='metrics')
aanpassen van het model
om de trainingstaak af te trappen, past u gewoon het modelobject aan met behulp van de standaard fit() methode in TensorFlow / Keras. Zo begon ik mijn model te trainen:
model.fit(data_gen_train, initial_epoch=0, epochs=10000, val_data_gen=data_gen_val, callbacks= )
wanneer de training wordt gestart, ziet u een standaard voortgangsbalk.

het trainingsproces zal het model aan het einde van elk tijdperk evalueren. Als je een set callbacks gebruikt die vergelijkbaar zijn met wat ik geïnitialiseerd en doorgegeven heb tijdens het passen, worden die checkpoints die modelverbetering tonen in termen van lager verlies opgeslagen in een opgegeven map.
als er geen fouten optreden en het opleidingsproces soepel verloopt, wordt de opleidingstaak stopgezet, hetzij vanwege het einde van het opleidingstijdperk, hetzij als het vroegtijdig stoppen van de callback geen verdere modelverbetering detecteert en het gehele proces stopt.
in ieder geval moet u eindigen met meerdere model checkpoints. We willen de beste kiezen uit alle beschikbare en gebruiken het voor gevolgtrekking.
getraind aangepast model in inferentiemodus
het uitvoeren van een getraind model in de inferentiemodus is vergelijkbaar met het uitvoeren van een voorgetraind model out of the box.

je initialiseert een modelobject dat het pad naar het beste checkpoint passeert, evenals het pad naar het txt-bestand met de klassen. Hier is hoe model initialisatie eruit ziet voor mijn project:
from models import Yolov4model = Yolov4(weight_path='path2checkpoint/checkpoints/epoch_48-val_loss-0.061.hdf5', class_name_path='path2classes_file/my_yolo_classes.txt')
wanneer het model is geïnitialiseerd, gebruik dan gewoon de predict() methode voor een afbeelding van uw keuze om de voorspellingen te krijgen. Als een samenvatting, detecties dat het model gemaakt worden geretourneerd in een handige vorm van een panda DataFrame. We krijgen de klassenaam, de grootte van het vak en de Coördinaten voor elk gedetecteerd object.
conclusies
u hebt zojuist geleerd hoe u een aangepaste yolov4 objectdetector kunt maken. We hebben het end-to-end proces doorlopen, beginnend bij het verzamelen van gegevens, annotatie en transformatie. Je hebt voldoende kennis over de vierde YOLO versie en hoe deze verschilt van andere detectoren.
niets weerhoudt u nu van het trainen van uw eigen model in TensorFlow en Keras. Je weet waar je een voorgetraind model vandaan haalt en hoe je de training moet starten.
in mijn volgende artikel zal ik u enkele van de best practices en life hacks laten zien die zullen helpen de kwaliteit van het uiteindelijke model te verbeteren. Blijf bij ons!



Anton Morgunov
Computer Vision Engineer op Basis.Centrum
liefhebber van Machine Learning. Gepassioneerd over computervisie. Geen papier – meer bomen! Werken aan de eliminatie van papieren kopieën door over te gaan naar volledige digitalisering!
read NEXT
TensorFlow Object Detection API: Best Practices to Training, Evaluation & Deployment
13 mins read / Author Anton Morgunov / Updated May 28th, 2021
dit artikel is het tweede deel van een serie waarin je een end-to-end workflow leert voor TensorFlow Object Detection en zijn API. In het eerste artikel, je geleerd hoe je een aangepaste object detector vanaf nul te maken, maar er zijn nog steeds tal van dingen die je aandacht nodig hebben om echt bekwaam te worden.
we zullen onderwerpen onderzoeken die net zo belangrijk zijn als het modelcreatieproces dat we al hebben doorlopen. Hier zijn enkele van de vragen die we zullen beantwoorden:
- hoe evalueer ik mijn model en krijg ik een schatting van de prestaties?
- Wat zijn de Hulpmiddelen die ik kan gebruiken om modelprestaties bij te houden en resultaten te vergelijken over meerdere experimenten?
- Hoe kan ik mijn model exporteren om het in de inferentiemodus te gebruiken?
- Is er een manier om de prestaties van het model nog meer te verbeteren?
Lees verder ->