Crawl budget is het aantal pagina ‘ s dat zoekmachines binnen een bepaalde termijn op een website zullen crawlen.
zoekmachines berekenen crawl budget op basis van crawl limit (hoe vaak ze kunnen kruipen zonder problemen te veroorzaken) en crawl demand (hoe vaak ze een site willen crawlen).
als u crawl budget verspilt, zullen zoekmachines niet in staat zijn om uw website efficiënt te crawlen, wat uiteindelijk uw SEO-prestaties zou schaden.
- Wat is crawl budget?
- waarom wijzen zoekmachines crawl budget toe aan websites?
- hoe wijzen ze crawl budget toe aan websites?
- Is crawl budget slechts ongeveer pagina ‘ s?
- Hoe werkt crawl limit / host load in de praktijk?
- Hoe werkt crawl demand / crawl scheduling in de praktijk?
- vergeet niet: crawl capaciteit van het systeem zelf
- waarom zou je geven om crawl budget?
- Wat is het crawl budget voor mijn website?
- Crawl budget in Google Search Console
- Ga naar de bron: server logs
- hoe optimaliseer je je crawl budget?
- toegankelijke URL ’s met parameters
- Duplicate content
- inhoud van lage kwaliteit
- verbroken en omgeleidende links
- onjuiste URL ’s in XML-sitemaps
- ContentKing
- pagina ‘ s met hoge laadtijden / time-outs
- grote aantallen niet-indexeerbare pagina ‘s
- slechte interne linkstructuur
- Hoe verhoog je het crawl budget van je website?
- veelgestelde vragen over crawl budget
- 1. 🧾 Wat is crawl budget?
- 2. 🤔 Hoe kan ik mijn crawl budget verhogen?
- 3. 🤷 Wat kan mijn crawl budget beperken?
- 4. 🤖 Moet Ik gebruik maken van canonieke URL en meta robots op alle?
Wat is crawl budget?
Crawl budget is het aantal pagina ‘ s dat zoekmachines binnen een bepaalde termijn op een website zullen doorzoeken.
waarom wijzen zoekmachines crawl budget toe aan websites?
omdat ze geen onbeperkte bronnen hebben en hun aandacht over miljoenen websites verdelen. Dus ze hebben een manier nodig om prioriteit te geven aan hun kruipende inspanning. Het toewijzen van crawl budget Aan elke website helpt hen dit te doen.
hoe wijzen ze crawl budget toe aan websites?
dat is gebaseerd op twee factoren, crawl limit en crawl demand:
- Crawl limit / host load: hoeveel crawling kan een website verwerken, en wat zijn de voorkeuren van de eigenaar?
- Crawl demand / crawl scheduling: welke URL ‘ s het meest waard zijn (opnieuw)crawlen, gebaseerd op de populariteit en hoe vaak het wordt bijgewerkt.
Crawl budget is een veel voorkomende term binnen SEO. Crawl budget wordt soms ook wel kruipruimte of kruiptijd genoemd.

Is crawl budget slechts ongeveer pagina ‘ s?
het is eigenlijk niet, voor het gemak hebben we het over pagina ‘ s, maar in werkelijkheid gaat het over elk document dat zoekmachines doorzoeken. Enkele voorbeelden van andere documenten: JavaScript-en CSS-bestanden, mobiele pagina-varianten, hreflang – varianten en PDF-bestanden.
Hoe werkt crawl limit / host load in de praktijk?
Crawl limit, of host load als je wilt, is een belangrijk onderdeel van crawl budget. Zoekmachines crawlers zijn ontworpen om te voorkomen dat overbelasting van een webserver met verzoeken, dus ze zijn voorzichtig over dit.Hoe bepalen zoekmachines de crawl limit van een website? Er zijn verschillende factoren die de crawl limit beïnvloeden. Om er een paar te noemen:
- tekenen van platform in slechte vorm: hoe vaak opgevraagde URL ‘ s time-out of return server fouten.
- het aantal websites dat op de host draait: als uw website op een gedeeld hostingplatform met honderden andere websites draait en u een vrij grote website hebt, is de crawl-limiet voor uw website zeer beperkt omdat de crawl-limiet op hostniveau wordt bepaald. Je moet de crawl limiet van de host delen met alle andere sites die erop draaien. In dit geval zou je veel beter van op een dedicated server, die zal waarschijnlijk ook massaal verminderen laadtijden voor uw bezoekers.
een ander ding om te overwegen is het hebben van aparte mobiele en desktop sites draaien op dezelfde host. Ze hebben ook een gedeelde crawl limit. Dus houd dit in gedachten.
zijn zoekmachines kruipen de belangrijkste delen van uw website? Voer een snelle test uit met ContentKing!
Hoe werkt crawl demand / crawl scheduling in de praktijk?
Crawl demand, of crawl scheduling, gaat over het bepalen van de waarde van het opnieuw crawlen van URL ‘ s. Nogmaals, veel factoren beïnvloeden crawl vraag waaronder:
- Populariteit: hoeveel inkomende interne en inkomende externe links een URL heeft, maar ook het aantal query ‘ s waarvoor het wordt gerangschikt.
- versheid: hoe vaak de URL wordt bijgewerkt.
- type pagina: is het type pagina dat waarschijnlijk zal veranderen. Neem bijvoorbeeld een product categorie pagina, en een algemene voorwaarden pagina – welke denk je dat verandert het vaakst en verdient om vaker te worden gekropen?

dwingen Google ’s crawlers om terug te komen naar uw site als er niets belangrijker te vinden (dwz zinvolle verandering) is geen goede strategie en ze zijn vrij slim in het uitwerken van de vraag of de frequentie van deze pagina’ s veranderen daadwerkelijk toegevoegde waarde. Het beste advies dat ik kan geven is om me te concentreren op het maken van de pagina ’s belangrijker (het toevoegen van meer nuttige informatie, het maken van de pagina’ s inhoud rijk (ze zullen natuurlijk leiden tot meer vragen standaard zolang de focus van een onderwerp wordt gehandhaafd). Door op natuurlijke wijze meer query ’s te activeren als onderdeel van’ recall ‘(impressies) maak je je pagina ‘ s belangrijker en ziehier: je zult waarschijnlijk vaker gecrowled worden.
vergeet niet: crawl capaciteit van het systeem zelf
terwijl zoekmachine Crawl systemen hebben enorme crawl capaciteit, aan het einde van de dag is het beperkt. Dus in een scenario waar 80% van Google ’s datacenters offline gaan op hetzelfde moment, hun crawl capaciteit neemt massaal en op zijn beurt alle websites’ crawl budget.Met dank aan Dawn Anderson (opent in een nieuw tabblad) voor het geven van details over crawl limit, crawl demand en crawl capacity!
waarom zou je geven om crawl budget?
u wilt dat zoekmachines zoveel mogelijk van uw indexeerbare pagina ‘ s vinden en begrijpen, en u wilt dat ze dat zo snel mogelijk doen. Wanneer u nieuwe pagina ‘ s toevoegt en bestaande bijwerkt, wilt u dat zoekmachines deze zo snel mogelijk ophalen. Hoe sneller ze de pagina ‘ s hebben geïndexeerd, hoe sneller je ervan kunt profiteren.
als u crawl budget verspilt, zullen zoekmachines niet in staat zijn om uw website efficiënt te crawlen. Ze zullen tijd besteden aan delen van uw site die er niet toe doen, wat kan resulteren in belangrijke delen van uw website worden onontdekt gelaten. Als ze niet weten over pagina ‘ s, zullen ze niet kruipen en indexeren, en je zult niet in staat zijn om bezoekers binnen te brengen via zoekmachines om hen.
u kunt zien waar dit toe leidt: het verspillen van crawl budget schaadt uw SEO-prestaties.
houd er rekening mee dat crawl budget over het algemeen alleen iets is om je zorgen over te maken als je een grote website hebt, laten we zeggen 10.000 pagina ‘ s en hoger.

een van de meer ondergewaardeerde aspecten van crawl budget is laadsnelheid. Een snellere laad website betekent dat Google kan kruipen meer URL ‘ s in dezelfde hoeveelheid tijd. Onlangs was ik betrokken bij een site upgrade waar de laadsnelheid was een belangrijke focus. De nieuwe site geladen twee keer zo snel als de oude. Toen het live werd geduwd, ging het aantal URL ‘ s Google crawled per dag omhoog van 150.000 naar 600.000 – en bleef daar. Voor een site van deze omvang en omvang, de verbeterde crawl rate betekent dat nieuwe en gewijzigde inhoud wordt gekropen een stuk sneller, en we zien een veel snellere impact van onze SEO inspanningen in SERPs.

een zeer wijze SEO (oke, het was AJ Kohn (opent in een nieuw tabblad)) ooit beroemde zei “Je bent wat Googlebot eet.”. Uw rankings en zoek zichtbaarheid zijn direct gerelateerd aan niet alleen wat Google kruipt op uw site, maar vaak, hoe vaak ze het crawlen. Als Google content mist op uw site, of niet vaak genoeg belangrijke URL ‘ s crawl vanwege beperkte/niet-geoptimaliseerde crawl budget, dan ga je een zeer harde tijd ranking inderdaad. Voor grotere sites kan het optimaliseren van crawl budget het profiel van eerder onzichtbare pagina ‘ s sterk verhogen. Terwijl kleinere site moeten minder zorgen te maken over crawl budget, dezelfde principes van optimalisatie (snelheid, prioritering, link structuur, de-duplicatie, enz.) kan je nog steeds helpen om te rangschikken.

ik ben het meestal eens met Google en voor het grootste deel veel websites hebben geen zorgen te maken over crawl budget. Maar voor websites die groot-in-size zijn en vooral degenen die regelmatig worden bijgewerkt, zoals uitgevers, kan optimaliseren een significant verschil maken.
Wat is het crawl budget voor mijn website?
van alle zoekmachines is Google het meest transparant over hun crawl budget voor uw website.
Crawl budget in Google Search Console
als u uw website hebt geverifieerd in Google Search Console, kunt u enig inzicht krijgen in het crawl budget van uw website voor Google.
volg deze stappen:
- Log in op Google Search Console en kies een website.
- Ga naar
Crawl>Crawl Stats. Daar kun je het aantal pagina ‘ s zien dat Google per dag kruipt.
tijdens de zomer van 2016 zag ons crawl budget er zo uit:
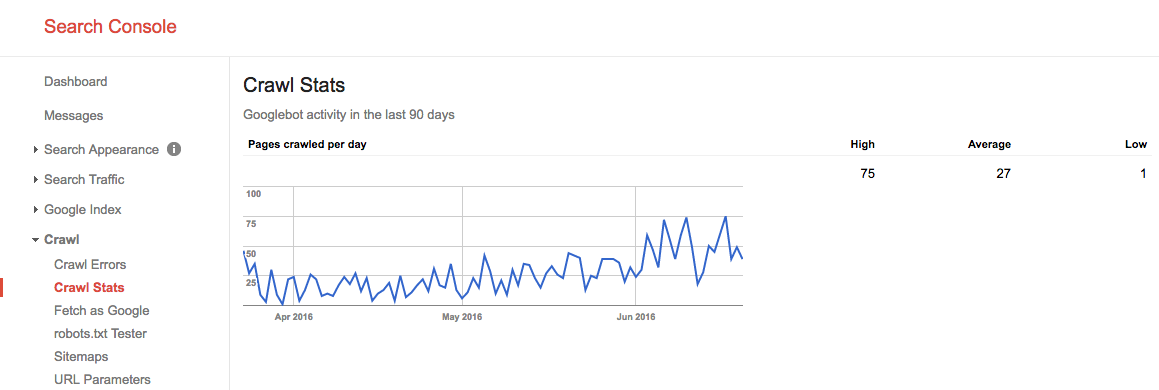
we zien hier dat het gemiddelde crawl budget 27 pagina ‘ s / dag is. Dus in theorie, als dit gemiddelde crawl budget hetzelfde blijft, zou je een maandelijks crawl budget hebben van 27 pagina ’s x 30 dagen = 810 pagina’ s.
Fast forward 2 years, and look at what our crawl budget is right now:
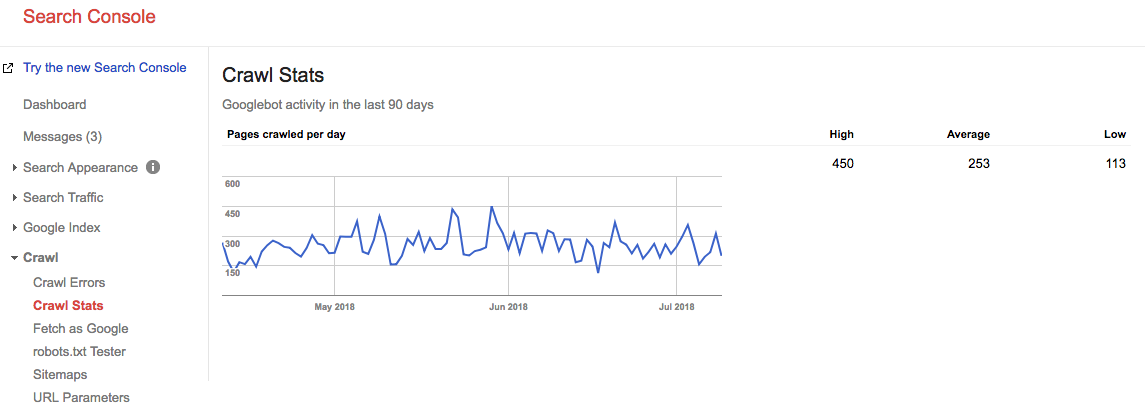
ons gemiddeld gemiddeld crawl budget is 253 pagina ‘ s / dag, dus je zou kunnen zeggen dat ons crawl budget 10X is gestegen in 2 jaar tijd.
Ga naar de bron: server logs
het is zeer interessant om uw server logs te controleren om te zien hoe vaak Google ‘ s crawlers uw website raken. Het is interessant om deze statistieken te vergelijken met degenen die worden gerapporteerd in Google Search Console. Het is altijd beter om te vertrouwen op meerdere bronnen.
laat crawl-problemen geen gemiste kans zijn. Houd uw site continu in de gaten met ContentKing en word in real-time gewaarschuwd voor problemen.
hoe optimaliseer je je crawl budget?
uw crawl-budget optimaliseren komt erop neer dat er geen crawl-budget wordt verspild. In wezen, de vaststelling van de redenen voor verspilde crawl budget. We monitoren duizenden websites; als je elk van hen zou controleren op crawl budget problemen, zou je snel een patroon zien: de meeste websites lijden aan dezelfde soort problemen.
Gemeenschappelijke redenen voor verspilde crawl budget dat we tegenkomen:
- toegankelijke URL ‘ s met parameters: een voorbeeld van een URL met een parameter is
https://www.example.com/toys/cars?color=black. In dit geval wordt de parameter gebruikt om de selectie van een bezoeker op te slaan in een productfilter. - Duplicate content: we noemen pagina ‘ s die sterk op elkaar lijken of precies hetzelfde zijn “duplicate content.”Voorbeelden zijn: gekopieerde pagina ‘s, pagina’ s met interne zoekresultaten en tagpagina ‘ s.
- inhoud van lage kwaliteit: pagina ’s met zeer weinig inhoud, of pagina’ s die geen waarde toevoegen.
- gebroken en omgeleidende links: gebroken links zijn links die verwijzen naar pagina ’s die niet meer bestaan, en omgeleidende links zijn links naar url’ s die worden omgeleid naar andere URL ‘ s.
- inclusief onjuiste URL ’s in XML-sitemaps: niet-indexeerbare pagina’ s en niet-Pagina ’s zoals 3xx, 4xx en 5xx-URL’ s moeten niet worden opgenomen in uw XML-sitemap.
- pagina ‘ s met hoge laadtijd / time-outs: pagina ‘ s die lang duren om te laden, of helemaal niet laden, hebben een negatieve impact op uw crawl budget, omdat het een teken is voor zoekmachines dat uw website niet kan omgaan met het verzoek, en dus kunnen ze uw crawl limiet aan te passen.
- hoge aantallen niet-indexeerbare pagina ‘s: de website bevat veel pagina’ s die niet indexeerbaar zijn.
- slechte interne linkstructuur: als uw interne linkstructuur niet correct is ingesteld, besteden zoekmachines mogelijk niet genoeg aandacht aan sommige van uw pagina ‘ s.

Ik heb vaak gezegd dat Google je baas is. Je zou niet naar een vergadering met je baas gaan tenzij je wist waar je over zou gaan praten, de hoogtepunten van je werk, de doelen van je vergadering. Kortom, je hebt een agenda. Als je het “kantoor” van Google binnenloopt, heb je hetzelfde nodig. Een duidelijke sitehiërarchie zonder veel cruft, een handige XML sitemap, en snelle responstijden zijn allemaal gaan om Google te helpen om te krijgen wat belangrijk is. Niet over het hoofd dit vaak verkeerd begrepen element van SEO.

voor mij is het concept van crawl budget een van de belangrijkste punten van technische SEO. Wanneer u optimaliseert voor crawl budget, valt al het andere op zijn plaats: interne koppeling, het oplossen van fouten, pagina snelheid, URL-optimalisatie, inhoud van lage kwaliteit, en meer. Mensen moeten graven in hun logbestanden vaker te controleren crawl budget voor specifieke URL ‘ s, subdomeinen, directory, enz. Monitoring crawl frequentie is zeer gerelateerd aan crawl budget en super krachtig.
toegankelijke URL ’s met parameters
in de meeste gevallen zouden URL’ s met parameters NIET toegankelijk moeten zijn voor zoekmachines, omdat ze een vrijwel oneindige hoeveelheid URL ‘ s kunnen genereren.We hebben uitgebreid geschreven over dit soort problemen in ons artikel over crawler vallen.
URL ‘ s met parameters worden vaak gebruikt bij het implementeren van productfilters op e-commercesites. Het is prima om ze te gebruiken,; zorg ervoor dat ze niet toegankelijk zijn voor zoekmachines.
Hoe kunt u ze ontoegankelijk maken voor de zoekmachine?
- gebruik uw robots.txt-bestand om zoekmachines te instrueren geen toegang te krijgen tot dergelijke URL ‘ s. Als dit om de een of andere reden geen optie is, gebruikt u de instellingen voor url-parameterverwerking in de Google Search Console en de Webmasterhulpmiddelen van Bing om Google en Bing te instrueren welke pagina ‘ s niet moeten worden doorzocht.
- voeg de waarde van het Nofollow-attribuut toe aan koppelingen op filterkoppelingen. Houd er rekening mee dat Google er vanaf Maart 2020 voor kan kiezen om het nofollow te negeren. Daarom is stap 1 nog belangrijker.
Duplicate content
u wilt niet dat zoekmachines hun tijd besteden aan duplicate content pages, dus het is belangrijk om de duplicate content in uw site te voorkomen of op zijn minst te minimaliseren.
Hoe doet u dit? Door…
- het opzetten van website redirects voor alle domeinvarianten (
HTTP,HTTPS,non-WWW, enWWW). - interne pagina ‘ s met zoekresultaten ontoegankelijk maken voor zoekmachines met uw robots.txt. Hier is een voorbeeld van robots.txt voor een WordPress website.
- het uitschakelen van speciale pagina ’s voor afbeeldingen (bijvoorbeeld: de beruchte afbeeldingsbijlage-pagina’ s in WordPress).
- voorzichtig zijn met het gebruik van taxonomieën zoals categorieën en tags.
Bekijk enkele meer technische redenen voor duplicate content en hoe deze te repareren.
inhoud van lage kwaliteit
pagina ‘ s met zeer weinig inhoud zijn niet interessant voor zoekmachines. Houd ze tot een minimum, of vermijd ze volledig indien mogelijk. Een voorbeeld van inhoud van lage kwaliteit is een FAQ-sectie met links naar de vragen en antwoorden te tonen, waar elke vraag en antwoord wordt geserveerd via een aparte URL.
verbroken en omgeleidende links
verbroken links en lange ketens van omgeleidingenzijn doodlopende wegen voor zoekmachines. Net als bij browsers, Google lijkt te volgen een maximum van vijf geketende omleidingen in een crawl (ze kunnen hervatten kruipen later). Het is onduidelijk hoe goed andere zoekmachines omgaan met latere omleidingen, maar we raden u aan geketende omleidingen volledig te vermijden en het gebruik van omleidingen tot een minimum te beperken.
het is duidelijk dat door het repareren van gebroken links en het omleiden van links, u snel verloren crawl budget kunt herstellen. Naast het herstellen van crawl budget, je bent ook een aanzienlijke verbetering van de gebruikerservaring van een bezoeker. Omleidingen, en ketens van omleidingen in het bijzonder, veroorzaken langere pagina laadtijd en daardoor de gebruikerservaring schaden.
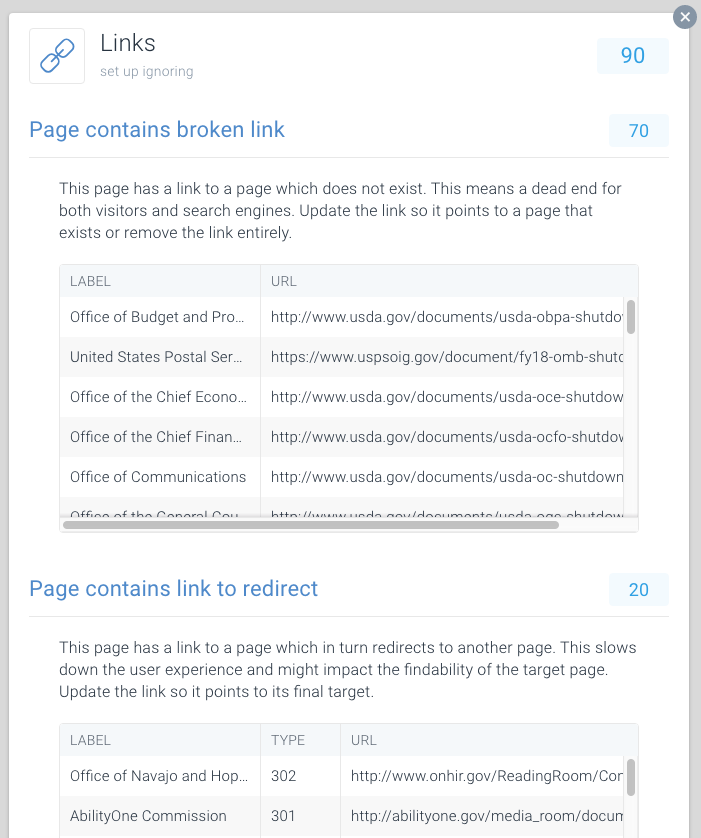
om het vinden van gebroken en omleiden van links gemakkelijk te maken, hebben we speciale Issues hieraan gewijd binnen ContentKing.
Ga naar Issues > Links om erachter te komen of u crawl budgetten verspilt door foutieve koppelingen. Werk elke link bij zodat deze naar een indexeerbare pagina linkt, of verwijder de link als deze niet meer nodig is.
onjuiste URL ’s in XML-sitemaps
alle URL’ s in XML-sitemaps moeten voor indexeerbare pagina ‘ s zijn. Vooral bij grote websites vertrouwen zoekmachines sterk op XML sitemaps om al uw pagina ‘ s te vinden. Als uw XML sitemaps zijn volgepropt met pagina ‘ s die, bijvoorbeeld, niet meer bestaan of worden omgeleid, je verspilt crawl budget. Controleer regelmatig je XML sitemap op niet-indexeerbare URL ‘ s die daar niet thuishoren. Controleer ook op het tegenovergestelde: zoek naar pagina ‘ s die ten onrechte zijn uitgesloten van de XML sitemap. De XML sitemap is een geweldige manier om te helpen zoekmachines besteden crawl budget verstandig.
Google Search Console
- Log in op Google Search Console
- klik op het
Crawltabblad - klik op het
Sitemapstabblad
Bing Webmaster Tools
- Log in op uw Bing Webmaster Tools account
- Klik op de
Configure My Sitetab - Klik op de
Sitemapstabblad
ContentKing
- Log in op uw ContentKing account
- Klik op de
Issuesknop - Klik op de
XML Sitemapknop - In geval van problemen met uw pagina, ontvangt u dit bericht:
Page is incorrectly included in XML sitemap
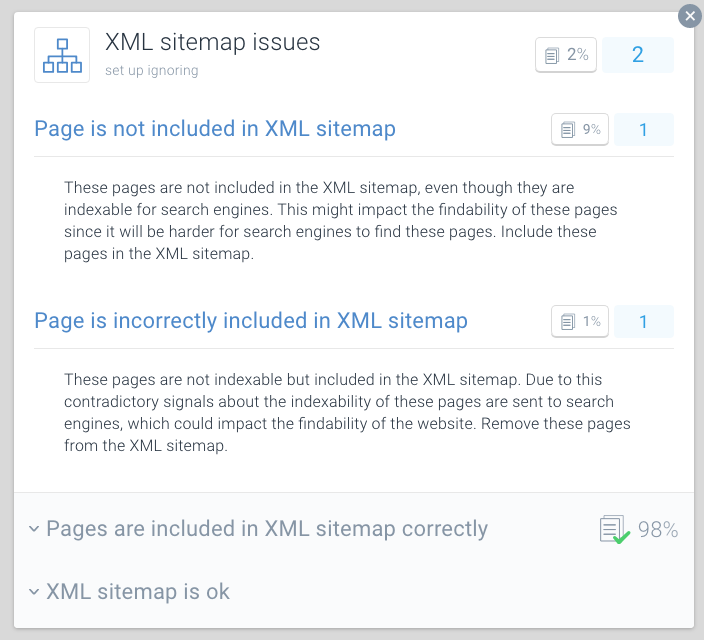
een goede praktijk voor crawl-budget Optimalisatie is om uw XML sitemaps op te splitsen in kleinere sitemaps. U kunt bijvoorbeeld XML sitemaps maken voor elk van de secties van uw website. Als je dit hebt gedaan, kunt u snel bepalen of er problemen gaande zijn in bepaalde delen van uw website.
stel dat uw XML sitemap voor Sectie A 500 links bevat, en 480 zijn geïndexeerd: dan doet u het best goed. Maar als uw XML sitemap voor Sectie B bevat 500 links en slechts 120 zijn geïndexeerd, dat is iets om naar te kijken. Je hebt mogelijk veel niet-indexeerbare URL ‘ s opgenomen in de XML sitemap voor sectie B.
slechte omstandigheden voor crawlers kunnen uw SEO schaden. Gebruik ContentKing om een snelle audit van uw website uit te voeren.
pagina ‘ s met hoge laadtijden / time-outs

wanneer pagina ’s hoge laadtijden hebben of een time-out hebben, kunnen zoekmachines minder pagina’ s bezoeken binnen hun toegewezen crawl-budget voor uw website. Naast dat nadeel, hoge laadtijden van pagina ‘ s en time-outs aanzienlijk schadelijk voor de gebruikerservaring van uw bezoeker, wat resulteert in een lagere conversieratio.
laadtijden van pagina ‘ s boven twee seconden zijn een probleem. Idealiter wordt uw pagina in minder dan een seconde geladen. Controleer regelmatig de laadtijden van uw pagina met tools zoals Pingdom (opent in een nieuw tabblad), WebPagetest (opent in een nieuw tabblad) of GTmetrix (opent in een nieuw tabblad).
Google rapporteert over de laadtijd van pagina ‘ s in beide Google Analytics (onder Behavior > Site Speed) en Google Search Console onder Crawl > Crawl Stats.
Google Search Console en Bing Webmaster Tools rapporteren beide op pagina time-outs. In Google Search Console, dit is te vinden onder Crawl > Crawl Errors, en in Bing Webmaster Tools, het is onder Reports & Data > Crawl Information.
controleer regelmatig of uw pagina ’s snel genoeg worden geladen, en onderneem onmiddellijk actie als ze dat niet zijn. snelladende pagina’ s zijn van vitaal belang voor uw online succes.
grote aantallen niet-indexeerbare pagina ‘s
als uw website een groot aantal niet-indexeerbare pagina’ s bevat die toegankelijk zijn voor zoekmachines, houdt u zoekmachines in principe bezig met het doorzoeken van irrelevante pagina ‘ s.
wij beschouwen de volgende typen als niet-indexeerbare pagina ‘ s:
- omleidingen (3xx)
- pagina ’s die niet gevonden kunnen worden (4xx)
- pagina’ s met serverfouten (5xx)
- pagina ’s die niet indexeerbaar zijn (pagina’ s die de robots noindex-richtlijn of canonieke URL bevatten)
om erachter te komen of je een groot aantal niet-indexeerbare pagina ’s hebt, zoek het totale aantal pagina’ s dat crawlers hebben gevonden binnen uw website en hoe ze afbreken. U kunt dit eenvoudig doen met ContentKing:
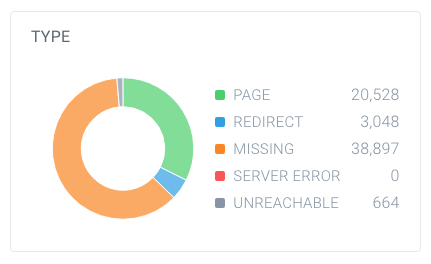
in dit voorbeeld zijn 63.137 URL ’s gevonden, waarvan slechts 20.528 pagina’ s zijn.
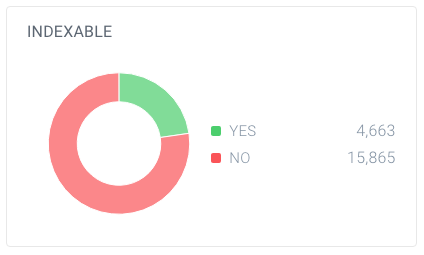
en van deze pagina ‘ s zijn slechts 4.663 indexeerbaar voor zoekmachines. Slechts 7,4% van de URL ‘ s gevonden door ContentKing kan worden geïndexeerd door zoekmachines. Dat is geen goede verhouding, en deze website moet zeker werken aan dat door het opruimen van alle verwijzingen naar hen die onnodig zijn, met inbegrip van:
- de XML sitemap (zie vorige paragraaf)
- Links
- canonieke URL ‘s
- hreflang referenties
- paginering referenties (link rel prev / next)
slechte interne linkstructuur
Hoe pagina’ s binnen uw website naar elkaar linken speelt een grote rol in crawl budget Optimalisatie. Wij noemen dit de interne linkstructuur van uw website. Backlinks opzij, pagina ’s die weinig interne links krijgen veel minder aandacht van zoekmachines dan pagina’ s die zijn gekoppeld aan door een heleboel pagina ‘ s.
vermijd een zeer hiërarchische linkstructuur, waarbij pagina ‘ s in het midden weinig links hebben. In veel gevallen zullen deze pagina ‘ s niet vaak worden gekropen. Het is nog erger voor pagina ‘ s aan de onderkant van de hiërarchie: vanwege hun beperkte hoeveelheid links, kunnen ze heel goed worden verwaarloosd door zoekmachines.
zorg ervoor dat uw belangrijkste pagina ‘ s veel interne links hebben. Pagina ‘ s die onlangs zijn gekropen meestal beter rangschikken in zoekmachines. Houd dit in gedachten en pas hiervoor uw interne linkstructuur aan.
als u bijvoorbeeld een blogartikel uit 2011 hebt dat veel organisch verkeer veroorzaakt, zorg er dan voor dat u er vanaf andere inhoud naar blijft linken. Omdat je door de jaren heen veel andere blogartikelen hebt geproduceerd, wordt dat artikel uit 2011 automatisch naar beneden gedrukt in de interne linkstructuur van je website.

u hoeft zich meestal geen zorgen te maken over de crawl-rate van uw belangrijke pagina ‘ s. Het zijn meestal pagina ‘ s die nieuw zijn, waar je niet naar linkt, en waar mensen niet naar toe gaan, die misschien niet vaak worden gekropen.
Hoe verhoog je het crawl budget van je website?
tijdens een interview (opent in een nieuw tabblad) tussen Eric Enge en Google ’s voormalige hoofd van het webspam team Matt Cutts, werd de relatie tussen autoriteit en crawl budget naar voren gebracht:

de beste manier om erover na te denken is dat het aantal pagina’ s dat we doorzoeken ruwweg evenredig is met uw PageRank. Dus als je veel inkomende links op je root pagina, we zullen zeker crawlen dat. Dan kan je root pagina linken naar andere pagina ‘ s, en die krijgen PageRank en we zullen die ook crawlen. Als je dieper en dieper in uw site, echter, PageRank heeft de neiging om af te nemen.
hoewel Google het updaten van PageRank waarden van pagina ‘ s in het openbaar heeft opgegeven, denken we dat (een vorm van) PageRank nog steeds wordt gebruikt in hun algoritmen. Aangezien PageRank een verkeerd begrepen en verwarrende term is, laten we het page authority noemen. De take-away hier is dat Matt Cutts eigenlijk zegt: Er is een vrij sterke relatie tussen page authority en crawl budget.
om het crawl budget van uw website te verhogen, moet u de autoriteit van uw website vergroten. Een groot deel van dit wordt gedaan door het verdienen van meer links van externe websites. Meer informatie hierover vindt u in onze link building guide.

als ik de industrie hoor praten over crawl budget, praten we meestal over de on-page en Technische veranderingen die we kunnen maken om het crawl budget in de loop van de tijd te verhogen. Echter, afkomstig van een link gebouw achtergrond, de grootste pieken in gekropen pagina ‘ s die we zien in Google Search Console rechtstreeks betrekking hebben op wanneer we winnen grote links voor onze klanten.
veelgestelde vragen over crawl budget
- 🧾 Wat is crawl budget?
- 🤔 Hoe verhoog ik mijn crawl budget?
- 🎛 ️ wat kan mijn Crawl budget beperken?
- 🤖 moet ik überhaupt canonieke URL-en meta-robots gebruiken?
1. 🧾 Wat is crawl budget?
Crawl budget is het aantal pagina ‘ s dat zoekmachines binnen een bepaalde termijn op een website zullen doorzoeken.
2. 🤔 Hoe kan ik mijn crawl budget verhogen?
Google heeft aangegeven dat er een sterke relatie is tussen page authority en crawl budget. Hoe meer autoriteit een pagina heeft, hoe meer crawl budget het heeft. Simpel gezegd, om uw crawl budget te verhogen, bouwen van uw pagina ‘ s Autoriteit.
3. 🤷 Wat kan mijn crawl budget beperken?
Crawl limit, ook bekend als crawl host load, is gebaseerd op vele factoren, zoals de conditie van de website en hosting mogelijkheden. Zoekmachine crawlers zijn ingesteld om te voorkomen dat overbelasting van een webserver. Als uw website serverfouten retourneert, of als de gevraagde URL ‘ s vaak een time-out hebben, zal het crawl-budget beperkter zijn. Evenzo, als uw website draait op een shared hosting platform, de crawl limiet zal hoger zijn als je moet je crawl budget te delen met andere websites die draaien op de hosting.
4. 🤖 Moet Ik gebruik maken van canonieke URL en meta robots op alle?
Ja, en het is belangrijk om de verschillen te begrijpen tussen indexering en crawl.
de canonieke URL-en metarobots-tags sturen een duidelijk signaal naar zoekmachines welke pagina ze in hun index moeten weergeven, maar het voorkomt niet dat ze die andere pagina ‘ s doorzoeken.
u kunt de robots gebruiken.txt-bestand en de nofollow link relatie voor het omgaan met crawl problemen.