クロール予算は、検索エンジンが特定の時間枠内にwebサイト
検索エンジンは、クロール制限(問題を起こさずにクロールできる頻度)とクロール需要(サイトをクロールする頻度)に基づいてクロール予算を計算します。
クロール予算を無駄にしている場合、検索エンジンはあなたのSEOのパフォーマンスを傷つけることになるだろう、効率的にあなたのウェブサイトをク
- クロール予算とは何ですか?
- 検索エンジンはなぜクロール予算をウェブサイトに割り当てるのですか?
- どのように彼らはウェブサイトにクロール予算を割り当てるのですか?
- クロール予算はページだけですか?
- クロール制限/ホストのロードは実際にはどのように機能しますか?
- クロール要求/クロールスケジュールは実際にはどのように機能しますか?
- 忘れないでください:システム自体のクロール容量
- なぜクロール予算を気にする必要がありますか?
- 私のウェブサイトのクロール予算とは何ですか?
- Google Search Consoleでのクロール予算
- ソースに移動します:サーバーログ
- クロールの予算をどのように最適化しますか?
- パラメータ付きのアクセス可能なUrl
- 重複したコンテンツ
- 低品質のコンテンツ
- 壊れたリンクとリダイレクト
- XMLサイトマップの不適切なUrl
- ContentKing
- 読み込み時間/タイムアウトの多いページ
- インデックス不可能なページの数が多い
- 不正な内部リンク構造
- どのようにあなたのウェブサイトのクロールの予算を増やすのですか?
- クロール予算に関するよくある質問
- 1. ├予算とは?
- 2. ✓クロール予算を増やすにはどうすればよいですか?
- 3. ✔クロール予算を制限できるものは何ですか?
- 4. 🤖Canonical URLとmeta robotsをまったく使用する必要がありますか?
クロール予算とは何ですか?
クロール予算は、検索エンジンが特定の時間枠内にウェブサイト上でクロールするページ数です。
検索エンジンはなぜクロール予算をウェブサイトに割り当てるのですか?
彼らは無制限のリソースを持っていないので、彼らは何百万ものウェブサイトに彼らの注意を分けています。 だから、彼らは彼らのクロールの努力に優先順位を付ける方法が必要です。 各webサイトにクロール予算を割り当てると、これを行うのに役立ちます。
どのように彼らはウェブサイトにクロール予算を割り当てるのですか?
これは、クロール制限とクロール需要の二つの要因に基づいています:
- クロール制限/ホスト負荷:webサイトがどのくらいのクロールを処理できるか、およびその所有者の好みは何ですか?
- Crawl demand/crawl scheduling:人気度と更新頻度に基づいて、どのUrlが最もクロールする価値があるか(再)。
クロール予算は、クロールスペースまたはクロール時間とも呼ばれます。

クロール予算はページだけですか?
それは実際には、私たちはページについて話している容易さのためにではありませんが、実際にはそれは検索エンジンがクロールする任意の文書につい 他のドキュメントの例としては、JavaScriptとCSSファイル、モバイルページバリアント、hreflangバリアント、PDFファイルなどがあります。
クロール制限/ホストのロードは実際にはどのように機能しますか?
クロール制限、またはホストの負荷が必要な場合は、クロール予算の重要な部分です。 検索エンジンのクローラは、webサーバーに要求が過負荷になるのを防ぐように設計されているため、これに注意してくださどのように検索エンジンは、ウェブサイトのクロール制限を決定しますか? クロール制限に影響を与えるさまざまな要因があります。 いくつかの名前を付けるには:
- 悪い形のプラットフォームの兆候:要求されたUrlがタイムアウトまたはサーバーエラーを返す頻度。
- ホスト上で実行されているwebサイトの量:あなたのwebサイトが何百もの他のwebサイトと共有ホスティングプラットフォーム上で実行されていて、かな ホストのクロール制限を、そのホストで実行されている他のすべてのサイトと共有する必要があります。 この場合、専用サーバーでの方がはるかに優れているため、訪問者のロード時間が大幅に短縮される可能性が最も高いでしょう。
もう一つ考慮すべきことは、同じホスト上で別々のモバイルサイトとデスクトップサイトを実行していることです。 共有クロールの制限もあります。 だからこれを覚えておいてください。
検索エンジンはウェブサイトの最も重要な部分をクロールしていますか? ContentKingで迅速なテストを実行します!
クロール要求/クロールスケジュールは実際にはどのように機能しますか?
クロール要求、つまりクロールスケジュールは、Urlを再クロールする価値を決定することです。 繰り返しになりますが、多くの要因がクロール需要に影響を与えます。:
- 人気度:URLに含まれるインバウンド内部リンクとインバウンド外部リンクの数だけでなく、ランキング対象のクエリの量も表示されます。
- Freshness:URLが更新される頻度。
- ページの種類:変更される可能性のあるページの種類です。 たとえば、製品カテゴリページ、および利用規約ページを取る-あなたは最も頻繁に変更し、より頻繁にクロールされるに値すると思いますか?

見つけることがより重要な何もないときにあなたのサイトに戻ってくるためにGoogleのクローラーを強制的に(すなわち意味のある変更)良い戦略ではな 私が与えることができる最もよい助言はページをより重要にさせることに集中することである(より有用な情報を加えること、ページの内容を豊富にさせること(トピックの焦点が維持される限りそれらは自然により多くの問い合わせをデフォルトで誘発する)。 自然に’リコール'(印象)の一部としてより多くの問い合わせを誘発することによってあなたのページをより重要にさせ、lo及び見よ:多分より頻繁に這われ
忘れないでください:システム自体のクロール容量
検索エンジンのクロールシステムには大規模なクロール容量がありますが、一日の終わりには限られ そのため、Googleのデータセンターの80%が同時にオフラインになるシナリオでは、クロール容量が大幅に減少し、すべてのwebサイトのクロール予算が減少します。
クロール制限、クロール需要、クロール容量の詳細を提供してくれたDawn Anderson(新しいタブで開きます)に感謝します!
なぜクロール予算を気にする必要がありますか?
検索エンジンに、インデックス可能なページをできるだけ多く見つけて理解してもらい、できるだけ早くそれをしてもらいたいと考えています。 新しいページを追加し、既存のものを更新するときは、検索エンジンは、できるだけ早くこれらをピックアップしたいです。 早くそれらがページを指示すればしたら、早くそれらから寄与できる。
クロールの予算を無駄にしている場合、検索エンジンはあなたのウェブサイトを効率的にクロールすることはできません。 彼らはあなたのウェブサイトの重要な部分が発見されていないままになる可能性があります問題ではないあなたのサイトの部分に時間を費や 彼らがページについて知らなければ、這い、指示しないし、それらに調査エンジンを通って訪問者をそれらに持って来られない。
これがどこにつながっているかを見ることができます:クロール予算を無駄にすることは、SEOのパフォーマ
クロールの予算は、一般的に大きなウェブサイトを持っている場合、10,000ページ以上としましょう心配するものであることに注意してください。

クロール予算のより過小評価された側面の1つは、負荷速度です。 より速いローディングのウェブサイトはGoogleが同じ時間のより多くのUrlを這うことができることを意味する。 最近、私は負荷速度が主な焦点だったサイトのアップグレードに関与していました。 新しいサイトは、古いものの倍の速さでロードされました。 それがライブプッシュされたとき、Googleが一日あたりクロールされたUrlの数は150,000から600,000に上昇し、そこに滞在しました。 このサイズと範囲のサイトでは、クロール率が向上しているため、新規および変更されたコンテンツのクロールが大幅に高速になり、SerpでのSEOの取り組みの影響がはるかに迅速になります。

非常に賢明なSEO(大丈夫、それはAJコーン(新しいタブで開きます)でした)かつて有名に言った”あなたはGooglebotが食べるものです。”. あなたのランキングと検索の可視性は、Googleがあなたのサイト上でクロールするものだけでなく、頻繁にクロールする頻度に直接関連しています。 Googleがあなたの場所の内容を逃すか、または限られた/最適化されていない這う予算のために十分に頻繁に重要なUrlを這わなければ、実際にランク付け 大規模なサイトでは、クロール予算を最適化すると、以前は見えなかったページのプロファイルが大幅に向上する可能性があります。 小規模なサイトでは、クロールの予算について心配する必要はありませんが、最適化の同じ原則(速度、優先順位付け、リンク構造、重複排除など)。)はまだランク付けするのを助けることができます。

私は主にGoogleに同意し、ほとんどの場合、多くのウェブサイトはクロール予算を心配する必要はありません。 しかし、サイズの大きいウェブサイト、特に出版社など頻繁に更新されるウェブサイトでは、最適化が大きな違いを生む可能性があります。
私のウェブサイトのクロール予算とは何ですか?
すべての検索エンジンのうち、Googleはあなたのウェブサイトのクロール予算について最も透明です。
Google Search Consoleでのクロール予算
Google Search Consoleでwebサイトを検証している場合は、webサイトのgoogleのクロール予算についていくつかの洞察を得ることができます。
次の手順に従います:
- Google Search Consoleにログインし、ウェブサイトを選択します。
- へ
Crawl>Crawl Stats. そこには、Googleが一日あたりクロールするページの数を見ることができます。
2016年の夏、私たちのクロール予算は次のようになりました:
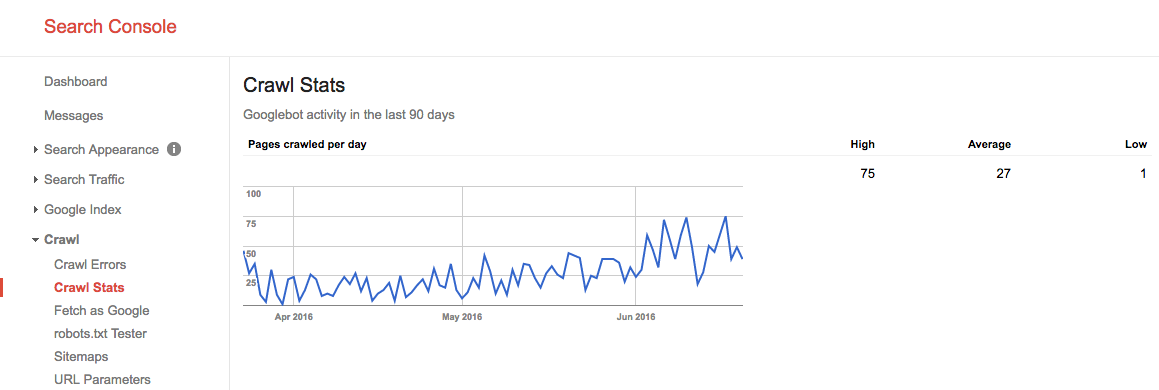
ここでは、平均クロール予算が27ページ/日であることがわかります。 したがって、理論的には、この平均クロール予算が同じままである場合、毎月のクロール予算は27ページx30日=810ページになります。
早送り2年、そして私たちのクロール予算が今何であるかを見てください:
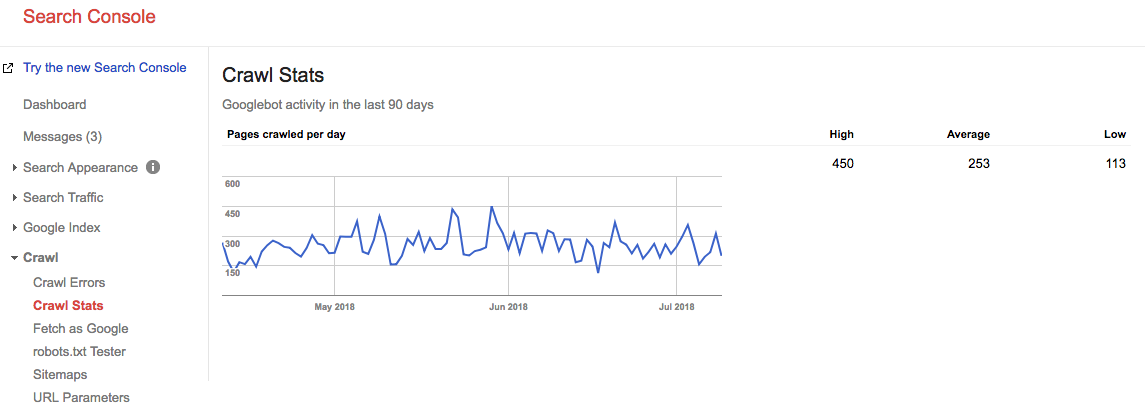
私たちの平均平均クロール予算は253ページ/日なので、クロール予算は10年で2倍になったと言うことができます。
ソースに移動します:サーバーログ
サーバーログをチェックして、Googleのクローラーがあなたのウェブサイトにヒットしている頻度を確認するのは非常に興味深い これらの統計情報をGoogle Search Consoleで報告されている統計情報と比較するのは興味深いことです。 複数のソースに依存する方が常に優れています。
クロールの問題を逃した機会にしないでください。 継続的にContentKingであなたのサイトを監視し、リアルタイムで問題に警告されます。
クロールの予算をどのように最適化しますか?
クロール予算を最適化するには、クロール予算が無駄にならないようにする必要があります。 基本的に、無駄なクロール予算の理由を修正します。 クロール予算の問題についてそれぞれをチェックすると、ほとんどのウェブサイトが同じ種類の問題に苦しんでいるパターンがすぐにわかります。
私たちが遭遇する無駄なクロール予算の一般的な理由:
- パラメータ付きのアクセス可能なUrl:パラメータ付きのURLの例は
https://www.example.com/toys/cars?color=blackです。 この場合、このパラメーターは、訪問者の選択を製品フィルターに格納するために使用されます。 - 重複コンテンツ:非常に類似している、またはまったく同じページを”重複コンテンツ”と呼びます。”例は: コピーされたページ、内部検索結果ページ、およびタグページ。
- 低品質のコンテンツ:コンテンツが非常に少ないページ、または値を追加しないページ。
- 壊れたリンクとリダイレクト:壊れたリンクは、もう存在しないページを参照するリンクであり、リダイレクトされたリンクは、他のUrlにリダイレクトされているUrlへのリンクです。
- XMLサイトマップに不適切なUrlを含める:インデックスできないページや、3xx、4xx、5xx Urlなどの非ページは、XMLサイトマップに含めるべきではありません。
- 読み込み時間/タイムアウトの高いページ: 読み込みに時間がかかるページ、またはまったく読み込まれないページは、検索エンジンにとってwebサイトがリクエストを処理できない兆候であり、クロー
- インデックスできないページの数が多い:ウェブサイトにはインデックスできないページがたくさん含まれています。
- 不正な内部リンク構造:内部リンク構造が正しく設定されていない場合、検索エンジンは一部のページに十分な注意を払わない可能性があります。

私は頻繁にGoogleがあなたの主任のようであることを言った。 あなたが話をしようとしていたもの、あなたの仕事のハイライト、あなたの会議の目標を知っていない限り、あなたはあなたの上司との会議に入る 要するに、あなたは議題を持っています。 あなたがGoogleの「オフィス」に入るとき、あなたは同じことが必要です。 多くのcruftのない明確なサイト階層、有用なXMLサイトマップ、および迅速な応答時間は、すべてGoogleが重要なものに到達するのに役立ちます。 SEOのこの頻繁に誤解された要素を見落としてはいけない。

私には、クロール予算の概念は、技術的なSEOの重要なポイントの一つです。 クロールの予算に合わせて最適化すると、内部リンク、エラーの修正、ページ速度、URLの最適化、低品質のコンテンツなど、他のすべてが適切に配置されます。 特定のUrl、サブドメイン、ディレクトリなどのクロール予算を監視するために、ログファイルをより頻繁に掘り下げる必要があります。 クロールの頻度を監視することは、クロールの予算と超強力に非常に関連しています。
パラメータ付きのアクセス可能なUrl
ほとんどの場合、パラメータ付きのUrlは、事実上無限の量のUrlを生成できるため、検索エンジンではアクセスできません。この種の問題については、クローラートラップについての記事で広範囲に記述しました。
パラメータを持つUrlは、eコマースサイトに製品フィルタを実装するときに一般的に使用されます。 それはそれらを使用するために良い;ちょうどそれらが調査エンジンにとって入手しやすいことを確かめなさい。
検索エンジンにアクセスできないようにするにはどうすればよいですか?
- あなたのロボットを使用してください。このようなUrlにアクセスしないように検索エンジンに指示するtxtファイル。 これが何らかの理由でオプションでない場合は、Google Search ConsoleとBingウェブマスターツールのURLパラメータ処理設定を使用して、クロールしないページについてGoogleとBing
- フィルタリンクのリンクにnofollow属性値を追加します。 2020年3月現在、Googleはnofollowを無視することを選択する可能性があることに注意してください。 したがって、ステップ1はさらに重要です。
重複したコンテンツ
検索エンジンが重複したコンテンツページに時間を費やしたくないので、サイト内の重複コンテンツを防止するか、少な
どのようにこれを行うのですか? によって…
- すべてのドメインバリアントのwebサイトリダイレ(
HTTP,HTTPS,non-WWW, およびWWW)。 - ロボットを使用して検索エンジンに内部検索結果ページにアクセスできないようにします。txt。 ここでは例のロボットです。ワードプレスのウェブサイトのためのtxt。
- 画像の専用ページを無効にする(例:WordPressの悪名高い画像添付ページ)。
- カテゴリやタグなどの分類法の使用に注意してください。
重複したコンテンツの技術的な理由とそれらを修正する方法を確認してください。
低品質のコンテンツ
コンテンツが非常に少ないページは、検索エンジンにとって興味深いものではありません。 それらを最小限に抑えるか、可能であれば完全に避けてください。 低品質のコンテンツの一例は、質問と回答を表示するためのリンクを持つFAQセクションであり、各質問と回答は別々のURLで提供されます。
壊れたリンクとリダイレクト
壊れたリンクとリダイレクトの長いチェーンは、検索エンジンにとって行き止まりです。 ブラウザと同様に、Googleは一度のクロールで最大五つの連鎖リダイレクトをフォローしているようです(後でクロールを再開する可能性があります)。 他の検索エンジンが後続のリダイレクトをどれだけうまく処理するかは不明ですが、連鎖したリダイレクトを完全に避け、リダイレクトの使用を最小限に抑えることを強くお勧めします。
壊れたリンクを修正し、リンクをリダイレクトすることで、無駄なクロール予算をすばやく回復できることは明らかです。 クロール予算の回復に加えて、訪問者のユーザーエクスペリエンスも大幅に向上しています。 リダイレクト、特にリダイレクトの連鎖は、ページの読み込み時間を長くし、ユーザーエクスペリエンスを損なう原因となります。
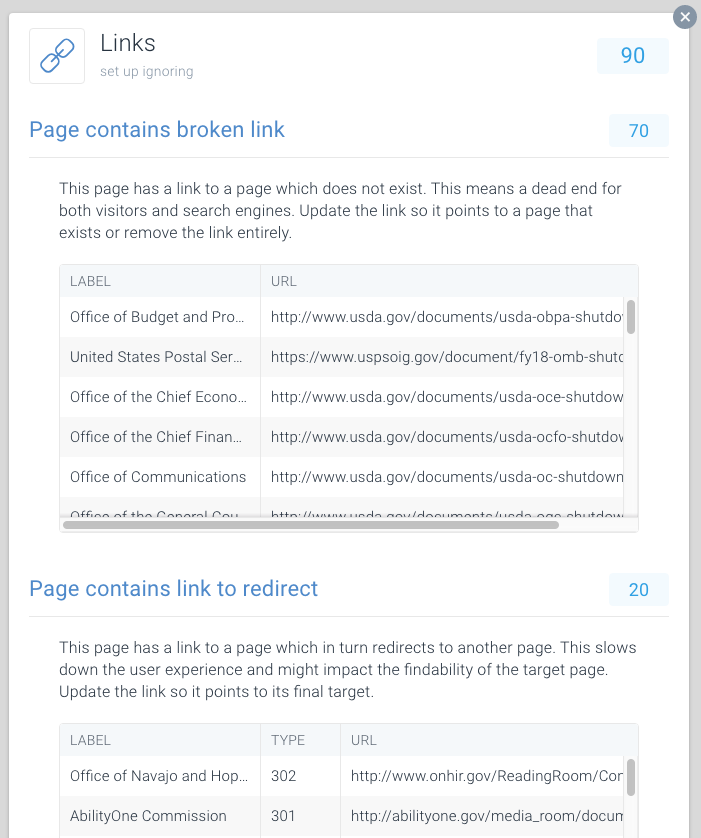
壊れたリンクを見つけてリダイレクトするのを簡単にするために、ContentKing内でこれに特別な問題を捧げました。
Issues>Linksに移動して、リンクに障害があるためにクロール予算を無駄にしているかどうかを確認します。 インデックス可能なページにリンクするように各リンクを更新するか、リンクが不要になった場合はリンクを削除します。
XMLサイトマップの不適切なUrl
XMLサイトマップに含まれるすべてのUrlは、インデックス可能なページ用でなければなりません。 特に大規模なウェブサイトでは、検索エンジンは、すべてのページを見つけるためにXMLサイトマップに大きく依存しています。 XMLサイトマップに存在しないページやリダイレクトしているページなどが雑然としている場合は、クロールの予算を無駄にしています。 そこに属していないインデックスできないUrlがないか、XMLサイトマップを定期的に確認してください。 XMLサイトマップから誤って除外されているページを探します。 XMLサイトマップは、検索エンジンがクロール予算を賢明に費やすのに役立つ素晴らしい方法です。
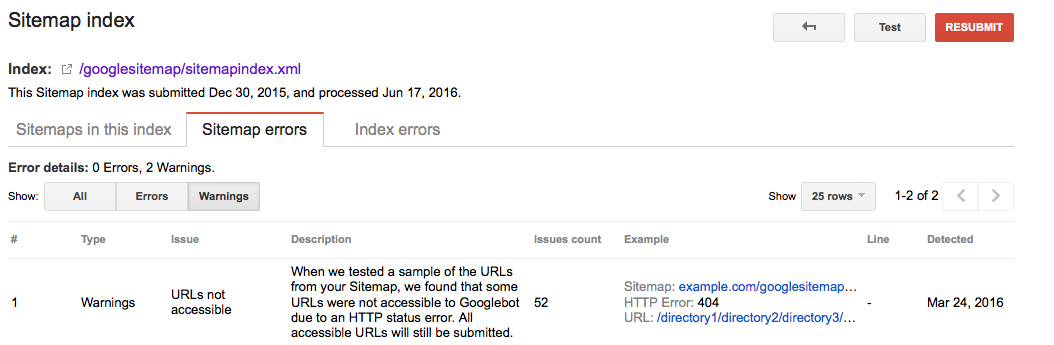
Google Searche Console
- Google検索コンソールにログイン
-
Crawlタブをクリック -
Sitemapsタブをクリック
Bingウェブマスターツール
- Bingウェブマスターツールアカウントにログオンする
-
Configure My Siteタブをクリックします -
Sitemapsタブをクリックします
ContentKing
- ContentKingアカウントにログオンします
-
Issuesボタンをクリックします -
XML Sitemapボタンをクリックします - ページに問題がある場合は、次のメッセージが表示されます:
Page is incorrectly included in XML sitemap
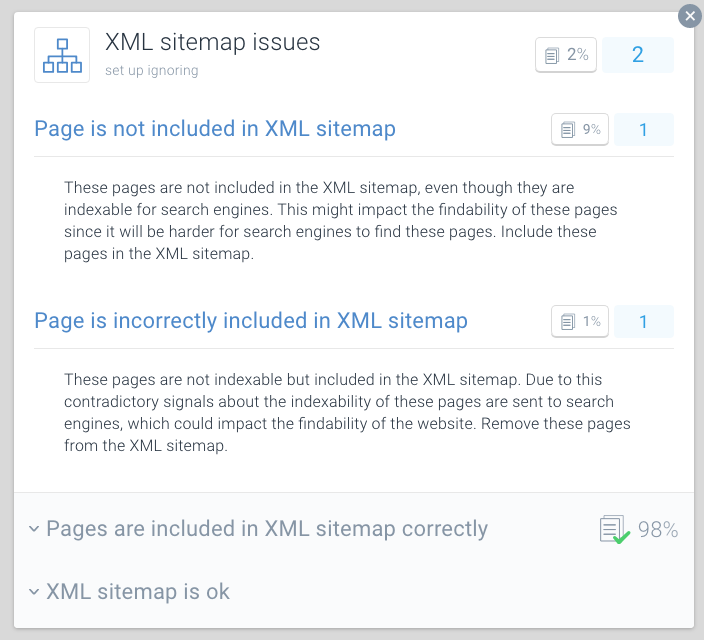
におけるXMLサイトマップの問題クロール予算の最適化のベストプラクティスの1つは、XMLサイトマップを たとえば、WEBサイトのセクションごとにXMLサイトマップを作成できます。 これを行った場合は、すぐにあなたのウェブサイトの特定のセクションで起こっている問題があるかどうかを判断することができます。
セクションAのXMLサイトマップには500個のリンクが含まれており、480個のリンクが索引付けされているとします。 しかし、セクションBのXMLサイトマップに500のリンクが含まれており、120だけが索引付けされている場合、それは調べるものです。 セクションBのXMLサイトマップには、インデックス化できないUrlがたくさん含まれている可能性があります。
クローラーの悪い条件はあなたのSEOを傷つけることができます。 ContentKingを使用して、webサイトの迅速な監査を実行します。
読み込み時間/タイムアウトの多いページ

ページのロード時間が高いかタイムアウ その欠点に加えて、高いページの読み込み時間とタイムアウトが大幅に低いコンバージョン率で、その結果、あなたの訪問者のユーザーエクスペリ
2秒以上のページの読み込み時間が問題です。 理想的には、あなたのページは1秒以内にロードされます。 Pingdom(新しいタブで開きます)、WebPagetest(新しいタブで開きます)、GTmetrix(新しいタブで開きます)などのツールを使用して、ページの読み込み時間を定期的に確認します。
Googleは両方のGoogleアナリティクスでページの読み込み時間を報告します(下Behavior > Site Speed) とGoogle検索コンソールの下にCrawl > Crawl Stats.
Google検索コンソールとBingウェブマスターツールの両方がページのタイムアウトを報告します。 Google検索コンソールでは、これは次の場所にありますCrawl > Crawl Errors, Bingウェブマスターツールでは、以下のようになっていますReports & Data > Crawl Information.
あなたのページが十分に速く読み込まれているかどうかを定期的に確認し、そうでない場合はすぐに行動を起こしてください。
インデックス不可能なページの数が多い
あなたのウェブサイトに検索エンジンにアクセス可能なインデックス不可能なページの数が多い場合、基本的に検索エンジンは無関係なページをふるいにかけることに忙しくしています。
次のタイプは索引付けできないページであると考えています:
- リダイレクト(3xx)
- 見つからないページ(4xx)
- サーバーエラーのあるページ(5xx)
- 索引付けできないページ(robots noindexディレクティブまたは正規URLを含むページ)
インデックスできないページの数が多いかどうかを調べるには、クローラーがあなたのウェブサイト内で見つけたページの総数と、それらがどのように分解されたかを調べます。 ContentKingを使用してこれを簡単に行うことができます:
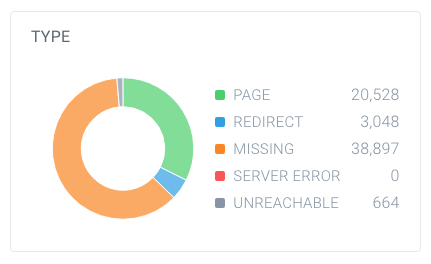
のURLブレークダウンこの例では、63,137個のUrlが見つかりましたが、そのうち20,528個だけがページです。
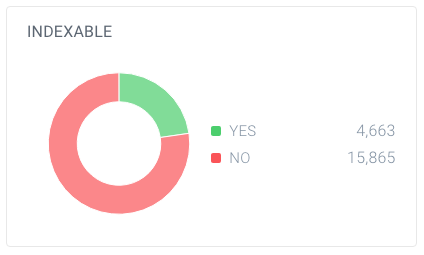
ページの索引性の内訳これらのページのうち、検索エンジンで索引可能なのは4,663ページのみです。 ContentKingによって見つけられるUrlの7.4%だけ調査エンジンによって指示することができる。 それは良い比率ではありません、そして、このウェブサイトは間違いなくそれらへのすべての参照をきれいにすることによってそれに取り組む必:
- XMLサイトマップ(前のセクションを参照)
- リンク
- 正規Url
- Hreflang参照
- ページネーション参照(リンクrel prev/next)
不正な内部リンク構造
ウェブサイト内のページが相互にリンクする方法は、クロール予算の最適化に大きな役割を果たします。 私たちはこれをあなたのウェブサイトの内部リンク構造と呼んでいます。 バックリンクはさておき、いくつかの内部リンクを持っているページは、多くのページにリンクされているページよりも検索エンジンからはるかに
非常に階層的なリンク構造を避け、中央のページにはリンクがほとんどありません。 多くの場合、これらのページは頻繁にクロールされません。 それは階層の底でページのために更に悪い:リンクの限られた量のために、調査エンジンによって非常によく無視されるかもしれない。
あなたの最も重要なページに沢山の内部リンクがあることを確かめなさい。 最近クロールされたページは、通常、検索エンジンでより良いランク付けされます。 これを念頭に置いて、このために内部リンク構造を調整してください。
たとえば、2011年のブログ記事があり、多くのオーガニックトラフィックをドライブしている場合は、他のコンテンツからリンクし続けてください。 あなたは長年にわたって他の多くのブログ記事を制作してきたので、2011年からその記事は自動的にあなたのウェブサイトの内部リンク構造にプッ

通常、重要なページのクロール率について心配する必要はありません。 それは通常、あなたがリンクしていない新しいページであり、人々が頻繁にクロールされないかもしれないことに行っていないページです。
どのようにあなたのウェブサイトのクロールの予算を増やすのですか?
Eric Engeとgoogleの元webspamチームの責任者Matt Cuttsとのインタビュー(新しいタブで開きます)の間に、権限とクロール予算の関係が提起されました:

それについて考える最もよい方法は私達が這うページの数があなたのPageRankに大体比例していることである。 あなたのルートページに着信リンクがたくさんあるのであれば、私たちは間違いなくそれをクロールします。 その後、ルートページは他のページにリンクすることができ、それらはPageRankを取得し、我々は同様にそれらをクロールします。 しかしあなたの場所でより深く、より深く得ると同時にPageRankは低下しがちである。
GoogleはページのPageRank値の更新を公に放棄しましたが、PageRankはまだアルゴリズムで使用されていると考えています(の一形態)。 PageRankは誤解と混乱の用語であるので、のは、ページ権限と呼んでみましょう。 ここでの持ち帰りは、Matt Cuttsが基本的に言っていることです:ページ権限とクロール予算の間にはかなり強い関係があります。
だから、あなたのウェブサイトのクロール予算を増やすためには、あなたのウェブサイトの権限を増やす必要があります。 これの大部分は、外部のウェブサイトからより多くのリンクを獲得することによって行われます。 これについてのより多くの情報は私達のリンク建物ガイドで見つけることができる。

業界がクロール予算について話しているのを聞くと、通常、クロール予算を時間の経過とともに増やすために行うことができるページ上および技術的な変 しかし、リンクの構築の背景から来て、Google Search Consoleで見るクロールされたページの最大のスパイクは、クライアントのために大きなリンクを獲得したときに直接関係しています。
クロール予算に関するよくある質問
- 🧾 クロール予算とは何ですか?
- 🤔クロール予算を増やすにはどうすればよいですか?
- 🎛 ️クロール予算を制限できるのは何ですか?
- 🤖canonical URLとmeta robotsをまったく使用する必要がありますか?
1. ├予算とは?
クロール予算は、検索エンジンが特定の時間枠内にウェブサイト上でクロールするページ数です。
2. ✓クロール予算を増やすにはどうすればよいですか?
Googleは、ページ権限とクロール予算の間に強い関係があることを示しています。 ページの権限が大きいほど、クロールの予算が大きくなります。 簡単に言えば、クロール予算を増やすには、ページの権限を構築します。
3. ✔クロール予算を制限できるものは何ですか?
クロール制限は、クロールホストの負荷とも呼ばれ、ウェブサイトの状態やホスティング能力などの多くの要因に基づいています。 検索エンジンのクローラは、webサーバーの過負荷を防ぐために設定されています。 Webサイトからサーバーエラーが返された場合、または要求されたUrlが頻繁にタイムアウトする場合は、クロールの予算がより制限されます。 同様に、webサイトが共有ホスティングプラットフォーム上で実行されている場合、クロール予算をホスティング上で実行されている他のwebサイトと共
4. 🤖Canonical URLとmeta robotsをまったく使用する必要がありますか?
はい、インデックス作成の問題とクロールの問題の違いを理解することが重要です。
canonical URLタグとmeta robotsタグは、インデックスにどのページを表示すべきかを検索エンジンに明確な信号を送りますが、他のページをクロールすることはできません。
ロボットを使うことができます。クロールの問題に対処するためのtxtファイルとnofollowリンク関係。