Gjennomsøkingsbudsjett er antall sider søkemotorer vil gjennomgå på et nettsted innen en viss tidsramme.
Søkemotorer beregner kravlesøk budsjett basert på kravlesøk grense (hvor ofte de kan kravlesøke uten å forårsake problemer) og kravlesøk etterspørsel (hvor ofte de ønsker å gjennomgå et område).
hvis du kaster bort gjennomsøkingsbudsjett, vil søkemotorer ikke kunne gjennomsøke nettstedet ditt effektivt, noe som vil ende opp med Å skade SEO-ytelsen din.
- Hva er gjennomsøkingsbudsjett?
- hvorfor tilordner søkemotorer gjennomsøkingsbudsjett til nettsteder?
- hvordan tilordner de gjennomsøkingsbudsjett til nettsteder?
- er gjennomsøkingsbudsjettet bare om sider?
- hvordan fungerer crawl limit / host load i praksis?
- Hvordan fungerer crawl demand / crawl scheduling i praksis?
- ikke glem: crawl kapasitet av selve systemet
- Hvorfor bør du bryr deg om crawl budsjett?
- Hva er gjennomsøkingsbudsjettet for nettstedet mitt?
- Gjennomsøkingsbudsjett I Google Search Console
- Gå til kilden: serverlogger
- Hvordan optimaliserer du crawl-budsjettet ditt?
- Tilgjengelige Nettadresser med parametere
- Duplikatinnhold
- Innhold av Lav kvalitet
- Ødelagte og omdirigere koblinger
- Uriktige Nettadresser i XML-områdekart
- ContentKing
- Sider med høy belastningstider / tidsavbrudd
- Høyt antall ikke-indekserbare sider
- Dårlig intern lenkestruktur
- Hvordan øker du nettstedets gjennomsøkingsbudsjett?
- Ofte stilte spørsmål om gjennomsøkingsbudsjett
- 1. 🧾 Hva er gjennomsøkingsbudsjett?
- 2. 🤔 Hvordan øker jeg gjennomsøkingsbudsjettet mitt?
- 3. 🤷 Hva kan begrense gjennomsøkingsbudsjettet mitt?
- 4. 🤖 Skal jeg i det hele tatt bruke canonical URL og meta robots?
Hva er gjennomsøkingsbudsjett?
Gjennomsøkingsbudsjett Er antall sider søkemotorer vil gjennomsøke på et nettsted innen en viss tidsramme.
hvorfor tilordner søkemotorer gjennomsøkingsbudsjett til nettsteder?
Fordi de ikke har ubegrensede ressurser, og de deler oppmerksomheten på millioner av nettsteder. Så de trenger en måte å prioritere deres kravlesøk. Tilordne gjennomsøkingsbudsjett til hvert nettsted hjelper dem med å gjøre dette.
hvordan tilordner de gjennomsøkingsbudsjett til nettsteder?
det er basert på to faktorer, kravlesøk og kravlesøk:
- Crawl limit / host load: hvor mye crawling kan et nettsted håndtere, og hva er eierens preferanser?
- Krav om Kravlesøk / kravlesøkplanlegging: Hvilke Nettadresser er mest verdt å gjennomgå på nytt, basert på populariteten og hvor ofte den oppdateres.
Gjennomsøkingsbudsjett er et vanlig begrep INNEN SEO. Kravlesøk budsjett er noen ganger også referert til som kravlesøk plass eller kravlesøk tid.

er gjennomsøkingsbudsjettet bare om sider?
det er egentlig ikke, for enkelhets skyld snakker vi om sider, men i virkeligheten handler det om noe dokument som søkemotorer kryper. Noen eksempler på andre dokumenter: JavaScript-og CSS-filer, mobilsidevarianter, hreflang – varianter og PDF-filer.
hvordan fungerer crawl limit / host load i praksis?
Kravlesøkgrense, eller vertsbelastning hvis du vil, er en viktig del av kravlesøkbudsjettet. Søkemotorer robotsøkeprogrammer er utformet for å hindre overbelastning av en webserver med forespørsler slik at de er forsiktig med dette.Hvordan søkemotorer bestemme crawl grensen for et nettsted? Det er en rekke faktorer som påvirker crawl grensen. For å nevne noen:
- tegn på plattform i dårlig form: hvor ofte forespurte Nettadresser timeout eller retur server feil.
- mengden nettsteder som kjører på verten: hvis nettstedet ditt kjører på en delt hostingplattform med hundrevis av andre nettsteder, og du har et ganske stort nettsted, er gjennomsøkingsgrensen for nettstedet ditt svært begrenset ettersom gjennomsøkingsgrensen bestemmes på vertsnivå. Du må dele vertens crawl grense med alle de andre nettstedene som kjører på den. I dette tilfellet vil du være langt bedre på en dedikert server,som mest sannsynlig også vil redusere belastningstidene for de besøkende.
En annen ting å vurdere er å ha separate mobile og stasjonære nettsteder som kjører på samme vert. De har også en delt crawl grense. Så hold dette i bakhodet.
gjennomsøker søkemotorer de viktigste delene av nettstedet ditt? Kjør en rask test Med ContentKing!
Hvordan fungerer crawl demand / crawl scheduling i praksis?
Kravlesøk, eller kravlesøkplanlegging, handler om å bestemme verdien av nettadresser for kravlesøk på nytt. Igjen påvirker mange faktorer kravlesøk blant annet:
- Popularitet: hvor mange inngående interne og inngående eksterne lenker EN URL har, men også mengden spørringer den rangerer for.
- Friskhet: hvor ofte NETTADRESSEN oppdateres.
- Type side: er typen side som sannsynligvis vil endres. Ta for eksempel en produktkategoriside , og en vilkår – side-hvilken tror du endres oftest og fortjener å bli gjennomsøkt oftere?

Å Tvinge googles crawlere til å komme tilbake til nettstedet ditt når det ikke er noe viktigere å finne (dvs. meningsfull endring), er ikke en god strategi, og de er ganske smarte på å finne ut om frekvensen av disse sidene endrer seg, faktisk gir verdi. Det beste rådet jeg kan gi er å konsentrere seg om å gjøre sidene viktigere (legge til mer nyttig informasjon, gjøre sidene innhold rik (de vil naturlig utløse flere spørringer som standard så lenge fokuset på et emne opprettholdes). Ved å naturlig utløse flere spørringer som en del av ‘ tilbakekalling ‘(visninger) gjør du sidene dine viktigere og se og se: du vil sannsynligvis bli gjennomsøkt hyppigere.
ikke glem: crawl kapasitet av selve systemet
mens søkemotor gjennomgang systemer har massiv crawl kapasitet, på slutten av dagen er det begrenset. Så i et scenario der 80% Av Googles datasentre går offline samtidig, reduseres gjennomsøkingskapasiteten massivt og i sin tur alle nettsteders gjennomsøkingsbudsjett.
Massiv takk Til Dawn Anderson (åpnes i en ny fane) for å gi oss detaljer om crawl limit, crawl demand og crawl capacity!
Hvorfor bør du bryr deg om crawl budsjett?
du vil at søkemotorer skal finne og forstå så mange som mulig av dine indekserbare sider, og du vil at de skal gjøre det så raskt som mulig. Når du legger til nye sider og oppdatere eksisterende, vil søkemotorer å plukke disse opp så snart som mulig. Jo før de har indeksert sidene, jo raskere kan du dra nytte av dem.
hvis du kaster bort gjennomsøkingsbudsjett, vil søkemotorer ikke kunne gjennomsøke nettstedet ditt effektivt. De vil bruke tid på deler av nettstedet ditt som ikke betyr noe, noe som kan føre til at viktige deler av nettstedet ditt blir uoppdaget. Hvis de ikke vet om sider, vil de ikke gjennomgå og indeksere dem, og du vil ikke kunne bringe besøkende inn gjennom søkemotorer til dem.
Du kan se hvor dette fører til: å kaste bort gjennomsøkingsbudsjett gjør VONDT FOR SEO-ytelsen din.
vær oppmerksom på at gjennomsøkingsbudsjettet vanligvis bare er noe å bekymre deg for hvis du har et stort nettsted, la oss si 10 000 sider og oppover.

En av de mer undervurderte aspektene av gjennomsøkingsbudsjettet er lasthastighet. En raskere lasting nettsted betyr At Google kan gjennomgå Flere Nettadresser på samme tid. Nylig var jeg involvert med en oppgradering av nettstedet der lasthastigheten var et stort fokus. Det nye nettstedet lastet dobbelt så fort som det gamle. Når Det ble presset live, gikk Antall Nettadresser Google gjennomsøkt per dag opp fra 150.000 til 600.000 – og ble der. For et nettsted av denne størrelsen og omfanget betyr den forbedrede gjennomsøkingsfrekvensen at nytt og endret innhold gjennomsøkes mye raskere, og vi ser en mye raskere innvirkning av VÅR SEO-innsats i SERPs.

EN veldig klok SEO (ok, DET VAR AJ Kohn (åpnes i en ny fane)) en gang berømt sa » Du er Hva Googlebot spiser .». Rangeringer og søkesynlighet er direkte relatert til Ikke Bare Hva Google gjennomsøker på nettstedet ditt, men ofte, hvor ofte de gjennomsøker det. Hvis Google savner innhold på nettstedet ditt, eller ikke gjennomsøker viktige Nettadresser ofte nok på grunn av begrenset/uoptimisert gjennomsøkingsbudsjett, vil du ha en veldig vanskelig tid å rangere faktisk. For større områder kan optimalisering av gjennomsøkingsbudsjett øke profilen til tidligere usynlige sider. Mens mindre nettsted trenger å bekymre seg mindre om gjennomsøkingsbudsjett, de samme prinsippene for optimalisering (hastighet, prioritering, lenkestruktur, de-duplisering, etc.) kan fortsatt hjelpe deg med å rangere.

Jeg er mest enig Med Google, og for det meste trenger mange nettsteder ikke å bekymre seg for gjennomsøkingsbudsjett. Men for nettsteder som er store i størrelse og spesielt de som oppdateres ofte, for eksempel utgivere, kan optimalisering gjøre en betydelig forskjell.
Hva er gjennomsøkingsbudsjettet for nettstedet mitt?
Av alle søkemotorene Er Google den mest gjennomsiktige om deres gjennomsøkingsbudsjett for nettstedet ditt.
Gjennomsøkingsbudsjett I Google Search Console
hvis du har bekreftet nettstedet ditt I Google Search Console, kan Du få et innblikk i nettstedets gjennomsøkingsbudsjett For Google.
Følg disse trinnene:
- Logg På Google Search Console og velg et nettsted.
- Gå til
Crawl>Crawl Stats. Der kan Du se antall sider Som Google gjennomsøker per dag.
sommeren 2016 så gjennomsøkingsbudsjettet slik ut:
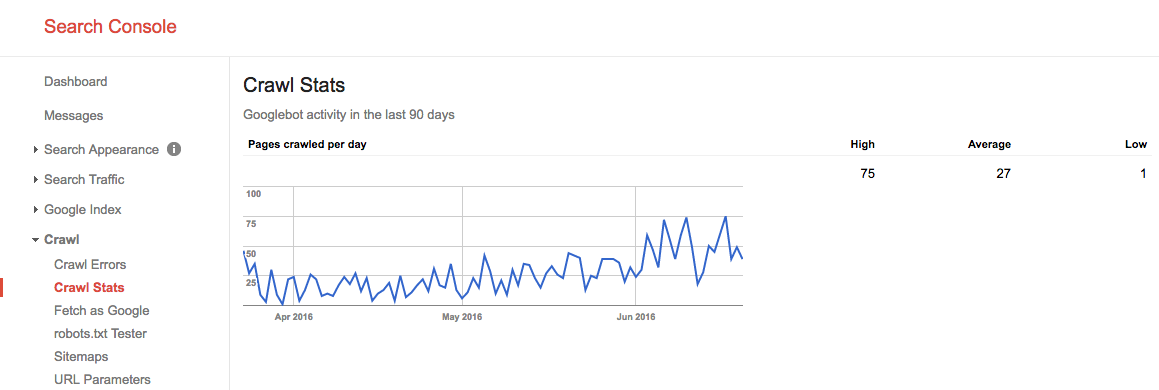
vi ser her at gjennomsnittlig gjennomsøkingsbudsjett er 27 sider / dag. Så i teorien, hvis dette gjennomsnittlige gjennomsøkingsbudsjettet forblir det samme, vil du ha et månedlig gjennomsøkingsbudsjett på 27 sider x 30 dager = 810 sider.
Spol frem 2 år, og se på hva vårt crawl-budsjett er akkurat nå:
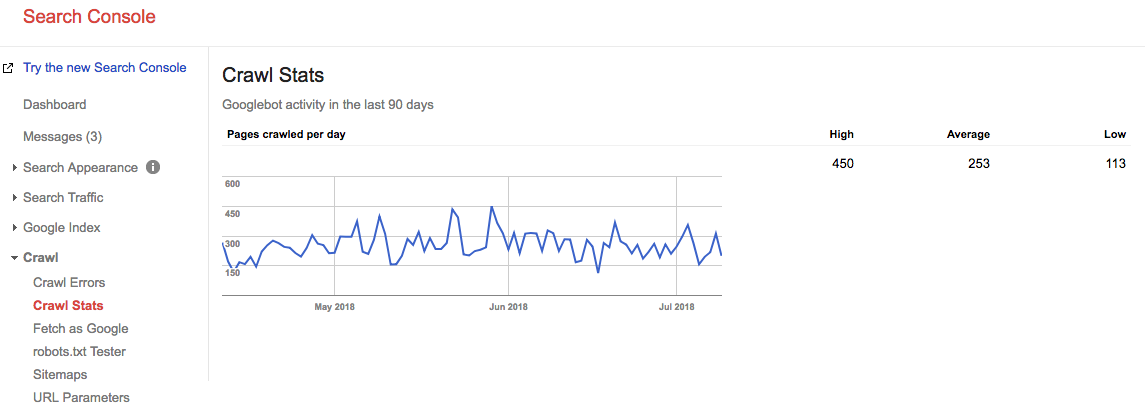
Vårt gjennomsnittlige gjennomsnittlige gjennomsøkingsbudsjett er 253 sider / dag, så du kan si at gjennomsøkingsbudsjettet gikk OPP 10X om 2 år.
Gå til kilden: serverlogger
det er veldig interessant å sjekke serverloggene dine for å se hvor ofte googles crawlere treffer nettstedet ditt. Det er interessant å sammenligne disse statistikkene med de som rapporteres I Google Search Console. Det er alltid bedre å stole på flere kilder.
Ikke la kravlesøk problemer være en tapt mulighet. Kontinuerlig overvåke nettstedet Ditt Med ContentKing og bli varslet om problemer i sanntid.
Hvordan optimaliserer du crawl-budsjettet ditt?
Optimalisering av gjennomsøkingsbudsjettet kommer ned til å sørge for at ingen gjennomsøkingsbudsjett er bortkastet. I hovedsak, fikse årsakene til bortkastet crawl budsjett. Vi overvåker tusenvis av nettsteder; hvis du skulle sjekke hver enkelt av dem for gjennomsøkingsbudsjettproblemer, vil du raskt se et mønster: de fleste nettsteder lider av samme type problemer.
Vanlige årsaker til bortkastet kravlesøk budsjett som vi møter:
- Tilgjengelige Nettadresser med parametere: et EKSEMPEL på EN NETTADRESSE med en parameter er
https://www.example.com/toys/cars?color=black. I dette tilfellet brukes parameteren til å lagre en besøkendes valg i et produktfilter. - Duplikatinnhold: vi kaller sider som er svært like, eller nøyaktig det samme, » duplikatinnhold.»Eksempler er: kopierte sider, interne søkeresultatsider og taggsider.
- Innhold Av Lav kvalitet: sider med svært lite innhold, eller sider som ikke gir noen verdi.
- Brutte og omdirigerende lenker: brutte koblinger er lenker som refererer til sider som ikke eksisterer lenger, og omdirigerte koblinger er koblinger Til Nettadresser som omdirigerer til andre Nettadresser.
- Inkludert uriktige Nettadresser i XML sitemaps: ikke-indekserbare sider og ikke-sider som 3xx, 4xx og 5xx Nettadresser bør ikke inkluderes I XML sitemap.
- Sider med høy belastningstid / tidsavbrudd: sider som tar lang tid å laste inn, eller ikke lastes i det hele tatt, har en negativ innvirkning på gjennomsøkingsbudsjettet ditt, fordi det er et tegn på søkemotorer at nettstedet ditt ikke kan håndtere forespørselen, og dermed kan de justere gjennomsøkingsgrensen.
- Høyt antall ikke-indekserbare sider: nettstedet inneholder mange sider som ikke er indekserbare.
- Dårlig intern lenkestruktur: hvis den interne lenkestrukturen ikke er riktig konfigurert, kan det hende at søkemotorer ikke betaler nok oppmerksomhet til noen av sidene dine.

Jeg har ofte sagt At Google er som sjefen din. Du ville ikke gå inn i et møte med sjefen din med mindre du visste hva du skulle snakke om, høydepunktene i arbeidet ditt, målene for møtet ditt. Kort sagt, du har en agenda. Nar Du gar inn I Googles «kontor», trenger Du det samme. Et klart nettstedhierarki uten mye cruft, et nyttig XML-sitemap og raske responstider skal alle Hjelpe Google med Å komme til det som er viktig. Ikke overse dette ofte misforstått element AV SEO.

for meg er begrepet gjennomsøkingsbudsjett et av hovedpunktene i teknisk SEO. Når du optimaliserer for gjennomsøkingsbudsjett, faller alt annet på plass: intern kobling, feilretting, sidehastighet, URL-optimalisering, innhold av lav kvalitet og mer. Folk bør grave i loggfilene oftere for å overvåke gjennomsøkingsbudsjettet for bestemte Nettadresser,underdomener, katalog osv. Overvåking crawl frekvens er svært knyttet til crawl budsjett og super kraftig.
Tilgjengelige Nettadresser med parametere
I de fleste tilfeller Bør Nettadresser med parametere ikke være tilgjengelige for søkemotorer, fordi De kan generere en nesten uendelig mengde Nettadresser.Vi har skrevet mye om denne typen problem i vår artikkel om crawler traps.
Nettadresser med parametere brukes ofte når du implementerer produktfiltre på e-handelsnettsteder. Det er greit å bruke dem,; bare sørg for at de ikke er tilgjengelige for søkemotorer.
Hvordan kan du gjøre dem utilgjengelige for søkemotoren?
- Bruk robotene dine.txt-fil for å instruere søkemotorer ikke å få tilgang Til Slike Nettadresser. Hvis dette ikke er et alternativ av en eller annen grunn, kan Du bruke INNSTILLINGENE for url-parameterhåndtering I Google Search Console og Bing-Verktøy For Nettredaktører til å instruere Google og Bing om hvilke sider Som ikke skal gjennomsøkes.
- Legg til attributtverdien nofollow i koblinger på filterkoblinger. Vær oppmerksom På At Fra Mars 2020 Kan Google velge å ignorere nofollow. Derfor er trinn 1 enda viktigere.
Duplikatinnhold
du vil ikke at søkemotoren skal bruke tiden sin på dupliserte innholdssider,så det er viktig å forhindre, eller i det minste minimere, duplikatinnholdet på nettstedet ditt.
Hvordan gjør du dette? Av…
- Sette opp nettsted omdirigeringer for alle domenevarianter (
HTTP,HTTPS,non-WWW, ogWWW). - gjør interne søkeresultatsider utilgjengelige for søkemotorer ved hjelp av roboter.txt. Her er et eksempel roboter.txt for Et WordPress-nettsted.
- Deaktivering av dedikerte sider for bilder(for eksempel: de beryktede bildevedleggingssidene I WordPress).
- Være forsiktig rundt din bruk av taksonomier som kategorier og koder.
Sjekk ut noen flere tekniske grunner for duplikatinnhold og hvordan du løser dem.
Innhold av Lav kvalitet
Sider med svært lite innhold er ikke interessante for søkemotorer. Hold dem til et minimum, eller unngå dem helt hvis det er mulig. Et eksempel på innhold av lav kvalitet er EN FAQ-seksjon med lenker for å vise spørsmålene og svarene, hvor hvert spørsmål og svar serveres over en egen URL.
Ødelagte og omdirigere koblinger
Ødelagte koblinger og lange kjeder av omdirigeringer er blindveier for søkemotorer. I likhet med nettlesere, Synes Google å følge maksimalt fem kjedede omdirigeringer i en gjennomsøking (De kan fortsette å gjennomsøke det senere). Det er uklart hvor godt andre søkemotorer håndtere påfølgende viderekoblinger, men vi anbefaler på det sterkeste at du unngår lenket viderekoblinger helt og holde bruken av viderekoblinger til et minimum.
det er klart at ved å fikse ødelagte koblinger og omdirigere koblinger, kan du raskt gjenopprette bortkastet gjennomsøkingsbudsjett. I tillegg til å gjenopprette gjennomsøkingsbudsjettet, forbedrer du også en besøkendes brukeropplevelse betydelig. Omdirigeringer, og kjeder av omdirigeringer i særdeleshet, føre til lengre siden lastetid og dermed skade brukeropplevelsen.
For å gjøre det enkelt å finne ødelagte og omdirigere koblinger, har Vi dedikert spesielle Problemer til Dette innen ContentKing.
Gå til Issues > Links for å finne ut om du kaster bort gjennomsøkingsbudsjetter på grunn av feilkoblinger. Oppdater hver kobling slik at den kobler til en indekserbar side, eller fjern koblingen hvis den ikke lenger er nødvendig.
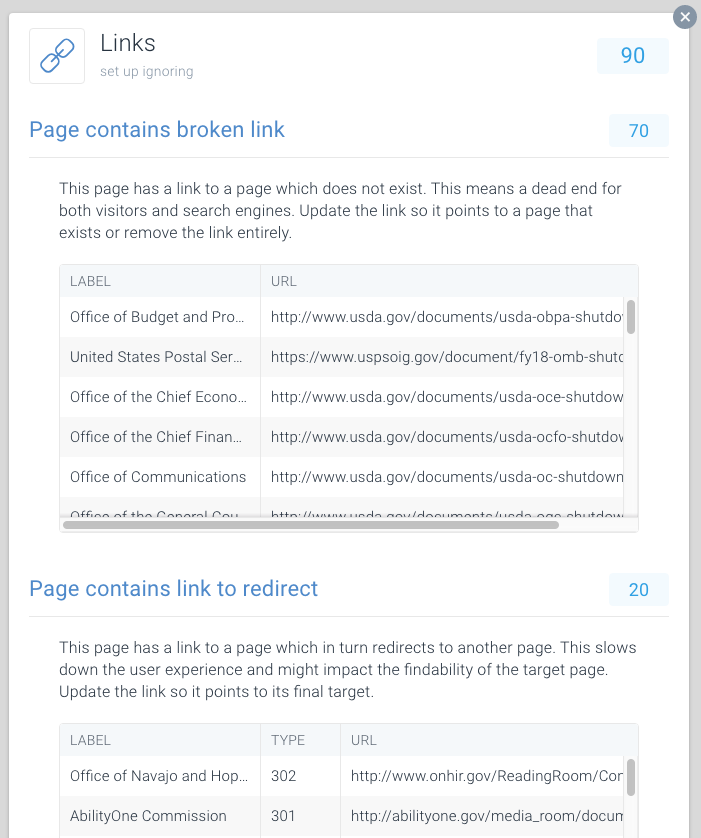
Uriktige Nettadresser i XML-områdekart
Alle Nettadresser som er inkludert I XML-områdekartene, skal være for indekserbare sider. Spesielt med store nettsteder, søkemotorer tungt stole PÅ XML sitemaps å finne alle sidene. HVIS XML sitemaps er rotete med sider som, for eksempel, ikke eksisterer lenger eller omdirigerer, du kaster bort gjennomsøkingsbudsjett. Sjekk XML sitemap regelmessig for ikke-indekserbare Nettadresser som ikke hører hjemme der. Se etter det motsatte også: se etter sider som er feilaktig ekskludert FRA XML sitemap. XML sitemap er en fin måte å hjelpe søkemotorer bruke gjennomgå budsjett klokt.
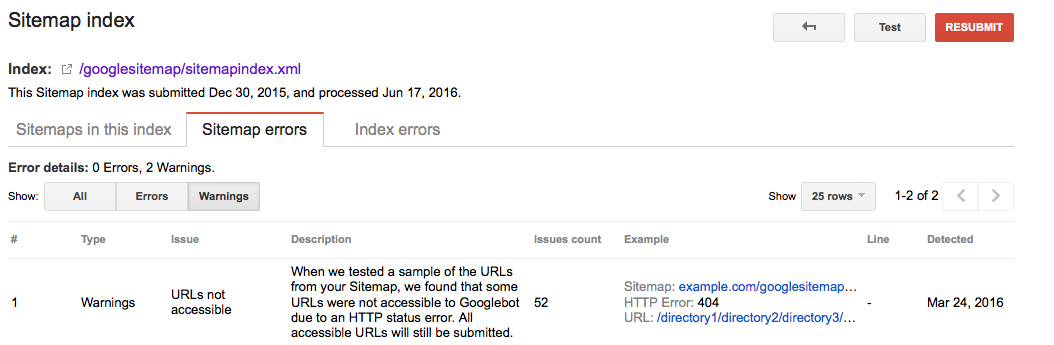
Google Searche Console
- Logg På Google Search Console
- Klikk på
Crawl– fanen - Klikk på
Sitemaps– fanen
Bing Webmaster Tools
- Logg På Bing Webmaster tools-kontoen
- Klikk på
Configure My Site– fanen - Klikk på
Sitemaps– fanen
ContentKing
- Logg På ContentKing-kontoen din
- Klikk på
Issues– knappen - Klikk på
XML Sitemap– knappen - ved problemer med siden din vil du motta denne meldingen:
Page is incorrectly included in XML sitemap
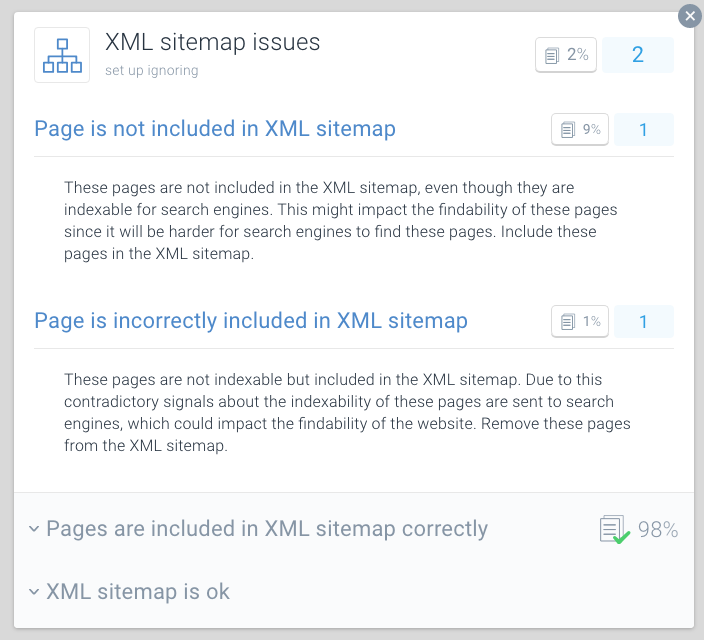
en beste praksis for gjennomsøkingsbudsjettoptimalisering er å dele XML sitemaps opp i mindre sitemaps. DU kan for eksempel opprette XML sitemaps for hver av nettstedets seksjoner. Hvis du har gjort dette, kan du raskt finne ut om det er noen problemer som skjer i visse deler av nettstedet ditt.
Si XML sitemap for seksjon a inneholder 500 koblinger, og 480 er indeksert: da gjør du det ganske bra. MEN HVIS XML sitemap for seksjon B inneholder 500 koblinger og bare 120 er indeksert, er det noe å se på. Du har kanskje tatt med mange Ikke-indekserbare Nettadresser I XML-sitemap for seksjon B.
Dårlige forhold for crawlere kan skade SEO. Bruk ContentKing til å kjøre en rask revisjon av nettstedet ditt.
Sider med høy belastningstider / tidsavbrudd

når sider har høy innlastingstid eller tidsavbrudd, kan søkemotorer besøke færre sider innenfor det tildelte gjennomsøkingsbudsjettet for nettstedet ditt. I tillegg til at ulempen, høy side lastetider og tidsavbrudd betydelig skade den besøkendes brukeropplevelse, noe som resulterer i en lavere konverteringsfrekvens.
sidelastetider over to sekunder er et problem. Ideelt sett vil siden din lastes på under ett sekund. Kontroller regelmessig sidens lastetider med verktøy som Pingdom (åpnes i en ny fane), WebPagetest (åpnes i en ny fane) eller GTmetrix (åpnes i en ny fane).
Google rapporterer om sidelastetid i Både Google Analytics (under Behavior > Site Speed) og Google Search Console under Crawl > Crawl Stats.
Google Search Console og Bing Webmaster Tools rapporterer begge om tidsavbrudd for sider. I Google Search Console finner du dette under Crawl > Crawl Errors, Og I Bing Webmaster Tools er det under Reports & Data > Crawl Information.
Sjekk regelmessig for å se om sidene dine lastes raskt nok, og ta tiltak umiddelbart hvis de ikke er Det. Hurtiglastende sider er avgjørende for din online suksess.
Høyt antall ikke-indekserbare sider
hvis nettstedet ditt inneholder et høyt antall ikke-indekserbare sider som er tilgjengelige for søkemotorer, holder du i utgangspunktet søkemotorer opptatt med å bla gjennom irrelevante sider.
vi anser følgende typer å være ikke-indekserbare sider:
- Omdirigeringer (3xx)
- Sider som ikke finnes (4xx)
- Sider med serverfeil (5xx)
- Sider som ikke kan indekseres (sider som inneholder robots noindex-direktivet eller KANONISK URL)
for å finne ut om du har et høyt antall ikke-indekserbare sider, se opp totalt antall sider som crawlere har funnet på nettstedet ditt og hvordan de bryter ned. Du kan enkelt gjøre dette ved Hjelp ContentKing:
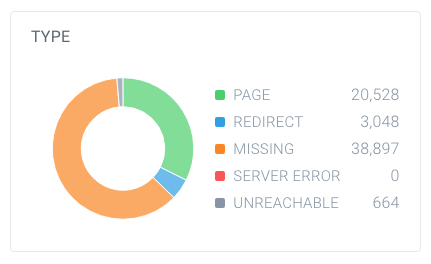
i dette eksemplet er det funnet 63 137 Nettadresser, hvorav bare 20 528 er sider.
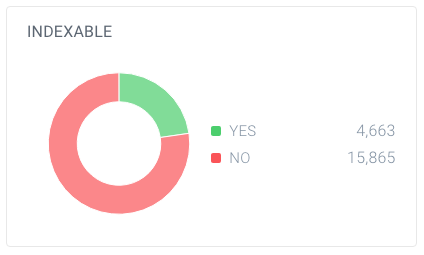
og ut av disse sidene er bare 4 663 indekserbare for søkemotorer. Bare 7,4% Av Nettadressene Funnet Av ContentKing kan indekseres av søkemotorer. Det er ikke et godt forhold, og dette nettstedet må definitivt jobbe med det ved å rydde opp alle referanser til dem som er unødvendige, inkludert:
- XML sitemap (se forrige avsnitt)
- Lenker
- Kanoniske Urler
- hreflang referanser
- Paginering referanser (link rel forrige / neste)
Dårlig intern lenkestruktur
hvordan sider på nettstedet ditt kobler til hverandre spiller en stor rolle i optimalisering av gjennomsøkingsbudsjett. Vi kaller dette den interne lenkestrukturen til nettstedet ditt. Backlinks til side, sider som har få interne koblinger får mye mindre oppmerksomhet fra søkemotorer enn sider som er knyttet til av mange sider.
Unngå en veldig hierarkisk lenkestruktur, med sider i midten som har få lenker. I mange tilfeller vil disse sidene ikke bli ofte gjennomsøkt. Det er enda verre for sider nederst i hierarkiet: på grunn av deres begrensede mengde lenker, kan de godt bli forsømt av søkemotorer.
Sørg for at de viktigste sidene dine har mange interne lenker. Sider som nylig har blitt gjennomsøkt, rangerer vanligvis bedre i søkemotorer. Vær oppmerksom på dette, og juster din interne lenkestruktur for dette.
hvis du for eksempel har en bloggartikkel fra 2011 som driver mye organisk trafikk, må du sørge for å fortsette å koble til den fra annet innhold. Fordi du har produsert mange andre bloggartikler gjennom årene, blir den artikkelen fra 2011 automatisk presset ned i nettstedets interne lenkestruktur.

Du trenger vanligvis ikke å bekymre deg for gjennomsøkingshastigheten på viktige sider. Det er vanligvis sider som er nye, som du ikke koblet til, og at folk ikke kommer til det, kan ikke gjennomsøkes ofte.
Hvordan øker du nettstedets gjennomsøkingsbudsjett?
under et intervju (åpnes i en ny fane) Mellom Eric Enge Og Googles tidligere leder Av webspam-teamet Matt Cutts, ble forholdet mellom autoritet og gjennomsøkingsbudsjett tatt opp:

Den beste måten å tenke på det er at antall sider som vi gjennomgå er omtrent proporsjonal Med PageRank. Så hvis du har mange innkommende lenker på rotsiden din, vil vi definitivt gjennomgå det. Deretter kan rotsiden din lenke til andre sider, og de vil få PageRank, og vi vil også gjennomgå dem. Når Du blir dypere og dypere på nettstedet ditt, Har PageRank imidlertid en tendens til å avta.
Selv Om Google har forlatt oppdatering PageRank verdier av sider offentlig, tror vi (en form For) PageRank er fortsatt brukes i sine algoritmer. Siden PageRank er et misforstått og forvirrende begrep, la oss kalle det page authority. Take-away her er At Matt Cutts i utgangspunktet sier: det er en ganske sterk sammenheng mellom page authority og crawl budsjett.
Så, for å øke nettstedets gjennomsøkingsbudsjett, må du øke autoriteten til nettstedet ditt. En stor del av dette gjøres ved å tjene flere linker fra eksterne nettsteder. Mer informasjon om dette finner du i vår link building guide.

Når jeg hører bransjen snakker om gjennomsøkingsbudsjett, snakker vi vanligvis om de på siden og tekniske endringene vi kan gjøre for å øke gjennomsøkingsbudsjettet over tid. Men kommer fra en link bygge bakgrunn, de største toppene i gjennomsøkt sider vi ser I Google Search Console direkte knyttet til når vi vinne store linker for våre kunder.
Ofte stilte spørsmål om gjennomsøkingsbudsjett
- 🧾 Hva er crawl budsjett?
- 🤔 Hvordan øker jeg gjennomsøkingsbudsjettet mitt?
- 🎛 ️ hva kan begrense gjennomsøkingsbudsjettet mitt?
- 🤖 Skal jeg i det hele tatt bruke kanonisk URL og meta-roboter?
1. 🧾 Hva er gjennomsøkingsbudsjett?
Gjennomsøkingsbudsjett Er antall sider søkemotorer vil gjennomsøke på et nettsted innen en viss tidsramme.
2. 🤔 Hvordan øker jeg gjennomsøkingsbudsjettet mitt?
Google har indikert At Det er et sterkt forhold mellom sidemyndighet og gjennomsøkingsbudsjett. Jo mer autoritet en side har, jo mer gjennomsøkingsbudsjett har den. Enkelt sagt, for å øke gjennomsøkingsbudsjettet, bygg sidens autoritet.
3. 🤷 Hva kan begrense gjennomsøkingsbudsjettet mitt?
Crawl limit, også kjent som crawl host load, er basert på mange faktorer, for eksempel nettstedets tilstand og hosting evner. Søkemotorroboter er satt til å hindre overbelastning av en webserver. Hvis webområdet returnerer serverfeil, eller hvis de forespurte Nettadressene tidsavbrudd ofte, blir gjennomsøkingsbudsjettet mer begrenset. På samme måte, hvis nettstedet ditt kjører på en delt hostingplattform, vil gjennomsøkingsgrensen være høyere da du må dele gjennomsøkingsbudsjettet med andre nettsteder som kjører på hosting.
4. 🤖 Skal jeg i det hele tatt bruke canonical URL og meta robots?
ja, og Det er viktig å forstå forskjellene mellom indekseringsproblemer og kravlesøkproblemer.
de kanoniske URL-og meta robots-taggene sender et klart signal til søkemotorer hvilken side de skal vise i indeksen, men det hindrer dem ikke i å gjennomsøke de andre sidene.
du kan bruke robotene.txt-fil og nofollow link forhold for å håndtere gjennomgå problemer.