
forrás: töltse fel a számítógépes Látásmodelleket a TensorFlow Object Detection API-val,
Jonathan Huang, kutató és Vivek Rathod, szoftvermérnök,
Google AI Blog
- Objektumérzékelés mint feladat a számítógépes látásban
- YOLO mint valós idejű objektumérzékelő
- mi a YOLO?
- YOLO más detektorokhoz képest
- a Yolo
- példák a YOLO alkalmazásokra
- YOLO mint objektumdetektor a TensorFlow-ban & Keras
- TensorFlow & Keras keretek a gépi tanulásban
- YOLO megvalósítás a TensorFlow-ban & Keras
- hogyan kell futtatni előre betanított YOLO out-of-the-box és kap eredmények
- hogyan kell a vonat az egyéni YOLO objektum észlelési modell
- feladat nyilatkozat
- Dataset & annotations
- hol kaphat adatokat
- hogyan jegyezzük fel az adatokat a YOLO-hoz
- hogyan lehet átalakítani az adatokat más formátumokból YOLO
- adatok felosztása részhalmazokra
- Adatgenerátorok létrehozása
- telepítés & beállítás szükséges a modellképzéshez
- modell képzés
- előfeltételek
- Modellobjektum inicializálása
- visszahívások meghatározása
- a modell felszerelése
- betanított egyéni modell következtetési módban
- következtetések
- Anton Morgunov
- TensorFlow Object Detection API: legjobb gyakorlatok a képzéshez, értékeléshez & telepítés
Objektumérzékelés mint feladat a számítógépes látásban
életünk minden nap találkozunk tárgyakkal. Nézz körül, és több tárgyat találsz magad körül. Emberi lényként könnyedén észlelhetsz és azonosíthatsz minden tárgyat, amit látsz. Ez természetes és nem igényel sok erőfeszítést.
számítógépek esetében azonban az objektumok észlelése összetett megoldást igénylő feladat. A számítógép “objektumok észlelése” azt jelenti, hogy feldolgozza a bemeneti képet (vagy egy képkockát egy videóból), és a képen lévő objektumokra és azok helyzetére vonatkozó információkkal válaszol. Számítógépes látás szempontjából ezt a két feladatot osztályozásnak és lokalizációnak nevezzük. Azt akarjuk, hogy a számítógép mondja meg, hogy milyen objektumok jelennek meg egy adott képen, és pontosan hol találhatók.
több megoldást fejlesztettek ki a számítógépek objektumok észlelésére. Ma felfedezzük a Yolo nevű korszerű algoritmust, amely valós idejű sebességgel nagy pontosságot ér el. Különösen megtanuljuk, hogyan kell kiképezni ezt az algoritmust egy egyéni adatkészleten a TensorFlow / Keras alkalmazásban.
először nézzük meg, mi is pontosan a YOLO, és miről híres.
YOLO mint valós idejű objektumérzékelő
mi a YOLO?
a YOLO a “csak egyszer nézel” rövidítése (ne tévessze össze azzal, hogy csak egyszer élsz A Simpson családból). Ahogy a neve is sugallja, egyetlen “pillantás” elegendő ahhoz, hogy megtalálja az összes objektumot a képen, és azonosítsa őket.
gépi tanulás szempontjából azt mondhatjuk, hogy minden objektum egyetlen algoritmus futtatásával detektálható. Ez úgy történik, hogy egy képet rácsra osztunk, és előrejelezzük a határoló négyzeteket és az osztály valószínűségeit a rács minden cellájára. Abban az esetben, ha YOLO-t szeretnénk alkalmazni az autó észlelésére, itt nézhet ki a rács és az előre jelzett határoló dobozok:

határoló doboz YOLO jósolja az első autó piros.
határoló doboz YOLO jósolja a második autó sárga.
a kép forrása.
a fenti kép csak a szűrés után kapott végső dobozkészletet tartalmazza. Érdemes megjegyezni, hogy a YOLO nyers kimenete sok határolódobozt tartalmaz ugyanarra az objektumra. Ezek a dobozok formájukban és méretükben különböznek. Amint az az alábbi képen látható, egyes dobozok jobban meg tudják ragadni a célobjektumot, míg mások, amelyeket egy algoritmus kínál, rosszul teljesítenek.

az összes sárga doboz a második autóra vonatkozik.
a vastag piros és sárga dobozok a legjobbak az autó észleléséhez.
a kép forrása.
egy adott objektumhoz a legjobb határoló doboz kiválasztásához nem maximális elnyomás (NMS) algoritmust kell alkalmazni.

dobozokat, amelyeket az autók előre jeleztek, hogy csak azokat tartsák meg, amelyek a legjobban rögzítik az objektumokat.
a kép forrása.
minden doboz, hogy YOLO jósolja van egy megbízhatósági szint társított őket. Az NMS ezeket a megbízhatósági értékeket használja az alacsony bizonyossággal előre jelzett négyzetek eltávolítására. Általában ezek mind olyan dobozok,amelyeket 0,5 alatti bizalommal jósolnak.

a megbízhatósági pontszámokat minden mező bal felső sarkában, az objektum neve mellett láthatja.
a kép forrása.
az összes bizonytalan határoló doboz eltávolításakor csak a magas megbízhatósági szintű dobozok maradnak. A legjobban teljesítő jelöltek közül a legjobb kiválasztásához az NMS kiválasztja a legmagasabb megbízhatósági szintű mezőt, és kiszámítja, hogyan keresztezi a többi mezőt. Ha egy kereszteződés magasabb, mint egy adott küszöbérték, akkor az alacsonyabb megbízhatóságú határoló doboz eltávolításra kerül. Abban az esetben, ha az NMS összehasonlít két mezőt, amelyek metszéspontja egy kiválasztott küszöb alatt van, mindkét mezőt a végső előrejelzésekben tartják.
YOLO más detektorokhoz képest
bár a Yolo motorháztetője alatt konvolúciós neurális hálót (CNN) használnak, még mindig képes valós idejű teljesítményt észlelni. Ez annak köszönhető, hogy YOLO képes egyszerre elvégezni az előrejelzéseket egylépcsős megközelítésben.
más, lassabb algoritmusok az objektumérzékeléshez (például a gyorsabb R-CNN) általában kétlépcsős megközelítést alkalmaznak:
- az első szakaszban érdekes képrégiók kerülnek kiválasztásra. Ezek a kép azon részei, amelyek bármilyen objektumot tartalmazhatnak;
- a második szakaszban ezeket a régiókat konvolúciós neurális háló segítségével osztályozzák.
általában sok régió van a képen az objektumokkal. Ezeket a régiókat osztályozásra küldik. Az osztályozás időigényes művelet, ezért a kétlépcsős objektum-észlelési megközelítés lassabban működik, mint az egylépcsős észlelés.
a YOLO nem választja ki a kép érdekes részeit, erre nincs szükség. Ehelyett előrejelzi a határolódobozokat és osztályokat az egész kép számára egyetlen előre haladó hálópasszban.
az alábbiakban láthatja, hogy a YOLO milyen gyors a többi népszerű detektorhoz képest.

az SSD és a YOLO egyfokozatú objektumdetektorok, míg a Faster-RCNN
és az R-FCN kétfokozatú objektumdetektorok.
a kép forrása.
a Yolo
verzióit először 2015-ben mutatta be Joseph Redmon “csak egyszer nézel ki: egységes, valós idejű Objektumdetektálás”című kutatási cikkében.
azóta a YOLO sokat fejlődött. 2016-ban Joseph Redmon leírta a második YOLO verziót a “YOLO 9000: jobb, gyorsabb, erősebb”részben.
körülbelül két évvel a második YOLO frissítés után Joseph újabb nettó frissítéssel állt elő. “YOLOv3: inkrementális fejlesztés” című tanulmánya sok számítógépes mérnök figyelmét felkeltette, és népszerűvé vált a gépi tanulási közösségben.
2020-ban Joseph Redmon úgy döntött, hogy abbahagyja a számítógépes látás kutatását, de ez nem akadályozta meg a YOLO-t abban, hogy mások fejlesszék. Ugyanebben az évben egy három mérnökből álló csapat (Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao) megtervezte a Yolo negyedik változatát, még gyorsabb és pontosabb, mint korábban. Eredményeiket a ” YOLOv4: Az Objektumérzékelés optimális sebessége és pontossága ” című cikk, amelyet 23.április 2020-án tettek közzé.
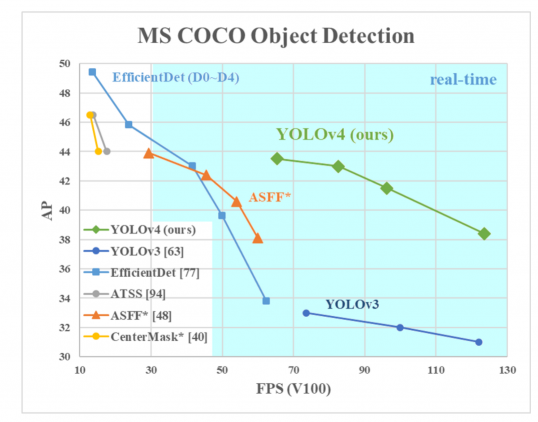
AP az Y tengelyen egy “átlagos pontosság”nevű mutató. Leírja a háló pontosságát.
FPS (képkocka másodpercenként) az X tengelyen egy mutató, amely leírja a sebességet.
a kép forrása.
két hónappal a 4. verzió megjelenése után egy független fejlesztő, Glenn Jocher bejelentette a YOLO 5.verzióját. Ezúttal nem publikáltak kutatási anyagot. A net elérhetővé vált Jocher GitHub oldalán PyTorch megvalósításként. Az ötödik változat nagyjából ugyanolyan pontosságú volt, mint a negyedik változat, de gyorsabb volt.
végül 2020 júliusában újabb nagy YOLO frissítést kaptunk. A “PP-YOLO: an Effective and effective Implementation of Object Detector” című tanulmányban Xiang Long és csapata a YOLO új verziójával állt elő. A YOLO ezen iterációja a 3. modellverzión alapult, és meghaladta a YOLO v4 teljesítményét.

az Y tengelyen lévő térkép egy “átlagos átlagos pontosság”nevű mutató. Leírja a háló pontosságát.
FPS (képkocka másodpercenként) az X tengelyen egy mutató, amely leírja a sebességet.
a kép forrása.
ebben az oktatóanyagban közelebbről megvizsgáljuk a YOLOv4-et és annak végrehajtását. Miért YOLOv4? Három ok:
- széles körű jóváhagyással rendelkezik a gépi tanulási közösségben;
- ez a verzió az észlelési feladatok széles körében bizonyította nagy teljesítményét;
- a YOLOv4-et számos népszerű keretrendszerben implementálták, beleértve a TensorFlow-t és a Keras-t, amelyekkel együtt fogunk dolgozni.
példák a YOLO alkalmazásokra
mielőtt továbblépnénk a cikk gyakorlati részéhez, az egyéni YOLO alapú objektumdetektorunk megvalósításához, szeretnék bemutatni néhány hűvös YOLOv4 megvalósítást, majd végrehajtjuk a megvalósításunkat.
Figyeljetek arra, hogy milyen gyorsak és pontosak az előrejelzések!
íme az első lenyűgöző példa arra, hogy a YOLOv4 mire képes, több objektum észlelésére különböző játék-és filmjelenetekből.
Alternatív megoldásként ellenőrizheti ezt az objektum-észlelési bemutatót egy valós kamera nézetből.
YOLO mint objektumdetektor a TensorFlow-ban & Keras
TensorFlow & Keras keretek a gépi tanulásban

a kép forrása.
a keretrendszerek minden informatikai területen elengedhetetlenek. A gépi tanulás sem kivétel. Az ML piacon számos olyan szereplő van, amelyek segítenek egyszerűsíteni az általános programozási élményt. A PyTorch, a scikit-learn, a TensorFlow, a Keras, az MXNet és a Caffe csak néhány említésre méltó.
ma szorosan együttműködünk a TensorFlow/Keras-szal. Nem meglepő, hogy ez a kettő a gépi tanulási univerzum legnépszerűbb keretrendszerei közé tartozik. Ez nagyrészt annak köszönhető, hogy mind a TensorFlow, mind a Keras gazdag fejlesztési képességeket kínál. Ez a két keret nagyon hasonlít egymásra. Anélkül, hogy túl sokat ásnánk a részletekbe, a legfontosabb dolog, hogy emlékezzünk arra, hogy a Keras csak a TensorFlow keretrendszer burkolója.
YOLO megvalósítás a TensorFlow-ban & Keras
a cikk írásakor 808 tároló volt YOLO implementációkkal egy TensorFlow / Keras háttéren. A YOLO 4-es verziója az, amit végre fogunk hajtani. A keresés korlátozása csak a YOLO v4-re, kaptam 55 tárolók.
gondosan böngészve mindegyiket, találtam egy érdekes jelöltet, akivel folytathatom.
a kép forrása.
ezt a megvalósítást a taipingeric és a jimmyaspire fejlesztette ki. Nagyon egyszerű és nagyon intuitív, ha korábban már dolgozott a TensorFlow-val és a Keras-szal.
a megvalósítás megkezdéséhez csak klónozza a repót a helyi gépre. Ezután megmutatom, hogyan kell használni a Yolo-t a dobozból, és hogyan kell kiképezni a saját egyedi objektumérzékelőjét.
hogyan kell futtatni előre betanított YOLO out-of-the-box és kap eredmények
nézzük a” Gyors indítás ” részben a repo, akkor láthatjuk, hogy kap egy modell fel és fut, csak meg kell importálni YOLO, mint egy osztály objektum és terhelés a modell súlyok:
from models import Yolov4model = Yolov4(weight_path='yolov4.weights', class_name_path='class_names/coco_classes.txt')
ne feledje, hogy előzetesen manuálisan kell letöltenie a modell súlyait. A YOLO-hoz mellékelt modell súlyok fájl a COCO adatkészletből származik, és elérhető az AlexeyAB hivatalos darknet projekt oldalán a GitHub-on. A súlyokat közvetlenül ezen a linken keresztül töltheti le.
közvetlenül ezután a modell teljesen készen áll a képekkel való munkára következtetési módban. Csak használja a predict () módszert egy választott képhez. A módszer standard a TensorFlow és Keras keretrendszerekhez.
pred = model.predict('input.jpg')
például ehhez a bemeneti képhez:

a következő modell kimenetet kaptam:

a modell előrejelzéseit a pandas DataFrame kényelmes formájában adják vissza. Megkapjuk az osztály nevét, a doboz méretét és a koordinátákat minden észlelt objektumhoz:

sok hasznos információ Az észlelt objektumokról
a predict() metóduson belül több paraméter is van, amelyek megadják, hogy meg akarjuk-e ábrázolni a képet az előre jelzett határoló dobozokkal, az egyes objektumok szöveges nevével stb. Nézze meg a docstring, hogy megy együtt a predict () módszer, hogy megismerjék, mi áll rendelkezésünkre:

arra számíthat, hogy a modell csak olyan objektumtípusokat képes felismerni, amelyek szigorúan a COCO adatkészletre korlátozódnak. Ha meg szeretné tudni, hogy egy előre kiképzett YOLO modell milyen objektumtípusokat képes felismerni, nézze meg a coco_classes oldalt.txt fájl elérhető …/yolo-v4-tf.kers/class_names/. 80 objektumtípus van benne.
hogyan kell a vonat az egyéni YOLO objektum észlelési modell
feladat nyilatkozat

objektum-észlelési modell tervezéséhez tudnia kell, hogy milyen objektumtípusokat szeretne észlelni. Ennek korlátozott számú objektumtípusnak kell lennie, amelyekhez az érzékelőt létre szeretné hozni. Jó, ha elkészítjük az Objektumtípusok listáját, amikor áttérünk a tényleges modellfejlesztésre.
ideális esetben rendelkeznie kell egy jegyzetekkel ellátott adatkészlettel is, amely érdekes objektumokat tartalmaz. Ezt az adatkészletet fogják használni a detektor betanításához és érvényesítéséhez. Ha még nincs hozzá adatkészlet vagy kommentár, ne aggódjon, megmutatom, hol és hogyan szerezheti be.
Dataset & annotations
hol kaphat adatokat
ha van egy jegyzetekkel ellátott adatkészlet dolgozni, csak hagyja ki ezt a részt, és lépjen a következő fejezetre. De, ha szüksége van egy adatkészletre a projektjéhez, most online forrásokat fogunk felfedezni, ahol adatokat szerezhet.
nem igazán számít, hogy milyen területen dolgozik, nagy esély van arra, hogy már van egy nyílt forráskódú adatkészlet, amelyet felhasználhat a projektjéhez.
az első forrás, amelyet ajánlok, Abhishek Annamraju “50+ objektum-észlelési adatkészlet különböző ipari területekről” cikke, aki csodálatos jegyzetekkel ellátott adatkészleteket gyűjtött olyan iparágak számára, mint a divat, a kiskereskedelem, a sport, az orvostudomány és még sok más.

a kép forrása.
további két nagyszerű hely az adatok keresésére paperswithcode.com és roboflow.com amelyek hozzáférést biztosítanak a kiváló minőségű adatkészletekhez az objektumok észleléséhez.
nézze meg ezeket a fenti eszközöket, hogy összegyűjtse a szükséges adatokat, vagy gazdagítsa a már meglévő adatkészletet.
hogyan jegyezzük fel az adatokat a YOLO-hoz
ha a képek adatkészlete megjegyzések nélkül érkezik, akkor magának kell elvégeznie az annotációs munkát. Ez a kézi művelet meglehetősen időigényes, ezért győződjön meg róla, hogy elegendő ideje van erre.
mint annotációs eszköz, több lehetőséget is figyelembe vehet. Személy szerint a LabelImg használatát javasolnám. Ez egy könnyű és könnyen használható kép annotációs eszköz, amely közvetlenül kimeneti kommentárokat YOLO modellek.
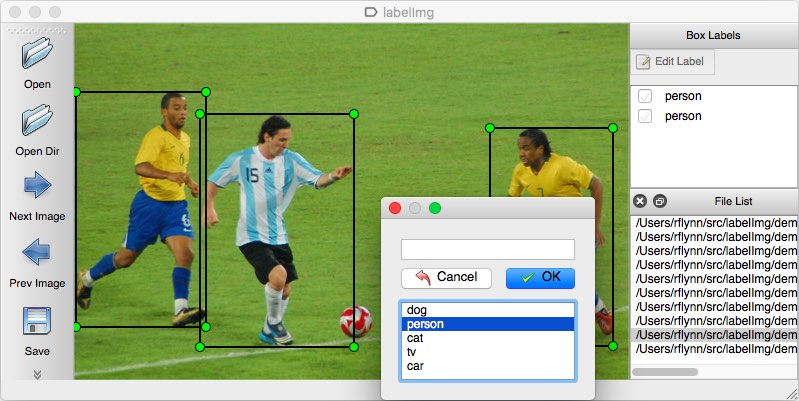
a kép forrása.
hogyan lehet átalakítani az adatokat más formátumokból YOLO
a YOLO megjegyzései txt fájlok formájában vannak. A txt fájl fol YOLO minden sorának a következő formátumúnak kell lennie:
image1.jpg 10,15,345,284,0image2.jpg 100,94,613,814,0 31,420,220,540,1
mi lehet szakítani minden sort a TXT fájlt, hogy mit tartalmaz:
- a sor első része a képek alapneveit adja meg: image1.jpg, kép2.jpg
- a sor második része meghatározza a határoló doboz koordinátáit és az osztálycímkét. Például 10,15,345,284,0 állapotok az xmin,ymin, xmax, ymax, class_id
- ha egy adott képen egynél több objektum van, akkor a kép alapneve mellett több doboz és osztálycímke lesz, szóközzel osztva.
a határoló doboz koordinátái egyértelmű fogalom, de mi a helyzet a class_id számmal, amely meghatározza az osztálycímkét? Minden class_id egy adott osztályhoz kapcsolódik egy másik txt fájlban. Például, előre képzett YOLO jön a coco_classes.txt fájl, amely így néz ki:
personbicyclecarmotorbikeaeroplanebus...
az osztályfájlok sorainak számának meg kell egyeznie az érzékelő által észlelni kívánt osztályok számával. A számozás nulláról indul, ami azt jelenti, hogy a class_id szám az osztályok fájl első osztályának 0 lesz. Osztály kerül a második sorban az osztályok txt fájl lesz az 1. szám.
most már tudod, hogy néz ki a Yolo kommentárja. Az egyéni objektumdetektor létrehozásának folytatásához arra kérem, hogy most két dolgot tegyen:
- hozzon létre egy osztályok txt fájlt, ahol palota az osztályok, hogy szeretné, hogy a detektor felismerni. Ne feledje, hogy az osztályrend számít.
- hozzon létre egy TXT fájlt kommentárokkal. Abban az esetben, ha már van kommentárja, de VOC formátumban (.XMLs), akkor használja ezt a fájlt átalakítani XML YOLO.
adatok felosztása részhalmazokra
mint mindig, az adatkészletet 2 részhalmazra szeretnénk felosztani: képzés és érvényesítés céljából. Meg lehet csinálni olyan egyszerű, mint:
from utils import read_annotation_lines train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1)
Adatgenerátorok létrehozása
amikor az adatok fel vannak osztva, folytathatjuk az adatgenerátor inicializálását. Minden adatfájlhoz lesz egy adatgenerátorunk. A mi esetünkben lesz egy generátorunk a képzési részhalmazhoz és a validációs részhalmazhoz.
így jönnek létre az adatgenerátorok:
from utils import DataGenerator FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
összefoglalva mindent, így néz ki az adatfelosztás és a generátor létrehozásának teljes kódja:
from utils import read_annotation_lines, DataGenerator train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1) FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
telepítés & beállítás szükséges a modellképzéshez
beszéljünk azokról az előfeltételekről, amelyek elengedhetetlenek a saját objektumdetektor létrehozásához:
- a Pythonnak már telepítve kell lennie a számítógépére. Abban az esetben, ha telepítenie kell, azt javaslom, hogy kövesse az Anaconda hivatalos útmutatóját;
- ha a számítógép rendelkezik CUDA-kompatibilis GPU-val (az NVIDIA által készített GPU), akkor néhány releváns könyvtárra van szükség a GPU-alapú képzés támogatásához. Abban az esetben, ha engedélyeznie kell a GPU támogatását, ellenőrizze az NVIDIA webhelyén található irányelveket. A cél az, hogy telepítse mind a CUDA eszközkészlet, mind a cudnn legújabb verzióját az operációs rendszeréhez;
- érdemes megszervezni egy független virtuális környezetet a munkához. Ehhez a projekthez a TensorFlow 2 telepítése szükséges. Az összes többi könyvtár később kerül bevezetésre;
- ami engem illet, a Yolov4 modellemet egy Jupyter Notebook fejlesztői környezetben építettem és tanítottam. Bár a Jupyter Notebook ésszerű lehetőségnek tűnik, fontolja meg a fejlesztést egy választott IDE-ben, ha akarja.
modell képzés

előfeltételek
mostanra meg kellett volna:
- az adatkészlet felosztása;
- két adatgenerátor inicializálva;
- egy TXT fájl az osztályokkal.
Modellobjektum inicializálása
a képzési munkára való felkészüléshez inicializálja a YOLOv4 modellobjektumot. Győződjön meg arról, hogy a Nincs értéket használja a weight_path paraméter értékeként. Ebben a lépésben meg kell adnia az osztályok txt fájljának elérési útját is. Itt van az inicializálási kód, amelyet a projektemben használtam:
class_name_path = 'path2project_folder/model_data/scans_file.txt' model = Yolov4(weight_path=None, class_name_path=class_name_path)
a fenti modell inicializálása egy modellobjektum létrehozásához vezet alapértelmezett paraméterkészlettel. Fontolja meg a modell konfigurációjának megváltoztatását úgy, hogy egy szótárban értéket ad át a config model paraméternek.

Config meghatározza a yolov4 modell paramétereit.
Az alapértelmezett modellkonfiguráció jó kiindulópont, de érdemes lehet kísérletezni más konfigurációkkal a jobb modellminőség érdekében.
különösen ajánlom a horgonyok és az img_size kísérletezését. Horgonyok adja meg az objektumok rögzítéséhez használt horgonyok geometriáját. Minél jobban illeszkednek a horgonyok alakjai az objektumok alakzataihoz, annál nagyobb lesz a modell teljesítménye.
az img_size Növelése bizonyos esetekben szintén hasznos lehet. Ne feledje, hogy minél magasabb a kép, annál hosszabb lesz a modell következtetése.
abban az esetben, ha a Neptune-t nyomkövető eszközként szeretné használni, inicializálnia kell egy kísérlet futtatását is, mint ez:
import neptune.new as neptune run = neptune.init(project='projects/my_project', api_token=my_token)
visszahívások meghatározása
TensorFlow & Keras a visszahívásokat használjuk az edzés előrehaladásának figyelemmel kísérésére, ellenőrző pontok létrehozására és az edzésparaméterek (pl. tanulási Arány) kezelésére.
a modell felszerelése előtt határozza meg a visszahívásokat, amelyek hasznosak lehetnek az Ön céljaihoz. Győződjön meg róla, hogy megadja a modellellenőrző pontok és a kapcsolódó naplók tárolásához szükséges útvonalakat. Így csináltam az egyik projektemben:
# defining pathes and callbacks dir4saving = 'path2checkpoint/checkpoints'os.makedirs(dir4saving, exist_ok = True) logdir = 'path4logdir/logs'os.makedirs(logdir, exist_ok = True) name4saving = 'epoch_{epoch:02d}-val_loss-{val_loss:.4f}.hdf5' filepath = os.path.join(dir4saving, name4saving) rLrCallBack = keras.callbacks.ReduceLROnPlateau(monitor = 'val_loss', factor = 0.1, patience = 5, verbose = 1) tbCallBack = keras.callbacks.TensorBoard(log_dir = logdir, histogram_freq = 0, write_graph = False, write_images = False) mcCallBack_loss = keras.callbacks.ModelCheckpoint(filepath, monitor = 'val_loss', verbose = 1, save_best_only = True, save_weights_only = False, mode = 'auto', period = 1)esCallBack = keras.callbacks.EarlyStopping(monitor = 'val_loss', mode = 'min', verbose = 1, patience = 10)
észrevehette volna, hogy a fenti visszahívási készletben a TensorBoard nyomkövető eszközként szolgál. Fontolja meg a Neptunusz használatát sokkal fejlettebb eszközként a kísérletkövetéshez. Ha igen, ne felejtsen el inicializálni egy újabb visszahívást, hogy lehetővé tegye az integrációt a Neptunusszal:
from neptune.new.integrations.tensorflow_keras import NeptuneCallback neptune_cbk = NeptuneCallback(run=run, base_namespace='metrics')
a modell felszerelése
a képzési feladat elindításához egyszerűen illessze be a modellobjektumot a TensorFlow / Keras standard fit() módszerével. Így kezdtem el edzeni a modellemet:
model.fit(data_gen_train, initial_epoch=0, epochs=10000, val_data_gen=data_gen_val, callbacks= )
amikor a képzés elindul, megjelenik egy szabványos folyamatjelző sáv.

a képzési folyamat minden korszak végén értékeli a modellt. Ha olyan visszahívásokat használ, amelyek hasonlóak ahhoz, amit inicializáltam és átadtam a felszerelés során, akkor azok az ellenőrző pontok, amelyek a modell javulását mutatják az alacsonyabb veszteség szempontjából, egy megadott könyvtárba kerülnek.
ha nem történik hiba, és a képzési folyamat zökkenőmentesen megy, a képzési feladat leáll vagy a képzési korszakok számának vége miatt, vagy ha a korai leállítási visszahívás nem észlel további modelljavítást, és leállítja a teljes folyamatot.
mindenesetre több modell ellenőrző pontot kell elérnie. Azt akarjuk, hogy válassza ki a legjobb az összes rendelkezésre álló is, és használja azt a következtetést.
betanított egyéni modell következtetési módban
betanított modell következtetési módban történő futtatása hasonló az előre betanított modell dobozból történő futtatásához.

inicializálja a modell objektum halad az utat a legjobb ellenőrzőpont, valamint az utat a txt fájlt az osztályok. Így néz ki a modell inicializálása a projektemben:
from models import Yolov4model = Yolov4(weight_path='path2checkpoint/checkpoints/epoch_48-val_loss-0.061.hdf5', class_name_path='path2classes_file/my_yolo_classes.txt')
a modell inicializálásakor egyszerűen használja a predict() módszert egy választott képhez, hogy megkapja az előrejelzéseket. Összefoglalva, a modell által készített észleléseket a pandas DataFrame kényelmes formájában adják vissza. Megkapjuk az osztály nevét, a doboz méretét és a koordinátákat minden észlelt objektumhoz.
következtetések
most tanulta meg, hogyan hozhat létre egyéni YOLOv4 objektumérzékelőt. Végigmentünk a végpontok közötti folyamaton, kezdve az adatgyűjtéstől, az annotálástól és az átalakítástól. Elegendő ismerete van a negyedik YOLO verzióról és arról, hogy miben különbözik a többi detektortól.
semmi sem akadályozza meg Önt abban, hogy saját modelljét betanítsa a TensorFlow-ban és a Keras-ban. Tudod, honnan szerezz egy előre kiképzett modellt, és hogyan kezdd el a képzési munkát.
a következő cikkemben bemutatok néhány bevált gyakorlatot és életfeltörést, amelyek segítenek javítani a végső modell minőségét. Maradj velünk!



Anton Morgunov
számítógépes Látásmérnök a Basis-nél.Központ
Gépi tanulás rajongó. Szenvedélyes a számítógépes látás iránt. Nincs papír – több fa! A papírmásolás megszüntetése a teljes digitalizációra való áttéréssel!
olvassa tovább
TensorFlow Object Detection API: legjobb gyakorlatok a képzéshez, értékeléshez & telepítés
13 perc olvasás | szerző Anton Morgunov | Frissítve május 28th, 2021
ez a cikk egy sorozat második része, ahol a TensorFlow Object Detection és API-jának végponttól végpontig tartó munkafolyamatát tanulhatja meg. Az első cikkben megtanultad, hogyan lehet a semmiből létrehozni egy egyedi objektumérzékelőt, de még mindig rengeteg olyan dolog van, amelyre figyelmet kell fordítani, hogy valóban jártas legyen.
olyan témákat fogunk feltárni, amelyek ugyanolyan fontosak, mint a már átélt modellalkotási folyamat. Íme néhány kérdés, amelyet megválaszolunk:
- hogyan értékeljem a modellemet és becsüljem meg a teljesítményét?
- milyen eszközöket használhatok a modell teljesítményének nyomon követésére és az eredmények összehasonlítására több kísérlet során?
- hogyan exportálhatom a modellemet, hogy következtetési módban használjam?
- van mód a modell teljesítményének még nagyobb növelésére?
olvasson tovább ->