
lähde: Supercharge your Computer Vision models with the Tensorflow Object Detection API,
Jonathan Huang, tutkija ja Vivek Rathod, ohjelmistoinsinööri,
Google AI Blog
- objektien havaitseminen Tietokonenäön tehtävänä
- YOLO reaaliaikaisena olionilmaisimena
- mikä on YOLO?
- YOLO verrattuna muihin ilmaisimiin
- versiot YOLOSTA
- esimerkkejä YOLO-sovelluksista
- YOLO olionilmaisimena Tensorflow ’ ssa & Keras
- Tensorflow & Keras frameworks Koneoppimisessa
- YOLO-toteutus TensorFlow ’ ssa & Keras
- miten ajaa esikoulutettua YOLOA ulos laatikosta ja saada tuloksia
- näin harjoittelet mukautettua YOLO-objektin tunnistusmallia
- Tehtävälauseke
- tietokokonaisuus & selitykset
- mistä saat tietoja
- miten Yolo
- kuinka muuntaa tietoja muista formaateista YOLO
- tietojen jakaminen osajoukkoihin
- luodaan datageneraattoreita
- asennus & mallikoulutuksen vaatimat asetukset
- Mallikoulutus
- Edeltävät opinnot
- Model object initialization
- määrittelemällä callbacks
- mallin
- koulutettu custom-malli päättelytilassa
- päätelmät
- Anton Morgunov
- TensorFlow Object Detection API: Best Practices to Training, Evaluation & Deployment
objektien havaitseminen Tietokonenäön tehtävänä
kohtaamme esineitä joka päivä elämässämme. Katso ympärillesi, ja löydät useita esineitä ympärilläsi. Ihmisenä voit helposti havaita ja tunnistaa jokaisen näkemäsi kohteen. Se on luonnollista eikä vaadi paljon vaivaa.
tietokoneille kohteiden havaitseminen on kuitenkin tehtävä, johon tarvitaan monimutkainen ratkaisu. Tietokoneen ”objektien havaitseminen” tarkoittaa syötekuvan (tai yksittäisen kuvan käsittelyä videolta) ja tiedon antamista kuvan kohteista ja niiden sijainnista. Tietokoneen visio termit, kutsumme näitä kahta tehtävää luokittelu ja lokalisointi. Haluamme tietokoneen sanovan, millaisia esineitä tietyssä kuvassa esitetään ja missä ne tarkalleen sijaitsevat.
on kehitetty useita ratkaisuja, joiden avulla tietokoneet tunnistavat kohteita. Tänään tutkimme huippumodernia algoritmia nimeltä YOLO, joka saavuttaa korkean tarkkuuden reaaliaikaisella nopeudella. Erityisesti, opimme kouluttaa tämän algoritmin mukautetun aineiston TensorFlow / Keras.
katsotaan ensin, mikä YOLO tarkalleen ottaen on ja mistä se on kuuluisa.
YOLO reaaliaikaisena olionilmaisimena
mikä on YOLO?
YOLO on lyhenne sanoista” You Only Look Once ”(don ’ t confuse it with You Only Live Once from The Simpsons). Kuten nimestä voi päätellä, yksi ”look” riittää kaikkien objektien löytämiseen kuvasta ja niiden tunnistamiseen.
koneoppimisen termein voidaan sanoa, että kaikki oliot havaitaan yhden algoritmin avulla. Se tehdään jakamalla kuva ruudukkoon ja ennustamalla rajauslaatikot ja luokkatodennäköisyydet jokaiselle ruudukon solulle. Jos haluamme palkata YOLON autojen tunnistamiseen, – tältä ruudukko ja ennustetut rajauslaatikot voivat näyttää.:

Bounding box, jonka YOLO ennustaa ensimmäisen auton olevan punainen.
Bounding box, jonka YOLO ennustaa toiselle autolle, on keltainen.
Kuvan lähde.
yllä oleva kuva sisältää vain suodatuksen jälkeen saadut viimeiset laatikot. On syytä huomata, että YOLON raaka-ulostulo sisältää monta rajauslaatikkoa samalle kohteelle. Nämä laatikot eroavat muodoltaan ja kooltaan. Kuten näette kuvan alla, jotkut laatikot ovat parempia syömällä kohde objekti, kun taas toiset tarjoamat algoritmi suorittaa huonosti.

kaikki keltaiset laatikot ovat toista autoa varten.
lihavoidut punaiset ja keltaiset laatikot ovat parhaita autojen tunnistamiseen.
Kuvan lähde.
parhaan rajausruudun valitsemiseksi tietylle kohteelle käytetään non-maximum suppression (NMS) algoritmia.

laatikot ennustetaan autojen pitää vain ne, jotka parhaiten talteen esineitä.
Kuvan lähde.
kaikkiin YOLON ennustamiin ruutuihin liittyy luottamustaso. NMS käyttää näitä luottamusarvoja poistaakseen heikolla varmuudella ennustetut laatikot. Yleensä nämä ovat kaikki ruutuja, joita ennustetaan alle 0,5: n varmuudella.

voit nähdä luotettavuuspisteet jokaisen ruudun vasemmassa yläkulmassa kohteen nimen vieressä.
Kuvan lähde.
kun kaikki epävarmat rajauslaatikot poistetaan, jäljelle jäävät vain laatikot, joilla on korkea luotettavuustaso. Valitakseen parhaiten menestyneiden ehdokkaiden joukosta parhaan, NMS valitsee laatikon, jolla on korkein luottamustaso ja laskee, miten se risteää muiden ympärillä olevien laatikoiden kanssa. Jos leikkauspiste on korkeampi kuin tietty kynnysarvo, rajauslaatikko, jolla on pienempi luottamus, poistetaan. Jos NMS vertaa kahta ruutua, joiden leikkauspiste on valitun kynnysarvon alapuolella, molemmat laatikot pidetään lopullisissa ennusteissa.
YOLO verrattuna muihin ilmaisimiin
vaikka yolon hupun alla käytetään convolutionaalista neuroverkkoa (CNN), se pystyy silti havaitsemaan kohteita reaaliaikaisella suorituskyvyllä. Se on mahdollista, koska YOLO pystyy tekemään ennustukset samanaikaisesti yksivaiheisesti.
muut, hitaammat algoritmit objektin havaitsemiseen (kuten nopeampi R-CNN) käyttävät tyypillisesti kaksivaiheista lähestymistapaa:
- ensimmäisessä vaiheessa valitaan mielenkiintoisia kuva-alueita. Nämä ovat kuvan osia, jotka saattavat sisältää mitä tahansa kohteita;
- toisessa vaiheessa jokainen näistä alueista luokitellaan konvolutionaarisen neuroverkon avulla.
yleensä on monia alueita kuvan esineitä. Kaikki nämä alueet lähetetään luokitukseen. Luokittelu on aikaa vievä operaatio,minkä vuoksi kaksivaiheinen objektin tunnistusmenetelmä toimii hitaammin kuin yksivaiheinen tunnistus.
YOLO ei valitse kuvan kiinnostavia osia, siihen ei ole tarvetta. Sen sijaan se ennustaa bounding laatikot ja luokat koko kuvan yhden eteenpäin net pass.
alta näet, kuinka nopea YOLO on muihin suosittuihin ilmaisimiin verrattuna.

SSD ja YOLO ovat yksivaiheisia objekti-ilmaisimia, kun taas Faster-RCNN
ja R-FCN ovat kaksivaiheisia objekti-ilmaisimia.
Kuvan lähde.
versiot YOLOSTA
Yolo esitteli ensimmäisen kerran vuonna 2015 Joseph Redmon tutkimuspaperissaan ”You Only Look Once: Unified, Real-Time Object Detection”.
sen jälkeen YOLO on kehittynyt paljon. Vuonna 2016 Joseph Redmon kuvasi toisen YOLO-version elokuvassa ”YOLO9000: Better, Faster, Stronger”.
noin kaksi vuotta toisen YOLO-päivityksen jälkeen Joseph keksi toisen nettipäivityksen. Hänen tutkielmansa nimeltä ”YOLOv3: an Incremental Improvement” kiinnitti monien tietokoneinsinöörien huomion ja siitä tuli suosittu koneoppimisyhteisössä.
vuonna 2020 Joseph Redmon päätti lopettaa tietokonenäön tutkimisen, mutta se ei estänyt YOLOA kehittämästä muita. Samana vuonna kolmen insinöörin ryhmä (Aleksei Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao) suunnitteli YOLON neljännen version, joka oli vielä nopeampi ja tarkempi kuin ennen. Heidän löytönsä on kuvattu ”YOLOv4: Optimal Speed and Accuracy of Object Detection ” paper they published on April 23rd, 2020.
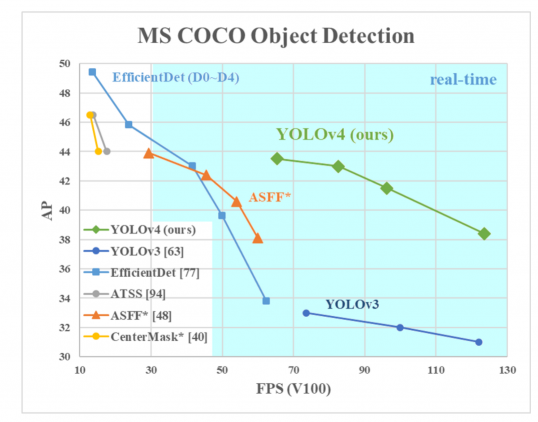
AP Y-akselilla on metriikka, jota kutsutaan ”keskimääräiseksi tarkkuudeksi”. Se kuvaa verkon tarkkuutta.
FPS (ruutua sekunnissa) X-akselilla on nopeutta kuvaava metriikka.
Kuvan lähde.
kaksi kuukautta julkaisun jälkeen 4. versio, riippumaton kehittäjä, Glenn Jocher, ilmoitti 5. versio YOLO. Tällä kertaa tutkimuspaperia ei julkaistu. Verkko tuli saataville Jocherin GitHub-sivulle Pytorchin toteutuksena. Viidennen version tarkkuus oli suurin piirtein sama kuin neljännen, mutta se oli nopeampi.
heinäkuussa 2020 saimme jälleen ison YOLO-päivityksen. Tutkielmassa ”PP-YOLO: an Effective and effective Implementation of Object Detector” Xiang Long ja tiimi keksivät uuden version YOLOSTA. Tämä YOLON iterointi perustui 3. malliversioon ja ylitti Yolo v4: n suorituskyvyn.

y-akselin kartta on metriikka, jota kutsutaan ”keskiarvotarkkuudeksi”. Se kuvaa verkon tarkkuutta.
FPS (ruutua sekunnissa) X-akselilla on nopeutta kuvaava metriikka.
Kuvan lähde.
tässä opetusohjelmassa aiomme tarkastella lähemmin YOLOv4: ää ja sen täytäntöönpanoa. Miksi YOLOv4? Kolme syytä:
- sillä on laaja hyväksyntä koneoppimisyhteisössä;
- tämä versio on osoittautunut tehokkaaksi monenlaisissa tunnistustehtävissä;
- YOLOv4 on toteutettu useissa suosituissa kehyksissä, muun muassa TensorFlow ’ ssa ja Kerasissa.
esimerkkejä YOLO-sovelluksista
ennen kuin siirrymme tämän artikkelin käytännön osaan, toteuttamaan mukautetun YOLO – pohjaisen olionilmaisimen, haluaisin näyttää pari siistiä YOLOv4-toteutusta, ja sitten teemme toteutuksemme.
kiinnitä huomiota siihen, kuinka nopeita ja tarkkoja ennustukset ovat!
tässä ensimmäinen vaikuttava esimerkki siitä, mitä YOLOv4 voi tehdä, havaitsemalla useita esineitä eri peli-ja elokuvakohtauksista.
Vaihtoehtoisesti voit tarkistaa tämän objektin tunnistusdemon tosielämän kameranäkymästä.
YOLO olionilmaisimena Tensorflow ’ ssa & Keras
Tensorflow & Keras frameworks Koneoppimisessa

Kuvan lähde.
puitteet ovat olennaisia kaikilla tietotekniikan osa-alueilla. Koneoppiminen ei ole poikkeus. ML-markkinoilla on useita vakiintuneita toimijoita, jotka auttavat meitä yksinkertaistamaan yleistä ohjelmointikokemusta. PyTorch, scikit-learn, TensorFlow, Keras, MXNet ja Caffe ovat vain muutamia mainitsemisen arvoisia.
tänään teemme tiivistä yhteistyötä TensorFlow / Kerasin kanssa. Ei ole yllättävää, että nämä kaksi ovat koneoppimisen universumin suosituimpia kehyksiä. Se johtuu pitkälti siitä, että sekä TensorFlow että Keras tarjoavat runsaasti kehitysominaisuuksia. Nämä kaksi kehystä ovat melko samanlaisia keskenään. Kaivamatta liikaa yksityiskohtiin on tärkeää muistaa, että Keras on vain TensorFlow-kehyksen kääre.
YOLO-toteutus TensorFlow ’ ssa & Keras
tätä artikkelia kirjoitettaessa TensorFlow / Keras-taustaosalla oli 808 Yolo-toteutusta sisältävää arkistoa. YOLO versio 4 on mitä aiomme toteuttaa. Rajoittaen etsinnän vain YOLO v4: ään, minulla on 55 arkistoa.
selaillessani niitä kaikkia huolellisesti löysin mielenkiintoisen ehdokkaan, jonka kanssa jatkaa.
Kuvan lähde.
tämän toteutuksen kehittivät taipingeric ja jimmyaspire. Se on melko yksinkertainen ja hyvin intuitiivinen, jos olet työskennellyt TensorFlow ’ n ja Kerasin kanssa aiemmin.
aloittaaksesi tämän toteutuksen työstämisen, kloonaa repo paikalliseen koneeseesi. Seuraavaksi näytän, miten YOLOA käytetään kättelyssä ja miten oma mukautettu objektinilmaisin koulutetaan.
miten ajaa esikoulutettua YOLOA ulos laatikosta ja saada tuloksia
kun katsoo Repon ”Quick Start” – osiota, huomaa, että saadaksemme mallin käyntiin, meidän täytyy vain tuoda YOLO luokan objektina ja ladata mallin painot:
from models import Yolov4model = Yolov4(weight_path='yolov4.weights', class_name_path='class_names/coco_classes.txt')
huomaa, että sinun täytyy ladata mallin painot manuaalisesti etukäteen. Yolon mukana tuleva model weights-tiedosto tulee COCO-aineistosta ja se on saatavilla Alexeyabin virallisella darknet-projektisivulla GitHubissa. Voit ladata painot suoraan tästä linkistä.
heti sen jälkeen malli on täysin valmis työskentelemään kuvien kanssa päättelytilassa. Käytä vain ennustus () – menetelmää valitsemaasi kuvaan. Menetelmä on standardi TensorFlow-ja Keras-kehyksille.
pred = model.predict('input.jpg')
esimerkiksi tälle syötekuvalle:

sain seuraavan mallin ulostulon:

ennustukset, että tehty malli palautetaan sopivassa muodossa pandas-DataFrame. Saamme luokan nimen, laatikon koon ja koordinaatit jokaiselle havaitulle kohteelle:

paljon hyödyllistä tietoa havaituista kohteista
predict () – menetelmässä on useita parametreja, joiden avulla voimme määrittää, haluammeko piirtää kuvan ennustetuilla rajausruuduilla, tekstimuotoisilla nimillä jokaiselle kohteelle jne. Tutustu docstring, joka menee yhdessä ennustaa () menetelmä tutustua mitä on saatavilla meille:

sinun pitäisi odottaa, että mallisi pystyy havaitsemaan vain sellaisia objektityyppejä, jotka on tiukasti rajattu COCO-aineistoon. Jos haluat tietää, mitä esinetyyppejä valmiiksi koulutettu YOLO-malli pystyy havaitsemaan, tutustu coco_classes-koodeihin.txt-tiedosto saatavilla … /yolo-v4-tf.kers/class_names/. Siellä on 80 esinetyyppiä.
näin harjoittelet mukautettua YOLO-objektin tunnistusmallia
Tehtävälauseke

voit suunnitella objektien tunnistusmallin, sinun täytyy tietää, mitä objektityyppejä haluat havaita. Tämän pitäisi olla rajoitettu määrä objektityyppejä, joille haluat luoda ilmaisimen. On hyvä saada lista esinetyypeistä valmiiksi, kun siirrytään varsinaiseen mallikehitykseen.
Ihannetapauksessa sinulla pitäisi olla myös merkitty aineisto, jossa on sinua kiinnostavia kohteita. Tätä aineistoa käytetään ilmaisimen kouluttamiseen ja validointiin. Jos sinulla ei ole vielä joko aineistoa tai merkintää sille, älä huoli, näytän sinulle, mistä ja miten voit saada sen.
tietokokonaisuus & selitykset
mistä saat tietoja
jos sinulla on selitetty tietokokonaisuus käsiteltävänäsi, Ohita tämä osa ja siirry seuraavaan lukuun. Mutta, jos tarvitset dataset projektiin, aiomme nyt tutkia online-resursseja, joista voit saada tietoja.
ei ole oikeastaan väliä millä alalla työskentelet, on suuri mahdollisuus, että on jo olemassa avoimen lähdekoodin aineisto, jota voit käyttää projektissasi.
ensimmäinen suosittelemani resurssi on Abhishek Annamrajun” 50 + Object Detection Datasets from different industry domains ” – artikkeli, joka on kerännyt hienoja selityksin varustettuja aineistoja muun muassa Muoti -, vähittäiskauppa -, urheilu -, lääketiede-ja paljon muuta.

Kuvan lähde.
kaksi muuta hienoa paikkaa etsiä tietoja ovat paperswithcode.com ja roboflow.com jotka tarjoavat pääsyn korkealaatuisiin tietokokonaisuuksiin objektin havaitsemista varten.
Tarkista yllä olevat tiedot kerätäksesi tarvitsemasi tiedot tai rikastaaksesi jo olemassa olevaa aineistoa.
miten Yolo
tietoja merkitään, jos kuvatiedostosi tulee ilman merkintöjä, sinun on tehtävä merkintätyö itse. Tämä manuaalinen käyttö on melko aikaa vievää, joten varmista, että sinulla on tarpeeksi aikaa tehdä se.
huomautustyökaluna voi harkita useita vaihtoehtoja. Henkilökohtaisesti suosittelisin Labelimgin käyttöä. Se on kevyt ja helppokäyttöinen kuvien merkintätyökalu, joka voi suoraan tuottaa merkintöjä YOLO-malleille.
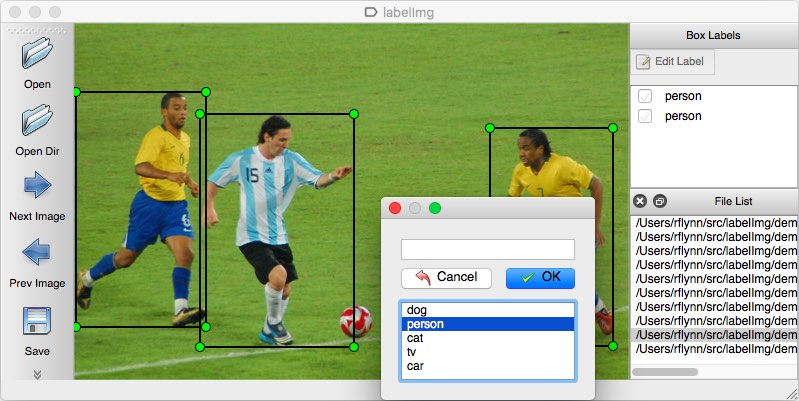
Kuvan lähde.
kuinka muuntaa tietoja muista formaateista YOLO
– merkinnöissä YOLO on muodossa txt-tiedostoja. Jokainen rivi txt tiedosto fol YOLO on oltava seuraavassa muodossa:
image1.jpg 10,15,345,284,0image2.jpg 100,94,613,814,0 31,420,220,540,1
voimme hajottaa jokaisen rivin txt-tiedostosta ja nähdä, mitä se koostuu:
- rivin ensimmäinen osa määrittää kuvien perusnimet: image1.jpg, image2.jpg
- janan toinen osa määrittelee rajausruudun koordinaatit ja luokkamerkinnän. Esimerkiksi 10,15,345,284,0 tilaa xmin, ymin, xmax, ymax, class_id
- jos tietyssä kuvassa on useampi kuin yksi objekti, kuvan perusnimen vieressä on useita ruutuja ja luokkanimikkeitä jaettuna välilyönnillä.
Bounding box-koordinaatit ovat selkeä käsite, mutta entä class_id-luku, joka määrittää luokan merkinnän? Jokainen class_id on linkitetty tiettyyn luokkaan toisessa txt-tiedostossa. Esimerkiksi valmiiksi koulutettu YOLO tulee coco_luokkien mukana.txt-tiedosto, joka näyttää tältä:
personbicyclecarmotorbikeaeroplanebus...
rivien määrä luokissa Tiedostojen on vastattava niiden luokkien määrää, jotka ilmaisimesi aikoo havaita. Numerointi alkaa nollasta, mikä tarkoittaa, että luokkatiedoston ensimmäisen luokan class_id-luku tulee olemaan 0. Luokka, joka on sijoitettu toiselle riville luokissa txt tiedosto on numero 1.
nyt tiedät, miltä yolon huomautus näyttää. Jatkaaksesi mukautetun objektin ilmaisimen luomista kehotan sinua tekemään kaksi asiaa nyt:
- luo luokat txt-tiedosto, jossa palace luokat, jotka haluat ilmaisin havaita. Muista, että luokkajärjestyksellä on väliä.
- luo txt-tiedosto, jossa on merkintöjä. Jos sinulla on jo merkintä, mutta VOC-muodossa (.XMLs), voit käyttää tätä tiedostoa muuntaa XML Yolo.
tietojen jakaminen osajoukkoihin
kuten aina, haluamme jakaa aineiston 2 osajoukkoon: koulutusta ja validointia varten. Se voidaan tehdä niin yksinkertainen kuin:
from utils import read_annotation_lines train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1)
luodaan datageneraattoreita
kun data on jaettu, voidaan edetä datageneraattorin alustukseen. Meillä on datageneraattori jokaiselle tiedostolle. Meidän tapauksessamme, meillä on generaattori koulutuksen osajoukko ja validointi osajoukko.
näin generaattorit syntyvät:
from utils import DataGenerator FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
yhteenvetona kaiken, tässä on mitä täydellinen koodi tietojen jakaminen ja generaattorin luominen näyttää:
from utils import read_annotation_lines, DataGenerator train_lines, val_lines = read_annotation_lines('../path2annotations/annot.txt', test_size=0.1) FOLDER_PATH = '../dataset/img'class_name_path = '../class_names/bccd_classes.txt' data_gen_train = DataGenerator(train_lines, class_name_path, FOLDER_PATH)data_gen_val = DataGenerator(val_lines, class_name_path, FOLDER_PATH)
asennus & mallikoulutuksen vaatimat asetukset
puhutaan niistä edellytyksistä, jotka ovat olennaisia Oman olionilmaisimen luomiseksi:
- Python pitäisi olla jo asennettuna tietokoneellesi. Jos sinun täytyy asentaa se, suosittelen tämän virallisen oppaan Anaconda;
- jos tietokoneessasi on CUDA-yhteensopiva GPU (Nvidian valmistama GPU), tarvitaan muutamia asiaan liittyviä kirjastoja GPU-pohjaisen koulutuksen tukemiseksi. Jos haluat ottaa GPU tuki, tarkista ohjeet Nvidian verkkosivuilla. Sinun tehtäväsi on asentaa uusin versio sekä CUDA Toolkit, ja cudnn käyttöjärjestelmän;
- kannattaa järjestää itsenäinen virtuaaliympäristö, jossa voi työskennellä. Tämä projekti vaatii TensorFlow 2: n asentamisen. Kaikki muut kirjastot otetaan käyttöön myöhemmin;
- mitä minuun tulee, olin rakentamassa ja kouluttamassa YOLOv4-malliani Jupyter-Kannettavien tietokoneiden kehitysympäristössä. Vaikka Jupyter Notebook tuntuu järkevältä vaihtoehdolta mennä, harkitse kehitystä valitsemassasi IDE: ssä, jos haluat.
Mallikoulutus

Edeltävät opinnot
tähän mennessä pitäisi olla:
- jako datasetille;
- kaksi datageneraattoria alustettu;
- txt-tiedosto, jossa luokat.
Model object initialization
to get ready for a training job, initialize the YOLOv4 model object. Varmista, että käytät mitään arvona weight_path-parametrille. Sinun pitäisi myös antaa polku luokat txt tiedosto tässä vaiheessa. Tässä on alustuskoodi, jota käytin projektissani:
class_name_path = 'path2project_folder/model_data/scans_file.txt' model = Yolov4(weight_path=None, class_name_path=class_name_path)
yllä oleva mallin alustus johtaa malliobjektin luomiseen oletusparametreilla. Harkitse mallisi kokoonpanon muuttamista siirtämällä sanakirjassa arvo config-mallin parametrille.

Config määrittää joukon parametreja YOLOv4-mallille.
Oletusmallikokoonpano on hyvä lähtökohta, mutta haluat ehkä kokeilla muita konfiguraatioita paremman mallilaadun saavuttamiseksi.
erityisesti suosittelen kokeilemaan ankkureita ja img_size. Ankkurit määrittelevät kohteiden kaappaamiseen käytettävien ankkureiden geometrian. Mitä paremmin ankkurien muodot sopivat esineiden muotoihin, sitä korkeampi mallin suorituskyky on.
Img_size-koon kasvattaminen voi olla hyödyllistä myös joissakin tapauksissa. Muista, että mitä korkeampi Kuva on, sitä kauemmin malli tekee päätelmän.
jos haluat käyttää Neptunusta seurantavälineenä, sinun tulisi myös alustaa koeajo, näin:
import neptune.new as neptune run = neptune.init(project='projects/my_project', api_token=my_token)
määrittelemällä callbacks
TensorFlow & Keras meidän on käytettävä callbacks seurata koulutuksen edistymistä, tehdä tarkistuspisteitä, ja hallita koulutuksen parametrit (esim.oppimistahti).
ennen kuin sovit mallisi, määrittele soittopyynnöt, joista on sinulle hyötyä. Varmista, että määrität polut mallin tarkastuspisteiden ja niihin liittyvien lokien tallentamiseen. Näin tein sen yhdessä projekteistani:
# defining pathes and callbacks dir4saving = 'path2checkpoint/checkpoints'os.makedirs(dir4saving, exist_ok = True) logdir = 'path4logdir/logs'os.makedirs(logdir, exist_ok = True) name4saving = 'epoch_{epoch:02d}-val_loss-{val_loss:.4f}.hdf5' filepath = os.path.join(dir4saving, name4saving) rLrCallBack = keras.callbacks.ReduceLROnPlateau(monitor = 'val_loss', factor = 0.1, patience = 5, verbose = 1) tbCallBack = keras.callbacks.TensorBoard(log_dir = logdir, histogram_freq = 0, write_graph = False, write_images = False) mcCallBack_loss = keras.callbacks.ModelCheckpoint(filepath, monitor = 'val_loss', verbose = 1, save_best_only = True, save_weights_only = False, mode = 'auto', period = 1)esCallBack = keras.callbacks.EarlyStopping(monitor = 'val_loss', mode = 'min', verbose = 1, patience = 10)
olisit voinut huomata, että edellä mainituissa kutsuissa set Tensorboardia käytetään seurantavälineenä. Harkitse Neptunuksen käyttämistä paljon edistyneempänä työkaluna kokeiden seuraamiseen. Jos näin on, älä unohda alustaa toista takaisinkutsua mahdollistaaksesi integraation Neptunen kanssa:
from neptune.new.integrations.tensorflow_keras import NeptuneCallback neptune_cbk = NeptuneCallback(run=run, base_namespace='metrics')
mallin
asentaminen harjoitustyön aloittamiseksi, yksinkertaisesti malliobjektin sovittaminen TensorFlow / Keras standard fit () – menetelmällä. Näin aloin treenata malliani:
model.fit(data_gen_train, initial_epoch=0, epochs=10000, val_data_gen=data_gen_val, callbacks= )
kun koulutus aloitetaan, näet normaalin etenemispalkin.

valmennuksessa arvioidaan mallia jokaisen aikakauden lopussa. Jos käytät joukko callbacks samanlainen kuin mitä alustin ja välitettiin asennettaessa, ne tarkistuspisteet, jotka osoittavat mallin parannusta kannalta pienempi menetys tallennetaan tiettyyn hakemistoon.
jos virheitä ei tapahdu ja koulutus etenee sujuvasti, koulutustyö keskeytetään joko koulutusjaksonumeron loppumisen vuoksi tai jos aikaisempi keskeyttäminen ei havaitse mallin parantumista ja pysäyttää koko prosessin.
joka tapauksessa pitäisi päätyä useisiin mallitarkastuspisteisiin. Haluamme valita parhaan kaikista käytettävissä olevista ja käyttää sitä päättelyyn.
koulutettu custom-malli päättelytilassa
koulutetun mallin ajaminen päättelytilassa on samanlaista kuin ennalta koulutetun mallin ajaminen laatikosta.

alustat malliobjektin, joka kulkee polulla parhaaseen tarkastuspisteeseen, sekä polun txt-tiedostoon luokkien kanssa. Tältä mallin alustus näyttää projektissani:
from models import Yolov4model = Yolov4(weight_path='path2checkpoint/checkpoints/epoch_48-val_loss-0.061.hdf5', class_name_path='path2classes_file/my_yolo_classes.txt')
kun malli on alustettu, käytä yksinkertaisesti valitsemasi kuvan predict () – menetelmää ennusteiden saamiseksi. Kertauksena mallin tekemät havainnot palautetaan kätevässä muodossa pandatiedotteena. Saamme luokan nimen, laatikon koon ja koordinaatit jokaiselle havaitulle kohteelle.
päätelmät
olet juuri oppinut luomaan mukautetun YOLOv4-oliotunnistimen. Olemme käyneet läpi päästä päähän-prosessin alkaen tiedonkeruusta, merkinnöistä ja muuntamisesta. Sinulla on tarpeeksi tietoa neljännestä YOLO-versiosta ja siitä, miten se eroaa muista ilmaisimista.
mikään ei estä sinua nyt harjoittelemasta omaa malliasi TensorFlow ’ ssa ja Kerasissa. Tiedät, mistä saa valmiiksi koulutetun mallin ja miten treenihommat saa käyntiin.
näytän tulevassa artikkelissani muutamia parhaita käytäntöjä ja elämänhuijauksia, jotka auttavat parantamaan lopullisen mallin laatua. Pysy luonamme!



Anton Morgunov
Computer Vision Engineer at Basis.Keskus
koneoppimisen harrastaja. Intohimoinen tietokoneen visio. Ei paperia – lisää puita! Tavoitteena paperikopioiden poistaminen siirtymällä täyteen digitalisaatioon!
READ NEXT
TensorFlow Object Detection API: Best Practices to Training, Evaluation & Deployment
13 min read | Author Anton Morgunov | Updated 28.toukokuuta 2021
tämä artikkeli on sarjan toinen osa, jossa opit TensorFlow Object Detection-ja sen API-työnkulun päästä päähän. Ensimmäisessä artikkelissa, opit luomaan mukautetun objektin ilmaisin tyhjästä, mutta on vielä paljon asioita, jotka tarvitsevat huomiota tulla todella taitava.
tutkimme aiheita, jotka ovat aivan yhtä tärkeitä kuin jo läpikäymämme mallin luomisprosessi. Tässä muutamia kysymyksiä, joihin vastaamme:
- miten arvioin malliani ja saan arvion sen suorituskyvystä?
- mitä työkaluja voin käyttää mallin suorituskyvyn seuraamiseen ja tulosten vertailuun useissa kokeissa?
- Miten voin viedä mallini käyttääkseni sitä päättelytilassa?
- onko olemassa keinoa parantaa mallin suorituskykyä entisestään?
Jatka lukemista ->