
出典:TensorFlowオブジェクト検出APIを使用してコンピュータビジョンモデルを過給する、
Jonathan Huang、研究科学者およびVivek Rathod、ソフトウェアエンジニア、
Google AI Blog
- コンピュータビジョンの仕事としての物体検出
- リアルタイムオブジェクト検出器としてのYOLO
- YOLOとは何ですか?
- YOLO他の検出器と比較して
- YOLO
- YOLOアプリケーションの例
- TensorFlow&Kerasフレームワークのオブジェクト検出器としてのYOLO
- 事前に訓練されたYOLOをすぐに実行して結果を取得する方法
- カスタムYOLOオブジェクト検出モデルをトレーニングする方法
- タスクステートメント
- Dataset&annotations
- YOLOのデータに注釈を付ける方法
- 他の形式のデータをYOLO
- データをサブセットに分割する
- データジェネレータの作成
- インストール&モデルトレーニングに必要なセットアップ
- モデルトレーニング
- 前提条件
- モデルオブジェクトの初期化
- コールバックの定義
- モデルのフィッティング
- 推論モードで学習したカスタムモデル
- Anton Morgunov
- TensorFlowオブジェクト検出API:トレーニング、評価へのベストプラクティス&展開
コンピュータビジョンの仕事としての物体検出
私たちは毎日私たちの生活の中で物体に遭遇します。 周りを見回すと、あなたはあなたを取り巻く複数のオブジェクトを見つけることができます。 人間として、あなたは簡単にあなたが見る各オブジェクトを検出し、識別することができます。 それは自然であり、多くの努力を取ることはありません。
しかし、コンピュータの場合、オブジェクトの検出は複雑な解決策を必要とするタスクです。 コンピュータが「物体を検出する」とは、入力画像(またはビデオからの単一フレーム)を処理し、画像上の物体とその位置に関する情報で応答することを意 コンピュータビジョンの用語では、これら二つのタスクの分類とローカリゼー 私たちは、コンピュータが与えられた画像上にどのような種類のオブジェクトが表示され、正確にどこにあるのかを言いたいと考えています。
コンピュータが物体を検出するのに役立つ複数のソリューションが開発されています。 今日は、リアルタイムの速度で高精度を実現するYOLOと呼ばれる最先端のアルゴリズムを探索します。 特に、TensorFlow/Kerasのカスタムデータセットでこのアルゴリズムを訓練する方法を学びます。
まず、YOLOが正確に何であり、それが有名なのかを見てみましょう。
リアルタイムオブジェクト検出器としてのYOLO
YOLOとは何ですか?
YOLOは”You Only Look Once”の頭字語です(シンプソンズの”You Only Live Once”と混同しないでください)。 名前が示すように、単一の”外観”は、画像上のすべてのオブジェクトを見つけてそれらを識別するのに十分です。
機械学習の用語では、すべてのオブジェクトは単一のアルゴリズム実行によって検出されると言うことができます。 これは、画像をグリッドに分割し、グリッド内の各セルの境界ボックスとクラス確率を予測することによって行われます。 車の検出にYOLOを使用したい場合は、グリッドと予測された境界ボックスが次のようになります:

YOLOが最初の車のために予測する境界ボックスは赤です。
YOLOが二台目の車に対して予測する境界ボックスは黄色です。
画像のソース。
上の画像には、フィルタリング後に取得されたボックスの最終セットのみが含まれています。 YOLOの生の出力には、同じオブジェクトの多くの境界ボックスが含まれていることは注目に値します。 これらの箱は形状とサイズが異なります。 下の画像でわかるように、いくつかのボックスはターゲットオブジェクトをキャプチャするのに優れていますが、アルゴリズムによって提供され

すべての黄色のボックスは、二号車のためのものです。
大胆な赤と黄色のボックスは、車の検出に最適です。
画像のソース。
与えられたオブジェクトに最適な境界ボックスを選択するには、非最大抑制(NMS)アルゴリズムが適用されます。

ボックスを処理します。
画像のソース。
YOLOが予測するすべてのボックスには、信頼水準が関連付けられています。 NMSは、これらの信頼値を使用して、低い確実性で予測されたボックスを削除します。 通常、これらはすべて、0.5以下の信頼度で予測されるボックスです。

各ボックスの左上隅、オブジェクト名の横に信頼スコアが表示されます。
画像のソース。
すべての不確実な境界ボックスが削除されると、信頼水準の高いボックスのみが残ります。 最もパフォーマンスの高い候補の中から最良のものを選択するために、NMSは信頼水準が最も高いボックスを選択し、それが周囲の他のボックスとどの 交差が特定のしきい値レベルよりも高い場合は、信頼度の低い境界ボックスが削除されます。 NMSが選択したしきい値以下の交差を持つ2つのボックスを比較する場合、両方のボックスは最終的な予測に保持されます。
YOLO他の検出器と比較して
畳み込みニューラルネット(CNN)はYOLOのフードの下で使用されていますが、リアルタイムのパフォーマンスで物体を検出すること これは、単一段階のアプローチで同時に予測を行うYOLOの能力のおかげで可能です。
オブジェクト検出のための他の遅いアルゴリズム(高速R-CNNのような)は、通常、二段階のアプローチを使用します:
- 第一段階では、興味深い画像領域が選択される。
- 第二段階では、これらの各領域は畳み込みニューラルネットを使用して分類されます。
通常、オブジェクトを含む画像上には多くの領域があります。 これらの地域はすべて分類に送られます。 分類は時間のかかる操作であるため、二段階のオブジェクト検出アプローチの実行は一段階の検出に比べて遅くなります。
YOLOは画像の興味深い部分を選択しないので、その必要はありません。 代わりに、画像全体の境界ボックスとクラスを単一の順方向ネットパスで予測します。
以下では、YOLOが他の一般的な検出器と比較されている速度を見ることができます。

SSDとYOLOは1段オブジェクト検出器ですが、Faster-RCNN
とR-FCNは2段オブジェクト検出器です。
画像のソース。
YOLO
YOLOのバージョンは、2015年にJoseph Redmonによって”You Only Look Once:Unified,Real-Time Object Detection”と題された研究論文で初めて導入されました。
それ以来、YOLOは多くの進化を遂げてきました。 2016年、ジョセフ-レッドモンは”YOLO9000:Better,Faster,Stronger”で第二のYOLOバージョンを説明した。
第二のYOLOの更新から約二年後、Josephは別のネットアップグレードを思いついた。 “Yolov3:An Incremental Improvement”と呼ばれる彼の論文は、多くのコンピュータエンジニアの注目を集め、機械学習コミュニティで人気を博しました。
2020年、Joseph Redmonはコンピュータビジョンの研究を中止することに決めましたが、YOLOが他の人によって開発されるのを止めませんでした。 その同じ年、3人のエンジニア(Alexey Bochkovskiy、Chien-Yao Wang、Hong-Yuan Mark Liao)のチームは、以前よりもさらに速く、より正確なYOLOの4番目のバージョンを設計しました。 彼らの調査結果は、”Yolov4″に記載されています: 物体検出の最適な速度と精度」論文彼らは4月に発表しました23rd、2020。
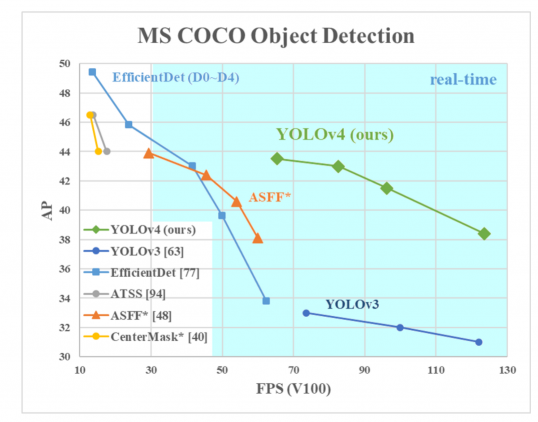
Y軸上のAPは、”平均精度”と呼ばれるメトリックです。 これは、ネットの精度を説明します。
X軸上のFPS(frames per second)は速度を表す指標です。
画像のソース。
第4版のリリースから二ヶ月後、独立した開発者、Glenn Jocherは、YOLOの第5版を発表しました。 今回は、研究論文が発表されませんでした。 このネットは、PyTorch実装としてJocherのGitHubページで利用可能になりました。 第五のバージョンは、第四のバージョンとほぼ同じ精度を持っていたが、それは速かったです。
最後に、2020年7月に別の大きなYOLOの更新がありました。 “PP-YOLO:オブジェクト検出器の効果的かつ効率的な実装”と題された論文で、Xiang LongとチームはYOLOの新しいバージョンを考え出しました。 このYOLOの反復は、3番目のモデルバージョンに基づいており、YOLO v4のパフォーマンスを超えていました。

Y軸上のマップは、”平均平均精度”と呼ばれるメトリックです。 これは、ネットの精度を説明します。
X軸上のFPS(frames per second)は速度を表す指標です。
画像のソース。
このチュートリアルでは、Yolov4とその実装を詳しく見ていきます。 なぜYolov4? 三つの理由:
- このバージョンは、機械学習コミュニティで広く承認されています。
- このバージョンは、幅広い検出タスクで高い性能を証明しています;
- Yolov4は、TensorFlowやKerasを含む複数の一般的なフレームワークで実装されています。
YOLOアプリケーションの例
この記事の実用的な部分に進む前に、カスタムYOLOベースのオブジェクト検出器を実装する前に、いくつかのクールなYlov4実装
予測がいかに速く正確であるかに注意してください!
ここでは、異なるゲームや映画のシーンから複数のオブジェクトを検出し、Yolov4が何ができるかの最初の印象的な例です。
または、このオブジェクト検出デモを実際のカメラビューから確認することもできます。機械学習におけるTensorFlow&KERAS
TensorFlow&Kerasフレームワークのオブジェクト検出器としてのYOLO

画像のソース。
フレームワークは、すべての情報技術領域に不可欠です。 機械学習も例外ではありません。 ML市場にはいくつかの確立されたプレーヤーがあり、全体的なプログラミング体験を簡素化するのに役立ちます。 PyTorch、scikit-learn、TensorFlow、Keras、MXNet、Caffeは言及する価値があります。
今日は、TensorFlow/Kerasと緊密に連携します。 驚くことではないが、これら2つは機械学習の世界で最も人気のあるフレームワークの1つです。 これは主に、TensorFlowとKerasの両方が開発のための豊富な機能を提供するという事実によるものです。 これらの2つのフレームワークは、互いに非常に似ています。 詳細をあまり掘り下げることなく、覚えておくべき重要なことは、KerasはTensorFlowフレームワークのラッパーに過ぎないということです。TensorFlowでのYOLO実装&Keras
この記事を書いている時点で、TENSORFLOW/KerasバックエンドにYOLO実装を持つ808のリポジトリがありました。 YOLOバージョン4は、実装する予定です。 検索をYOLO v4のみに制限すると、55のリポジトリが得られました。
慎重にそれらのすべてを閲覧し、私は続けるために興味深い候補を見つけました。
画像のソース。
この実装は、taipingericとjimmyaspireによって開発されました。 以前にTensorFlowとKerasで作業したことがあれば、非常にシンプルで直感的です。
この実装で作業を開始するには、リポジトリをローカルマシンにクローンするだけです。 次に、YOLOをすぐに使用する方法と、独自のカスタムオブジェクト検出器を訓練する方法を紹介します。
事前に訓練されたYOLOをすぐに実行して結果を取得する方法
レポの”クイックスタート”セクションを見ると、モデルを起動して実行するには、YOLOをク:
from models import Yolov4model = Yolov4(weight_path='yolov4.weights', class_name_path='class_names/coco_classes.txt')
モデルの重みを事前に手動でダウンロードする必要があることに注意してください。 YOLOに付属のモデルウェイトファイルはCOCOデータセットから来ており、GithubのAlexeyAB公式darknetプロジェクトページで入手できます。 このリンクから直接重みをダウンロードすることができます。
直後、モデルは推論モードで画像を操作する準備ができています。 選択した画像にはpredict()メソッドを使用してください。 この方法は、TensorFlowおよびKerasフレームワークの標準です。
pred = model.predict('input.jpg')
たとえば、この入力画像の場合:

私は次のモデル出力を得ました:

モデルが作成した予測は、pandas DataFrameの便利な形式で返されます。 検出された各オブジェクトのクラス名、ボックスサイズ、座標を取得します:

検出されたオブジェクトに関する多くの有用な情報
predict()メソッドには複数のパラメータがあり、予測された境界ボックス、各オブジェクトのテキスト名などで画像をプロットするかどうかを指定できます。 Predict()メソッドと一緒に使用できるdocstringをチェックして、利用可能なものに慣れるようにしてください:

モデルは、COCOデータセットに厳密に制限されたオブジェクトタイプのみを検出できることを期待する必要があります。 事前に訓練されたYOLOモデルが検出できるオブジェクトタイプを知るには、coco_classesをチェックしてください。…/yolo-v4-tfで利用可能なtxtファイル。kers/class_names/. そこには80のオブジェクトタイプがあります。
カスタムYOLOオブジェクト検出モデルをトレーニングする方法
タスクステートメント

オブジェクト検出モデルを設計するには、どのオブジェクトタイプを検出するかを知る必要があります。 これは、検出器を作成するオブジェクトタイプの数が限られている必要があります。 実際のモデル開発に移行するときに、オブジェクトタイプのリストを用意するのは良いことです。
理想的には、興味のあるオブジェクトを持つ注釈付きデータセットも必要です。 このデータセットは、検出器を訓練して検証するために使用されます。 あなたはまだそれのためのデータセットや注釈のいずれかを持っていない場合は、心配しないで、私はあなたがそれを得ることができる場所と方法を
Dataset&annotations
からデータを取得する場所注釈付きのdatasetを使用する場合は、この部分をスキップして次の章に進みます。 しかし、プロジェクトにデータセットが必要な場合は、データを取得できるオンラインリソースを探索します。
どのフィールドで作業しているかは問題ではありませんが、プロジェクトに使用できるオープンソースのデータセットがすでにある可能性が高いです。
私がお勧めする最初のリソースは、ファッション、小売、スポーツ、医学などの産業のための素晴らしい注釈付きデータセットを収集したAbhishek Annamrajuによる”50+Object Detection Datasets from different industry domains”

画像のソース。
データを探すための他の2つの素晴らしい場所は次のとおりですpaperswithcode.com とroboflow.com オブジェクト検出のための高品質のデータセットへのアクセスを提供します。
上記のアセットをチェックして、必要なデータを収集したり、すでに持っているデータセットを強化したりします。
YOLOのデータに注釈を付ける方法
画像のデータセットに注釈がない場合は、注釈ジョブを自分で行う必要があります。 この手動操作は非常に時間がかかるので、十分な時間があることを確認してください。
注釈ツールとして、複数のオプションを検討することができます。 個人的には、LabelImgを使用することをお勧めします。 これは、YOLOモデルの注釈を直接出力できる軽量で使いやすい画像注釈ツールです。
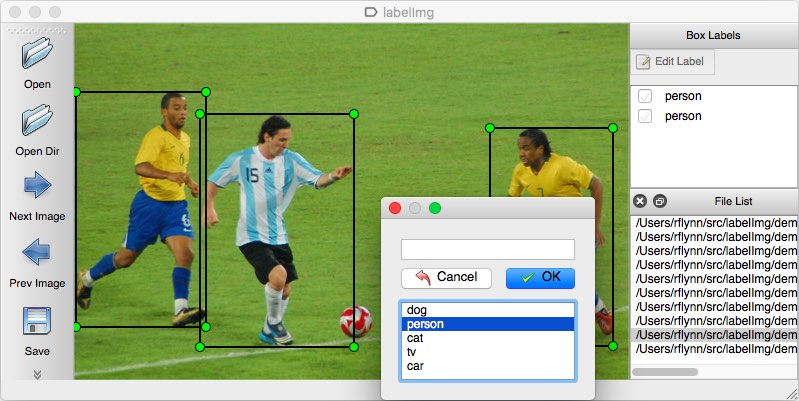
画像のソース。
他の形式のデータをYOLO
に変換する方法YOLOの注釈はtxtファイルの形式です。 TxtファイルFOL YOLOの各行は、次の形式でなければなりません:
image1.jpg 10,15,345,284,0image2.jpg 100,94,613,814,0 31,420,220,540,1
txtファイルから各行を分割し、それが何で構成されているかを見ることができます:
- 行の最初の部分は、イメージのベース名を指定します。image1。jpg、image2。jpg
- 行の2番目の部分は、境界ボックスの座標とクラスラベルを定義します。 たとえば、xmin、ymin、xmax、ymax、class_idの状態は10,15,345,284,0です
- 指定された画像に複数のオブジェクトがある場合は、画像のベース名の横に複数のボックスとクラスラベルがあり、スペースで分割されています。
境界ボックス座標は明確な概念ですが、クラスラベルを指定するclass_id番号はどうですか? 各class_idは、別のtxtファイル内の特定のクラスとリンクされています。 たとえば、事前に訓練されたYOLOにはcoco_classesが付属しています。このようなtxtファイル:
personbicyclecarmotorbikeaeroplanebus...
classesファイルの行数は、ディテクタが検出するクラスの数と一致する必要があります。 つまり、classesファイルの最初のクラスのclass_id番号は0になります。 Classes txtファイルの2行目に配置されているクラスには、番号が1になります。
これで、YOLOの注釈がどのように見えるかがわかりました。 カスタムオブジェクトディテクタを作成し続けるには、次の2つのことを行うことをお勧めします:
- 検出器で検出したいクラスを格納するクラスtxtファイルを作成します。 クラスの順序が重要であることを覚えておいてください。
- 注釈付きのtxtファイルを作成します。 すでに注釈を持っているが、VOC形式の場合(。このファイルを使用して、XMLからYOLOに変換できます。
データをサブセットに分割する
いつものように、データセットをトレーニングと検証のための2つのサブセットに分割したいと考えています。 それは次のように簡単に行うことができます:
from utils import read_annotation_lines train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1)
データジェネレータの作成
データが分割されると、データジェネレータの初期化に進むことができます。 データファイルごとにデータジェネレータが用意されています。 私たちの場合、トレーニングサブセットと検証サブセットのジェネレータがあります。
データジェネレータの作成方法は次のとおりです:
from utils import DataGenerator FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
すべてを要約すると、データ分割とジェネレータ作成のための完全なコードは次のようになります:
from utils import read_annotation_lines, DataGenerator train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1) FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
インストール&モデルトレーニングに必要なセットアップ
独自のオブジェクト検出器を作成するために不可欠な前提条件について話しましょう:
- あなたのコンピュータにPythonが既にインストールされているはずです。 あなたがそれをインストールする必要がある場合には、私はAnacondaによってこの公式ガイドに従うことをお勧めします;
- お使いのコンピュータにCUDA対応GPU(NVIDIA製のGPU)がある場合、GPUベースのトレーニングをサポートするには、いくつかの関連ライブラリが必要です。 GPUサポートを有効にする必要がある場合は、NVIDIAのwebサイトのガイドラインを確認してください。 あなたの目標は、CUDA ToolkitとcuDNNの両方の最新バージョンをオペレーティングシステムにインストールすることです;
- 作業するために独立した仮想環境を整理することができます。 このプロジェクトにはTensorFlow2がインストールされている必要があります。 他のすべてのライブラリは、後で導入されます;
- 私にとっては、Jupyter Notebook開発環境でYolov4モデルを構築し、トレーニングしていました。 Jupyter Notebookは合理的な選択肢のようですが、必要に応じて選択したIDEでの開発を検討してください。
モデルトレーニング

前提条件
今ではあなたが持っている必要があります:
- データセットの分割;
- 初期化された二つのデータジェネレータ;
- クラスを含むtxtファイル。
モデルオブジェクトの初期化
トレーニングジョブの準備をするには、Yolov4モデルオブジェクトを初期化します。 Weight_pathパラメーターの値としてNoneを使用するようにしてください。 また、このステップでclasses txtファイルへのパスを指定する必要があります。 プロジェクトで使用した初期化コードは次のとおりです:
class_name_path = 'path2project_folder/model_data/scans_file.txt' model = Yolov4(weight_path=None, class_name_path=class_name_path)
上記のモデルの初期化は、パラメーターの既定のセットを持つモデルオブジェクトの作成につながります。 Config modelパラメーターに値としてディクショナリを渡して、モデルの構成を変更することを検討してください。

Configは、Yolov4モデルのパラメーターのセットを指定します。
デフォルトのモデル設定は良い出発点ですが、モデルの品質を向上させるために他の設定を試してみることをお勧めします。
特に、anchorsとimg_sizeを試してみることを強くお勧めします。 アンカーは、オブジェクトをキャプチャするために使用されるアンカーのジオメトリを指定します。 アンカーの形状がオブジェクトの形状に適合するほど、モデルのパフォーマンスは高くなります。
img_sizeを増やすと、場合によっては便利かもしれません。 イメージが高いほど、モデルが推論を行う時間が長くなることに注意してください。
Neptuneを追跡ツールとして使用する場合は、次のように実験の実行も初期化する必要があります:
import neptune.new as neptune run = neptune.init(project='projects/my_project', api_token=my_token)
コールバックの定義
TensorFlow&Kerasでは、コールバックを使用してトレーニングの進捗状況を監視し、チェックポイントを作成し、トレーニングパラメータ(学習率など)を管理
モデルを近似する前に、目的に役立つコールバックを定義します。 モデルチェックポイントと関連するログを格納するパスを指定してください。 ここで私は私のプロジェクトの一つでそれをやった方法です:
# defining pathes and callbacks dir4saving = 'path2checkpoint/checkpoints'os.makedirs(dir4saving, exist_ok = True) logdir = 'path4logdir/logs'os.makedirs(logdir, exist_ok = True) name4saving = 'epoch_{epoch:02d}-val_loss-{val_loss:.4f}.hdf5' filepath = os.path.join(dir4saving, name4saving) rLrCallBack = keras.callbacks.ReduceLROnPlateau(monitor = 'val_loss', factor = 0.1, patience = 5, verbose = 1) tbCallBack = keras.callbacks.TensorBoard(log_dir = logdir, histogram_freq = 0, write_graph = False, write_images = False) mcCallBack_loss = keras.callbacks.ModelCheckpoint(filepath, monitor = 'val_loss', verbose = 1, save_best_only = True, save_weights_only = False, mode = 'auto', period = 1)esCallBack = keras.callbacks.EarlyStopping(monitor = 'val_loss', mode = 'min', verbose = 1, patience = 10)
上記のコールバックでは、set TensorBoardが追跡ツールとして使用されていることに気づいた可能性があります。 実験追跡のためのはるかに高度なツールとして海王星を使用することを検討してください。 その場合は、Neptuneとの統合を有効にするために別のコールバックを初期化することを忘れないでください:
from neptune.new.integrations.tensorflow_keras import NeptuneCallback neptune_cbk = NeptuneCallback(run=run, base_namespace='metrics')
モデルのフィッティング
トレーニングジョブを開始するには、TensorFlow/Kerasの標準fit()メソッドを使用してモデルオブジェクトをフィッティングします。 ここで私は私のモデルを訓練し始めた方法です:
model.fit(data_gen_train, initial_epoch=0, epochs=10000, val_data_gen=data_gen_val, callbacks= )
トレーニングが開始されると、標準のプログレスバーが表示されます。

学習プロセスは、すべてのエポックの終わりにモデルを評価します。 私が初期化し、フィッティング中に渡したものと同様のコールバックのセットを使用すると、低損失の点でモデルの改善を示すチェックポイントは、指定されたディレクトリに保存されます。
エラーが発生せず、トレーニングプロセスがスムーズに進行した場合、トレーニングエポック数が終了したため、または早期停止コールバックがそれ以上のモデ
いずれにしても、複数のモデルチェックポイントになるはずです。 利用可能なすべてのものから最良のものを選択し、それを推論に使用したいと考えています。
推論モードで学習したカスタムモデル
推論モードで学習したモデルを実行することは、事前に学習したモデルをそのまま実行することに似ています。

クラスを使用して、最適なチェックポイントへのパスとtxtファイルへのパスを渡すモデルオブジェクトを初期化します。 私のプロジェクトでは、モデルの初期化がどのように見えるかは次のとおりです:
from models import Yolov4model = Yolov4(weight_path='path2checkpoint/checkpoints/epoch_48-val_loss-0.061.hdf5', class_name_path='path2classes_file/my_yolo_classes.txt')
モデルが初期化されたら、選択した画像のpredict()メソッドを使用して予測を取得します。 要約として、モデルが作成した検出は、pandas DataFrameの便利な形式で返されます。 検出された各オブジェクトのクラス名、ボックスサイズ、および座標を取得します。
カスタムYolov4オブジェクト検出器を作成する方法を学習しました。 データの収集、注釈、変換から始めて、エンドツーエンドのプロセスを完了しました。 あなたは4番目のYOLOバージョンとそれが他の検出器とどのように異なるかについて十分な知識を持っています。
TensorflowとKerasで独自のモデルをトレーニングすることを止めるものはありません。 あなたはどこから事前に訓練されたモデルを取得するとどのように訓練の仕事をキックオフすることを知っています。
私の今後の記事では、私はあなたに最終的なモデルの品質を向上させるのに役立つベストプラクティスとライフハックのいくつかを紹介します。 私たちと一緒にいて!



Anton Morgunov
Basisのコンピュータビジョンエンジニア。センター
コンピュータビジョンに情熱を持っています。 紙はありません-より多くの木! 完全デジタル化に移行し、紙コピーの排除に向けて取り組んでいます!
次を読む
TensorFlowオブジェクト検出API:トレーニング、評価へのベストプラクティス&展開
13分read|Author Anton Morgunov|Updated May28th,2021
この記事は、TensorFlowオブジェクト検出とそのAPIのエンドツーエンドのワークフローを学ぶシリーズの第二部です。 最初の記事では、最初からカスタムオブジェクト検出器を作成する方法を学びましたが、本当に熟練するために注意が必要なものはまだたくさんあ
すでに経験したモデル作成プロセスと同じくらい重要なトピックを探ります。 ここで私たちが答える質問のいくつかは次のとおりです:
- どのように私のモデルを評価し、その性能の推定値を取得するには?
- モデルのパフォーマンスを追跡し、複数の実験で結果を比較するために使用できるツールは何ですか?
- 推論モードで使用するためにモデルをエクスポートするにはどうすればよいですか?
- モデルのパフォーマンスをさらに向上させる方法はありますか?
続きを読む->