
Kilde: Supercharge Dine Datasynsmodeller Med Tensorflow Object Detection API,
Jonathan Huang, Forsker Og Vivek Rathod, Programvareingeniør,
Google AI Blog
- Objektdeteksjon Som en oppgave I Datasyn
- YOLO som objektdetektor i sanntid
- Hva er YOLO?
- YOLO sammenlignet med andre detektorer
- Versjoner AV YOLO
- Eksempler på yolo-applikasjoner
- YOLO som objektdetektor I TensorFlow & Keras
- TensorFlow & Keras-rammer i Maskinlæring
- yolo-implementering I TensorFlow & Keras
- hvordan kjøre pre-trent YOLO out-of-the-box og få resultater
- slik trener du den egendefinerte yolo-objektdeteksjonsmodellen
- Task statement
- Datasett & merknader
- hvor får du data fra
- hvordan annotere data FOR YOLO
- hvordan transformere data fra andre formater TIL YOLO
- Splitting av data i undergrupper
- Opprette data generatorer
- Installasjon & oppsett som kreves for modellopplæring
- Modell trening
- Forutsetninger
- Initialisering av modellobjekt
- Definere tilbakeringinger
- Tilpass modellen
- Trent tilpasset modell i slutningsmodus
- Konklusjoner
- Anton Morgunov
- Tensorflow Object Detection API: Beste Praksis for Opplæring, Evaluering & Distribusjon
Objektdeteksjon Som en oppgave I Datasyn
vi møter objekter hver dag i livet vårt. Se deg rundt, og du vil finne flere objekter rundt deg. Som menneske kan du enkelt oppdage og identifisere hvert objekt du ser. Det er naturlig og krever ikke mye innsats.
for datamaskiner er det imidlertid en oppgave å oppdage objekter som trenger en kompleks løsning. For en datamaskin å» oppdage objekter » betyr å behandle et inngangsbilde (eller en enkelt ramme fra en video) og svare med informasjon om objekter på bildet og deres posisjon. I datasynsbetingelser kaller vi disse to oppgavene klassifisering og lokalisering. Vi vil at datamaskinen skal si hva slags objekter som presenteres på et gitt bilde og hvor nøyaktig de er plassert.
Flere løsninger er utviklet for å hjelpe datamaskiner med å oppdage objekter. I dag skal vi utforske en toppmoderne algoritme KALT YOLO, som oppnår høy nøyaktighet ved sanntidshastighet. Spesielt lærer vi hvordan du trener denne algoritmen på et tilpasset datasett I TensorFlow / Keras.
først, La oss se hva YOLO er og hva DET er kjent for.
YOLO som objektdetektor i sanntid
Hva er YOLO?
YOLO er et akronym for «Du Ser Bare En gang» (ikke forveksle Det Med At Du Bare Lever En Gang Fra The Simpsons). Som navnet antyder, er et enkelt «utseende» nok til å finne alle objekter på et bilde og identifisere dem.
i maskinlæringsvilkår kan vi si at alle objekter oppdages via en enkelt algoritmekjøring. Det gjøres ved å dele et bilde i et rutenett og forutsi avgrensningsbokser og klassesannsynligheter for hver celle i et rutenett. I tilfelle vi ønsker Å ansette YOLO for bildeteksjon, her er hva rutenettet og de forutsagte grenseboksene kan se ut:

Markeringsrammen SOM YOLO spår for den første bilen er i rødt.
Markeringsrammen SOM YOLO spår for den andre bilen er gul.
Kilden til bildet.
bildet ovenfor inneholder bare det siste settet med bokser oppnådd etter filtrering. DET er verdt å merke seg AT YOLOS råutgang inneholder mange grensebokser for samme objekt. Disse boksene varierer i form og størrelse. Som du kan se på bildet nedenfor, er noen bokser bedre til å fange målobjektet, mens andre som tilbys av en algoritme, utfører dårlig.

alle gule bokser er for den andre bilen.
de dristige røde og gule boksene er de beste for biloppdagelse.
Kilden til bildet.
for å velge den beste markeringsrammen for et gitt objekt, brukes en nms-algoritme (Non-maximum suppression).

bokser spådd for bilene å holde bare de som best fange objekter.
Kilden til bildet.
alle bokser SOM YOLO forutser har et konfidensnivå knyttet til dem. NMS bruker disse konfidensverdiene til å fjerne boksene som ble spådd med lav sikkerhet. Vanligvis er disse alle bokser som er spådd med tillit under 0,5.

du kan se konfidenspoengene øverst til venstre i hver boks, ved siden av objektnavnet.
Kilden til bildet.
når alle usikre avgrensningsbokser er fjernet, er det bare boksene med høyt konfidensnivå som er igjen. FOR å velge den beste blant de beste kandidatene, velger NMS boksen med høyest konfidensnivå og beregner hvordan den krysser med de andre boksene rundt. Hvis et skjæringspunkt er høyere enn et bestemt terskelnivå, fjernes markeringsrammen med lavere konfidens. HVIS NMS sammenligner to bokser som har et skjæringspunkt under en valgt terskel, holdes begge boksene i endelige spådommer.
YOLO sammenlignet med andre detektorer
selv om et convolutional neural net (CNN) brukes under yolos hette, er DET fortsatt i stand til å oppdage objekter med sanntidsytelse. DET er mulig takket VÆRE YOLOS evne til å gjøre spådommene samtidig i en enkelt-trinns tilnærming.
andre, langsommere algoritmer for objektdeteksjon (Som Raskere R-CNN) bruker vanligvis en to-trinns tilnærming:
- i første fase velges interessante bildeområder. Dette er delene av et bilde som kan inneholde objekter;
- i den andre fasen klassifiseres hver av disse regionene ved hjelp av et innviklet nevralt nett.
Vanligvis er det mange regioner på et bilde med objektene. Alle disse regionene sendes til klassifisering. Klassifisering er en tidkrevende operasjon, og derfor utfører to-trinns objektdeteksjonstilnærming langsommere sammenlignet med ett-trinns deteksjon.
YOLO velger ikke de interessante delene av et bilde, det er ikke behov for det. I stedet spår det markeringsbokser og klasser for hele bildet i en enkelt frem netto pass.
Nedenfor kan DU se hvor fort YOLO er sammenlignet med andre populære detektorer.

SSD og YOLO er ett-trinns objektdetektorer, Mens Faster-RCNN
og R-FCN er to-trinns objektdetektorer.
Kilden til bildet.
Versjoner AV YOLO
YOLO ble først introdusert i 2015 Av Joseph Redmon i sin forskning papir med tittelen «Du Bare Ser En Gang: Unified, Real-Time Object Detection».
SIDEN DA HAR YOLO utviklet seg mye. I 2016 Beskrev Joseph Redmon DEN ANDRE YOLO-versjonen i «YOLO9000: Bedre, Raskere, Sterkere».
omtrent to år etter DEN ANDRE yolo-oppdateringen kom Joseph opp med en annen nettoppgradering. Hans papir, kalt «YOLOv3: En Inkrementell Forbedring», fanget oppmerksomheten til mange dataingeniører og ble populær i maskinlæringssamfunnet.
I 2020 bestemte Joseph Redmon seg for å slutte å forske på datasyn, men DET stoppet IKKE YOLO fra å bli utviklet av andre. Samme år designet Et team av tre ingeniører (Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao) den fjerde versjonen AV YOLO, enda raskere og mer nøyaktig enn før. Deres funn er beskrevet i » YOLOv4: Optimal Hastighet og Nøyaktighet Av Objektdeteksjon » papir de publiserte 23. April 2020.
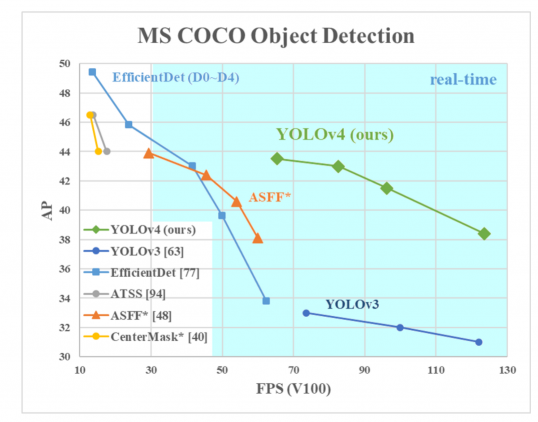
AP På Y-aksen er en metrisk kalt «gjennomsnittlig presisjon». Den beskriver nøyaktigheten av nettet.
FPS (bilder per sekund) På X-aksen er en beregning som beskriver hastighet.
Kilden til bildet.
To måneder etter utgivelsen av 4. versjon, annonserte En uavhengig utvikler, Glenn Jocher, DEN 5. versjonen AV YOLO. Denne gangen ble det ikke publisert noe forskningspapir. Nettet ble tilgjengelig På Jocher GitHub side som en pytorch implementering. Den femte versjonen hadde omtrent samme nøyaktighet som den fjerde versjonen, men det var raskere.
Til slutt, i juli 2020 fikk vi en annen stor YOLO-oppdatering. I et papir med tittelen «PP-YOLO: En Effektiv Og Effektiv Implementering Av Objektdetektor», Kom Xiang Long og team opp med en ny versjon AV YOLO. DENNE iterasjonen AV YOLO var basert på 3. modellversjon og overgikk YTELSEN TIL YOLO v4.

kartet På y-aksen er en metrisk kalt «gjennomsnittlig presisjon». Den beskriver nøyaktigheten av nettet.
FPS (bilder per sekund) På X-aksen er en beregning som beskriver hastighet.
Kilden til bildet.
I denne opplæringen skal vi se nærmere På YOLOv4 og dens implementering. Hvorfor YOLOv4? Tre grunner:
- den har bred godkjenning i maskinlæringssamfunnet;
- denne versjonen har bevist sin høye ytelse i et bredt spekter av deteksjonsoppgaver;
- YOLOv4 har blitt implementert i flere populære rammer, inkludert TensorFlow og Keras, som vi skal jobbe med.
Eksempler på yolo-applikasjoner
Før Vi går videre til den praktiske delen av denne artikkelen, implementerer vår tilpassede YOLO-baserte objektdetektor, vil jeg gjerne vise deg et par kule YOLOv4-implementeringer, og så skal vi gjøre implementeringen vår.
Vær oppmerksom på hvor raskt og nøyaktig spådommene er!
Her er det første imponerende eksempelet På Hva YOLOv4 kan gjøre, oppdage flere objekter fra forskjellige spill-og filmscener.
Alternativt kan du sjekke dette objektet deteksjon demo fra en real-life kameravisning.
YOLO som objektdetektor I TensorFlow & Keras
TensorFlow & Keras-rammer i Maskinlæring

Kilden til bildet.
Rammer er avgjørende i alle informasjonsteknologi domene. Maskinlæring er intet unntak. DET er flere etablerte aktører I ML-markedet som hjelper oss med å forenkle den generelle programmeringsopplevelsen. PyTorch, scikit-learn, TensorFlow, Keras, MXNet og Caffe er bare noen få verdt å nevne.
I Dag skal vi jobbe tett med TensorFlow / Keras. Ikke overraskende er disse to blant de mest populære rammene i maskinlæringsuniverset. Det skyldes i stor grad at Både TensorFlow og Keras gir rike muligheter for utvikling. Disse to rammene er ganske lik hverandre. Uten å grave for mye inn i detaljer, er det viktig å huske At Keras bare er en wrapper For TensorFlow-rammen.
yolo-implementering I TensorFlow & Keras
da denne artikkelen ble skrevet, var det 808 repositorier med yolo-implementeringer på En TensorFlow / Keras-backend. YOLO versjon 4 er det vi skal implementere. Begrense søket til BARE YOLO v4, jeg fikk 55 repositories.
omhyggelig å bla gjennom dem alle, fant Jeg en interessant kandidat å fortsette med.
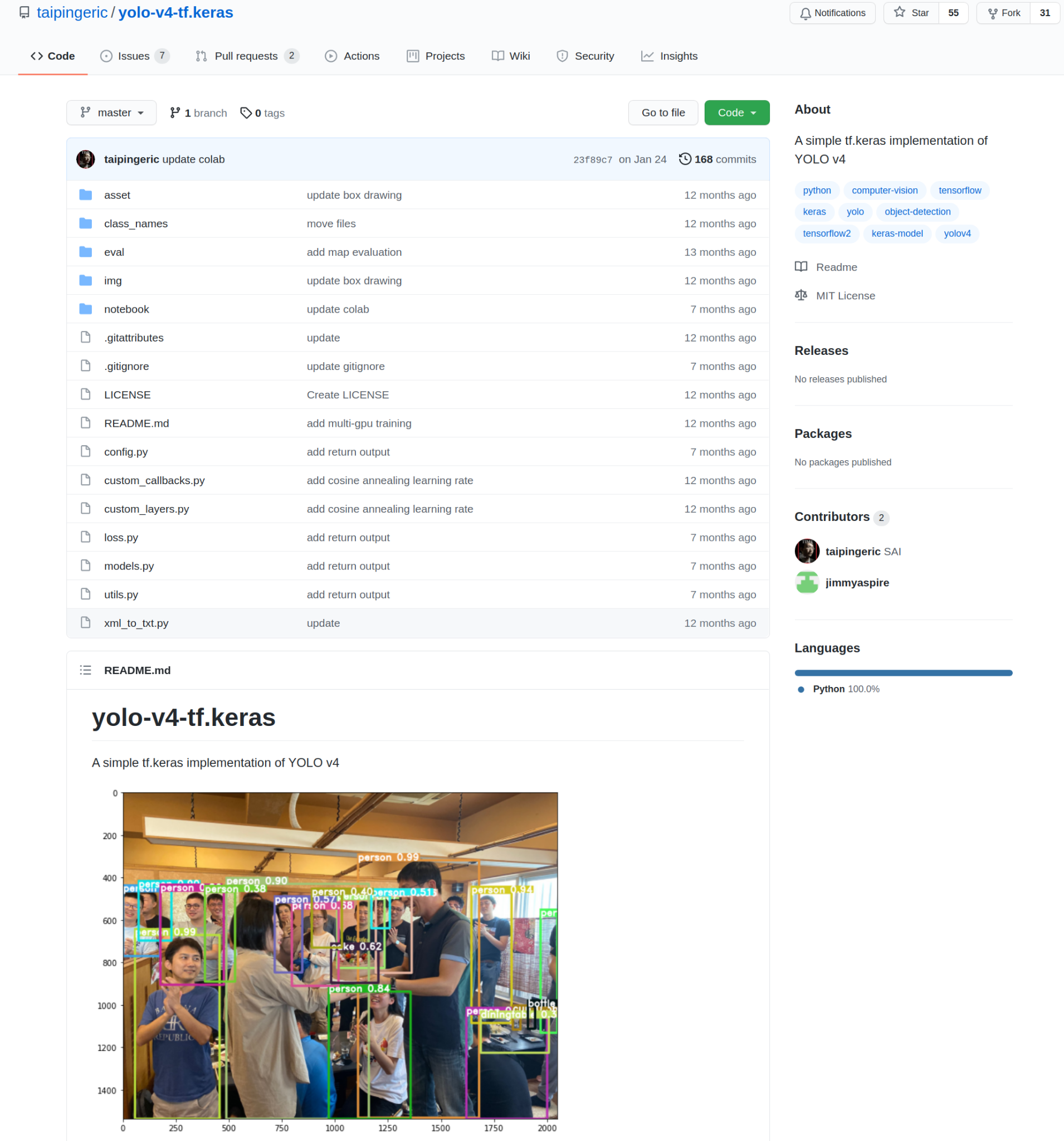
Kilden til bildet.
denne implementeringen ble utviklet av taipingeric og jimmyaspire. Det er ganske enkelt og veldig intuitivt hvis Du har jobbet med TensorFlow og Keras før.
for å begynne å jobbe med denne implementeringen, klone du bare repo til din lokale maskin. Deretter vil jeg vise deg hvordan du bruker YOLO ut av esken, og hvordan du trener din egen tilpassede objektdetektor.
hvordan kjøre pre-trent YOLO out-of-the-box og få resultater
Ser på» Quick Start » delen av repo, kan du se at for å få en modell oppe og går, vi må bare importere YOLO som en klasse objekt og last i modellen vekter:
from models import Yolov4model = Yolov4(weight_path='yolov4.weights', class_name_path='class_names/coco_classes.txt')
Merk at du må manuelt laste ned modellvekter på forhånd. Modellvektfilen som følger MED YOLO kommer fra COCO datasettet, og den er tilgjengelig På Alexeyabs offisielle darknet-prosjektside på GitHub. Du kan laste ned vektene direkte via denne linken.
Rett etter er modellen fullt klar til å jobbe med bilder i slutningsmodus. Bare bruk predict () – metoden for et bilde av ditt valg. Metoden er standard for Tensorflow og Keras rammeverk.
pred = model.predict('input.jpg')
For eksempel for dette inngangsbildet:

jeg fikk følgende modellutgang:

Forutsigelser som modellen laget returneres i en praktisk form av en pandas DataFrame. Vi får klassenavn, boksstørrelse og koordinater for hvert oppdaget objekt:

Masse nyttig informasjon om de oppdagede objektene
det er flere parametere i predict () – metoden som lar oss spesifisere om vi vil plotte bildet med de forutsagte grenseboksene, tekstnavn for hvert objekt, etc. Sjekk ut docstring som går sammen med predict () – metoden for å bli kjent med hva som er tilgjengelig for oss:

du bør forvente at modellen din bare vil kunne oppdage objekttyper som er strengt begrenset til COCO-datasettet. For å vite hvilke objekttyper en pre-trent YOLO-modell kan oppdage, sjekk ut coco_classes.txt-fil tilgjengelig i … / yolo-v4-tf.kers/class_names/. Det er 80 objekttyper der inne.
slik trener du den egendefinerte yolo-objektdeteksjonsmodellen
Task statement

hvis du vil utforme en objektdeteksjonsmodell, må du vite hvilke objekttyper du vil oppdage. Dette bør være et begrenset antall objekttyper som du vil lage din detektor for. Det er godt å ha en liste over objekttyper forberedt når vi beveger oss til den faktiske modellutviklingen.
Ideelt sett bør du Også ha et annotert datasett som har objekter av interesse. Dette datasettet vil bli brukt til å trene en detektor og validere den. Hvis du ennå ikke har et datasett eller merknad for det, ikke bekymre deg, jeg skal vise deg hvor og hvordan du kan få det.
Datasett & merknader
hvor får du data fra
hvis du har et annotert datasett å jobbe med, hopper du bare over denne delen og går videre til neste kapittel. Men hvis du trenger et datasett for prosjektet ditt, skal vi nå utforske elektroniske ressurser der du kan få data.
det spiller ingen rolle hvilket felt du jobber i, det er stor sjanse for at det allerede er et datasett med åpen kildekode som du kan bruke til prosjektet ditt.
den første ressursen jeg anbefaler er «50+ Object Detection Datasett fra ulike industri domener» artikkel Av Abhishek Annamraju som har samlet fantastiske kommenterte datasett for bransjer som Mote, Detaljhandel, Sport, Medisin og mange flere.

Kilden til bildet.
Andre to flotte steder å lete etter dataene er paperswithcode.com og roboflow.com som gir tilgang til datasett av høy kvalitet for objektdeteksjon.
Sjekk ut disse ressursene ovenfor for å samle inn dataene du trenger eller for å berike datasettet du allerede har.
hvordan annotere data FOR YOLO
hvis datasettet med bilder kommer uten merknader, må du selv gjøre annotasjonsjobben. Denne manuelle operasjonen er ganske tidkrevende, så sørg for at du har nok tid til å gjøre det.
som et annotasjonsverktøy kan du vurdere flere alternativer. Personlig vil jeg anbefale Å bruke LabelImg. Det er en lett og lett-å-bruke bilde merknad verktøy som kan direkte utgang merknader FOR YOLO modeller.
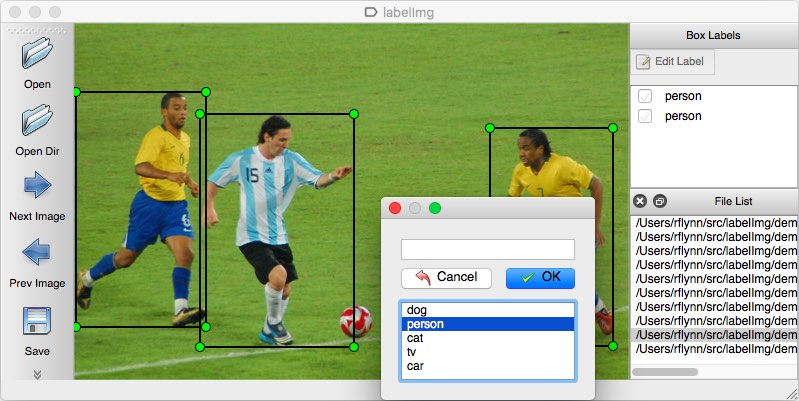
Kilden til bildet.
hvordan transformere data fra andre formater TIL YOLO
Merknader FOR YOLO er i form av txt-filer. Hver linje i en txt-fil fol YOLO må ha følgende format:
image1.jpg 10,15,345,284,0image2.jpg 100,94,613,814,0 31,420,220,540,1
Vi kan bryte opp hver linje fra txt-filen og se hva den består av:
- den første delen av en linje angir basenavnene for bildene: image1.jpg, image2.jpg
- den andre delen av en linje definerer koordinatene for markeringsrammen og klasseetiketten. For eksempel 10,15,345,284,0 stater for xmin, ymin, xmax, ymax, class_id
- Hvis et gitt bilde har mer enn ett objekt på det, vil det være flere bokser og klasse etiketter ved siden av bildet basename, delt med et mellomrom.
Markeringsbokskoordinater er et klart konsept, men hva med class_id-nummeret som angir klasseetiketten? Hver class_id er knyttet til en bestemt klasse i en annen txt-fil. For eksempel kommer pre-trent YOLO med coco_classes.txt-fil som ser slik ut:
personbicyclecarmotorbikeaeroplanebus...
Antall linjer i klassefilene må samsvare med antall klasser som detektoren din skal oppdage. Numeration starter fra null, noe som betyr at class_id-nummeret for første klasse i klassefilen skal være 0. Klassen som er plassert pa den andre linjen i klassene txt-filen vil ha nummer 1.
nå vet du hvordan annotasjonen FOR YOLO ser ut. For å fortsette å lage en tilpasset objektdetektor oppfordrer jeg deg til å gjøre to ting nå:
- lag en klasser txt fil hvor du vil palace av klassene som du vil at detektoren å oppdage. Husk at klasseordren er viktig.
- Lag en txt-fil med merknader. I tilfelle du allerede har merknad, men I VOC-format (.XMLs), kan du bruke denne filen til å transformere FRA XML TIL YOLO.
Splitting av data i undergrupper
som alltid vil vi dele datasettet i 2 undergrupper: for trening og for validering. Det kan gjøres så enkelt som:
from utils import read_annotation_lines train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1)
Opprette data generatorer
når dataene er delt, kan vi gå videre til data generator initialisering. Vi har en datagenerator for hver datafil. I vårt tilfelle har vi en generator for treningsdelen og for valideringsdelen.
slik opprettes datageneratorene:
from utils import DataGenerator FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
for å oppsummere alt, her er hva den komplette koden for data splitting og generator skapelse ser ut:
from utils import read_annotation_lines, DataGenerator train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1) FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
Installasjon & oppsett som kreves for modellopplæring
la oss snakke om forutsetningene som er avgjørende for å lage din egen objektdetektor:
- Du bør Ha Python allerede installert på datamaskinen. I tilfelle du trenger å installere det, anbefaler jeg å følge denne offisielle guiden Av Anaconda;
- hvis datamaskinen har EN CUDA-aktivert GPU( EN GPU laget AV NVIDIA), er det nødvendig med noen få relevante biblioteker for å støtte GPU-basert opplæring. Hvis DU trenger å aktivere GPU-støtte, sjekk retningslinjene på NVIDIAS nettsted. Målet ditt er å installere den nyeste versjonen AV BÅDE CUDA Toolkit, og cuDNN for operativsystemet;
- du vil kanskje organisere et uavhengig virtuelt miljø å jobbe i. Dette prosjektet krever tensorflow 2 installert. Alle andre biblioteker vil bli introdusert senere;
- Som for meg, jeg var å bygge og trene Min YOLOv4 modell i En Jupyter Bærbare utviklingsmiljø. Selv Om Jupyter Notebook virker som et rimelig alternativ å gå med, bør du vurdere utvikling i EN IDE etter eget valg hvis du ønsker det.
Modell trening

Forutsetninger
Nå bør du ha:
- en splitt for datasettet ditt;
- to data generatorer initialisert;
- En txt-fil med klassene.
Initialisering av modellobjekt
hvis Du vil gjøre deg klar for en opplæringsjobb, initialiserer Du YOLOv4 – modellobjektet. Kontroller At Du bruker Ingen som en verdi for parameteren weight_path. Du bør også gi en bane til klassene dine txt-fil på dette trinnet. Her er initialiseringskoden jeg brukte i prosjektet mitt:
class_name_path = 'path2project_folder/model_data/scans_file.txt' model = Yolov4(weight_path=None, class_name_path=class_name_path)
ovennevnte modellinitialisering fører til opprettelse av et modellobjekt med et standard sett med parametere. Vurder å endre konfigurasjonen av modellen din ved å sende i en ordbok som en verdi til config – modellparameteren.

Config angir et sett med parametere For yolov4-modellen.
Standardmodellkonfigurasjon er et godt utgangspunkt, men du vil kanskje eksperimentere med andre configs for bedre modellkvalitet.
spesielt anbefaler jeg å eksperimentere med ankre og img_size. Ankere angir geometrien til ankrene som skal brukes til å fange objekter. Jo bedre formen på ankrene passer til objektformene, desto høyere blir modellytelsen.
Økende img_size kan også være nyttig i noen tilfeller. Husk at jo høyere bildet er, desto lengre vil modellen gjøre slutningen.
hvis Du vil bruke Neptun som sporingsverktøy, bør du også initialisere et eksperimentløp, slik:
import neptune.new as neptune run = neptune.init(project='projects/my_project', api_token=my_token)
Definere tilbakeringinger
TensorFlow & Keras lar oss bruke tilbakeringinger til å overvåke treningsfremdriften, gjøre sjekkpunkter og administrere treningsparametere (f.eks. læringsfrekvens).
før du monterer modellen, definer tilbakeringinger som vil være nyttige for dine formål. Pass på å angi baner for å lagre modellkontrollpunkter og tilknyttede logger. Slik gjorde jeg det i et av mine prosjekter:
# defining pathes and callbacks dir4saving = 'path2checkpoint/checkpoints'os.makedirs(dir4saving, exist_ok = True) logdir = 'path4logdir/logs'os.makedirs(logdir, exist_ok = True) name4saving = 'epoch_{epoch:02d}-val_loss-{val_loss:.4f}.hdf5' filepath = os.path.join(dir4saving, name4saving) rLrCallBack = keras.callbacks.ReduceLROnPlateau(monitor = 'val_loss', factor = 0.1, patience = 5, verbose = 1) tbCallBack = keras.callbacks.TensorBoard(log_dir = logdir, histogram_freq = 0, write_graph = False, write_images = False) mcCallBack_loss = keras.callbacks.ModelCheckpoint(filepath, monitor = 'val_loss', verbose = 1, save_best_only = True, save_weights_only = False, mode = 'auto', period = 1)esCallBack = keras.callbacks.EarlyStopping(monitor = 'val_loss', mode = 'min', verbose = 1, patience = 10)
du kunne ha lagt merke til at i de ovennevnte tilbakeringinger satt TensorBoard brukes som et sporingsverktøy. Vurder Å bruke Neptun som et mye mer avansert verktøy for eksperimentsporing. I så fall, ikke glem å initialisere en annen tilbakeringing for å muliggjøre integrasjon Med Neptune:
from neptune.new.integrations.tensorflow_keras import NeptuneCallback neptune_cbk = NeptuneCallback(run=run, base_namespace='metrics')
Tilpass modellen
for å starte treningsjobben, må du bare tilpasse modellobjektet ved hjelp av standard fit () – metoden I TensorFlow / Keras. Slik begynte jeg å trene min modell:
model.fit(data_gen_train, initial_epoch=0, epochs=10000, val_data_gen=data_gen_val, callbacks= )
Når treningen er startet, vil du se en standard fremdriftslinje.

opplæringsprosessen vil evaluere modellen på slutten av hver epoke. Hvis du bruker et sett med tilbakeringinger som ligner på det jeg initialiserte og passerte under montering, vil de kontrollpunktene som viser modellforbedring i form av lavere tap, bli lagret i en spesifisert katalog.
hvis det ikke oppstår feil og treningsprosessen går greit, stoppes treningsjobben enten på grunn av slutten av treningsperiodens nummer, eller hvis den tidlige stoppende tilbakekallingen ikke oppdager ytterligere modellforbedring og stopper den totale prosessen.
i alle fall bør du ende opp med flere modellkontrollpunkter. Vi ønsker å velge den beste fra alle tilgjengelige og bruke den til slutning.
Trent tilpasset modell i slutningsmodus
Å Kjøre en utdannet modell i slutningsmodus ligner på å kjøre en forhåndslært modell ut av esken.

du initialiserer et modellobjekt som passerer i banen til det beste kontrollpunktet, samt banen til txt-filen med klassene. Her er hva modell initialisering ser ut for mitt prosjekt:
from models import Yolov4model = Yolov4(weight_path='path2checkpoint/checkpoints/epoch_48-val_loss-0.061.hdf5', class_name_path='path2classes_file/my_yolo_classes.txt')
når modellen er initialisert, bruk bare predict () – metoden for et bilde av ditt valg for å få spådommene. Som en oppsummering, er deteksjoner som modellen laget returnert i en praktisk form av en pandas DataFrame. Vi får klassenavn, boksstørrelse og koordinater for hvert oppdaget objekt.
Konklusjoner
du har nettopp lært hvordan du lager en tilpasset YOLOv4 objektdetektor. Vi har gått over ende-til-ende-prosessen, fra datainnsamling, merknad og transformasjon. Du har nok kunnskap om den fjerde yolo-versjonen og hvordan den skiller seg fra andre detektorer.
Ingenting stopper deg nå fra å trene din egen modell I TensorFlow og Keras. Du vet hvor du skal få en pre-trent modell fra og hvordan å sparke av trening jobben.
I min kommende artikkel vil jeg vise deg noen av de beste praksisene og livshackene som vil bidra til å forbedre kvaliteten på den endelige modellen. Bli hos oss!



Anton Morgunov
Datamaskin Visjon Ingeniør På Basis.Senter
Maskinlæringsentusiast. Lidenskapelig om datasyn. Ingen papir-flere trær! Arbeide mot papirkopi eliminering ved å flytte til full digitalisering!
LES NESTE
Tensorflow Object Detection API: Beste Praksis for Opplæring, Evaluering & Distribusjon
13 minutter lest / Forfatter Anton Morgunov / Oppdatert 28. Mai 2021
denne artikkelen er den andre delen av en serie der du lærer en ende-til-ende-arbeidsflyt for Tensorflow-Objektdeteksjon og DENS API. I den første artikkelen lærte du hvordan du lager en tilpasset objektdetektor fra bunnen av, men det er fortsatt mange ting som trenger din oppmerksomhet for å bli virkelig dyktig.
vi vil utforske emner som er like viktige som modellprosessen vi allerede har gått gjennom. Her er noen av spørsmålene vi vil svare på:
- hvordan evaluere modellen min og få et estimat av ytelsen?
- hvilke verktøy kan jeg bruke til å spore modellytelse og sammenligne resultater på tvers av flere eksperimenter?
- hvordan kan jeg eksportere modellen min for å bruke den i slutningsmodus?
- er det en måte å øke modellytelsen enda mer?
Fortsett å lese ->